

探索鏈外計算採用偏中心化等手段能夠得到更高的擴展性摘要
Web3.0時代,互聯網底層不會全部基於區塊鏈構建,數據計算也不會全部跑在公鏈的“獨木橋”上。考慮到數據計算的效率問題、以及不同底層程序語言環境,Web3.0時代的數據計算基礎層將是複雜多樣的環境。因此,如何破解區塊鏈時代數據計算效率成為下一代計算範式的重點方向。
Web3.0時代的區塊鏈基礎設施,光靠共識機制創新以及跨鍊是遠遠不夠的,脫鏈/鏈外計算(off-chain)目前已經成為解決問題的大趨勢。由於不可能三角的束縛,探索鏈外計算採用偏中心化等手段能夠得到更高的擴展性,這種方案的關鍵是如何將鏈外計算結果在鏈上得到一致共識,通過TEE、零知識證明等技術手段實現鏈外數據計算結果回到主鏈上達成一致共識和安全。本報告分析以Oasis、Arweave、Mina等鏈下計算模式為案例,分析了Web3.0時代數據計算的可能範式,以及如何實現鏈上鍊下、鏈間數據計算協同的可能方式。
圍繞性能的升級,公鏈的演進大致經歷瞭如下歷程:
1)共識機制的探索。共識機制經歷了從POW到POS、再到各類POS機制的改進版本,無非是想解決公鏈的擴展性問題,但依然受不可能三角束縛;
2)跨鏈試圖以多鏈來承載應用。跨鏈則是為了考慮一條公鏈不能適用於所有場景,需要多個公鏈來解決數據承載和計算運行。跨鏈依舊要對束縛行業的不可能三角進行相應的平衡;
3)Off-chain(脫鏈計算、鏈外計算)來解放主鏈負擔正在成為趨勢。從以太坊2.0的分片到L2網絡,全部工作無非圍繞如何解放主鏈負擔來進行。整體上的思路就是脫鏈/鏈外計算,把計算(存儲等資源消耗)與存證分開。脫鏈計算最核心的問題就是鏈上鍊下數據驗證問題,或者說,如何使鏈下的數據計算在鏈上得到共識,使得這種方式能夠被去中心化用戶相信。
本章節介紹Oasis、Arweave的SCP模式以及MINA生態的Snapp三個典型的脫鏈計算項目案例。從這些不盡相同的實現方式,可以窺見Web3.0世界的數據計算實現方案繁雜的真實一面。未來Web3.0世界,也許不是理想的公鏈獨木橋,而是紛繁複雜的百花齊放。
在Web2.5時代,如何將數據在兩個生態之間共享、程序如何跨兩個生態運行、兩個生態系統融合將是時代的剛需。將數據在中心化世界和去中心化世界共享,將催生預言機類應用的巨大需求。 Web2.0時代的數據和應用將在通往Web3.0時代的路上長期存在,並將不斷與Web3.0進行融合——數據將在所謂的新的Web3.0應用生態和當西Web2.0生態之間共享,應用程序將橫跨Web3.0和Web2.0系統之間運行(Web2.5時代),用戶將同時屬於兩個生態世界。另外,龐大的Web2.0時代的數據資產和計算方式將會繼續長期存在,這些勢必構成了Web3.0時代的一部分。對於這部分數據和計算如何與區塊鍊主導的新生態進行融合,同時數據的存儲、網絡和計算內存等互聯網基礎資源的調用該如何協調,這些都是巨大的挑戰。這方面的問題不是光靠跨鏈、預言機就能夠解決的。
風險提示:區塊鏈商業模式落地不及預期;監管政策的不確定性。
一、核心觀點
Web3.0時代,互聯網底層不會全部基於區塊鏈構建,數據計算也不會全部跑在公鏈的獨木橋上。考慮到數據計算的效率問題、以及不同底層程序語言環境,Web3.0時代的數據計算基礎層將是複雜多樣的環境。因此,如何破解區塊鏈時代數據計算效率成為下一代計算範式的重點方向。
對於去中心化系統,光靠共識機制創新以及跨鍊是遠遠不夠的,脫鏈/鏈外計算(off-chain)目前已經成為解決問題的大趨勢。由於不可能三角的束縛,探索鏈外計算採用偏中心化等手段能夠得到更高的擴展性,這種方案的關鍵是如何將鏈外計算結果在鏈上得到一致共識,通過TEE、零知識證明等技術手段實現鏈外數據計算結果回到主鏈上達成一致共識和安全。本報告分析以Oasis、Arweave、Mina等鏈下計算模式為案例,分析了Web3.0時代數據計算的可能範式,以及如何實現鏈上鍊下、鏈間數據計算協同的可能方式。
二、Web3.0的共識:公鏈獨木橋外可以做很多事
以以太坊為代表的公鏈在基礎性能方面的限制,光靠共識機制方面的創新是不夠的,靠多鏈之間的跨接亦不足以承載web3.0的數據和計算。於是以太坊2.0的分片、L2、波卡平行鍊等各類擴展方案成為當下現實的解決方案。這些方案細節盡不相同,但最終都傳遞了一種市場共識:即,Web3.0數據和計算不會都跑在公鏈這個獨木橋上,大量數據和計算處理會在公鏈之外實現(可以是L2、平行鏈,甚至可以是其他非區塊鏈方式)。也就是說,脫(主)鏈計算(off-chain)已經成為行業的共識,尤其是對於大量的數據處理和計算,會在主鏈之外完成。
本文暫時稱各類在底層公鍊主鏈之外的方式為鏈外計算。如何在公鏈之外建立有效的數據和計算平台,承載Web3.0各類應用成為未來重要的問題。
2.1.通往Web3.0之路:從共識機制、跨鏈、模塊化公鏈的探索
公鏈基礎性能是行業一個繞不開的終極問題。圍繞性能的升級,公鏈的演進大致經歷瞭如下歷程:
1) 共識機制的探索。共識機制經歷了從POW到POS機制,再到各類POS機制的改進版本,無非是想解決公鏈的擴展性問題。但無論怎樣的共識機制,完成一致性的共識勢必犧牲系統的工作性能,這是牢不可破的不可能三角;
2) 跨鏈試圖以多鏈來承載應用。跨鏈則是為了考慮一條公鏈不能適用於所有場景,需要多個公鏈來解決數據承載和計算運行。例如,波卡(Polkadot)作為一個可伸縮的異構多鏈系統,能夠傳遞任何數據(不只限於代幣)到所有區塊鏈,實現各個鏈之間資產與數據的互相流通。這對於區塊鍊網絡的擴展性和應用多樣性來說非常重要,單獨一條區塊鏈的性能畢竟有限,且在專用和通用之間難以平衡。同時,束縛行業的不可能三角(即擴展性、安全和去中心化不可能同時達到)也要進行相應的平衡。
3) Off-chain(脫鏈計算、鏈外計算)來解放主鏈負擔。從以太坊2.0的分片到L2網絡,全部工作無非圍繞如何解放主鏈負擔來進行。即,繁重的數據計算交給主鏈之外進行——可能是分片這類劃分任務群組的方式,或者L2、甚至是非區塊鏈系統來承載數據計算,最終結果返回到主鏈存證。主鏈的一致性共識提供數據結果的驗證,保證充分的去中心化和安全,而繁重的數據計算交給主鏈之外的平台進行。
雖然這些性能卓越的平台工作時犧牲了一些去中心化或者安全,但可以通過零知識證明、TEE等技術手段實現主鏈對鏈外平台的監督和驗證。整體上的思路就是脫鏈/鏈外計算,把計算(存儲等資源消耗)與存證分開。
近期,行業出現一個新提法:模塊化公鏈。類似互聯網協議分層,未來公鏈會分執行層(Execution Layer )、結算層(Settlement Layer)、數據可用性層(Data Availability Layer)。在以太坊上,執行層就是運行各類Dapp的L2,然後將打包的的交易數據(Rollup)返回到以太坊主鏈上做驗證上鍊,目前數據同樣是存儲到以太坊上(當然是做Rollup打包後),但對於日益膨脹的原始數據,有人考慮設立數據可用性層來存儲數據,進一步解放以太坊主鏈,使其只做驗證計算工作(共識)——畢竟,龐大的鏈上鍊下數據驗證問題數據存儲會進一步限制以太坊的性能。
當然,這種理想的分層方法還未得到驗證,包括Vitalik也對數據可用性層安全性提出了質疑的聲音。脫鏈計算最核心的問題就是鏈上鍊下數據驗證問題,或者說,如何使鏈下的數據計算在鏈上得到共識,使得這種方式能夠被去中心化用戶相信。

對於分片、L2和鏈外計算,公鏈就好比是貨物運輸管理嚴格的主幹道(一致共識),不可能所有數據都跑在主幹道上,支路的運輸車輛,通過零知識證明等手段證明自己工作嚴謹、可信的前提下,可以將繁複的鄉村毛細小路上的貨物打包裝箱後運行在主幹道上。如何向主鏈證明其數據結果可信,則要藉助零知識證明、TEE等靈活的技術手段,以適應不同的工作場景。

另外,龐大的Web2.0時代的數據資產和計算方式將會繼續長期存在,這些勢必構成了Web3.0時代的一部分。對於這部分數據和計算如何與區塊鍊主導的新生態進行融合,同時數據的存儲、網絡和計算內存等互聯網基礎資源的調用該如何協調,這些都是巨大的挑戰。這方面的問題不是光靠跨鏈、預言機就能夠解決的。
三、Web3.0數據計算:鏈外計算的三種模式
雖然數據計算脫離了主鏈,但分片、L2等技術手段還是考慮基礎數據計算依托區塊鏈,兼顧了去中心化的考慮。由於不可能三角的束縛,探索鏈外計算採用偏中心化等手段能夠得到更高的擴展性,這種方案的關鍵是如何將鏈外計算結果在鏈上得到一致共識,通過TEE、零知識證明等技術手段實現鏈外數據計算結果回到主鏈上達成一致共識和安全。
鏈外計算的核心問題是是脫離主鏈,數據計算如何獲得共識?也就是說,如何使得用戶相信主鏈之外的計算?
本章節介紹三個典型案例。從這些不盡相同的實現方式,可以窺見Web3.0世界的數據計算實現方案繁雜的真實一面。未來Web3.0世界,也許不是理想的公鏈獨木橋,而是紛繁複雜的百花齊放。
3.1. Oasis:共識層與執行層(ParaTime)分離的模塊化分層設計
Oasis網絡是一個運用權益證明(POS)、去中心化的Layer1區塊鍊網絡,其使用的模塊化架構實現了共識層和智能合約執行層ParaTime層兩部分的解耦合,即數據計算(合約執行)脫離了L1主鏈(即共識層),放在ParaTime層執行,且充分考慮了隱私計算。同時在設計上,對共識層進行了盡可能簡單化的設計,共識層僅處理Token的轉移、質押以及解綁定等較為簡單的操作,這一設計類似於以太坊Layer2項目將智能合約的執行與共識操作隔離相類似,均有助於提高網絡的安全性與效率。而在ParaTime層的設計上,Oasis將該層的各個ParaTime模塊相分離,不同的ParaTime模塊可針對不同的需求做出相應的優化調整,彼此之間互相獨立的完成運行。
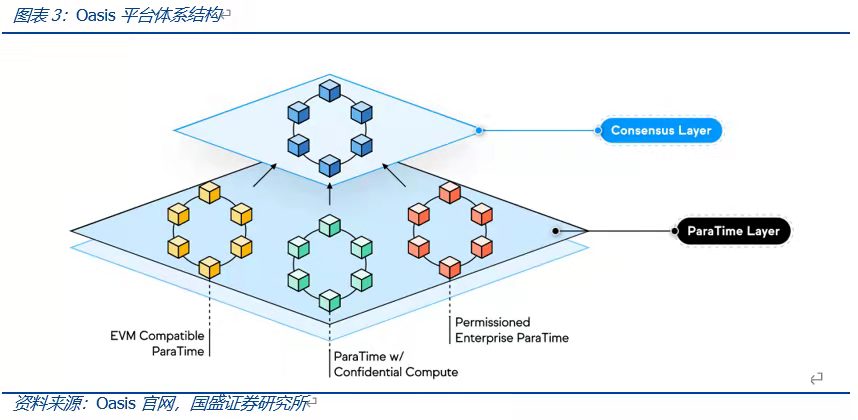
運行時,不同的ParaTime構建各自不同的執行環境、驗證機制以及加密機制,智能合約在ParaTime層完成執行後,將其結果值提交至共識層。共識層則從ParaTime層中接受各類參數值,並將這些值寫入下一個區塊之中,同時處理較為基礎的操作。而在運行過程中,若存在某個ParaTime的運行超載或出錯,其僅會影響出錯ParaTime提交到共識層的狀態更新,不會對其他ParaTime的運行產生影響。為防止某一ParaTime層惡意向共識層發送過多的垃圾信息導致共識層運行速度降低,每一ParaTime層必須向共識層支付交易費用,從而增加負載攻擊的成本。
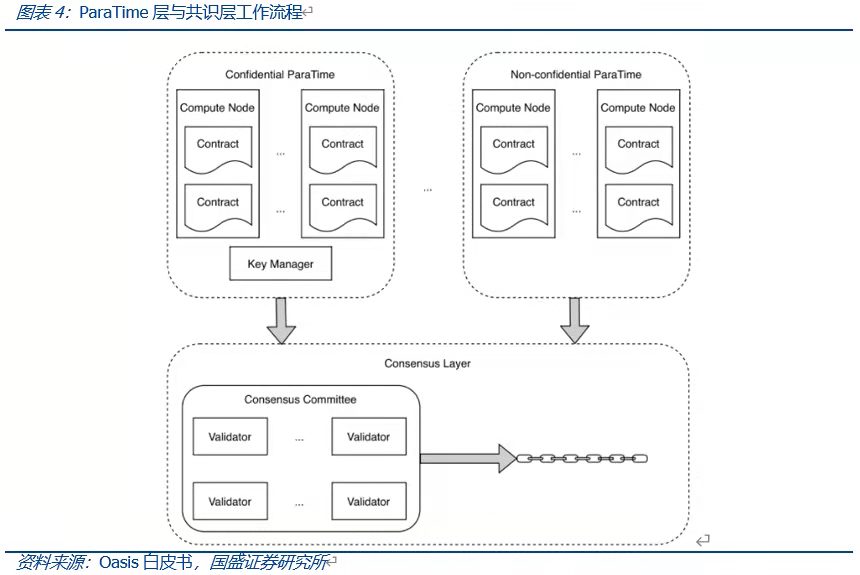
那麼ParaTime層如何與L1主鏈完成對接以及達成共識呢?在執行結果的驗證方面,Oasis採用差異檢測來對ParaTime的執行結果進行驗證。在執行差異檢測時,會從節點中隨機選擇計算節點組成計算委員會,當委員會所有成員同意結果時,則會接受結果。如若檢測到差異,則使用差異解析協議對其進行處理。差異檢測成本更低執行更快,而差異解析則往往會耗費更多的成本。具體執行過程中,計算節點首先將執行結果通過Gossip協議網絡發送到差異檢測器,檢測結果若無異常,則由驗證器提交至共識層完成處理和出塊。若是存在爭議,則會啟動差異解析協議來確定正確結果,並對產生爭議結果的節點進行懲罰,由爭議節點支付差異解析的成本。
不同的ParaTime在進行並行運算時,可以將每個結果同步提交至共識層,也可定期提交多個結果的融合值,以此實現ParaTime結果產出量與共識層出塊數量的解耦合。但其缺點在於無法確定不同ParaTime之間的相對順序,如ParaTime A產出的結果TA與ParaTime B產出的結果TB被同時提交至同一區塊,則無法判斷TA與TB的發生順序。除此以外,Oasis還支持通過IBC協議(鏈間通信協議,Inter-Blockchain Communication Protocol)為不同ParaTime間提供通信,通過TEE(可信執行環境)為平台提供更高的隱私和安全性。
隱私計算是Oasis的亮點。 Oasis網絡支持隱私計算基礎上的智能合約,充分體現了隱私計算的特點。在加密的ParaTime中,節點需要使用TEE(可信執行環境,Trusted Execution Environment)安全計算技術,TEE相當於為智能合約執行提供一個安全島。數據對節點運營商或應用開發者來說是完全加密的。計算層採用TEE可信執行環境運行智能合約,使Oasis網絡可以兼顧性能和隱私,且支持計算密集性應用場景,如近期流行的機器學習和深度學習。
總結而言,Oasis通過將共識層與計算層分離的方式,實現了節點功能的解耦合,從而大大降低了網絡各個節點的運行壓力,提高了平台的運行速度。同時TEE為數據計算提供了隱私與安全解決方案,在Web3.0時代有著豐富的想像空間。
3.2. Arweave:基於存儲共識的計算範式
Arweave(AR)通過去中心化的運行方式以及POA(Proof Of Access)共識機制為用戶提供數據存儲服務,同時向提供存儲服務的礦工給予AR獎勵。 POA實現的基礎為Arweave獨創的Blockweaves結構,每一區塊不僅與先前塊(Previous Block)相連,還同時與一個召回塊(Recall Block)相連,召回塊的生成則取決於先前塊的哈希值以及區塊高度。在決定出塊礦工時,礦工必須證明他們能夠訪問召回塊中的數據,從而獲得出塊權,進而獲得出塊獎勵。因此這就要求礦工1)盡可能多的複制各類區塊;2)盡可能的保存難以復制的區塊:3)盡可能的保存存儲人數較少的區塊,從而在開採新塊時獲得更多的優勢。同時由於區塊鏈特有的數據可驗證和可追溯的特性,能夠極大程度的確保鏈上數據的可信性,從而實現可信的永久存儲。
Arweave採用”一次付費,永久存儲”的模式。長期來看AR的存儲的成本非常低,甚至接近於零。且AR的存儲效率較快,因此,AR常被比喻為圖靈機的磁帶,就像磁帶一樣、以較低的成本存儲用戶數據。
因此,利用AR的高效、低成本的存儲,可以將數據計算放在鏈下進行,而數據源來自於AR鏈上、且計算結果也會存證上鍊。 SCP(基於存儲的共識範式,Storage-based Consensus Paradigm)正是實現基於AR的計算,即AR作為數據來源的圖靈磁帶,為鏈下應用程序提供數據源,計算結果亦上傳到AR存證。其效率決定於鏈下應用程序和計算機的性能,自然比基於共識機制的鏈上計算要高。
在以太坊等傳統Layer1上,計算、存儲以及共識等功能均由節點負責,通過POW等共識機製完成上鍊存證,而受不可能三角的束縛,其效率可想而知。而SCP則將鏈上存證與計算功能相分離。簡而言之,公鏈本身更像是計算機硬盤,只負責數據的存儲。在保證鏈上存儲數據可信的前提下,智能合約的執行則可以在鏈下任何具有計算能力的設備上進行。
SCP的理念源於SmartWeave,其為建立在Arweave上的智能合約平台,通過懶惰評估過程(The Process of Lazy Evaluation)將智能合約的執行負擔轉移到用戶身上。不同於以太坊每個節點都要執行每一筆交易(這樣的共識會影響計算效能),SmartWeave採用“惰性評估”系統,將交易驗證的計算交給用戶。當用戶與SmartWeave 合約交互時,他們會評估dApp 上的每筆先前交易,確認與鏈上存儲數據最新狀態一致,然後將交易結果寫入Arweave 網絡進行存證,如此重複。運行時,可將SmartWeave看作是鏈外運行的虛擬機。其通過讀取應用程序的代碼以及Arweave上的輸入參數,在本地完成交易的執行,之後再將輸出結果與Arweave同步,從而實現鏈上存儲與鏈下計算的分離。用戶的驗證工作類似區塊的鍊式結構,逐級追溯、驗證交易,而這一切並不需要在鏈上完成,而是用戶在鏈下完成的工作,也就是說,這個環節可以不受共識機制的束縛。

SCP的另一個開發實例是Arweave上的everPay。 everPay是一個跨鏈代幣支付協議,為用戶和商戶之間提供實時的代幣支付服務。 everPay將其他公鏈的各類資產鎖定在一個智能合約之中,並將其映射成相應的資產。如當用戶將資產從Ethereum跨鏈至Arweave時,首先由Coordinator收集和驗證交易,並將各筆交易放入序列化的待處理交易池中,隨後待處理的交易會被分批打包,每隔一段時間上傳至Arweave。此後Detector會對鏈上全局狀態以及賬戶餘額進行驗證,任何用戶都可以申請成為Detector節點。而Arweave上未經處理的交易則會由Watchmen來使用多重簽名或閾值簽名來完成,並將完成結果返回至Ethereum。因此,合約的執行均在鏈下完成,數據均存儲於鏈上,實現存儲與計算的分離。
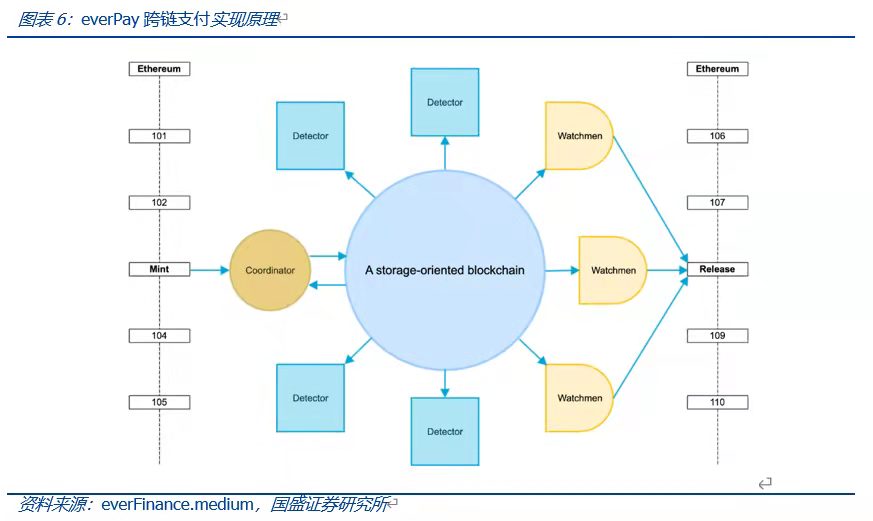
總結而言,基於存儲的共識範式建立起了Offchain-Dapp的原型。鏈上存儲,鏈下運行,充分發揮鏈上存儲可溯源、不可篡改的特性。在基於數據可信的基礎上,解放鏈上運行所帶來的的負載壓力,將其分散至用戶方,更合理的使用Web3.0資源的同時,提高Dapp的運行效率。同時,SCP的開發可以基於任何編程語言進行,且鏈下計算的效能提高了可用性和可擴展性,存儲成本低;同時,鏈下部署應用程序與Web2.0應用可以進行很好的對接。
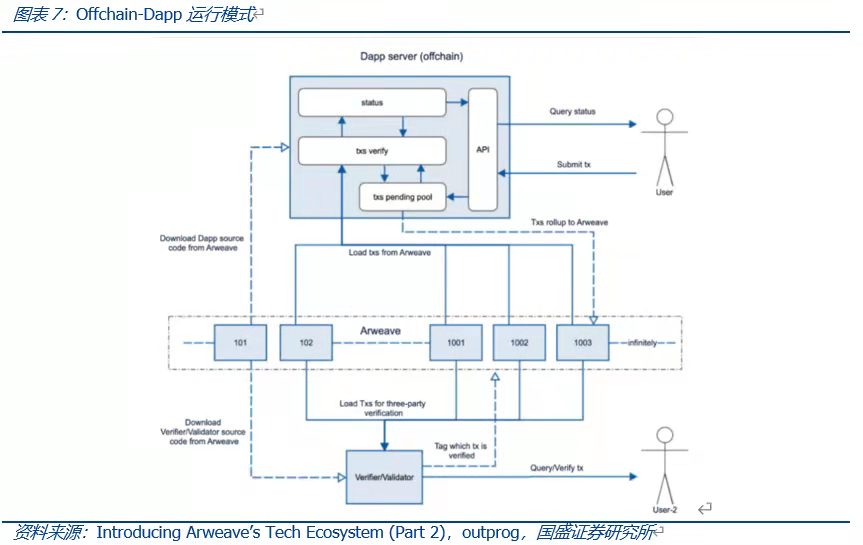
另外,如何確保鏈下應用程序執行的計算可信——即如何實現SCP的共識?數據來自於AR鏈上,應用程序也可以開源發佈在鏈上,因此,計算程序和數據均有鏈上存證保證,如果用戶本地修改應用程序和數據,那麼相當於形成了一次分叉,並不源數據和應用程序的計算結果共識。這一點與區塊鏈項目的開源代碼類似,礦工節點運行一樣的開源客戶端腳本,形成一致共識。如果對客戶端代碼(或者數據源)進行修改,那麼將形成一次分叉。因此,雖然運算是在鏈下執行,但來自於鏈上的數據源和開源程序代碼確保了鏈下結果可信。
3.3. Mina:零知識智能合約Snapp
在主鍊和外部應用環境之間進行數據計算協同工作,為了使得最終的結果達成共識,需要證明每次計算使用的數據與鏈上的區塊中數據一致。對於存儲在一連串歷史區塊中的數據,在主鍊和外部應用環境之間,如何以較輕便的、去中心化的方式來驗證數據的有效性? Mina作為目前最為輕量級的公鏈平台,通過遞歸零知識證明將區塊鏈替換為易於驗證、區塊大小恆定的加密證明,不必窮盡所有區塊,而以最新區塊(21kb左右)就可以實現驗證。這樣大幅減少了每位用戶需要下載的數據量,降低用戶點對點連接的門檻,提高了網絡的去中心化程度。
一般區塊鏈公鏈整個賬本數據量非常大(如比特幣賬近400G),且按照時間順序分散在很多區塊中,為數據驗證帶來較大是負擔。 Mina則使用遞歸zk-SNARK(零知識證明)實現驗證證明,只需要把每個區塊中的交易做一次驗證證明,然後將證明存入區塊中,且不會為每一個區塊單獨做一次證明,而是每一次新區塊做證明時連帶上一次的區塊證明一起生成一次證明,存入最新區塊。可以簡單理解為,類似套娃一樣,最新區塊將本區塊內的數據和前一個區塊的驗證證明數據一起做一個類似快照的證明。這樣,每一個區塊都只需要一個次證明結果,就可以將所有歷史區塊的數據證明包含在內。舉一個例子比喻,旅行者為了證明自己到過哪些景點,可以每到一個景點便打卡拍照,且下一次景點拍照時候手拿上一次景點照片一起拍照,如此遞歸下去,每一張照片都套娃式的包含了前面所有景點的打卡信息,那麼只需要一張最新的照片,就能夠證明該旅行者確實到過所有的景點。
這樣就實現了一種效果:區塊鏈上儲存的全都是交易正確性的證明,而非交易本身。因為前面說到的這種證明佔用空間很小,因此區塊的大小得以被壓縮。
在此基礎上,Mina開發了更具可延展性以及以隱私為中心的Dapp——Snapp。 Snapp由智能合約和UI界面兩部分組成。由於Snapp基於零知識證明(zk-SNARKs)構建,開發者需要構建證明者函數和相應的驗證者函數來生成和處理零知識證明。
證明者函數作為Snapp的一部分直接運行在用戶的web瀏覽器,當用戶與Snapp的UI界面交互時,用戶需要將私有數據輸入(PRIVATE INPUTS)和公共數據輸入(PUBLIC INPUTS)提交給證明者函數以生成零知識證明。

在生成零知識證明之後,不再需要用戶提供任何私有數據輸入,進而保護用戶隱私安全。驗證者函數則用於驗證零知識證明是否通過了證明者函數中定義的所有約束函數(也就是數據是否有效),一般由Mina網絡完成驗證。
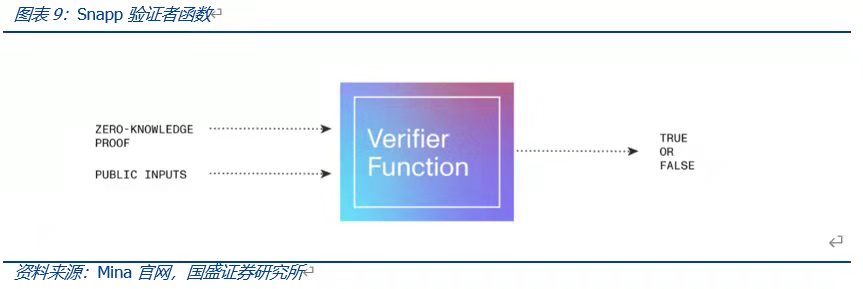
具體運行上,證明功能在用戶的web瀏覽器上完成,其生成的零知識證明(驗證密鑰)則會被存儲在給定Snapp賬戶的鏈上,之後發送至Mina網絡進行驗證。因此,交易的生成和數據計算在鏈下完成,同時該過程會生成可用於驗證交易的零知識證明,而用戶原始私有數據隱私是得到充分保護的。鏈上只負責對該證明進行驗證,通過驗證後將其上鍊保存,並對Snapp的狀態進行更新。
從用戶的角度來看,當用戶與Snapp進行交互時,用戶通過智能合約的前端UI與之進行交互,之後Snapp通過證明者函數將用戶輸入的數據在本地生成零知識證明,數據可以是私有的(不會被透明公開)也可以是公共(存儲在鏈上或鏈下)的。除此以外,還會生成與交易有關的Snapp狀態更新列表,用於更改Snapp狀態。之後用戶將數據提交至Mina網絡,Mina網絡會通過Snapp給出的驗證者函數對該筆交易進行驗證,成功通過後更新Snapp的狀態。
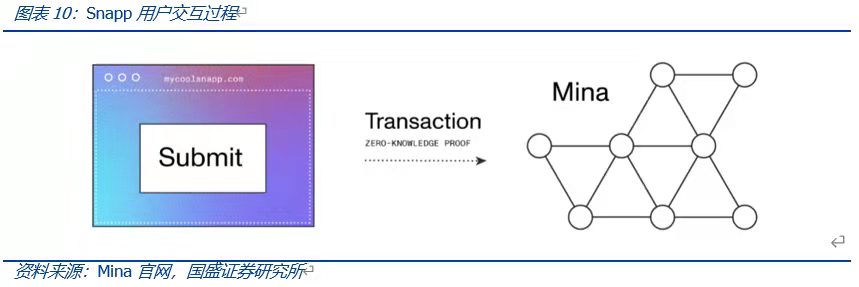
例如用戶可以將自己的徵信數據在本地生成證明並提交上鍊,可以在不洩露自身隱私數據的情況下,得到DeFi系統靈活的信貸服務;而傳統的DeFi借貸服務都是需要以資產的超額抵押為前提。這個應用場景的意義在於,將多個生態的數據和應用實現快速對接,這些生態可以是區塊鏈、也可以是鏈下生態。因此,Snapp應用可以很方便充當跨鏈、跨鏈上鍊下的橋樑角色。
3.4.小結
從上述三個案例來看,Oasis平台在設計時就考慮到了模塊化分層設計,因此在設計之初就完成了計算與共識的分層。而Arweave與Mina更類似使用分層解決方案來主動的將計算與存儲等功能進行分離,如Arweave的SCP與Mina的Snapp均是在公鏈運行一段時間後才誕生的。總結而言,前者為設計上的分層,後兩者為解決方案上的分層。拋開這兩類不同路徑的整體表現情況,對於現有公鏈而言,解決方案的路徑似乎能夠更快速的完成共識、計算與存儲的分層,並且能根據自身特點做出相應的調整。但如若分層與模塊化將成為不久將來的發展方向,前者的設計架構上的轉變似乎才能更好的面對時代的需求。
四、Web2.5時代的剛需:預言機
也許未來Web3.0的真是樣子難以預測,但毫無疑問的是,Web2.0時代的數據和應用將在通往Web3.0時代的路上同時存在,並將不斷與Web3.0進行融合——數據將在所謂的新的Web3.0應用生態和當西Web2.0生態之間共享,應用程序將橫跨Web3.0和Web2.0系統之間運行,用戶將同時屬於兩個生態世界。我們不妨將Web2.0向Web3.0過渡的時期成為Web2.5時代。
在Web2.5時代,如何將數據在兩個生態之間共享、程序如何跨兩個生態運行、兩個生態系統融合將是時代的剛需。將數據在中心化世界和去中心化世界共享,將催生預言機類應用的巨大需求。
Web2.0時代API接口成為App獲取外部數據的重要方式。 API接口即應用程序接口(Application Programming Interface)是一組預先定義好的函數或HTTP接口,其允許用戶或開發人員不訪問源碼而直接調用程序的例程。對於app而言,API接口成為了APP獲取外部數據以及輸出自身數據的窗口。而對於鏈上應用程序Dapp而言,由於區塊鏈本身確定、封閉的特性,Dapp一般無法直接獲取鏈外數據(如Dapp從Coingecko上獲取BTC實時報價)。預言機(Oracle Machine)正是區塊鏈外信息寫入區塊鏈內的機制,其本質是為智能合約提供外部信息的第三方服務,當智能合約請求鏈外數據時,由預言機將鏈外數據輸入鏈上。
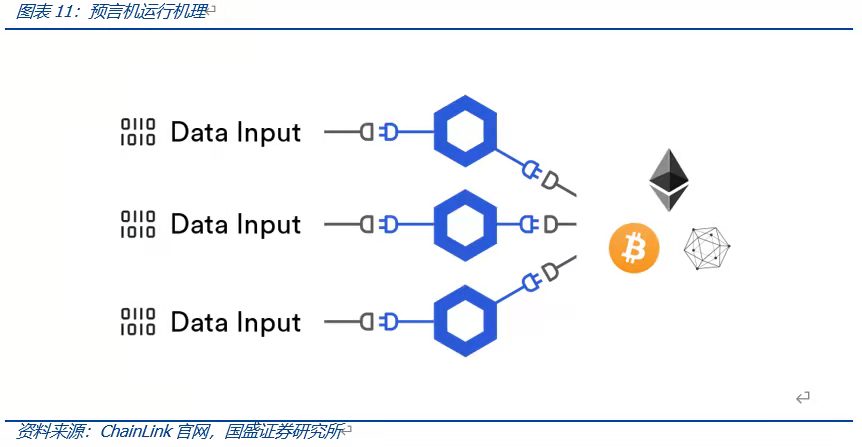
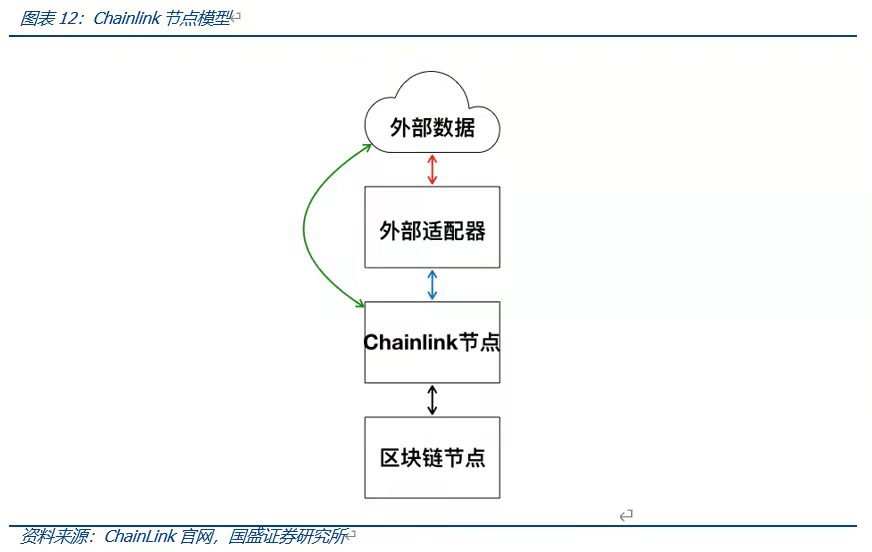
目前ChainLink為鏈上使用較多的預言機協議之一,其使用第三方預言機的方式運行,即在鏈上合約請求外部數據時,合約的請求將發送給預言機合約,之後預言機合約將相關事件發送給第三方的鏈下Chainlink網絡,由ChainLink網絡完成外部數據的收集工作,此後再次通過預言機合約將數據返回請求數據的合約。該方法的好處在於由Chainlink提供的第三方預言機通過預定的共識規則來確定結果能夠確保數據傳輸的安全性,然而無效冗餘(第三方預言機沒有API提供者直接提供外部數據高效)和缺少透明度(第三方網絡無法得知數據來源)的存在導致第三方預言機仍面對不少的挑戰。
API3為解決第三方預言機存在的問題,其採用第一方預言機的方式將API的提供直接交給了由數據提供商運營的預言機,組成dAPI,並通過DAO管理其數據饋送。

運行時,dApps訂閱dAPIs服務並支付相應的訂閱費,以此獲取數據或服務,當調用的數據出錯時,使用Staking Pool中的資金為訂閱支付賠償。 API提供著向提供dAPIs,各自運行各自的預言機服務,由API3 DAO向其支付相應的報酬。 Stakers通過質押API3 Token,為質押池提供保險金並參與API3 DAO的治理,主要包括選擇較為優質的服務商進入聚合器dAPIs。
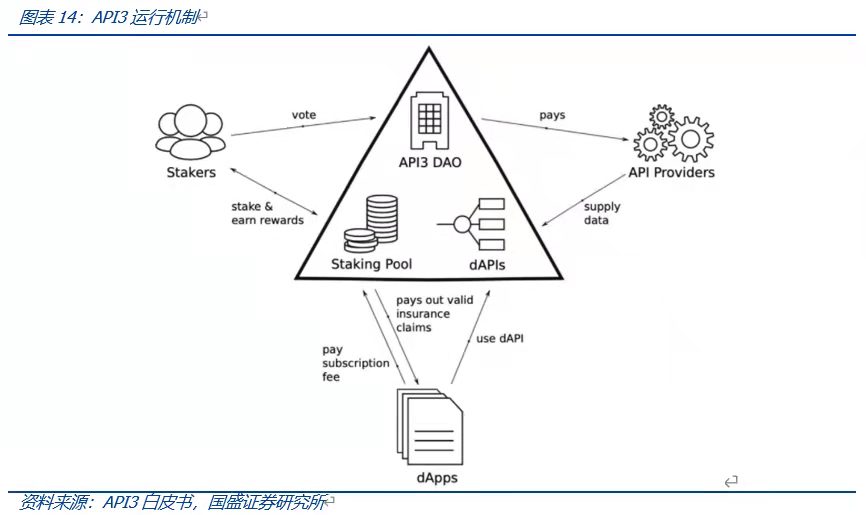
鏈下計算很重要的一點在於保證鏈上數據的可信性,如按照數據來源將鏈上數據分為鏈上產生和鏈下導入兩類,則需要同時保證該兩類數據的可信性。 API3等預言機協議的存在保證了鏈下導入數據的可信性,但是否存在一種更為高效的方式,將原本需要鏈下導入的數據直接交由鏈下計算,從而減少鏈上負載,還值得我們去探索。
展開全文打開碳鏈價值APP 查看更多精彩資訊
