本文將從數據特點、性能表現、擴展性等方面出發,對區塊鏈存儲模塊的數據庫選型及定向優化進行介紹。
原文標題《打破K/V存儲的性能瓶頸》
【前言】
前文《區塊鏈≠ 分佈式存儲》中,介紹了「區塊鏈系統」和「傳統分佈式數據庫」的異同,並認為“世界狀態”的維護是區塊鏈系統或區塊鏈存儲模塊的核心關注點,而交易數據、賬戶及其相關數據、交易執行結果三者一同構成賬戶模型下區塊鏈系統最基本的世界狀態。
本文將從數據特點、性能表現、擴展性等方面出發,對區塊鏈存儲模塊的數據庫選型及定向優化進行介紹。
圖片
區塊鏈存儲模塊需要關心的數據類型
【賬本數據】▲ 什麼是區塊鏈賬本?通常情況下,區塊鏈賬本包含「賬戶數據」與「合約數據」。
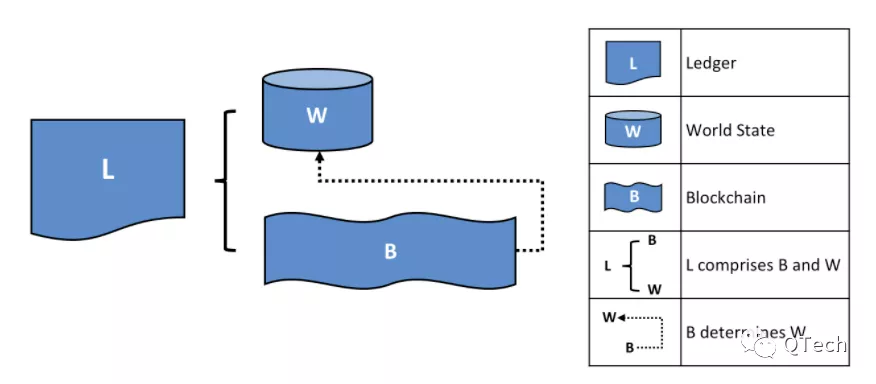
用一個日常的例子來理解賬本:在查詢銀行賬戶時,我們最關注的可能是當前的餘額,但如果要探究當前的餘額是經歷怎樣的變化而來,就需要去查詢歷史的交易記錄。這就體現出了區塊鏈賬本的核心含義,即當前的狀態(餘額)與一組決定該狀態的交易,如下圖所示:
 圖片
圖片
在區塊鏈中,上述狀態代表系統中所有對象的當前狀態集合,其往往是一個哈希值,而且當任意一個對象發生改變,該哈希值就會徹底改變。借助該哈希值,我們能非常直觀的判斷兩個區塊鏈節點是否處於相同的狀態;而決定狀態的交易指的其實就是物理上的區塊鏈,鏈上存儲了所有造成狀態改變的交易,不同於世界狀態,區塊鏈只能追加而不能被修改。
▲ 如何存儲賬本?
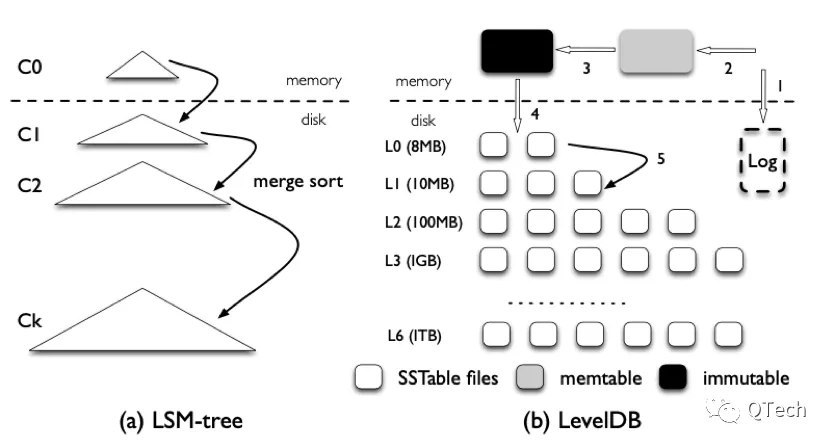
如果從「數據類型」的角度出發,經過上面的分析我們其實可以看出區塊數據其實是一種連續的且只支持末尾追加的結構,因此完全可以充分利用磁盤順序寫入的優勢,連續地進行存儲(本系列的後續文章將著重介紹:區塊鏈連續型數據的存儲);而對於「狀態數據」來說,由於會被頻繁地寫入和更新,因此從性能角度出發,狀態數據更適合基於LSM-tree的存儲引擎,如以太坊[1]、超級賬本結構[2]等區塊鏈項目均使用Leveldb作為默認的狀態數據庫。
區塊鏈需要保證每一筆交易執行的原子性:一筆交易要么完全執行成功,要么完全執行失敗,一旦執行過程中產生了錯誤,就需要回退掉這筆交易帶來的所有狀態修改。
以太坊引入了StateDB的概念來解決這個問題,即把某一筆交易執行過程中產生的修改緩存在內存數據庫中,執行成功後再藉助Leveldb原子寫入的特性進行持久化。
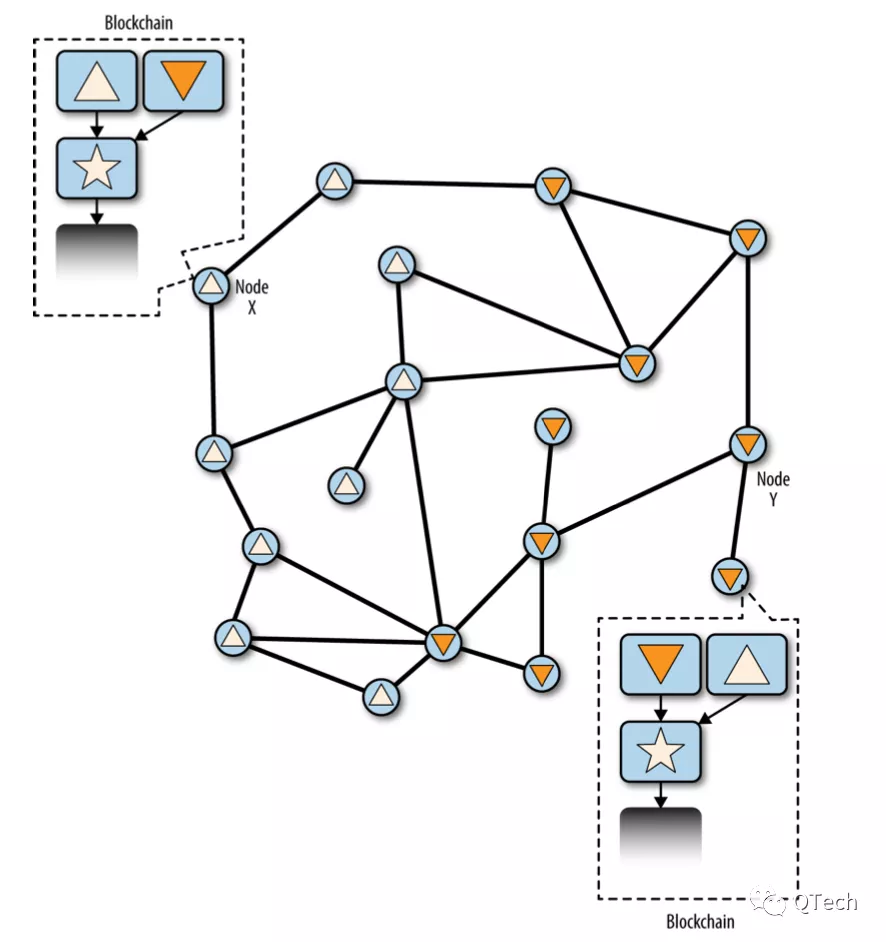
▲ 問題分析在區塊鏈正常運行的情況下,上述對於賬本的存儲方式沒有任何問題。然而我們知道,在以比特幣[3]、以太坊為代表的公鏈中,出現短暫的鏈分叉是非常普遍的現象(如下圖所示),節點可以根據預設的協議(如比特幣的最長鏈原則)進行自動恢復;而即使在使用了拜占庭容錯類算法的聯盟鏈中,在算法層面不可能發生分叉,但仍然可能出現某個節點因為寫入過程宕機、拜占庭行為、系統資源或硬件故障等原因造成執行失敗或數據不一致的問題,從而也產生了分叉的現象,為了保證系統的魯棒性和邏輯的完備性,在聯盟鏈中也需要對分叉的狀態進行數據恢復的機制。
下圖表示整個區塊鏈處於分叉的狀態,五角星區塊代表了上一次全網一致的狀態,正三角形和倒三角形分別表示了當前兩個不同的狀態。
 圖片
圖片
經過上面的介紹,我們若要進行數據的恢復,讓整個系統恢復一致,需要那些異常節點:
1)回滾掉分叉點之後的區塊和交易;
2)撤回這些交易對狀態數據庫造成的影響。
前者的實現可以非常簡單,若我們通過KV數據庫來存儲區塊和交易數據,那麼我們可以根據對應區塊號或者交易哈希來進行刪除操作,若通過連續型數據庫來進行追加式的存儲,直接進行類似文件的截斷即可;而對於後者,狀態數據的鍵與區塊號或交易並沒有任何綁定關係,某筆交易造成某些鍵值的修改是散落在整個狀態空間的,無法進行簡單的回退。
在以太坊[1]StateDB中引入了修改集(Journal)的結構,借助於修改集我們可以完成狀態數據的回退。修改集是一個記錄每次修改操作的數據結構。以以太坊為例,若Jackson和Zoey各自都有10個代幣,在執行完一條“Jackson給Zoey轉賬5個代幣”後,會為這兩個人各自生成一條修改集(如下圖所示)。
在以太坊中,通過修改集的撤銷(Undo)和重做(Redo)可以實現狀態的回滾和重做,同樣以上述轉賬為例,當這筆交易需要被回滾時,可以從修改集中得到“Jackson在轉賬前的餘額為10,Bob在轉賬前的餘額為10”這個信息,通過進行修改集的撤銷從而恢復至交易前的狀態;而若需要重放這筆交易時,無須重新使用虛擬機執行交易,而是通過修改集內的值進行賦值即可。
因此當我們要回滾某個區塊時,我們可以取出該區塊執行過程中產生的所有修改集,並且逐一撤銷,並將得到的結果寫入底層數據庫,最終完成本次回滾。
 圖片
圖片
上述流程邏輯上看沒有任何問題,但在底層數據庫的角度而言,這樣的回滾方式則顯得效率低下。
首先,我們在執行交易時,需要對交易的每次修改都生成對應的修改集,且這份修改集要隨著區塊一起持久化存儲,以防日後可能出現的分叉事件,這顯然是對執行與存儲資源的一種消耗,尤其是在使用智能合約的場景,一筆合約交易可能會造成無數的對象修改,從而產生無數的修改集;
其次,對於LSM-tree來說,刪除或者更新一條數據也是以插入新數據的方式完成的,只有當後台進行歸併操作並發現某一輪歸併出現了重複的key時,才會根據記錄的新舊來刪除或更新數據,因此Undo修改集的方式會加劇LSM-tree的存儲空間放大問題。
▲ 如何優化
上節提到,無論是公鏈還是聯盟鏈都需要完備的應對分叉的邏輯,但並非所有的區塊都有被回滾的風險,如比特幣中一個被確認一個小時或六個區塊之後的區塊幾乎不存在被回滾的風險,如PBFT算法中經過Checkpoint確認的區塊也不存在回滾的風險,以此作為出發點,我們可以參考StateDB的思想:只持久化那些不可能再被回滾的區塊,而採用緩存的方式存儲有回滾風險的區塊。
在所有的LSM-tree的實現中,均將整棵樹分成了內存和磁盤兩部分(如下圖)。如在LevelDB中擁有一個MemTable和一個Immutable作為寫緩存來實現異步地磁盤寫入;而RocksDB更為靈活,使得內存的MemTable數量可配,進一步提高寫入速度。針對回滾的場景,我們可以對MemTable進行定向的優化。
 圖片
圖片
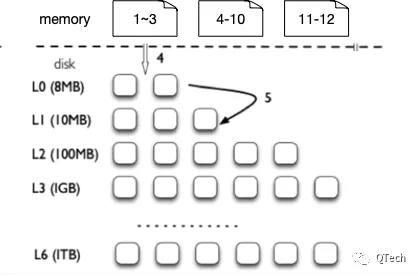
MemTable是以大小進行劃分的,現在我們將其以PBFT算法中的的Checkpoint進行劃分,即每個MemTable中保存的是若干個同屬於一個Checkpoint的區塊,而從MemTable寫入磁盤的時機也不再是大小超過閾值,而是共識經過了Checkpoint檢查,確定全網有Quorum個節點處於一致的狀態,才通知存儲模塊進行持久化,在這種方式下,所有持久化的數據將不再有被回滾的可能,如下圖所示的LSM-tree的內存部分包含了3個Checkpoint的MemTable,它們將根據共識的狀態被確定性地寫入磁盤。值得一提的是,為了控制內存的佔用,傳統LSM-tree中的MemTable大小是可配的,一旦超過閾值即觸髮刷盤,而在我們的方案中,得益於PBFT算法Watermark的限制,內存佔用也是受限制的。
 圖片
圖片
在這種情況下如何進行狀態數據的回滾呢?
在上圖中,磁盤部分的數據是不可能再被回滾掉的,那麼如果經過共識Checkpoint比對發現12號區塊發生了分叉,我們如何回滾掉12號區塊呢?在Leveldb中MemTable是一張跳表,我們無法從中剝離出12號區塊相關的數據。此時就需要利用Leveldb中的預寫日誌了(Write Ahead Log,WAL),WAL是為了防止數據寫入內存後的宕機丟失而存在的,即數據一定是先被寫入磁盤,才會寫入內存。而Leveldb中的WAL是按照MemTable進行組織的,一個MemTable對應著一個WAL,若我們可以以區塊為劃分來組織WAL,就可以解決上述回滾掉12號區塊的問題,即直接刪除11-12這張MemTable,隨後將11號區塊的WAL重新寫入新的MemTable,最後刪除12號區塊的WAL。
經過上述的定向改造,回滾狀態數據庫幾乎已經完全是內存操作了,且我們不再需要額外的修改集來完成回滾操作。
【索引數據】
▲ 什麼是區塊鏈索引?
交易(Transaction)是區塊鏈中最基本也是最重要的數據結構。每筆交易中都封裝了一次對區塊鏈賬本的操作,經過驗證的合法交易將會被執行並保存在區塊鏈中;而區塊(Block)是存儲交易及相關元數據的數據結構。交易由交易哈希唯一標識,而區塊可由區塊號或區塊哈希唯一標識(不考慮分叉的情況)。
用戶在發送交易後,需要向區塊鏈查詢交易的上鍊情況,若係統中只存儲了世界狀態數據,那麼用戶對歷史數據的查詢只能通過遍歷所有區塊實現,這樣的代價和延遲顯然是無法接受的。因此為了保證用戶的使用體驗,區塊鏈往往會提供多種索引方式供用戶查詢使用,如通過索引快速的確認交易所在的區塊,甚至可以更細粒度的直接定位到交易存儲於這個區塊內的哪個位置。
現階段的區塊鏈的基礎結構較為簡單,通常在底層採用單機KV存儲引擎,如LevelDB,RocksDB等進行數據的持久化存儲。這也意味著上述索引數據與所有賬本數據一起存儲在了同一個數據存儲引擎。但是聯盟鍊或私有鏈通常作為企業級商用系統,整體數據量極大。隨著數據量日益增大,數據庫存儲讀寫性能將會受到嚴重影響,區塊鏈基礎信息的查詢(區塊查詢、交易查詢)的性能也會急劇下降,導致用戶查詢延遲大幅增加,在延遲要求較高的場景下,這幾乎是不可接受的。
我們以以太坊與Hyperledger Fabric為例,分析其索引信息的存儲方式和大數據量下的索引數據解決方案。
▲ 實例分析之“以太坊”
以太坊[1]中提供了通過交易哈希查詢交易、通過區塊編號或者區塊哈希查詢區塊的功能。分析源碼可知,以太坊中維護瞭如下的映射關係:
(H) + 區塊哈希 -> 區塊編號
(h) + 區塊編號 + (n) -> 區塊哈希
(h) + 區塊編號 + 區塊哈希 -> 區塊頭
(b) + 區塊編號 + 區塊哈希 -> 區塊體
(l) + Tx Hash -> 區塊號
以通過交易哈希查詢交易為例,根據以上映射關係,首先可通過交易哈希獲取包含此交易的區塊的編號,根據區塊編號獲取相應區塊哈希,根據區塊編號與區塊哈希可獲取區塊體,從而獲得此區塊包含的所有交易列表,之後遍歷交易列表,即可找到目標交易。
以太坊將所有數據都直接存入LevelDB,其freezer會定時從LevelDB中將部分數據遷移至freezerTable,但不包括區塊哈希到區塊編號的映射與交易哈希到區塊編號的映射。從數據量上看,由於一個區塊可能包含多筆交易,交易哈希到區塊編號索引的數據量最為龐大。
▲ 實例分析之Hyperledger Fabric
超級賬本結構[2]同樣提供了通過交易ID查詢交易、通過區塊編號或者區塊哈希查詢區塊的功能。分析源碼可知,Fabric中維護瞭如下的映射關係:
(h) + Block Hash -> Block Loc
(n) + 區塊編號 -> 區塊位置
展開全文打開碳鏈價值APP 查看更多精彩資訊