
導語
隨著區塊鏈技術的逐步發展,區塊鏈與分佈式數據庫的聯繫愈加緊密和微妙。 2021年發表在SIGMOD會議(ACM Conference on Management of Data)上的這篇論文,從底層設計上對區塊鏈與分佈式數據庫的分類方法以及兩者的混合系統進行了分析。
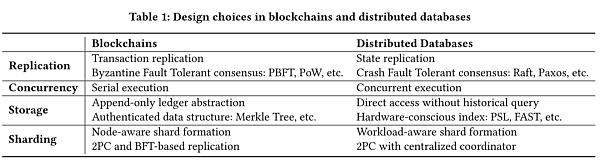
研究首先詳細介紹了用於描述區塊鏈、分佈式數據庫以及它們的混合系統的分類方法:從復制、並發、存儲和分片四個方面考慮;然後使用許可鏈Quorum、Fabric以及數據庫TiDB、etcd,設計性能實驗並細緻地分析了實驗結果;最後,給出了一個可以用於解釋和估計混合系統性能的框架。
論文題目:Blockchains vs. Distributed Databases: Dichotomy and Fusion
作者:Pingcheng Ruan, Tien Tuan Anh Dinh, Dumitrel Loghin, Meihui Zhang, Gang Chen, Qian Lin, Beng Chin Ooi
論文鏈接:Blockchains vs. Distributed Databases | Proceedings of the 2021 International Conference on Management of Data (acm.org)
區塊鏈與分佈式數據庫的介紹
從數據結構的角度來看,區塊鍊是一條由哈希指針串聯起來的區塊鍊錶,每個區塊中包含了一系列交易;從系統的角度來看,區塊鍊是一個由多個互不信任的節點共同維護一個全網一致的賬本的分佈式系統。
區塊鏈可以分為許可鍊和非許可鏈。其中非許可鍊是完全開放的,每一個人都有資格記帳、讀取數據,例如比特幣、以太坊。而許可鏈則有一定的准入機制和權限控制,例如Hyperledger Fabric。儘管早期區塊鏈的底層設計與數據庫完全不同,但是智能合約應用到了區塊鏈以後,用戶能夠自由地部署和運行圖靈完備的代碼,使得區塊鏈與數據庫之間產生了可比性。因此,論文將具有合約能力的區塊鏈與數據庫進行對比研究。
分佈式數據庫是一種數據存儲在不同物理位置的數據庫。多年來,傳統的關係型數據庫一直是主流。由於大數據處理和硬件發展等等的現實原因,為了實現系統的高可用性和可擴展性,分佈式系統開始進化,在這個新的設計趨勢下,出現了NoSQL和NewSQL。
NoSQL為了增強系統的可擴展性,拋棄了傳統數據庫的關係模型以及強ACID語義,NoSQL有著更加靈活的數據存儲結構,例如Key-Value(鍵值)存儲、列存儲、文檔存儲等等。 NoSQL的一致性較弱,可實現最終一致性、順序一致性或因果一致性等等。 NoSQL 的設計更加靈活,但加大了上層應用的複雜性。
NewSQL是介於關係數據庫與NoSQL 之間的設計,它保留了關係數據庫的數據模型以及對ACID 語義的支持,同時具有NoSQL對海量數據的存儲管理能力以及可擴展性。
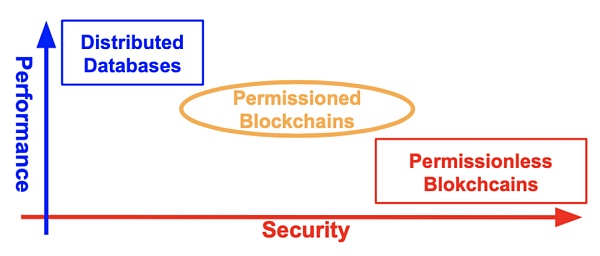
下圖顯示了分佈式數據庫與許可鏈、非許可鏈在安全與性能上的權衡。
分類法
論文提出的分類方法如圖所示。下面,從四個方面逐個進行介紹:
複製是將數據的副本存放在系統中多個節點上的一種技術。
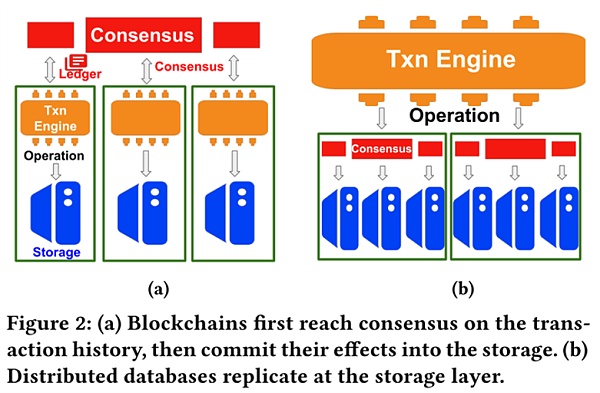
從復制模型的角度來看,區塊鏈複製了有序的事務(transaction)日誌,複製的單位是事務,事務中包含交易上下文、簽名、時間戳等應用級別的信息,且便於驗證。 “事務”一詞無論在區塊鏈還是數據庫中都表達為對於底層數據執行的邏輯計算,是一個操作序列。在區塊鏈中,事務表現為合約部署、調用這樣的形式,可以看作我們通常所稱的交易,例如,調用合約時將引起對數據的一個操作序列,這一序列操作具有原子性,要么執行完成,要么不執行,完成以後會使得系統的狀態發生改變。
分佈式數據庫則復制了讀寫操作的有序日誌,每次復制一個操作。如圖所示,需要一個可信的事務管理器進行協調,複製的單位是更細粒度的操作時,系統更便於實現並發。
從復制方式的角度來看,區塊鍊和分佈式數據庫可以選擇不同的方式進行數據複製。論文將復制方式總結為主備份複製和狀態機複製,其中狀態機複製又分為共識協議和共享日誌兩種。
主備份複製是指,副本中確定的某個主副本運行確定性狀態機,而備份僅存儲狀態。主數據庫通過處理操作計算一系列新的應用程序狀態,並將這些狀態按生成順序轉發給每個備份。也就是把主副本的整個狀態實時地傳輸到備用服務器;而狀態機複製則是讓每個副本都實現一個確定性狀態機。本質上是維護每個副本上操作或事務的有序日誌。每個複制副本從相同的初始狀態開始,然後以相同的順序應用日誌中的操作或事務。
基於共識協議的複制和基於共享日誌的複制區別在於,後者依賴於可信的外部服務提供一個共享日誌,從而在每個副本上執行這個日誌以改變狀態。
從故障模型來看,區塊鍊和分佈式數據庫需要解決的故障問題不同,這決定了兩者的共識層以及上層應用的不同特點。
在分佈式數據庫當中,節點屬於值得信任的內部系統,因而只需要容忍節點宕機,數據庫通常使用CFT協議(Protocols that tolerate crash failures),例如Paxos、Raft;而在區塊鏈中,各個節點需要在互不信任的情況下達成共識,因此需要容忍節點的惡意行為,因此區塊鏈常常會使用代價更大的BFT協議(Protocols that tolerate Byzantine failures),例如PBFT、PoW等。
如圖是CFT與BFT協議在不同的網絡模型當中所需要達到的網絡規模,同步網絡是延遲有界且已知的網絡,而異步網絡中的延遲可能是無限的。其中,f是故障節點的數目。
 並髮指的是讓交易或事務在同一時間執行。數據庫領域中的並發控制技術一直是研究熱點,好的並發優化能夠使得數據庫系統的性能大大提升。而區塊鏈中的交易常常是串行執行的,並發技術用得不多,主要原因在於,交易執行在很多區塊鏈系統中並非性能瓶頸,其次,由於交易常常會共用合約的狀態數據,因而串行執行交易更加簡單、保險。
並髮指的是讓交易或事務在同一時間執行。數據庫領域中的並發控制技術一直是研究熱點,好的並發優化能夠使得數據庫系統的性能大大提升。而區塊鏈中的交易常常是串行執行的,並發技術用得不多,主要原因在於,交易執行在很多區塊鏈系統中並非性能瓶頸,其次,由於交易常常會共用合約的狀態數據,因而串行執行交易更加簡單、保險。
存儲決定了系統中的數據存儲的機制。
在存儲模型方面,大部分的數據庫只存儲最新的可供修改的數據信息,即便有歷史信息,也只是作為節點故障恢復的日誌;而區塊鏈則存儲了所有的歷史數據,並且以只增的方式維護。
在索引方面,區塊鍊為了支持數據的正確性驗證,會採用類似Merkle Tree這樣的數據結構存儲數據;而分佈式數據庫則更關注性能,在建立索引時根據硬件的性質進行特殊優化,例如,硬盤中的數據以B+樹的數據結構存儲,而內存中的數據則使用對於多核並行和緩存更加友好的FAST 或PSL 等結構進行存儲。
分片在數據庫領域也是一種常用的技術,它將數據分佈到不同的分片當中,由分片中的節點進行處理,從而達到擴展系統或提升處理性能的目的。
分片形成協議決定了節點和數據應該分配到哪個分片。數據庫中可以根據數據的哈希計算結果、數據的範圍等進行分片,而區塊鏈更關注安全性,分片必須足夠大,從而避免惡意節點在分片中的數目超過安全假設,此外,分片的分配機制也不應該受到節點行為的影響。
分片的原子性要求跨分片的事務在它涉及到的所有分片中要么都提交,要么都中止,表現出行為上的一致性。在分佈式數據庫中,原子性一般由兩階段提交協議(2 Phase Commit,2PC)保證,這需要依賴某個可信的協調者,而區塊鏈中缺少這樣的協調者,因此會引入BFT協議來協調跨分片交易。
最後,根據所述的分類方法,論文還給出了一些系統設計的分析和對比。
性能實驗
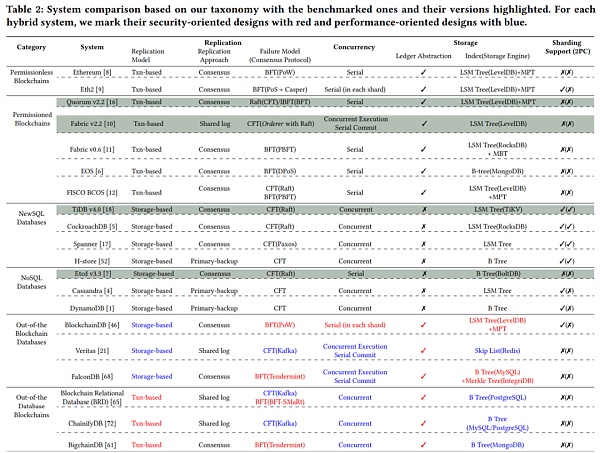
性能實驗主要選擇了兩個許可鏈系統Quorum、Fabric,兩個分佈式數據庫TiDB、etcd。
Quorum是以太坊的Go語言實現的一個分支,它在以太坊的基礎上添加了交易與合約的隱私性、許可管理以及基於Raft的共識機制,它以order-execute形式的架構打包區塊;Fabric是一個由Linux 基金會主辦的一個全球協作項目超級賬本中的一個子項目,它的架構模型則是execute-order-validate;TiDB是NewSQL數據庫,它繼承了大部分MySQL的特性,並由三個獨立的模塊組成:PD用於協調集群管理,TiKV用於KV存儲,server解析和調度SQL查詢;etcd是NoSQL數據庫,它使用kv數據模型,具有寬鬆的事務限制,側重於可用性和一致性之間的權衡。
為了公平比較,實驗讓所有系統中每個節點都有狀態數據的完整副本。對於Fabric,交易由所有peer節點執行和背書,排序節點固定為三個。 Quorum和Fabric使用Raft協議。
實驗從五個角度進行分析,分別是峰值性能,以及上述分類法的四個方面,即復制、並發、存儲和分片。
在峰值性能方面,區塊鍊和分佈式數據庫之間的性能差距相當大。
這裡用100K記錄填充每個系統,每條記錄大小為1KB。記錄僅更新和僅查詢的工作負載下的吞吐量和延遲。 TiKV作為TiDB底層的分佈式數據庫模塊,也參與了比較。
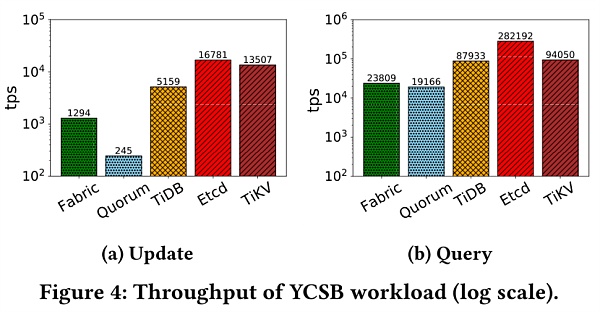
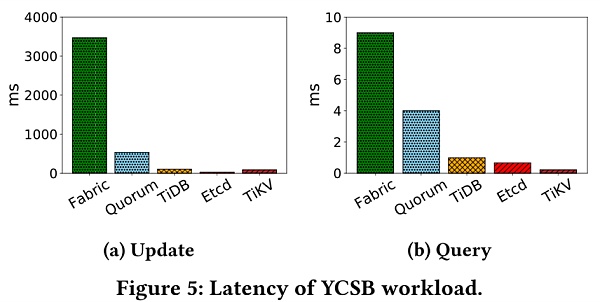
可以看出,NoSQL性能優於NewSQL,這是因為它們不會產生支持ACID事務的開銷。此外,TiDB的吞吐量比性能較好的的區塊鏈Fabric仍然高4倍。
在復制方面,基於事務的複制模型影響了系統的並發能力,這對系統性能的影響是主要的。
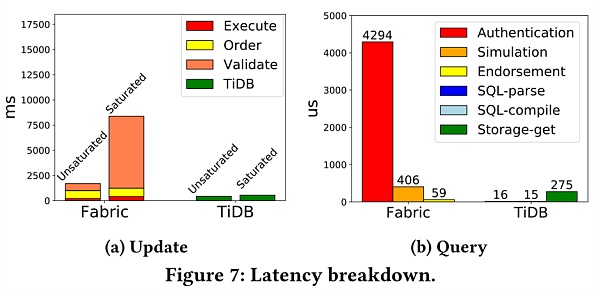
圖7根據Fabric和TiDB的性能表現,比較了基於事務和基於操作的複制模型的影響。除了與TiDB相比具有更高的延遲之外,當系統飽和時,Fabric的延遲也會顯著增加。而當請求速率超過系統容量時,驗證階段就會成為瓶頸。論文認為延遲增加歸因於Fabric中的串行驗證,區塊和區塊內的事務在提交以前是順序驗證的。
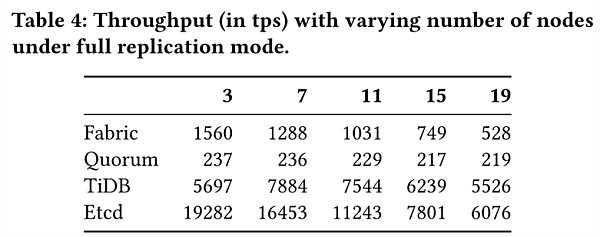
圖8給出了四個系統隨節點數目增多而變化的吞吐量。其中Fabric的複制方法是基於共享日誌的,其他則是基於共識協議的。 Fabric的吞吐量隨著節點數目增加而下降,在實驗中觀察到區塊驗證的延遲增加了,這是因為背書策略設置為所有peer節點都要對一筆交易進行背書。 Quorum使用raft協議,但是性能對節點個數不敏感,這是因為Quorum的order-execute架構,打包區塊的過程順序進行。
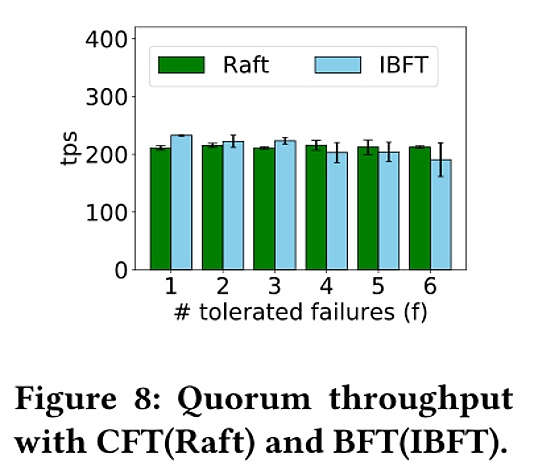
圖8表示在Quorum中比較了Raft和IBFT共識協議的吞吐量,以分析不同故障模型的性能影響。在規模更大的網絡中,IBFT的吞吐量方差更大,這是因為IBFT比起Raft,需要與更多的節點通訊以避免主節點切換,而惡意節點越多,重新選舉主節點的概率越大,事務中斷的概率就會變大。
在並發方面,execute-order-validate架構的區塊鏈在高競爭和高約束的工作負載下性能較低。

圖9給出了偏度對性能的影響。每個事務修改一項記錄,記錄的鍵值服從Zipfian分佈,分佈根據偏度係數θ變化,θ越大,表示修改衝突的可能性越大,競爭越大。可以看出,當競爭發生時,TiDB的吞吐量劇烈下降;etcd和Quorum串行執行事務,沒有並發控制;而Fabric性能下降了31%,這是由於Fabric對讀寫衝突的樂觀並發控制機制導致事務中止。此外,TiDB的吞吐量下降與事務中止率的增加不成比例,原因在於它的鎖存機制耗費了更多的時間。
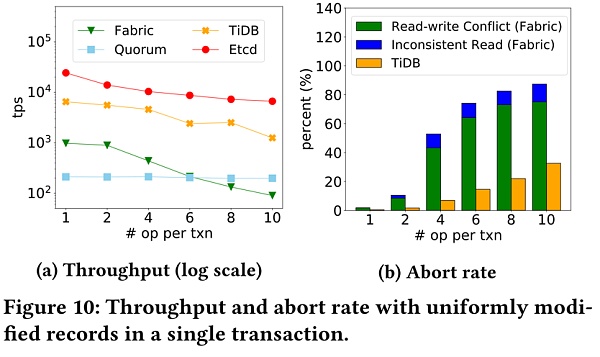
圖10增加每個事務中的操作數目以觀察事務原子性對性能的影響。從左圖可以看出,當每個事務的操作數增加時,Fabric、TiDB和etcd的性能有所下降。說明更多的操作導致了衝突,而且TiDB的事務還可能跨越多個分片;右圖顯示了TiDB和Fabric的隨操作數變化的事務中止率。 TiDB的事務中止主要是由於寫寫衝突,而Fabric中則來源於不一致的讀以及讀寫衝突,而不一致的讀可能是因為需要預執行和背書交易的peer節點提交區塊的速率不同。
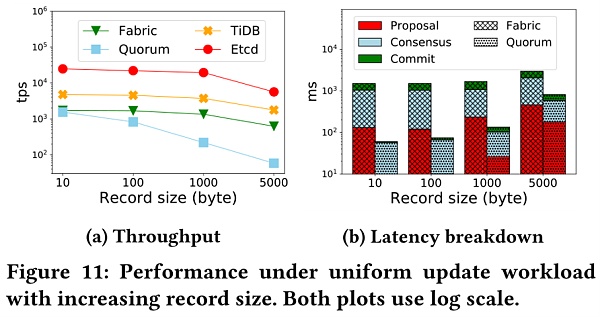
圖11顯示了記錄,即需要處理的數據的大小對於性能的影響,從左圖可以看出,隨著記錄增大,所有系統的性能幾乎都降低了。且Quorum的吞吐量顯著下降。右圖分析了Fabric和Quorum的事務延遲的細節。 Quorum在Commit階段由於重建MPT(Merkle Patricia Trie)數據結構而引入了哈希函數的成本,且Proposal階段與Commit階段的延遲同速增長。因為Quorum的order-execute架構使交易在打包區塊的節點和共識後的其他節點處都要進行串行驗證,相比之下,Fabric的串行處理只有一次。
在存儲方面,區塊鏈中的賬本抽像模型會帶來很大的存儲開銷,此外,避免狀態數據受到篡改所需的安全開銷則很小。
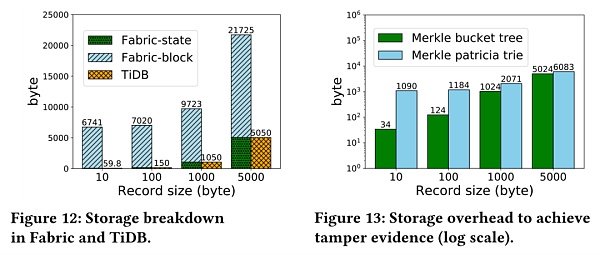
圖中顯示了記錄大小對於存儲開銷的影響。 Fabric的存儲開銷比TiDB高得多,這是因為Fabric中的區塊鏈的賬本鏈條抽像模型。右圖比較了Fabric中的MBT(Merkle Bucket Trie)和Quorum的MPT,MBT的開銷更小,因為它的樹結構規模是固定的。
在分片方面,由於分片的形成和周期性重新配置的安全要求,分片區塊鏈的性能遠遠落後於分佈式數據庫。
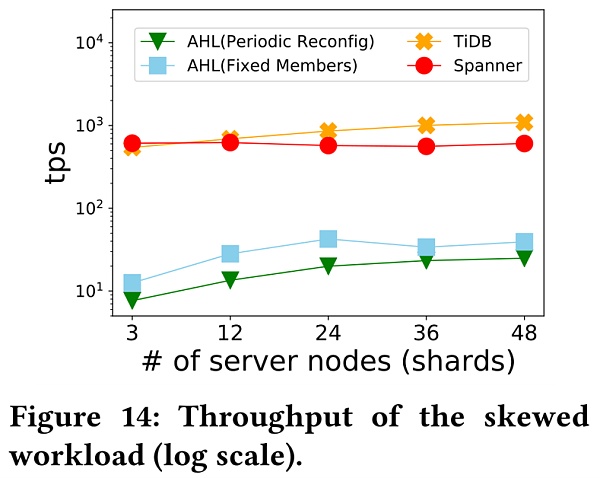
這裡使用了TiDB,AHL,以及Spanner。 AHL是基於Fabric的分片區塊鏈,Spanner則是基於雲的NewSQL數據庫。如圖14所示,當節點數目增加時,TiDB的吞吐量比Spanner更高,這是因為一旦檢測到衝突,TiDB會立即中止事務,而Spanner使用了悲觀並發控制機制,在事務衝突的情況下將爭奪鎖;與分片固定的AHL相比,定期重新配置分片的AHL為了實現更高的安全性,在性能上降低了30%。然而由於PBFT協議的高成本和其他安全開銷,AHL和數據庫之間的性能差距仍然很大。
分析框架
根據上述的研究分析,論文在最後提出了一個可以用於分析和預測混合系統的框架,不過,僅以吞吐量作為評價指標。
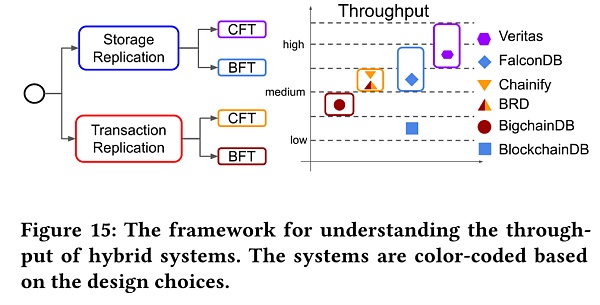
可以看到,複製模型和故障模型很大程度地影響了系統性能。基於事務的複制不像基於操作的複制那樣有較好的並發性,因此吞吐量低。而比起BFT協議,CFT協議的網絡開銷更低。
總結
這篇論文系統地探討和總結了區塊鍊和分佈式數據庫之間在設計上的差異,給出了由複制、並發、存儲和分片四個維度構成的分類方法,利用這種方法,給出了現有一些系統的設計取向的分析,並進行了對應的性能測試,用實驗結果說明了底層設計選擇對性能的影響,最後,還提供了一個用於評價和估計系統吞吐量的框架。整篇文章的工作完整詳實,有利於理解區塊鍊和數據庫之間的設計聯繫和區別,從更細緻和有條理的角度認識目前的區塊鏈與數據庫相融合的研究工作。
