這份數據證明是什麼?又是怎麼實現的?帶著這份疑問,本文將詳細介紹目前主流的數據證明的實現以及解決方案和優化思路。
【背景介紹】
前文《打破K/V存儲的性能瓶頸》中,我們提到用一個哈希值來反映區塊鏈系統中所有對象的當前狀態集合,並稱之為“世界狀態”。現在大多數區塊鏈底層平台為了支持與其他鏈集成,或者為了部署在更小的終端,都會提供輕節點的功能,輕節點也就是存儲少量數據的“輕量級節點”,但因為沒有存儲全量數據,無法對其他節點的數據進行正確性的驗證。這里便需要其他節點生成一份數據證明,配合輕節點本地保存的“世界狀態”來進行數據的驗證。
這份數據證明是什麼?又是怎麼實現的?帶著這份疑問,本文將詳細介紹目前主流的數據證明的實現以及解決方案和優化思路。
【默克爾證明】
介紹數據證明前,我們先要了解傳統的默克爾樹,以及對應的證明生成和驗證的流程。
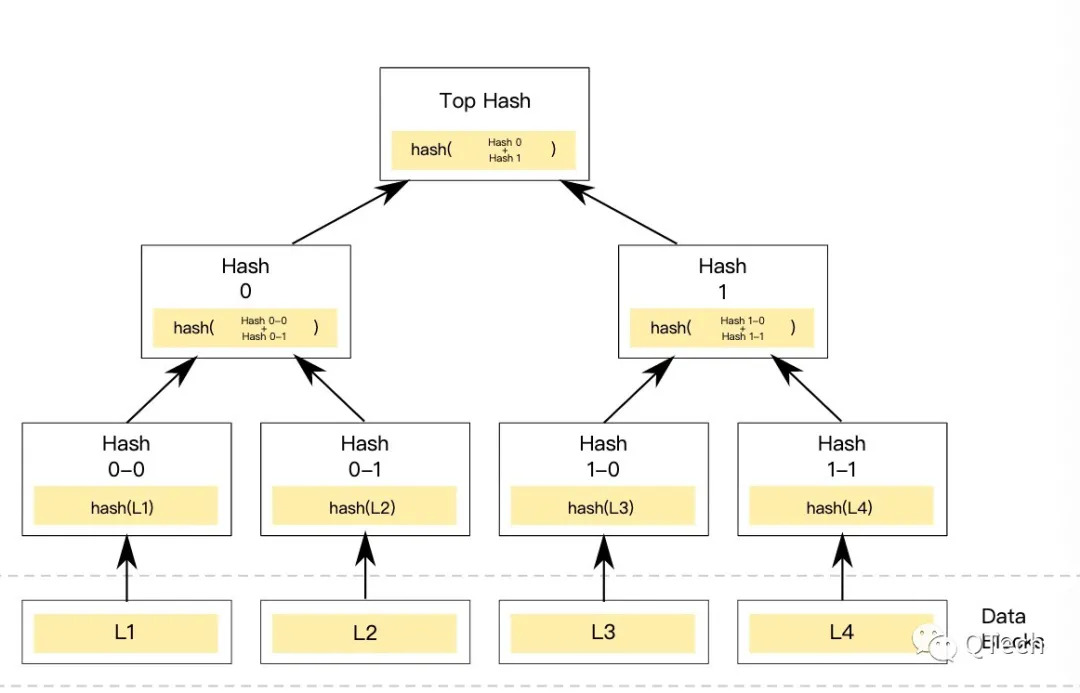
默克爾樹(Merkle Tree),因發明人叫Merkle,並且是樹形結構而得名。如下圖,默克爾樹的葉節點存儲數據或者數據的哈希值,任一父節點包含了其子節點總和的哈希值。
圖片
默克爾樹最大的作用便是快速校驗部分數據是否在原始數據中。
舉個例子,要想驗證L2在上圖的這棵樹上,只需要節點列表[L2,Hash0-0,Hash1]即可,通過L2可以計算出Hash0-1,通過Hash0-1與Hash0-0可以計算出Hash0,再通過Hash0與Hash1,便可以得到一個樹根,再把該樹根與Top Hash進行比對即可快速驗證L2是否在樹中。默克爾樹生成數據證明以及驗證數據證明的原理就是如此,生成證明時自底向上,不斷獲取父節點的兄弟節點,打包成數據證明;驗證時通過遍歷證明中的節點列表,不斷進行哈希得到父節點的操作,最後可以得到樹根節點,再把該樹根與原樹根進行比對,達到驗證的目的。
這種基本的默克爾樹廣泛應用在區塊鏈系統中,例如比特幣中輕錢包的SPV(簡單支付驗證)便是應用該原理,比特幣中區塊記錄的root便是區塊中交易集合構成的默克爾樹的樹根,使得無需下載完整區塊,只需要區塊頭便可以驗證某條交易的有效性。
【以太坊上的數據證明】
默克爾樹雖然滿足了數據證明以及驗證的需求,但是其二叉樹的結構,會使其在存儲龐大的狀態數據時,造成中間節點太多,有存儲壓力大的問題;並且默克爾樹在對數據的增刪改查方面沒有解決方案,我們知道狀態數據在執行合約時需要頻繁的讀寫,因此可以對數據進行查詢修改也是非常重要的,針對以上幾點問題,以太坊提出了默克爾帕特里夏樹(Merkle Patricia Tree,下文稱MPT)。
▲ 什麼是MPT?
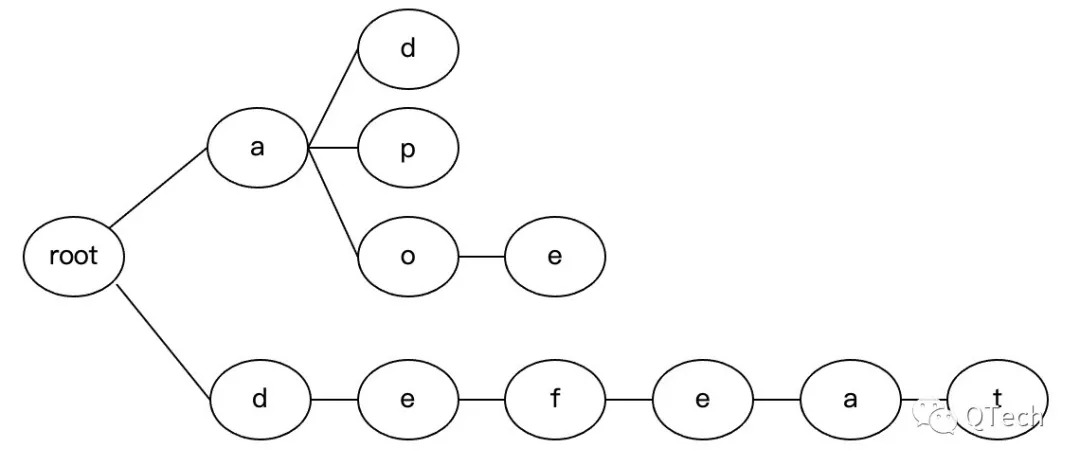
MPT主要結合了默克爾樹和前綴樹的特點,前綴樹顧名思義,是一種利用字符串的公共前綴來進行查詢的樹,如下圖所示,用來查詢有共同前綴的數據不需要進行字符的比對,十分方便,但缺點也十分明顯,如果一個字符串與其他節點沒有公共前綴時,便會帶來很多節點的創建,造成存儲空間的浪費。
 圖片
圖片
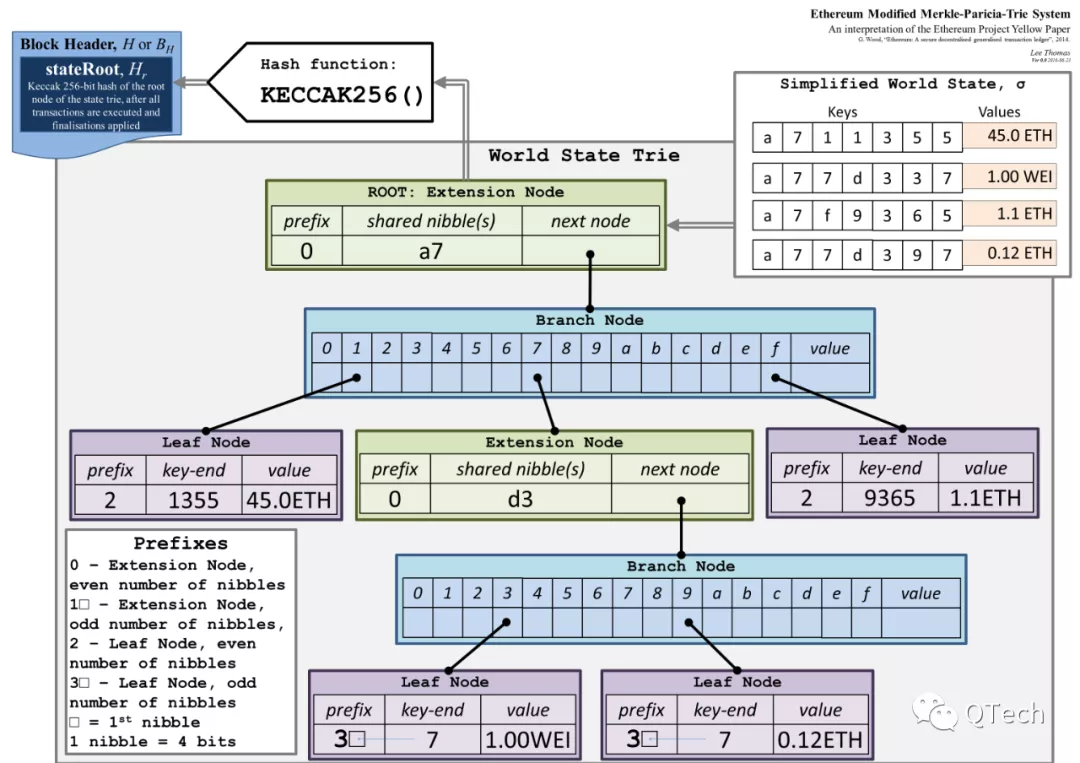
基於默克爾樹以及前綴樹的優缺點,MPT提出了四種節點類型:
1)空節點:用來表示空字符串;
2)分支節點:用來表示MPT樹中所有擁有超過1個子節點以上的非葉子節點,最多能容納十六個子節點;
3)葉子節點:表示為 [key, value]的一個鍵值對,其中key是一種十六進制編碼(HP編碼),value是節點具體內容的RLP編碼;
4)擴展節點:同樣表示為[key, value]的一個鍵值對,不過value是其他節點的hash值,這個hash可以被當做key,用來在數據庫中查詢子節點;
 圖片
圖片
相比於普通的前綴樹以及默克爾樹,MPT加入了擴展節點,可以將不共享的前綴壓進一個節點,帶來路徑壓縮的特性,降低了樹的高度,減少了空間浪費;分支節點的加入,使得單個節點最多能有十六個分叉,同樣也是降低了樹高;並且通過哈希值進行樹節點間的連接,確保了安全性與可驗證性。
對MPT上的數據進行增刪改查,需要通過前綴索引到對應的節點,葉子節點的改動會帶來新的分支節點或者擴展節點的加入,新的節點需要進行哈希計算得出新的哈希值,然後更新父節點的信息,造成索引路徑上節點的哈希值的連鎖的改動,最後生成一個唯一的“世界狀態”。
在MPT上,要想生成數據證明,也需要沿著樹進行前綴的索引,並把索引路徑上的節點打包成證明返回即可。驗證數據證明的時候,需要驗證葉子節點中鍵的正確性,並且對證明中的節點列表進行自底向上的哈希操作,最後比對樹根的值即可。
▲ 性能瓶頸
上文提到以太坊是以節點的哈希值作為數據庫存儲節點的鍵,這些節點的存儲與區塊號或交易並沒有任何綁定關係,並且散落在整個狀態空間中的,那麼隨著交易量的增大,狀態變遷帶來的新節點也會增多,數據存儲壓力會越來越大。
由於以太坊底層採取的是leveldb存儲,對於每個鍵值的讀取最壞情況下需要一次磁盤IO,那麼在執行合約的時候,將會有大量的時間耗費在狀態的讀取中,久而久之系統整體的性能會越來越差。
【聯盟鏈下如何優化? 】
當下主流數據庫一般分為兩種:以LSM樹為主的數據庫例如leveldb、rocksdb;還有以B+樹為主的數據庫例如mysql。相同條件下B+樹的讀要比LSM樹更有效率,在聯盟鏈場景下,我們知道大部分應用場景都是讀多寫少,那麼針對聯盟鏈,能不能基於B+樹來提出一種既能實現數據證明,又可以兼顧到讀寫性能的方法呢?答案是肯定的,我們提出了一種默克爾B+樹的結構,結合了B+樹以及默克爾樹的特點,降低了查詢所需的磁盤IO以及存儲的數據量,在保持高性能的同時,還能提供數據證明、數據可驗證的功能。
▲ 什麼是默克爾B+樹?
B+樹是一種n叉的平衡查找樹,所有鍵值對都會按鍵值的大小順序存放在最後一層葉子節點中,父節點會記錄其連接的子節點的最小鍵值,方便索引。
默克爾B+樹以B+樹為基礎,包含了兩種節點:處於最後一層的數據節點、索引節點,該樹具有以下的特點:
1)每個節點會有一個ID;
2)索引節點的子節點列表中存放了子節點的最小鍵以及哈希值;
3)數據節點的子節點列表存放的是[key,value]狀態數據鍵值對;
4)每個節點的哈希值由它的子節點列表總和的哈希值得出;
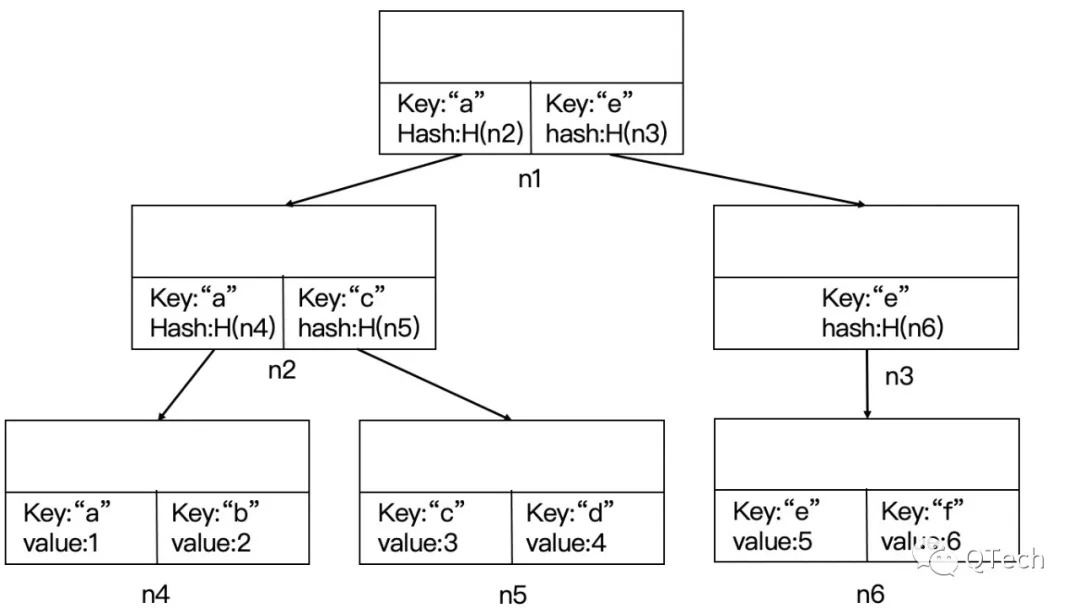 圖片
圖片
如上圖,將狀態數據以鍵值對的形式存入數據節點,每個節點最後會以頁的形式存放到磁盤中,為了更適應磁盤的讀寫策略,規定每個頁大小為4K(磁盤頁大小通常為4K),這樣就可以通過計算出頁ID*頁大小的偏移量從磁盤讀取某個節點。
同樣我們規定每個節點最多容納4K的數據,如果某個數據節點插入太多鍵值對,導致其超過了4K的閾值,將會產生分裂,變為多個不超過閾值的新數據節點,並把對應的新節點信息插入到原父節點的子節點列表中,再遞歸檢查父節點即索引節點是否超過閾值,如果超過將會重複分裂過程。
這裡我們會提供一個最大頁ID以及空閒ID列表來管理頁ID,當新建了一個節點時,會先去空閒ID列表查詢一下是否存在滿足條件的ID,有則取出來分配給新節點,否則會把最大頁ID分配給新節點,並遞增最大頁ID。有分配自然就會有回收,當節點A分裂為節點B和節點C時,節點A的頁ID就會被回收,納入到空閒ID列表中。當發現某個節點變為空節點時,也會被回收頁ID。
由於默克爾B+樹在每個節點都存儲了哈希值,每次對狀態數據的增刪改查,都會造成底層數據節點的變動,進而影響從數據節點到根節點路徑上的節點哈希值,最後生成出唯一的“世界狀態”。
在生成數據證明時,同樣是沿著樹根,通過鍵的比對向下索引,並把索引路徑上的節點打包成證明返回即可。驗證數據證明的時候,可以在數據證明中的節點路徑進行同樣的索引操作,驗證索引路徑的一致性,並且進行節點哈希值的正確性校驗,最後比對樹根的值即可。
▲ 優化思路
根據上文來看,默克爾B+樹確實可以實現較高的讀寫效率以及可驗證性,但是還有很大的優化空間,基於此,我們打算從優化磁盤讀的角度提出優化思路。
對於節點限制在4K大小這點,可以有效提高節點分叉數,降低樹高,進而降低磁盤IO次數,但是仍然需要log(n)次的磁盤IO,為了最大化降低IO次數,我們把索引節點與數據節點分開存儲為索引文件和數據文件。索引節點中可以認為只存放了鍵,因此索引文件遠遠小於數據文件,把索引文件通過mmap(內存映射)的形式維護在內存中,這樣對底層的數據的讀取只需要數據文件的一次磁盤IO即可,大大提升了讀效率,在聯盟鏈讀多寫少的場景下具有較大的優勢。
【小結】
本文是存儲系列推文的延續,主要闡述了區塊鏈中數據證明的實現。
首先介紹了對狀態數據做數據證明的背景需求,並以以太坊為例,詳細介紹其狀態數據存儲結構MPT,闡述了在MPT上數據證明以及驗證的實現,並進一步分析了以太坊的性能瓶頸。
針對聯盟鏈讀多寫少的場景,本文提出了一種以默克爾B+樹為基礎的解決方案,解釋了在默克爾B+樹上的數據證明以及驗證的實現,並且為了進一步提高性能,提供了優化思路,通過索引與數據分離的方式來完善可用性。
作者簡介
鄭柏川趣鏈科技基礎平台部區塊鏈存儲研究小組
參考文獻
[1] https://github.com/ethereum/go-ethereum
[2]https://en.wikipedia.org/wiki/Merkle_tree
展開全文打開碳鏈價值APP 查看更多精彩資訊