

現在的Serverless 市場為什麼還需要OpenFunction ?概述
無服務器計算,即通常所說的Serverless,已經成為當前云計算領域的熱門話題與趨勢技術。無服務器計算是一種契合於當下云原生生態的開發、運行模式。無服務器並非不依賴服務器,而是對開發者而言服務器被抽象為更精確的算力單元。加州大學伯克利分校在論文A Berkeley View on Serverless Computing 中提出的關於Serverless 的觀點——Serverless computing = FaaS + BaaS 被廣泛接受,而FaaS (函數即服務) 是Serverless 的核心。
自AWS Lambda 面世後,各大雲計算巨頭廠商紛紛投入Serverless 戰場,爭相推出各自的Serverless 或FaaS 平台。另一方面,開發者不希望被特定廠商綁定的意願也讓開源的Serverless 項目有了一席之地。如今OpenFaaS(faas 倉庫20.3k)、Kubeless(6.7k)、Fission(6.4k)、OpenWhisk(5.4k)、Knative(serving 倉庫3.9k) 社區已經擁有大量的擁簇與開發者。
那麼為什麼KubeSphere 社區要做一個自己的FaaS 項目而不是直接集成現有的主流Serverless 或FaaS 框架?或者說現在的Serverless 市場為什麼還需要OpenFunction ?
Serverless 新願景
根據CNCF 的雲原生報告可以看出,Kubernetes 在容器編排技術領域擁有絕對的優勢,甚至可以將Kubernetes 作為雲原生的代名詞。雲原生是目前備受矚目的技術潮流,該領域的創新非常活躍,陸續湧現出了眾多優秀的開源項目(比如Serverless 領域的KEDA、Knative 等),並且還將繼續引領技術趨勢。在Kubernetes 宣布1.20 版本將棄用Docker、不再將其作為默認的容器運行時之後,儘管Docker 仍然佔據著容器運行時領域最大的份額,但對於雲原生開發者來說,不得不開始著手順應這方面的變化。
與此同時,人們生活方式的變化不斷催生新的業務模式,5G、大數據、邊緣計算、AI 推理、圖數據庫等服務應運而生。這些應用場景不但擴大了Serverless 的潛在市場,結合雲原生的技術潮流也孵化出很多新的技術,如Dapr、WebAssembly 等。如何突破現有項目的局限引入更新更強力的技術,如何抹平運行時之間的差異降低應用的開發成本,逐漸成為了開發者的新煩惱。
OpenFunction 項目背景
OpenFunction開源項目鏈接:
https://github.com/OpenFunction/OpenFunction
OpenFunction 是KubeSphere 社區發起的開源FaaS 項目,目前的核心開發人員均來自KubeSphere 團隊。 KubeSphere 社區一直陸續收到社區用戶對Serverless 或FaaS 功能的需求,也注意到了社區開發者參與Serverless 開發的興趣:
-
KubeSphere 是否有計劃集成Knative ?我願意參與開發!
-
KubeSphere 有FaaS 方面的計劃嗎?是否可以集成OpenFaaS ?
-
可否提供日誌告警的功能?這個需求本質上是可自動伸縮的異步數據處理。
和雲原生一樣,Serverless 是個不容錯失的賽道。僅僅集成現有的Serverless 或FaaS 項目還不足以體現Serverless 這個領域的重要性,於是KubeSphere 社區從2020 年下半年開始對Serverless 領域進行深度調研。經過一段時間的調研後,我們發現:
-
現有開源FaaS 項目絕大多數啟動較早,大部分都在Knative 出現前就已經存在了;
-
Knative 是一個非常傑出的Serverless 平台,但是Knative Serving 僅僅能運行應用,不能運行函數,還不能稱之為FaaS 平台;
-
Knative Eventing 也是非常優秀的事件管理框架,但是設計有些過於復雜,用戶用起來有一定門檻;
-
OpenFaaS 是比較流行的FaaS 項目,但是技術棧有點老舊,依賴於Prometheus 和Alertmanager 進行Autoscaling,在雲原生領域並非最專業和敏捷的做法;
-
近年來雲原生Serverless 相關領域陸續湧現出了很多優秀的開源項目如KEDA、 Dapr、 Cloud Native Buildpacks(CNB)、 Tekton、 Shipwright 等,為創建新一代開源FaaS 平台打下了基礎。
綜上所述,我們調研的結論就是:現有開源Serverless 或FaaS 平台並不能滿足構建現代云原生FaaS 平台的要求,而云原生Serverless 領域的最新進展卻為構建新一代FaaS 平台提供了可能。於是KubeSphere 社區決定發起OpenFunction 項目,其目標是構建新一代開源函數計算平台。
開源項目與社區發展
截至2021 年8 月, OpenFunction 陸續發布了4 個版本,在最新的v0.3.1 版裡builder 和serving 部分已經趨於穩定,並且發布了OpenFunction 自己的事件驅動框架OpenFunction Events。 KubeSphere 社區將持續在OpenFunction 進行投入,最新路線圖詳見OpenFunction Roadmap (https://github.com/OpenFunction/OpenFunction/blob/main/docs/roadmap.md)。
目前青雲全象低代碼平台已經採用OpenFunction 實現靈活的低代碼平台插件機制;也有來自Nebula 的社區用戶用OpenFunction 實現了語音助手;有社區開發者為OpenFunction 社區貢獻了NodeJS 版的Function Framework 和Builder。隨著項目逐漸成熟,會有越來越多的社區用戶使用OpenFunction,我們也期待有更多的社區開發者參與進來。
OpenFunction FaaS 框架設計詳解
OpenFunction 是一個開源的函數即服務(FaaS)框架,和大多數同類產品一樣,旨在讓用戶專注於他們的業務邏輯,而不必擔心底層運行環境和基礎設施。如下圖所示函數生命週期中幾個重要的部分分別是: 函數框架(Functions framework)、函數構建(Build)、函數服務(Serving)和事件驅動框架(Events Framework),下面我們將分別詳細闡述這幾個重要部分的設計及架構。
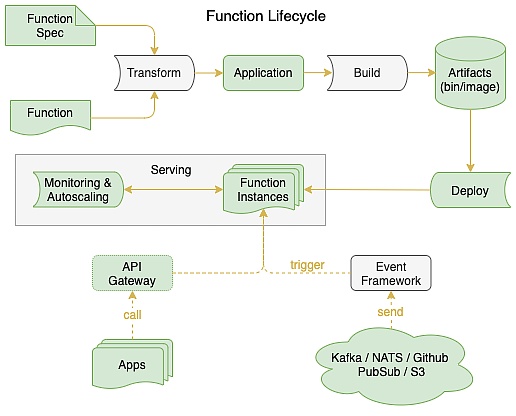 OpenFunction 函數生命週期示意圖
OpenFunction 函數生命週期示意圖
函數框架(Functions framework)
在FaaS 框架中,怎樣將一段函數代碼轉換為可運行的應用是一個重要的環節。我們知道函數計算之所以降低了開發成本,正是因為函數框架(Functions framework)代替開發者完成了很多與業務無關的工作。不僅如此,函數框架還為開發者提供了應用運行環境中的上下文和語義明確的函數開發擴展庫(可以理解為SDK)。
這部分的設計並不復雜,實現的難點在於如何做到上述的語義明確和功能強大。
我們調研了幾種主流的FaaS 框架(平台),發現大部分的項目選擇了封裝函數入參的做法,其意圖在於抽象輸入數據的處理方式,即無論請求是什麼格式,都可以使用框架提供的函數擴展庫來獲取數據。在這些成熟的案例中,我們發現封裝入參的方式可以使函數在同一個框架內具有很高的靈活性和可擴展性。當函數的數據輸入源變更後,函數本身不需要再做對應的入參適配,從而降低了使用者的開發成本。
從這個角度看,封裝入參方式比不封裝(或自定義)入參方式具備更大的潛力。接受了這個設定之後,我們再來看看函數框架的本質。函數框架本質上可以歸納為以下三個作用:
-
將用戶提供的函數轉換成可以運行的應用;
-
將用戶函數封裝為一個標準的訪問地址,提供給輸入端;
-
將輸出端封裝為一個標準的訪問地址,提供給用戶函數。
如果你了解過Dapr,你就會發現後面兩點和Dapr 的工作原理幾乎一致。 Dapr 是一種分佈式應用運行時,它以一種優雅的方式簡化了開發者與中間件的交互。在Kubernetes 中,Dapr 可以看作以Sidecar 的方式實現了函數轉換的功能。那麼是否能用Dapr 作為FaaS(Serverless)平台中的Functions framework?答案是肯定的。 OpenFunction 正是基於Dapr 提供了一套靈活的functions framework 機制(其中包含了借鑒Google functions-framework 處理HTTP 函數的部分)實現了與各種複雜中間件的對接,並搭載兩種運行時——以Knative serving 為基礎的同步函數運行時,和以KEDA 結合Dapr 為基礎的異步函數運行時OpenFunctionAsync,以期實現對實際生產中大部分應用場景的覆蓋。
為了能讓這個函數框架真正運作起來,往往還需要藉助一些函數範圍外的配置,用於定義函數和触發器、數據源、數據目標之間的關聯關係。我們稱之為函數上下文(OpenFunction Context),理論上它通常具備以下內容:
-
使用者通用元數據,如用戶ID、RequestID 等其他上下文信息;
-
事件源的定義,如名稱、類型、服務地址、數據類型等;
-
觸發器的定義,如名稱、類型、觸發規則、觸發週期、執行方式等;
-
函數的定義,如名稱、監聽地址等;
-
提供自定義的key-value 參數,如環境變量,以及用於適配不同的Runtime 等。
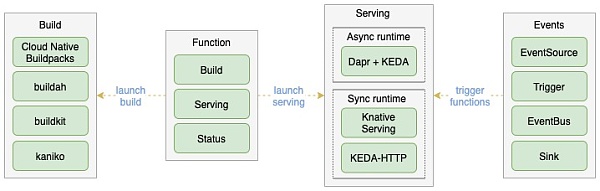 OpenFunction 組件示意圖
OpenFunction 組件示意圖
函數構建(Build)
我們通常會用Build 來指代容器鏡像的打包,但實際上將源代碼打包成鏡像只是構建工作中的一個步驟,開發者還有諸如拉取代碼、代碼預處理、鏡像上傳等工作需要完成。由此我們將Build 拆分為兩個主要的功能點,即製作容器鏡像與創建構建流水線。在調研了Cloud Native Buildpacks(CNB)、Tekton、Shipwright 等開源項目後,我們最終設計了OpenFunction Builder CRD,為用戶提供了一種可以自由選擇Build 方案的Build 框架。
Docker 被Kubernetes 放棄作為默認的容器運行時後,我們在Kubernetes 中製作容器鏡像還有多種選擇比如Kaniko、Buildah、BuildKit 以及Cloud Native Buildpacks(CNB)。其中前三者均依賴Dockerfile 去製作容器鏡像,而Cloud Native Buildpacks(CNB)是雲原生領域最新湧現出來的新技術,它不依賴於Dockerfile,而是能自動檢測要build 的代碼,並生成符合OCI 標準的容器鏡像,已經被Google Cloud、IBM Cloud、Heroku、Pivotal 等公司採用。
OpenFunction 選擇Cloud Native Buildpacks(CNB) 作為容器鏡像製作的默認選擇,陸續也會支持Kaniko、Buildah、BuildKit 等方式。
Cloud Native Buildpacks(CNB) 的核心是CNB Lifecycle,它負責將由應用源代碼到鏡像的構建步驟抽像出來,形成一套標準規範從而完成對整個過程的編排,並最終產出應用鏡像。這樣一來,開發者就可以將不同邏輯的最小構建單元buildpack(可以理解為Dockerfile 中的鏡像分層) 按自身的需求組合到一起,生成一個構建器(builder),再交由CNB 處理鏡像的構建過程。
因為這是一套開源的標準,所以在OpenFunction Builder 中開發者不但可以選擇OpenFunction 自身的構建器(builder)來構建鏡像,還可以選擇任何一種符合CNB Lifecycle 的構建器,如Google buildpacks、Paketo buildpacks 等,這意味著使用者可以構建任何語言、類型的應用。
Build 的另一個需求——構建流水線,就需要藉助Tekton 這樣優秀的流水線工具作為支持。在最開始的版本中,OpenFunction 毫不猶豫地選擇Tekton 來拆分構建環節的工作,為之前所談到的構建任務在Tekton 中創建對應的Task 及Pipeline 等。
在對Shipwright 的調研中我們發現Shipwright 同樣由Tekton 驅動,並且Shipwright 將Tekton 的設計理念帶入了鏡像構建過程,形成了非常云原生的鏡像構建框架,同時也支持使用Kaniko、Buildah、BuildKit 以及Cloud Native Buildpacks(CNB)構建鏡像,並可以通過指定BuildStrategy 和ClusterBuildStrategy 在上述四種鏡像構建方法之間進行切換。
於是我們在v0.3.0 版本中將原有的Tekton + Cloud Native Buildpacks 的構建方案切換成了Shipwright。 OpenFunction Builder 從設計上完美解決瞭如何在沒有Dockerfile 的情況下製作容器鏡像的問題,並且具備了高度自由、雲原生的構建器(構建方案)選擇機制。無論是使用現成的Dockerfile 還是僅用一段源代碼,OpenFunction Builder 都可以將其構建為Open Container Initiative(OCI)標準鏡像並上傳到指定的倉庫中。
函數服務(Serving)
函數服務(Serving)指的是如何運行函數/ 應用,以及賦予函數/ 應用基於事件驅動或流量驅動的自動伸縮的能力(Autoscaling)。我們根據這兩個方面設計了負責運行函數/ 應用的OpenFunction Serving CRD,並將函數分為同步函數和異步函數。同步函數是指客戶端發出請求後,必須等到函數執行完成並獲取函數運行結果後才返回;異步函數是指客戶端觸發函數後,無需等待函數運行結束即可返回。
在同步函數方面,Knative Serving 具備了非常出色的自動伸縮機制,OpenFunction 支持Knative Serving 作為同步函數運行時,未來還將基於KEDA http-add-on 開發OpenFunctionSync 同步函數運行時。
在異步函數方面,我們結合KEDA 和Dapr 開發了OpenFunctionAsync 異步函數運行時。 Dapr 用於解耦函數對各種中間件的訪問;KEDA 提供了ScaledObject 和ScaledJob 兩種資源,用於根據實際事件源的監控指標自動進行工作負載副本數量的伸縮,它很好地彌補了Knative Serving 在非HTTP 驅動源場景中的不足。同時KEDA 也在持續開發可以處理HTTP 請求的http-add-on 項目,這使得OpenFunction 在後續的演進中具備了更多的選擇,OpenFunction 未來將集成KEDA http-Add-on 實現不依賴Knative Serving 的OpenFunctionSync 運行時。
我們將上面的工作集合起來,即使用OpenFunction Serving CRD 來管理控制函數運行的整個生命週期。 Serving CRD 包含了使用者對函數類型、輸入、輸出端的定義,以及函數實例自動伸縮的定義。 OpenFunction Controller 會按照這些定義,生成相應的Knative Service、Dapr 和KEDA 組件,其中Knative Service 負責同步函數的運行與自動伸縮;KEDA 會負責異步函數的自動伸縮,而Dapr 會負責異步函數對接外部輸入/ 輸出。展開來講, Dapr 會將外部的輸入通過OpenFunction Context 傳遞給Functions framework,進而傳遞給函數;函數執行完成會通過調用Functions framework 中相應的函數將輸出通過Dapr 輸出到外部。
事件驅動框架(Events Framework)
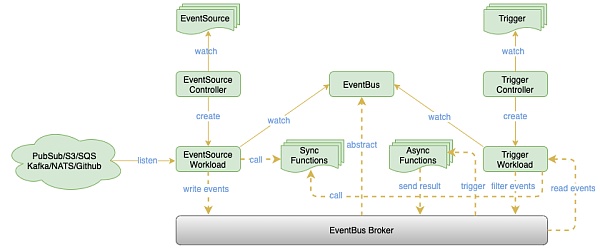 OpenFunction 事件框架示意圖
OpenFunction 事件框架示意圖
除了核心的FaaS 框架之外,OpenFunction 也設計了事件驅動框架以實現對異步函數的驅動。目前事件框架參考了Argo Events 與Knative Eventing 的部分設計,同時避免了引入類似Knative Eventing 中過於復雜的設計;通過引入Dapr 解耦了EventBus 與底層具體Message Broker 的綁定,進而利用Dapr 的binding 和pubsub 分別對接事件源與EventBus,以更優雅和可插拔的方式實現了類似Argo Events 的架構,具備了對事件源的條件判斷、對事件的流轉控制等能力。
本質上來看,事件框架也是一個由事件驅動的工作負載,那麼它本身可以是Serverless 形式的工作負載嗎?可以用OpenFunction 的異步函數來驅動嗎?其實OpenFunction 社區已將該設計列入路線圖中,目前也已實現部分組件的自驅動能力。
OpenFunction 的挑戰
我們從一些關於Serverless 的報告中可以看出,Serverless 服務有著可觀的市場潛力,未來五年內也許就會達到千億級的市場規模。然而對於Serverless 技術本身來說,仍有很多待解決的問題,如冷啟動、安全性、可觀測性等等。
OpenFunction 在發展的過程中非常看中趨勢中的技術,相信它們可以帶來活力與變革能力(也許Wasm 會成為OpenFunction 的下一個服務運行時)。將成熟的與新生的技術掰開揉碎和在一起,再穿插進獨立的設計與思考,或許就是OpenFunction 解決上述問題的後發者優勢,當然也是OpenFunction 當下面臨的挑戰。
加入OpenFunction 社區
期待感興趣的開發者加入OpenFunction 社區。可以提出任何你對OpenFunction 的疑問、設計提案與合作提議。
作者:
方闐 | 開放函數維護者
霍秉傑| OpenFunction 發起人
展開全文打開碳鏈價值APP 查看更多精彩資訊