

用戶體驗(UX) 描述了人們在與系統或服務交互時的感受,包括多個因素,包括可用性、設計、營銷、可訪問性、性能、舒適度和實用性。
用戶體驗(UX) 描述了人們在與系統或服務交互時的感受,包括多個因素,包括可用性、設計、營銷、可訪問性、性能、舒適度和實用性。唐諾曼曾經說過,
“萬物皆有個性;一切都發出了情感信號。即使這不是設計師的本意,瀏覽網站的人也會推斷出個性並體驗情感。糟糕的網站具有可怕的個性,通常在不知不覺中向用戶灌輸可怕的情緒狀態。我們需要設計東西——產品、網站、服務——來傳達任何想要的個性和情感。”
以太坊的個性是一個極其高深莫測且容易被誤解的人。更糟糕的是,大多數用戶在使用您的界面或錢包時甚至不會將其視為與以太坊進行交互。如果你曾經在Artblock 拍賣的實時聊天中,你會注意到拍賣一結束,至少有十幾個人抱怨他們沒有搶到份額是Metamask 的錯。我認為在過去的一年裡,以太坊上許多dapp 的用戶體驗在產品交互和交易的可解釋性方面都有了很大的改進。在大多數情況下,dapps 不再只是在您簽署交易後給您留下一個加載微調器。
即使dapps 的設計總體上在改進,但我不確定UX 研究的深度。當我看到對各種協議的數據分析或研究時,用戶大多被視為同質的。根據我所看到的UniswapV3 流動性提供商和Rabbithole Questers 的一些分析,這種情況有所改變,但即便如此,這些分析仍主要集中在剛剛確認的鏈上交易上。根據我自己的經驗,大多數情緒誘發和行為怪癖發生在我提交、等待、加速或取消交易時。對於某些應用程序,用戶可能會在提交交易後離開並去做其他事情。但是對於像Artblock 的拍賣這樣的產品,他們會一直待到確認發生為止,可能會檢查所有可能的更新並增加焦慮。
我認為通過開始更多地利用內存池(mempool),我們可以更好地理解用戶行為和摩擦。內存池是節點臨時存儲未確認交易的地方。這意味著如果您提交、加速或取消您的交易,那麼這些操作將首先顯示在內存池中。需要注意的是,來自內存池的數據並未存儲在節點中,因此您無法像查詢已確認交易那樣查詢歷史數據。從這裡,您可以看到他們提交了一些交易,將交易加速了很多次,但遠未達到所需的gas 價格,最終在20 個區塊後看到了確認。我相信這是用戶體驗和他們在整個過程中可能感受到的情緒的一個很好的代表。如果我們了解不同用戶群體在這個循環中的行為,我們就可以弄清楚如何補充他們的決策或緩解他們的焦慮。據我所知,幾乎只有以太坊基金會、所有核心開發人員和一些錢包團隊出於用戶體驗的原因利用內存池數據。
用戶體驗研究論文:通過隨著時間的推移通過拍賣查看用戶的行為以及他們的錢包歷史,我們可以開始為不同的用戶群體提供行為身份。從這裡,我們可以確定要嘗試緩解的主要問題。為此,我們將使用Blocknative 獲取一個月的Artblocks Auctions 數據,並使用Dune 查詢對這些地址的歷史進行分層。
這篇文章將比我之前的一些文章更具技術性,因為我相信這項工作可以而且應該很容易推廣。我想強調的是,我的背景不是用戶體驗研究,我純粹是在嘗試我認為加密原生用戶體驗研究的樣子。
數據來源和預處理所有拍賣數據
如果你對技術位不感興趣,請跳到下一節——關於特徵工程
Blocknative 和Mempool 數據流
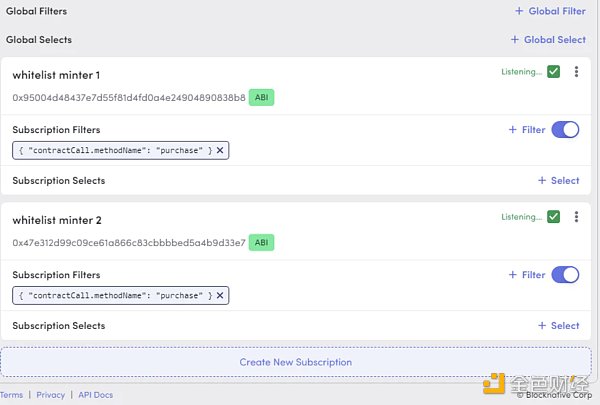
使用Blocknative 的Mempool 瀏覽器,您可以過濾提交給特定合約或來自特定錢包的交易。就我而言,我想听聽Artblock 的NFT 合約列入白名單的鑄幣合約。您可以在此處找到我使用的流,如果您想使用完全相同的設置,請將其保存下來。
您可以在其子圖中使用以下查詢找到列入白名單的鑄幣地址:
獲得所有購買的訂閱過濾器需要三個步驟:
-
使用“創建新訂閱”按鈕添加新地址
-
單擊地址旁邊的“ABI”按鈕添加ABI。就我而言,我只需要“購買”功能。

3. 為methodName 匹配購買添加過濾器(確保您沒有執行全局過濾器)
最後,您的設置應如下所示:
為了存儲這些數據,我創建了一個ngrok/express 端點來存儲在本地運行的SQLite 數據庫中。我創建了一個GitHub 模板,其中包含複製此設置的步驟。可能這裡要記住的最重要的一點是,在Blocknative 帳戶頁面中將POST 端點添加為webhook 時,您需要將POST 端點作為ngrok URL 的一部分。
關鍵預處理函數
多個交易哈希
當您加速或取消交易時,原始交易哈希將替換為新交易。這意味著如果您想在其整個生命週期中跟踪用戶的交易,您需要將新交易哈希與原始交易哈希進行協調。假設您將交易加速五次,您將擁有總共六個哈希值(原始哈希值+ 五個新哈希值)。我通過將tx_hash 的字典映射到新的replaceHash 來調和這一點,然後遞歸替換。

區塊編號問題
刪除的交易的區塊號為0,所以為了解決這個問題,我按時間戳按升序對數據幀進行排序,然後進行向後填充,這樣0 就會被它放入的正確區塊號替換。這是功能的重要修復工程。

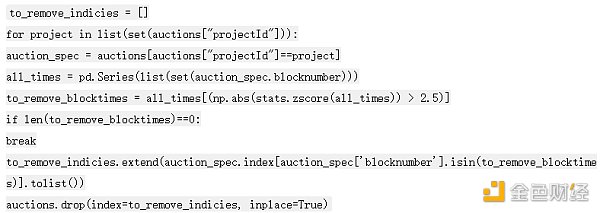
在主要拍賣期間處理鑄造
對於大多數項目,藝術家會在拍賣向公眾開放之前鑄造一些作品。有些項目不會立即售罄,因此在拍賣開始幾天后,您仍會收到鑄造。我的分析集中在關鍵的拍賣時段,主要是前30 分鐘。為了擺脫上面的兩個鑄造案例,我刪除了基於區塊編號的異常值。
添加荷蘭拍賣價格
對於數據集中除項目118 之外的所有項目,均使用荷蘭式拍賣價格格式。我使用dune查詢獲取薄荷價格數據,然後將其合併到數據集上。我不得不對有內存池操作但在拍賣期間沒有確認的塊使用向前和向後填充。

每次拍賣的特徵工程
如果您對技術部分不感興趣,只需閱讀粗體部分並跳過其餘部分。
在數據科學中,特徵是從更大的數據集計算出來的變量,用作某種模型或算法的輸入。所有特徵都在preprocess_auction 函數中計算,並且每次拍賣都會計算,而不是將所有拍賣組合成一個特徵集。
第一組特性是交易狀態的總數,是一個簡單的pivot_table 函數:
-
number_submitted : 提交的交易總數
-
cancel:以取消結束的交易計數
-
failed:以失敗結束的交易計數
-
dropped:以丟棄結束的交易計數
-
confirmed:以確認結束的交易計數
我之前提到過,由於各種問題,一些數據沒有用於拍賣,這些交易從數據集中刪除。
下一組特性包括它們的gas行為。這裡的關鍵概念是捕捉他們的交易gas 與每個區塊的平均確認gas 相差多遠。然後,我們可以為整個拍賣的gas 價格距離的平均值、中位數和標準差創建特徵。有一堆轉置和索引重置以按正確的順序獲取區塊編號列,但重要的函數是fill_pending_values_gas,它在捕獲的操作之間向前填充gas 價格。這意味著,如果我在區塊編號1000 處使用0.05 ETH的gas 進行交易,而我的下一個操作是在區塊編號1005 之前我加速到0.1 ETH 的gas,那麼此函數將用0.05ETH填充編號1000-1005 之間的區塊。

第三組特性是計算拍賣中採取的行動的總數和頻率。在這裡,我們從每個塊的總操作(加速)的支點開始,並進行一些特殊計算以獲取每個事務的第一個待處理實例:

從這裡我們通過三個步驟到達average_action_delay:
-
我們對每個區塊採取動作action的數量(是的,有些人在同一個區塊中多次加速交易)
-
我們在沒有動作的情況下丟棄區塊,然後計算剩餘區塊編號之間的差值。我們為每個區塊採取的每個額外動作添加一個0。
-
對差異和給我們average_action_delay的添加的0取平均值,

total_actions 簡單得多,因為它只是整個樞軸的動作總和。
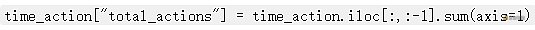
最後一個依賴時間的特性是block_entry,由於引入了荷蘭式拍賣,這是一個重要的特性。本質上,這會跟踪自開始以來提交事務的區塊。

price_eth 也被添加為一個特性,它與block_entry 點相關聯。
最後一組特性基於Dune 查詢,特別是自第一次交易以來的天數、交易中使用的總gas 以及交易總數。為了以正確的格式獲取地址數組,我在讀入SQL 數據後使用了以下代碼行:

對此的Dune查詢相當簡單。我將地址字符串粘貼到VALUES 下,並製作了一些CTE 以獲得我想要的功能。在最後的SELECT 中,我也嘗試添加每個地址的ens。您可以在此處找到查詢:https://dune.xyz/queries/96523
最後,我們只是合併了每個錢包的活躍天數、使用的總gas 和交易總數的數據。

完成所有這些後,我們終於準備好運行一些有趣的無監督學習算法,並嘗試驗證我們對用戶群的假設。
聚類和可視化用戶組
在我開始這個項目之前,我預計會看到以下用戶組從數據中彈出:
-
設置然後忘掉:這裡應該有兩個群體,那些設置了非常高的gas 和平均/低gas 的交易,然後在拍賣的剩餘時間裡不要碰它。
-
加速:這裡也應該有兩個群體,一類是經常加速並直接更新交易作為gas價格的因素,一類是經常加速交易但gas價格基本上沒有變化的人。
我對驗證這些群體非常感興趣,看看每個群體有多大,看看是否有用戶在多次拍賣過程中在群體之間移動。最簡單的方法是使用無監督機器學習,根據所有特徵的可變性來識別用戶組群。從本質上講,這就像查看一個州的收入分配,然後將其分成不同收入集中度、地理坐標和年齡的子分配。請注意,這不是分箱,其中分佈被分成相等的範圍- 它是根據整個範圍內的觀察密度計算的。我們將採用的方法稱為“無監督”,因為我們的數據集沒有任何現有標籤,而不是像回歸分析這樣的方法,其中預測的值可以被驗證為正確或錯誤。
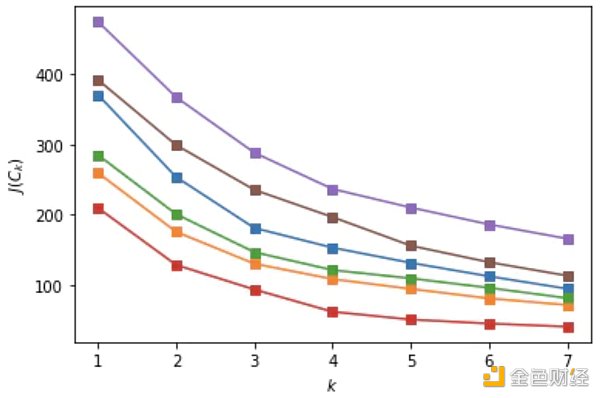
我決定使用的算法稱為k-means,其中k 代表您希望識別的集群數量。每個集群都有一個“質心”,就像一個圓的中心。有多種方法可以確定最佳集群的數量,我使用的兩種方法是肘點和輪廓分數。這兩種提問方式都很奇葩,
“每個額外的集群是否有助於增加集群的密度(計算為集群中點與質心的平均距離)並保持集群之間的足夠分離(兩個集群之間沒有重疊)?”
我發現3 個集群在大多數慣性改進方面是最佳的,同時保持高輪廓分數(大約0.55)。
本次分析使用了6 次拍賣
選擇集群後,我們希望能夠可視化並驗證它們的存在。這裡有超過15 個變量,因此我們需要減少維數以繪製它。減少維數通常依賴於PCA 或t-SNE 算法,在我們的例子中我使用了t-SNE。不要太擔心理解這部分,這些算法本質上捕獲所有特徵的方差,為我們提供X 和Y 分量,使點彼此的傳播最大化。
讓我們從8 月4 日看看項目118,LeWitt Generator Generator:
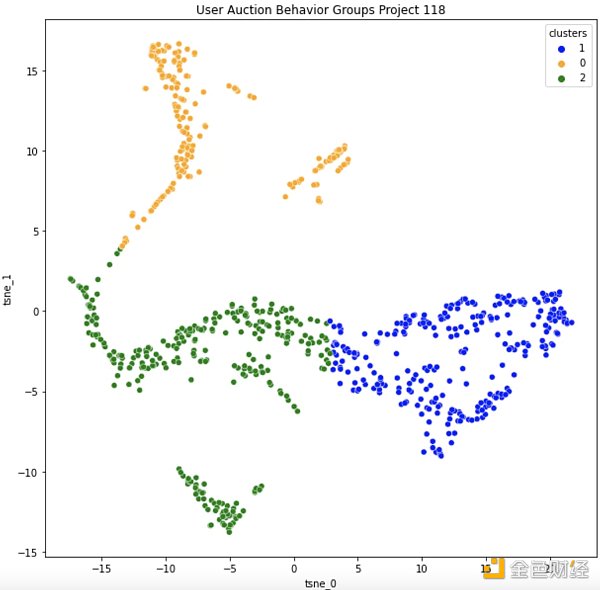
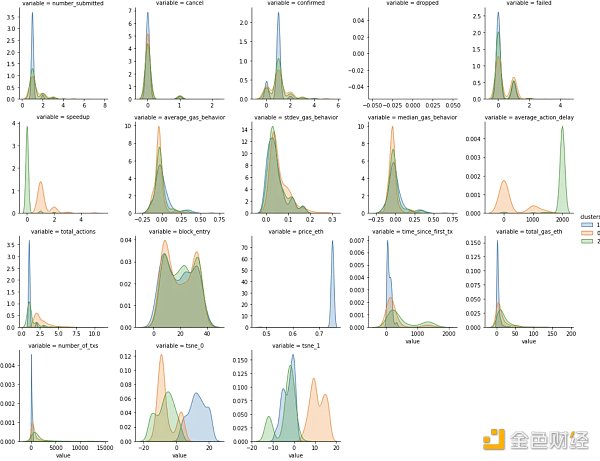
這些是使用KDE 計算的按集群劃分的每個變量的子分佈。顏色與上述集群中的顏色相匹配。
在查看了每個變量的子分佈和一些數據示例後,我能夠對集群進行分類。 Orange 集群是速度最快的組,同時平均提交的gas 交易也略低。 Blue 和Green 集群彼此表現出相似的行為,但Blue 中的地址通常比Green 集群中的地址具有更少的歷史記錄。
縱觀全局,原來的“提速”和“高低設置”產生兩組的假設似乎是錯誤的。相反,我們有一個“加速”群體(橙色)和一個“一勞永逸”群體(藍色和綠色在行為上相同)。我認為“設置並忘掉”群體中的新錢包(藍色)與舊錢包(綠色)可能在實際用戶中有很多重疊,用戶只是創建了新錢包來競標更多的鑄幣。基於他們的不耐煩和低於平均水平的gas價格,“加速”群體在我看來要么經驗不足,要么比其他用戶更貪婪。在整個拍賣過程中,這群人似乎也相當焦慮。令我驚訝的是,加速群體佔投標者總數的比例較小,因為我曾預計該群體佔投標者的60-70%,而不是30%。
現在,這個用戶行為研究真正有趣的地方在於將項目118(0.75 ETH 的設定價格)與項目140(荷蘭拍賣,價格從1.559 降到0.159 ETH)。
這是8 月21 日開始的項目140 Good Vibrations的集群聚集:
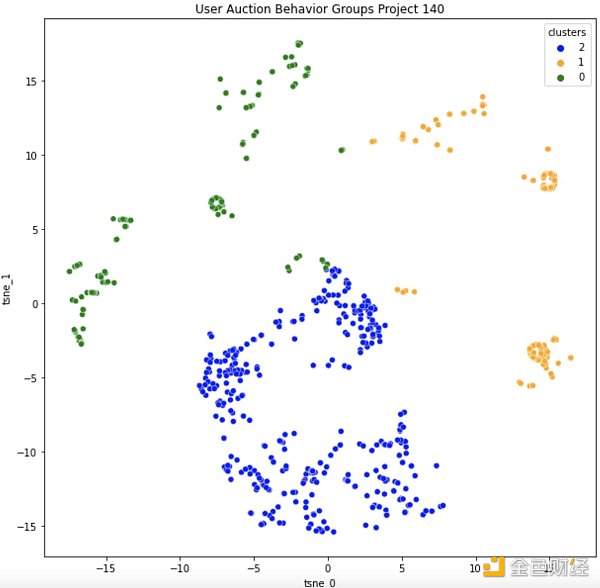
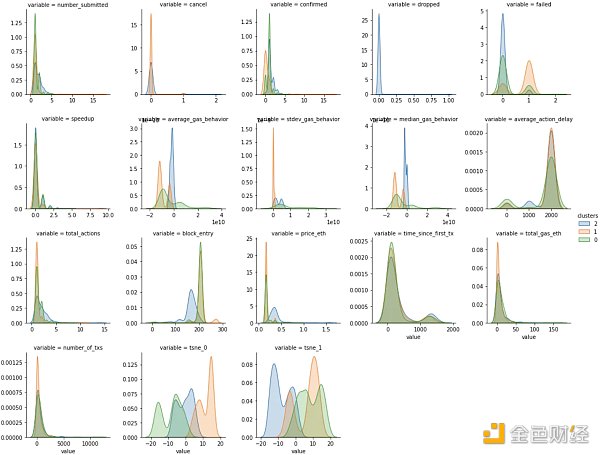
我們可以看到,現在大部分聚類變異性來自block_entry、price_eth 和所有gas_behavior 特徵。這與項目118 的主要變量大相徑庭。在118 中,設定價格意味著人們以相當均勻的分佈(剩餘數量似乎無關緊要)進入拍賣,而“加速”群體使行動相當無休止- 可能非常焦慮。
在項目140 中,我們在average_action_delay 或total_actions 中沒有看到相同的動作差異,相反,我們可能看到相同的“加速”群體在非常晚的階段進入並設置遠低於平均水平的gas價格,如平均gas行為。綠色集群可能代表比橙色集群有更多經驗的用戶,但他們的行為仍在橙色和藍色之間轉換。如果我嘗試將其映射到118 中的集群,我相信“加速”群體現在已成為進入較晚並發出低gas量的“貪婪”群體(橙色)。 “設置並忘記”群體很好地映射到“早搶”群體(綠色和藍色),因為他們都表現出很好的耐心和足夠的gas投標安全性淨值。
我稱橙色群體為“貪婪”,不僅因為他們的行為,還因為他們的交易失敗率。
對於項目118,“加速”群體與“設置並忘掉”群體的失敗率在10-15% 之間。

百分比丟失需要(取消 + 丟棄 + 失敗)/ number_submitted
對於項目140,“貪婪”集群的失敗率約為69%,而“早期搶奪”群體的失敗率約為5-15%。

總的來說,我對此的理解是,該團體的壞習慣和情緒被放大了——我覺得我們在焦慮→貪婪之間做出了權衡。這可能使拍賣的壓力較小,但最終導致更多用戶感到不安(由於失敗的鑄幣)。
我確信可以進行更細粒度的分析,以根據工廠/策劃/遊樂場或藝術家本人對拍賣進行進一步細分。隨著社區的不斷發展,這只會變得更加有趣和復雜,並且情緒在單次拍賣和未來拍賣中是否回歸都會發揮更大的作用。
這項對多次拍賣的研究幫助我們驗證了我們的假設,了解用戶組的比例,並了解用戶的好壞行為如何隨時間(和其他參數)變化。現在我們需要將其插入到產品週期流程的其餘部分中。
我們從哪裡開始:
我為此只選擇Artblocks 拍賣而不是混合平台的原因是因為我想尋找一個可以控制界面和項目類型可變性的地方。這應該為我們提供了相當一致的用戶和行為類型。
這只是UX 研究週期的開始,因此理想情況下,我們可以繼續以下步驟:
-
使用無監督機器學習算法來識別用戶群體(集群)並查看有多少人在進入拍賣時犯了“錯誤”。這是我們今天介紹的步驟。
-
創建一個新的用戶界面,例如出價屏幕上的直方圖視圖,或顯示大多數人通常何時進入/擁擠拍賣以及以什麼價格參加的歷史數據。任何可以為用戶提供當前和歷史背景的東西,尤其是來自速度集群的那些。
-
在每次拍賣中,通過創建的算法運行內存池/錢包數據,以查看用戶群體是否發生了變化,以及特定用戶是否“學會”以不同方式參與拍賣(即他們是否在用戶群體之間移動)。我認為如果做得好,可以在這一步中找到最大的價值。使用ENS 或其他標識符來幫助補充這個分組也會成倍地有用。
-
根據結果,繼續迭代用戶界面和設計。您還可以運行更明智的A/B 測試,因為您甚至可以通過基於用戶的最後一個集群(或對新用戶使用標籤傳播)進行有根據的猜測來確定要顯示的屏幕。
荷蘭式拍賣風格的變化也是第2 步的一個例子,我們能夠看到用戶行為的明顯轉變。雖然通常這種A/B 測試側重於提高參與度或轉化率,但我們在這裡優化的是用戶的學習和改進能力。如果在多平台背景中進行迭代,這可能會變得更加健壯,以便我們可以研究某人如何在生態系統級別進行學習(甚至可以補充Rabbithole 數據和用戶配置文件)。由於我的Artblocks 用戶研究全部基於公開來源的數據,因此可以被任何其他拍賣/銷售平台複製和補充。加密可能是第一個擁有同步且透明的用戶組和用戶體驗研究的行業,可應用於產品和學術界。 Nansen 錢包標籤已經朝著這個方向邁出了一步,但是當來自不同產品的團隊從不同的方面和方法構建它時,情況就不一樣了。
我最終的設想是使用數據來構建以下用戶角色(其中包含子組/級別):
-
我想購買一個Fidenza,所以我可以通過私人銷售購買一個,自己也可以在拍賣會上出價,在prtyDAO 出價拍賣中出價,或者通過fractional.art 購買一小部分。
-
我一般喜歡Fidenzas,所以我只會購買NFTX Fidenza 指數代幣或fractional.art上的Artblocks NFT 籃子。
-
我已經是一個收藏家,所以我想使用我已經持有的一組精選的NFT 和ERC20(使用genie-xyz 交換)交換或競標Fidenza。
-
我喜歡通過初始鑄造與二級市場進行收購的熱潮,並大量參與Artblocks在線鑄造之類的拍賣。
我希望你覺得這個項目有趣和/或有幫助,我玩得很開心。感謝Blocknative 的人們為我提供幫助,感謝Artblocks 的社區回答我的許多拍賣問題。與往常一樣,如有任何問題或想法,請隨時與我們聯繫!
您可以在此處找到包含所有數據和腳本的GitHub 存儲庫。該腳本可能有點難以閱讀,因為我仍在重構和清理它。當我分析8 月最後幾次拍賣的新模式時,這裡的腳本和一些分析可能會更新。
展開全文打開碳鏈價值APP 查看更多精彩資訊