
網絡安全法、個人信息保護……遇上隱私計算技術,將會碰撞出怎樣的火花?本文為您詳解隱私計算技術之聯邦學習。
3 聯邦學習中的數據安全問題
回顧聯邦學習的起源,它同時具備兩個動機:解決“聯邦”場景下的方法框架問題,以及解決隱私保護問題。前面兩節分別介紹框架部分的方法與局限性,本節介紹隱私保護中的數據安全部分,而模型安全部分則放到下一節介紹。
需要指出的是,通常所謂的“數據不出門”是一個不夠嚴謹的說法:它只是表明原始數據本身不會被傳遞。但出於“有用性”要求,要絕對防止信息洩露卻並無可能[13];因此,在前面介紹的各種聯邦學習方案中,與原始數據密切相關的信息不可避免要發送出去,從而使得攻擊者或“誠實但好奇”的參與方有可能根據這些信息反推原始數據或提取與原始數據有關的信息,導致各種安全問題。
因此,仍需對各個應用場景的安全需求進行分級,並根據實際需要和資源約束情況選擇使用相應的安全協議。數據安全算法主要是各種多方安全計算(MPC)協議,實際應用中也有非MPC的協議。按照所能提供的安全保證,可以對這些方法作如圖表4所示的區分。
接下來,我們按照安全保證級別從高到底分別介紹代表性的協議。
圖表4 聯邦學習中常見數據安全協議的保證級別
3.1 惡意多數安全:SPDZ協議
SPDZ是一個先於聯邦學習而存在的多方安全計算協議,讀作[Speed-Z],為四位發明者姓氏首字母拼合而成,最早發表於2011年[14],後來又先後優化為SPDZ2[15]以及MASCOT[16]。協議分為不涉及被計算數據和邏輯的預處理階段,以及需要數據和計算邏輯的“在線”階段。在線階段很高效,因此後續的效率升級都是針對預處理階段。
SPDZ的基本方法是秘密分享。假設有n個參與方,第i個參與方Pi持有被分享數V的一個分量Vi,而所有這些分量加起來1等於被分享值:
1一般需要在域上計算,本文從略,下同
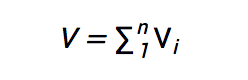
跟加性秘密分享方法(見3.5)不同的是,SPDZ能夠同時支持加法和乘法,構成了完備的多項式計算能力。在秘密分享的基礎上計算加法很簡單,各參與方對自己掌握的分量執行相加運算即可;但計算乘法需要打開所謂的Beaver乘法三元組[17]。
這是符合乘法關係的三個數,由各參與方秘密分享持有,一般在預處理階段生成。使用三元組存在較大的網絡通信開銷。 SPDZ協議使用消息鑑別碼機制和承諾協議,能夠在惡意多數情況下保證作弊行為極大概率會被發現(統計安全性);並且這個保證無須依賴公信第三方來提供。
這使得SPDZ協議特別適合在具有潛在業務競爭關係或者彼此信任度不是特別高的機構間開展聯邦學習合作。而在線計算所需之Beaver乘法三元組則在預處理階段生成,同樣無須公信第三方;由於相關技術比較複雜且多次優化,此處不作介紹。在部署上,各參與方可以直接作為SPDZ節點參與,也可以採用兩個、三個或多個SPDZ安全計算節點,供各方以秘密分享的方式提供數據給節點作進一步計算。
在實際應用中,由於SPDZ僅支持加法和乘法,存在較大局限性,特別是在處理ReLU、MaxPooling等函數的時候。例如,TensorFlow Encrypted對SPDZ的實現(Pond)使用了切比雪夫多項式近似方法來逼近ReLU函數。如果場景允許放寬安全要求,則可以考慮採用ABY3或者SecureNN協議。
3.2 惡意少數安全:ABY3協議
ABY3協議框架基於三方安全計算,協議框架中三個服務器是彼此對等的。在安全性上,ABY3能夠抵抗最多一個惡意參與方而保證安全性,即在惡意行為發生的時候能夠中止協議,在安全與效率之間取得了較好的平衡。
具體算法實現上,綜合採用算術協議(Arithmetic)、二進制協議(Binary)以及混淆電路協議(Yao,此處以姚期智院士的姓氏首字母代指其首創的混淆電路方法),在協議切換上有很多創新[18]。對二進制協議和混淆電路協議的支持使得ABY3能夠直接計算非線性函數,同時其獨特的乘法算法採用截尾方法(truncation)而不需要依賴Beaver三元組。
3.3 半誠實安全:SecureNN協議和Falcon框架
SecureNN協議和ABY3協議幾乎同時出現。其中,SecureNN為專門針對神經網絡訓練的需要開發。多個數據方提供的輸入數據被以秘密共享的形式分發給訓練服務器,而訓練出來的模型既可以繼續保持為服務器之間秘密共享的狀態,也可以重建出來。
SecureNN實現了ReLU函數的變種,並實現了其它非線性函數,包括ReLU,Maxpool,除法等,能夠滿足神經網絡訓練的現實需要[19]。 SecureNN配置了兩個安全計算節點P0和P1,以及一個協調節點P2。在大多數算法實現中,P0和P1持有被秘密分享的輸入值,而P2則負責協調協議的執行,包括生成必要的隨機數以及計算某些中間結果。特別是在矩陣乘法中,P2的一個任務是負責生成Beaver乘法三元組。 SecureNN僅能保證半誠實安全,而在存在一個惡意方的時候,僅能保證隱私不洩露,不能保證計算結果正確。 SecureNN不能支持惡意多數下的安全性,例如,P0和P1合謀即可恢復任何數據提供方的數據。
SecureNN另外有一個創新,任何兩個實體之間可以通過密鑰交換協議確定共享秘密,之後以該共享秘密為密鑰,使用偽隨機數函數(PRF)可以持續生成秘密分享的參數而無須持續通信,這能在一定程度上改善性能。
在SecureNN和ABY3的基礎上,疊加獨特的協議和算法創新,普林斯頓大學、微軟研究院、Algorand基金會、Technion聯合開發了Falcon框架[20]。根據其作者的介紹,Falcon在推理應用上的計算速度為SecureNN的八倍,比肩ABY3,通信效率則為前兩者的數十倍。
在模型訓練應用上,計算速度以及通信效率也有多倍提升。使用Falcon的開發者既可以選擇惡意安全(允許最多一個惡意方並在發現惡意行為的時候中止協議),也可以選擇半誠實安全性並獲得更好的性能。除了其優異的安全計算性能,Falcon還能較好地支持參數數量高達上億的大型網絡。 Falcon使用三個對等服務器。訓練和模型預測應用均由這三個服務器完成,訓練出來的模型以秘密分享的形式保存在三個服務器上。模型應用的時候,查詢方提供的數據仍然以秘密分享的形式分別提供給三個服務器,從而保證了機密性。
3.4 公信第三方保證:Paillier同態加密技術及其安全與性能問題
基於公信第三方保證的技術和方法並不屬於多方安全計算,但現實中排除公信方無法存在的場景後,可能確實還存在一定的用途,需要結合具體應用場景分析。有部分聯邦學習框架在縱向聯邦中應用了Paillier加法同態方案[7],並且缺省使用了1024位加密強度。
這裡存在兩方面的問題:安全性和計算性能。 Paillier算法的加密強度可以參照RSA算法,而RSA的1024位在今天大約僅相當於80位對稱加密強度[21];根據一項2012年的研究[23],受其保護的相關數據有可能在肉雞網絡或者大型計算集群上被花費一年甚至更短時間破解;而考慮到這些年來的硬件進展,當下所需的破解時間恐怕還要大幅縮短。提高密鑰位數是一種應對方法,但這涉及到Paillier算法的計算性能問題。
如果密鑰長度提升到當下可接受的水平即2048位,則對應的Paillier算法需要計算4096位的模指數,預期性能較低。在普通的工作站上,實測解密性能每核心僅為每秒數百次(參照RSA 4096簽名性能;使用openssl speed rsa命令測試,測試期間CPU運行頻率為4.2 GHz,OpenSSL版本為1.1.1f)。
3.5 無保證:加性秘密分享協議
在一些開源軟件中,橫向聯邦學習方法被簡化,每個參與設備所計算出來的權重更新數據被匯總到服務器;在服務器那裡,這些數據被簡單疊加求和,以便得到該輪訓練所產生的模型更新量。這並非[4]所提出的加權疊加算法FedAvg,但由於其被應用於部分開源的隱私計算框架,有一定影響力,故略作介紹。為了防止服務器得到每個設備的權重更新數據進而推導出參與設備的私有數據,加性秘密分享協議給參與該輪訓練的所有設備都分配了一個隨機數用來和待匯總疊加的數相加,起到混淆的作用。這樣服務器看到的設備數據近乎隨機,無法從中得到有用的數據。
為了仍然能夠保證疊加出來的數值為正確,根據所分配出去的隨機數,另外計算一個能與所有這些隨機數的總和相抵消的數,提供給服務器,以便其在執行疊加操作後再用之抵消用來混淆的那些數,從而得到正確的疊加結果。
以上描述,可能輔以數學式子更加容易理解。假設n個設備參與聯邦學習,第i個設備Di有一個數Wi需要發送給服務器,而服務器需要將所有的這些數疊加起來:
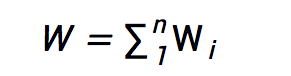
為了防止服務器得知具體的每個Wi,每個設備得到了一個隨機數ri,將之與Wi相加得到Ri = Wi + ri並發送給服務器。然後服務器計算:
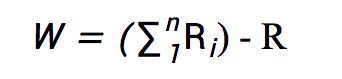
其中R是用來抵消所有的ri的,由安全的方法計算出來並分配給服務器:
不難驗證,通過在疊加結果中減去各節點用來混淆真實數值的隨機數,服務器能夠得到正確的匯總結果並且同時無法得知任何個別設備的更新值。加性秘密分享協議看上去很簡單,容易實現,然而它有很多問題。其中最重要的是影響模型質量:它不能以不同參與設備的數據量為權重來加權匯總模型更新值;如果不配合其它技術調整,甚至目前還沒有取得收斂性的理論保證,其應用也因此較為受限。 4 聯邦學習中的模型安全問題模型安全問題有別於數據安全問題。就聯邦學習而言,數據安全著重保護的是計算過程中交換的各種數據本身的安全性。而模型安全典型問題則為,惡意方可能通過偽造數據、篡改梯度更新數據等手段對訓練過程或者所訓練出來的模型加以攻擊,使其產生錯誤的分類或者預測;同時,訓練出來的模型也有可能“記住”某些數據特徵,從而以某種方式導致隱私洩露。本節簡要介紹目前已知的模型安全攻擊手段。有些技術不一定是是專門針對聯邦學習的,甚至先於聯邦學習而存在,但聯邦學習獨特的、引入了多個利益主體的開放架構,使得攻擊面比集中式機器學習大為擴大。 4.1 數據投毒數據投毒是指通過污染、變造數據等手段,影響最終模型的性能。[24](2004年)和[25](2005年)已經研究如何在存在攻擊者進行數據投毒的情況下(例如,在垃圾郵件中混入大量“好”詞),保持垃圾郵件過濾器的質量。構造對抗樣本可以認為是一種數據投毒手段。使用傳統的系統安全或者通信安全技術無法從源頭約束數據本身,因此防禦數據投毒的措施往往還需要落實在原始數據和協議上。數據方面,[26]發現,即使數據投毒用戶只佔較小比例,也能有效影響模型的性能,並且其毒化效果在訓練的後期較為明顯。考慮到有毒數據所造成的模型更新具有一定的可識別特性,[25]提出,可以提取高維更新向量中的相關參數並利用主成分分析方法降維、分類後去識別惡意參與者。協議方面,[27]提出,差分隱私的學習算法能夠抵抗少量被毒數據,並給出了隱私參數與被毒數據量之間的具體量化關係。實際應用中,[25]所採取的明文讀取參與方的模型更新數據這個做法跟隱私保護的需求產生了衝突。可以考慮綜合採用可信計算技術以及[26]所建議的差分隱私技術去解決這個衝突。我們將在第4.3節進一步介紹差分隱私技術,在第5.3節介紹可信計算技術。 4.2 模型投毒在聯邦學習場景中,由於模型更新數據可能來自惡意參與方,模型投毒成為現實威脅。雖然數據投毒也會造成模型更新數據的異常,模型投毒卻更具針對性,而且有可能通過精心構造模型更新向量來規避異常檢測方法。因此,使用可信計算技術來約束參與方的行為,使之不能脫離數據支撐而任意製造模型更新值,將成為基礎的防衛手段。後門攻擊是一種特殊的模型投毒手段[28]。攻擊者在維持模型的總體精確度的同時,更改模型在某些樣本上的預測結果,能夠達到隱藏其攻擊使之免被發現的效果。例如,黑灰產團伙設法攻擊一個通過聯邦學習訓練的風控模型,使其將該團伙的某些作弊特徵識別為正常用戶行為,則該團伙可以設法逃過風控系統的識別,同時系統的總體風險識別率似乎仍可接受。目前還沒有能特別有效防衛後門攻擊的算法手段[29]。 4.3 隱私數據推理攻擊方根據訓練過程中獲得的數據或者模型參數,試圖推算誠實參與方的隱私數據。數據方的梯度更新數據可以通過加密、多方安全計算或可信計算技術加以保護,避免隱私數據被從梯度更新數據中推算出來。在此基礎上,仍然可以考慮疊加其它技術進一步保護隱私,例如差分隱私和數據脫敏技術,以進一步保護數據;例如,需要防止的是模型訓練出來後有可能會“記住”某些數據特徵從而造成隱私洩露。差分隱私(DP, Differential Privacy)[13]是典型的先於聯邦學習已經存在的技術,甚至早於分佈式學習。 Dwork等證明,要絕對防止隱私的洩露是不可能做到的,這主要是由於有用性要求,即數據需要被使用,這不可避免會造成信息的洩露。因此,剩下的可能性是如何盡量限制相對隱私的洩露,這就是“差分”的由來:任何查詢結果一定程度上不應該能夠被用來推斷某個個體的數據是否被包含在數據集中。反映在其定義上則存在“相鄰數據集”概念。所謂相鄰數據集,指兩個數據集只相差一條記錄,而差分隱私則定義為相鄰數據集在一定程度上(以ε-δ計量)不可區分[13];在橫向聯邦學習的場景中,相鄰數據集也可以指數據集D1和D2僅相差某個用戶或者某台設備所貢獻的數據[30]。除了差分隱私,脫敏技術也是應該考慮的一個方面。涉及個人隱私的數據如詳細的住址、電話號碼、身份證號碼等,受到法律的嚴格保護。一般而言,這種數據也不會對擬建立的模型能有直接助益,可以從數據中刪除或模糊化而不影響模型的預測性能。 4.4 模型竊取聯邦優化算法、(橫向)聯邦學習算法,以及後來的其它文獻所提出的算法,都沒有考慮全局模型分發給參與方之後的保密問題。 SPDZ,ABY3,SecureNN和Falcon較好地解決了全局模型的保密問題,但是無法直接對模型更新值進行異常檢測或者主成分分析,需要另外採取措施防禦數據投毒。 5 聯邦學習的應用建議以上介紹了聯邦學習的基本方法,以及其中所涉及到的模型質量、數據安全、模型安全和隱私保護問題。希望讀者讀完後對聯邦學習的全貌能有初步了解。接下來,我們給出一些具體可操作的落地應用建議。 5.1 落地應用1+3我們把聯邦學習的應用過程高度簡化為1+3。其中,1指的是一個公式:聯邦學習= 機器學習+ 數據安全這個公式首先回答了“聯邦學習是什麼”這個問題:它首先是一個機器學習的技術,並且疊加了多個機構協作共同建模和利用模型所需要的數據安全技術(模型質量和模型安全問題在現階段可能是第二位的)。通過這個公式,可以初步判斷相關的場景是否需要使用聯邦學習技術。確定需要使用聯邦學習技術之後,我們需要回答如下3個問題以確定總體方案:第一個是數據維度分佈:參與各方是否具有同樣的數據維度?這決定我們需要應用橫向還是縱向的聯邦學習技術。當然也可以考慮分割型神經網絡;第二個是確立安全需求:有沒有外部數據合作方,有的話,對方是十分可信,還是說有可能藉機竊取數據?這決定我們需要應用惡意多數安全的協議(SPDZ或其升級版本),還是惡意少數安全的協議(ABY3),還是半誠實安全的協議(SecureNN)。如果是供應商自行研發的安全協議,可以要求供應商提供帶安全證明的已發表論文。另外,監管機構可能會在跨境數據合作場景中要求惡意多數安全的協議,即便場景僅限於同一家集團公司國內外業務部門之間的合作。第三個是模型歸屬問題:訓練出來的模型歸其中一方所有還是共同所有?模型體現了數據的價值,其歸屬及管理均關涉各方利益。例如設想一個貸款需求或信用卡分期需求預測模型,如果根據某個銀行的數據訓練出來之後的模型被其競爭對手獲得,這相當於數據使用權的流失,還可能進一步導致優質客戶流失。釐清1+3之後,我們就確立了聯邦學習落地的初步方向。當然,剩下的一些問題也同樣重要。 5.2 設立性能基準為了確定聯邦學習的模型性能、準確計量應用聯邦學習技術所產生的收益等,需要設立相應基準。例如,一家銀行以僅靠自有數據作信用卡分期需求預測作為基準,對比使用聯邦學習技術聯合外部數據作建模以及預測,可以評估外部數據以及聯邦學習技術在提升預測準確性方面的性能,進而評估項目的實際財務收益。另外如果數據可以合規獲得,也可以對比測試聯邦學習和集中式學習,以便確定聯邦學習所訓練出來的模型質量相比集中式學習是否有較大差距。 5.3 考慮採用可信計算技術除了前述基於軟件、算法的解決方案,還可以結合使用基於硬件的可信計算技術作為補充,或者作為某些環節提升安全性的輔助手段。可信計算技術基於可信執行環境(TEE,Trusted Execution Environment)。 TEE有多種實現,每家的威脅模型和安全設計均有所不同。其中Intel SGX技術和ARM TrustZone技術可用於聯邦學習。雖然這些技術可能還存在一定的安全隱患,例如側信道攻擊(Side Channel Attack);但只要聯邦學習系統的主要安全性並不依賴可信計算技術,則仍然可取。在橫向聯邦學習技術中,服務器往往會分發全局模型到各個移動設備。為防止攻擊者嘗試模型投毒或者其它攻擊,在移動設備端可以使用ARM TrustZone技術來保證客戶端的行為。 Intel SGX技術的威脅模型強大,安全假設少。通俗地講,SGX除了CPU以外誰也不信任。因此,如果不考慮可能的安全漏洞和側信道攻擊,攻擊者即便完全掌握了物理主機或虛擬客機的操作系統、底層主機系統固件,可以讀取和修改任意位置的內存內容,也無法得知運行在SGX安全圍圈(enclave)內的數據。 SGX安全圍圈範圍內的內存數據經過AES算法加密,並且僅能在CPU內部由對應的SGX安全圍圈解密。加解密當然會損失一部分性能,但AES的硬件實現十分高效,不會造成主要的性能障礙。 SGX另外能夠提供遠程認證能力,能夠保證安全圍圈上運行的軟件是經過認證的版本,沒有被篡改過。這在聯邦學習中特別重要,它能保證參與方的行為不會偏離約定的協議。例如,在梯度更新數據被通過多方安全計算技術提交聚合之前,可以放在一個前置的SGX容器中進行數據檢測,以保證檢測邏輯得到嚴格執行,同時又能避免聚合端檢測造成跟隱私保護要求的衝突;又如,SGX可以用來保證多方安全計算的參與方嚴格遵循協議約定,因此可以將原本要求惡意多數安全的協議放寬為惡意少數安全或半誠實安全。我們認為,一個強調安全性的聯邦學習方案或者產品應該提供SGX支持能力。總的來說,SGX通過內存加密能夠保護運行中的數據,也能認證應用使其免遭篡改,構成了一個可信的安全底層。在SGX的基礎上再根據安全需要疊加SPDZ、ABY3、SecureNN或者Falcon,能形成比較好的安全保護,極大提升攻擊門檻。目前,對SGX的支持已經被集成進Linux 5.11內核,不久將被各大Linux分發商以及雲服務商所支持。同時,經歷多年的工作站級支持後,英特爾公司已經在其主流服務器芯片中搭載SGX技術,其安全圍圈能夠使用最多1TB內存,幾乎不會再因圍圈換頁操作而導致性能下降。這也是英特爾公司的首款10納米芯片,代號Ice Lake,2021年四月份已經正式發布。在不遠的將來,使用SGX技術將無須另行購置硬件、配置操作系統。另外,神經網絡應用往往可以使用顯卡加速。而本來使用顯卡加速的神經網絡應用在遷移到SGX上以後,將因無法使用顯卡而使性能大降為原來的百分之二甚至更低。 Slalom提供了在SGX安全圍圈內計算深度神經網絡,同時能將全部線性層計算安全外包給顯卡的技術。 Slalom技術最高可達到僅用顯卡計算性能的40%[30]。 6 結語聯邦學習是一門仍在蓬勃發展中的學科,有很多可以改進的地方和未解決的問題。其中,數據非獨立同分佈所造成的質量影響,除了可以進一步開展學術研究,也需要結合具體應用場景進行評估、測試,如果實際影響不大而使用聯邦學習的收益相比更大,亦可容忍。至於數據安全和模型安全,讀者需要了解其中存在的問題,並結合實際情況進行應對。希望本文的介紹能給讀者一個初步但全面的了解,保證落地應用中沒有大的方向性和安全性問題。接上篇:一篇搞懂隱私計算中的聯邦學習(上)參考資料:
[4] McMahan HB、Moore E、Ramage D 等。 從分散數據中高效學習深度網絡[J]. 人工智能與統計,2017:1273-1282。
[13] 德沃克 C. 差異隱私。 關於自動機、語言和編程的國際研討會。 施普林格,柏林,海德堡,2006:1-12。
[14] 帕斯特羅 V、Smart N、Zakarias S。 來自某種同態加密的多方計算。 密碼學 ePrint 檔案,報告 2011/535,2011。http://eprint.iacr.org。 2013 年。
[15] Damgård I、Keller M、Larraia E 等。 為不誠實的多數人提供實用的秘密保護 MPC – 或:打破 SPDZ 限制[C]// 歐洲計算機安全研究研討會。 施普林格柏林海德堡,2013:1-18。
[16] 凱勒 M , 奧爾西尼 E , Scholl P . MASCOT:更快的惡意算術安全計算與不經意轉移[C]// ACM SIGSAC 計算機與通信安全會議。 ACM,2016:830-842。
[17] 海狸 D . 使用電路隨機化的高效多方協議[C]. 年度國際密碼學會議。 施普林格,柏林,海德堡,1991:420-432。
[18] 莫哈塞爾 P,林達爾 P。 ABY3:機器學習的混合協議框架[C]// 2018 年 ACM SIGSAC 計算機和通信安全會議論文集。 ACM,2018:35-52。
[19] 瓦格 S,古普塔 D,錢德蘭 N。 SecureNN:用於神經網絡訓練的 3 方安全計算[J]. 隱私增強技術論文集,2019 年,2019 年(3):26-49。
[20] Wagh S、Tople S、Benhamouda F 等。 FALCON:用於私有深度學習的誠實多數惡意安全框架。 arXiv 預印本 arXiv:2004.02229。 2020 年。
[21] 巴克 E、貝克 W、伯爾 W 等人。 密鑰管理建議:第 1 部分 – 總則,修訂版 5。國家標準與技術研究院,技術管理局。 2020:54-55。
[23] 伯恩斯坦 DJ、海寧格 N、朗格 T。 FactHacks:現實世界中的 RSA 分解。 混沌計算機俱樂部 29C3, 26. 2012。
[24] Dalvi N、Domingos P、Sanghai S 等人。 對抗性分類[C]. 第十屆 ACM SIGKDD 知識發現和數據挖掘國際會議論文集。 2004:99–108。
[25] 洛德 D,溫順 C。 對統計垃圾郵件過濾器的好詞攻擊[C]// 電子郵件和反垃圾郵件會議。 DBLP,2005 年。
[26] Tolpegin V、Truex S、Gursoy ME 等。 針對聯邦學習系統的數據中毒攻擊[M]. 歐洲計算機安全研究研討會。 施普林格查姆。 2020 年:480-501。
[27] 馬雲,朱新,許傑。 針對差分私人學習者的數據中毒:攻擊和防禦。 arXiv 預印本 arXiv:1903.09860。 2019 年。
[28] Bagdasaryan E、Veit A、Hua Y 等人。 如何為聯邦學習提供後門。 人工智能與統計國際會議。 2020 年:2938-2948。
[29] Kairouz E、McMahan HB、Avent B 等人。 聯邦學習的進展和未解決的問題。 機器學習的基礎和趨勢®,2021 年,14(1-2):1-210。
[30] McMahan HB、Ramage D、Talwar K 等。 學習差分私有循環語言模型。 arXiv 預印本 ar
作者簡介郭偉基:原美國運通在中國境內合資銀行卡清算機構——連通(杭州)技術服務有限公司創新技術部負責人,總監,主要從事前沿創新技術如隱私計算、聯邦學習、同態加密、智能合約等在金融支付、風險管理、精準營銷等方面的應用。內容旨在信息傳遞,不構成任何投資建議。
展開全文打開碳鏈價值APP 查看更多精彩資訊