本文轉自公號:老雅痞
作者:Eric Rescorla
最近,人們對通常被稱為去中心化網絡(dWeb)的東西很感興趣(儘管現在我們聽到更多的是Web3這個詞)。勾勒出這些術語之間的確切區別(假設這是有可能的)不在這篇文章的討論範圍之內(儘管Web3似乎在某種程度上涉及到區塊鏈),但這裡的共同點似乎是用一個不太中心化的網絡生態系統來取代現有的相當中心化的網絡生態系統。這篇文章探討了實際建立這樣一個系統所面臨的挑戰。
網絡的基礎設施至少在兩個主要方面是中心化的:
-
面向用戶的主要內容分發平台相對較少(Google、YouTube、Facebook、Twitter、TikTok等),它們顯然對網民傳播信息的能力具有巨大的影響力。
-
即使你願意放棄在這些內容平台上發布信息,建立任何大規模系統的最簡單方法(幾乎是唯一經濟的方法,除非你的資金非常充足)是在相對較少的基礎設施供應商之一中運行,如亞馬遜AWS、谷歌云平台、Cloudflare、Fastly等,他們已經擁有高度可擴展的地理分佈系統。
在這種情況下,去中心化可以意味著從建立那些以不太中心化的方式運作的特定內容平台的類似物(如Mastodon或Diaspora)到在IPFS或Beaker這樣的點對點平台上重建整個網絡的結構。自然,在第二種情況下,你也會想讓這些內容平台有可能只是更好重現!使用一個大部分或完全的點對點系統至少不應該要求在某個地方有一堆大的服務器來使這一切運作。這第二個更加雄心勃勃的項目是這篇文章的主題。
分佈式與去中心化的區別
這裡要做的一個重要區分是分佈式系統(通常也稱為聯合式)和去中心化系統(通常稱為點對點)之間的區別。舉個例子,網絡是一個分佈式系統:它由許多不同的網站組成,由不同的實體運營,但這些網站是在服務器上運行的,運營一個網站需要自己運行一個服務器或將其外包給其他人。這些服務器必須準備好處理所有用戶的負載,這意味著它們必須在某個地方有大量的帶寬,當更多的用戶試圖連接時,可以優雅地擴展,等等。
相比之下,BitTorrent是一個去中心化的系統:它使用BitTorrent用戶本身的資源來提供數據,這意味著你不需要一個巨大的服務器來發布數據到BitTorrent網絡,即使有很多人想下載它。即使在帶寬便宜的世界裡,這也有一些明顯的操作優勢,但特別是如果你想發布一些別人不願意發布的東西,也許是因為政府的審查制度或更經常的版權原因。如果你運行一個服務器,你很難隱瞞有一百萬人剛剛連接下載了某部電影,你應該擔心版權警察來找你,但如果你只是把你的拷貝發佈到BitTorrent網絡中,要想知道是誰發布的就難多了,特別是如果其他50人也這樣做的話。
請注意,有可能出現基本上是去中心化的混合系統(但它卻依賴於中心化的組件)。例如,在點對點系統中,新的對等節點通常需要連接到一些“引入服務器”來幫助他們加入網絡;這些服務器需要易於查找,並且要做到這一點,一種(儘管不是唯一的)方法就是中心化操作它們。
從歷史上看,點對點系統已經在相對有限的領域進行了部署,主要是那些與上述抵制審查的用例之外的某種部署有關。然而,人們對更廣泛的用例當然有很多興趣,包括取代網絡的大部分內容。這是一個非常困難的問題,部分原因是這種系統在本質上不如中心化或聯合式的系統有效和靈活。這篇文章探討了建立這樣一個系統所面臨的挑戰。這並不是說以更多的聯盟方式建立像Twitter或Facebook這樣的系統就沒有挑戰,但問題的規模不同(也許這是另一篇文章的主題)。
點對點架構與客戶/服務器架構的對比
與點對點架構相反的是客戶/服務器架構,也就是說,在一個系統中,各元素扮演著不對稱的角色,其中一個元素(通常屬於用戶[1])是“客戶”,另一個元素(通常是與某個組織相關的某種共享資源)是“服務器”。例如,這就是網絡的工作方式,客戶端是瀏覽器。相比之下,點對點系統被認為是對稱的。
然而,在實踐中,這些界限可能是相當模糊的。例如,常見的系統是在客戶端和服務器架構之間以及服務器之間使用相同的協議,第二種模式更像是典型的“點對點“配置。例如,郵件客戶使用SMTP發送電子郵件,但郵件服務器也使用SMTP相互發送電子郵件,發件人承擔“客戶”的角色;顯然在這種情況下,每個“服務器“既是客戶又是服務器,取決於郵件流向的方向。即使在名義上是點對點的系統中,也經常使用為客戶/服務器應用而設計的協議(如TLS),在這種情況下,即使上述應用是對稱的,節點也可能為這些協議的目的承擔客戶/服務器角色。
點對點系統的基本原理
我們都(希望)知道像網絡這樣的客戶/服務器發布系統是如何工作的,但點對點(以下簡稱P2P)發布系統是如何工作的呢?讓我們從討論最簡單的情況開始,也就是發布不透明的二進制資源(文檔、電影,等等)。本節試圖描述這樣一個系統的足夠的基礎知識,以便使本篇文章的其餘部分有意義。
在客戶端/服務器系統中,要發布的資源存儲在服務器上,但在P2P系統中,沒有服務器,所以資源存儲在“網絡中”。這在操作上的意思是,它存儲在碰巧此時在線的用戶的某個子集的電腦上。為了使其發揮作用,我們需要一套規則(即協議)來描述哪些端點存儲了特定的內容,以及當你想檢索它時如何找到它們。一個常見的設計是所謂的分佈式哈希表,這基本上很抽象,其中每個資源都有一個“鍵”(即一個地址),用來引用它,還有一個“值”,是其實際內容。密鑰決定了哪個(些)節點負責存儲該值,並被其他節點用來存儲和/或檢索它。
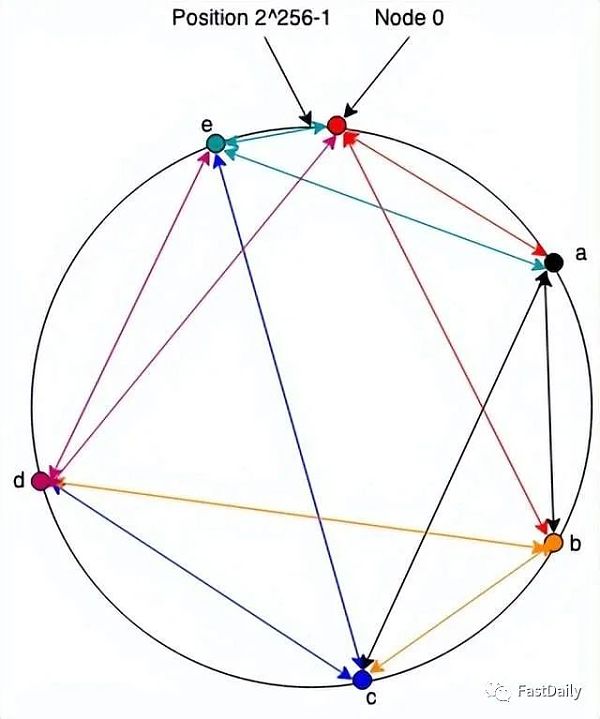
作為一個直觀的疑問,請考慮下面的DHT系統。這是Chord(在計算中,Chord是一種點對點分佈式哈希表的協議和算法。分佈式哈希表通過將鍵分配給不同的計算機稱為“節點”來存儲鍵值對;一個節點將存儲它負責的所有鍵的值。Chord 指定如何將鍵分配給節點,以及節點如何通過首先定位負責該鍵的節點來發現給定鍵的值。Chord 是與CAN、Tapestry和Pastry一起的四種原始分佈式哈希表協議之一)的過度簡化版本,它是最早的DHT 之一,所以我們稱它為“Note”。注意,系統中的每個節點都有一個隨機生成的標識符,它是一個來自0至2∧256 -1的數字(抱歉讀者們,我們用了LaTeX 表示法)。通常我們認為這些數字被組織成了一個環,ids 是順時針分配的,因此節點2∧256 -1 就在(之前)節點0旁邊,如下圖所示:
網絡中的每個節點(”環”)都保持著一組與環中其他節點的連接(箭頭的顏色是根據保持連接的節點而定)。我不會在這裡詳細介紹這些算法,只想說讓這些算法有效地工作是製作DHT的科學的重要內容。在註釋中,我們只假設每個節點都與下一個節點(即具有下一個最高身份的節點)和其他更遠的節點有一個連接,如上圖所示。
為了與具有id 的節點通信?, 一個節點向它所連接的節點發送一條消息?,並帶有id?最接近但不大於,(即,如果你順時針繞圈,你連接到的節點不會位於它們之間)。節點?做同樣的事情。當你最終到達一個直接連接到的節點?時,它傳遞消息。例如,如果節點0想向節點c發送一條消息,它將把它發送給b,然後b 將它發送給c。當c想要回复時,它將它發送給連接到節點0的節點e ,因此直接發送它。請注意,這意味著請求/響應對需要圍繞環進行整個行程。
存儲數據
到目前為止,我們只有一個通信系統,但是(相對)容易把它變成一個存儲系統:我們在與節點標識符相同的命名空間中為每條數據分配一個地址,並且每個節點負責存儲任何數據(位於它和前一個節點之間的地址)。因此,例如,在下圖中,節點c將負責存儲地址為k的資源,節點e將負責存儲地址為l的資源。
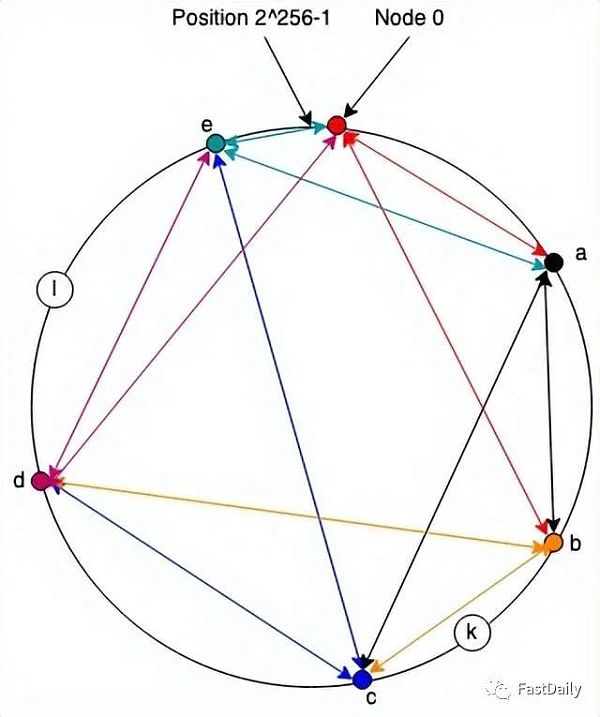
如果節點a想要存儲地址為k的值,它會向c 發送一條消息,要求存儲它。同樣,如果節點d想要檢索它,它會向c發送一條消息。
當然,這裡有幾個明顯的問題。首先,如果節點c從網絡上掉下來會怎樣?畢竟,它是某人的個人電腦,所以他們隨時都可能關閉它。這個問題的答案自然是將數據複製到其他一些節點上,這樣一來,這些節點同時下線的概率就會適當降低。精確的複制策略也是一個複雜的話題,根據DHT的不同而不同,我們不需要在這裡討論它。
第二,如果某個值既大又流行怎麼辦?在這種情況下,存儲它的節點可能突然要一次性傳輸大量的數據。這很容易使某人的鏈接完全飽和,即使他們有一個快速的互聯網連接。唯一真正的解決辦法是分配負載,你可以通過兩種方式做到。首先,你可以將資源分塊(例如,將你的電影分成5分鐘的小塊),然後將每個分塊存儲在不同的地址下;這樣做的影響是,不同的節點將負責發送每個小塊,因此它們的帶寬份額也相應地減少。你也可以嘗試讓更多的節點負責流行的內容,這也會分散負載。
最後,如果每條信息都要穿越幾個節點才能被送達,這就會增加網絡的總負載,與路徑長度(節點數量)成正比,同時也會因為延遲而降低性能。處理這個問題的方法之一是讓兩個通信節點建立一個直接的連接來進行大量的數據傳輸,並使用DHT來取得聯繫,這樣他們就可以做到這一點。這就大大降低了整體負荷。
命名事物
在前面的描述中,我已經交待了事物的地址是如何得出的。
一種常見的設計是通過對象的內容來計算地址,例如通過散列。這就是所謂的內容可尋址存儲(CAS),在很多情況下很方便,因為它不需要DHT中的任何額外內容完整性。如果你知道該對象的哈希值,你就可以檢索它,如果哈希值出現錯誤,你就知道檢索它時出現了問題。
當然,考慮到你需要對象來計算它的哈希值,這種設計意味著你需要一些服務來把你知道名字的對象(例如,”John Wick”)映射到它們的哈希值上,所以現在我們要么有一個中心化的服務來做這個,要么我們需要建立一個點對點版本的服務,我們又回到了我們開始的地方。
另一種常見的方法是擁有從加密密鑰衍生出來的名字。例如,我們可以說,我的所有數據都存儲在我的公鑰的哈希值上(同樣,也許有一些合適的分片系統)。當數據被存儲時,我們會要求它被簽名,節點會丟棄那些簽名沒有被驗證的存儲值。這有很多優點,但其中一個關鍵的優點是,你可以讓給定地址的數據發生變化,因為地址與加密密鑰而不是內容相聯繫。例如,假設被存儲的是我的網站;我可能想改變它而不想發布一個新的地址。有了與密鑰綁定的地址,這是可能的。
顯然,加密鑰匙也不是很好的標識符,因為它們很難被記住,但據推測,你會在上面設置某種去中心化的命名層,例如基於區塊鏈的命名層。
安全
任何真正的系統都需要某種方式來確保內容的完整性。與網絡不同,僅僅建立一個與存儲節點的TLS連接是不夠的,因為那隻是某人的計算機,它可能會說謊(儘管你仍然可能想出於隱私原因而說謊)。相反,每個對象需要以某種方式進行完整性保護,要么讓它的地址成為它的哈希值,要么通過數字簽名。
除了內容的完整性之外,這裡還有很多地方可能出錯。例如,如果負責的節點聲稱一個給定的對象(或一個你試圖路由到的節點)不存在,會發生什麼?或者,如果一組節點試圖通過DDoS攻擊使網絡流量飽和怎麼辦?你如何處理人們試圖存儲或檢索超過其“公平份額”(不管那是什麼)的數據。人們談論了各種方法來解決這些問題,但我們對DHT的操作經驗比我們對網絡的操作經驗規模要小,而且對故障的容忍度要高得多(如果人們突然無法從BitTorrent下載《冰雪奇緣》,迪士尼就不會損失很多錢),所以不清楚它們是否能在規模上真正安全。
一個去中心化的網絡發布系統
現在我們有了一種存儲數據並再次找到它的方法,我們有了一個開始,可以想像如何建立一個去中心化的網絡版本。就像我們在研究網絡如何工作時一樣,讓我們從發布靜態文件開始。
回顧一下URI的結構:

我們需要做的是把這個結構映射到我們的P2P存儲系統的資源上。因此,我們最終可能會得到一個像下面這樣的URL:

起源
這個系統的一個重要的安全要求是,與不同機構相關的數據有不同的起源(背景見這裡:
https://educatedguesswork.org/posts/web-security-model-origin/)。如果多個用戶發布的數據有不同的起源,那麼他們可以通過瀏覽器互相攻擊,這是一個明顯的問題。
note: 一開始就告訴我們需要使用Note 而不是通過HTTP 來檢索數據。在中間部分,我們沒有一個“host”字段告訴我們從哪裡檢索普通HTTPS URI 中的內容,而是有一個“authority”字段,它告訴我們將使用其密鑰的用戶的身份對URL 的數據進行簽名。如上所述,我假設我們有一些方法可以將用戶友好的身份映射到鍵;有些系統沒有,這似乎對用戶很不利,但如果你願意,可以隨意將權限視為密鑰哈希。
資源本身被存儲在一個由Hash(URL)給出的地址上(這是對我上面描述的一個小而簡單的改變),並且如上所述,由與權威相關的密鑰簽名。
如果你首先假設P2P系統的存在,這一切都很簡單。為了發布一些東西,我在DHT中的URL地址處做了一個存儲,並用我的密鑰簽名。然後我就可以把這個URL交給人們,他們可以通過計算地址,然後驗證簽名的資源,從DHT中檢索數據。請注意,由於地址是從URL而不是從內容中計算出來的,因此只需做一個新的存儲,就可以就地更新。
退一步說,這確實有點像我上面描述的價值主張:任何人都可以將網站發佈到網絡上,而不需要有一屋子的電腦,也不需要支付亞馬遜/谷歌/Fastly等。因此,如果你不仔細看,它似乎是完成了任務,很容易理解這種熱情。不幸的是,這個系統也有一些相當嚴重的缺點。
性能
性能(這裡指的是頁面加載的時間)是網絡瀏覽器和服務器的一個主要考慮因素。對網絡性能最重要的是檢索每個資源所需的時間。這與視頻會議或遊戲不同,在視頻會議或遊戲中,延遲(你的數據包到達對方的時間)或抖動(延遲的變化)真的很重要。在網絡中,這主要是指下載速度。
連接
為了理解從客戶/服務器到點對點的轉變對性能的影響,有必要了解一下網絡和數據傳輸的工作原理。互聯網是一個分組交換的網絡,這意味著它傳輸的是1000字節左右的單獨尋址的信息。由於網絡資源通常大於1K,客戶和服務器通過建立連接來傳輸數據,連接是雙方的持久聯繫,它將一組數據包映射成每一方都可以讀寫的數據流的樣子。發送方將文件分解成數據包並發送,接收方負責在收到後重新組裝。歷史上這是由TCP完成的,儘管現在看到越來越多的人使用QUIC,它的操作原理類似,至少在我們需要在這裡討論的層面上是這樣的。
下圖顯示了一個使用TCP和TLS 1.3安全的HTTPS連接的開始:

增加一個連接上的HTTP請求的數量
當HTTP最初被設計時,你只能在一個連接上有一個請求。由於我在這裡描述的原因,這是非常低效的,而且在很大程度上由於Jeff Mogul的工作,增加了一個功能,允許在同一個連接上發出多個請求。不幸的是,這些請求只能連續發出,這就造成了一個新的瓶頸。作為回應,瀏覽器開始在同一個網站上創建多個並行連接,這讓他們可以一次發出多個請求(由於TCP動態,有時也會搶占更大一部分的可用帶寬)。 2015年,HTTP/2增加了在同一TCP連接上復用多個請求的能力,響應交錯進行,但仍有一個問題,即響應A的數據包丟失後,其他所有的響應都會停滯(這種特性稱為線頭阻塞),這在多個連接之間不會發生。最後,2021年發布的QUIC增加了多路復用功能,即使在單一的QUIC連接上也沒有線頭阻塞。
正如你所看到的,前兩次往返完全是為了建立連接而消耗的。在兩次往返之後,客戶端終於可以請求資源了,在最終獲得任何數據之前又是一次往返。根據網絡細節,每次往返的時間可能從幾毫秒到200毫秒不等,因此,在瀏覽器看到第一個字節的數據之前,可能需要600毫秒。這是一個大問題,在過去的幾年裡,IETF已經花費了相當大的努力來減少網絡連接建立時間的往返次數(使用TLS 1.3和QUIC)。
一旦建立了連接,你就需要傳遞數據,這並不是一下子就能完成的。正如我之前提到的,它被分解成一個個數據包流,隨著時間的推移被發送到另一邊。這就是事情變得有點棘手的地方,因為發送方和接收方都不知道網絡的容量(即,它能承載多少比特/秒),如果發送方試圖發送得太快,那麼額外的數據包就會被丟棄。為了避免這種情況,TCP(或QUIC)試圖通過逐步加快發送速度來計算出一個安全的發送速率,直到出現擁堵的跡象(例如,數據包丟失或延遲),然後再退縮。重要的是,這意味著最初你不會使用網絡的全部容量,直到連接變暖(這被稱為“慢速啟動”),所以數據傳輸率往往會隨著時間的推移越來越快,直到達到穩定狀態。
所有這一切的含義是,新的連接是昂貴的,你想通過一個連接發送盡可能多的數據。事實上,在過去的30年裡,HTTP的大部分發展都是在尋找方法,使單個網頁使用越來越少的連接。
點對點的性能
這就把我們帶到了點對點系統的性能問題上。正如我上面提到的,如果你想移動大量的數據,你真的想讓客戶端直接連接到存儲數據的節點上。這帶來了幾個問題。
首先,我們有通過P2P網絡發送第一條信息的延遲,然後再返回。這通常會比直接信息慢,因為它不能採取直接路徑。然後,一般來說,不可能簡單地直接與其他人的個人電腦建立連接,因為他們通常在NAT和防火牆等網絡元素後面。所謂的“打洞“協議,如ICE,在許多情況下允許你建立直接連接,但它們會引入額外的延遲(至少一個往返,但往往更多)。一旦完成,你還必須建立一個加密連接,所以我們說的是額外的2次往返的地方。更糟糕的是,在很多情況下,存儲節點在拓撲上離你很遠,因此有很長的往返時間;大網站和CDN故意把存在點設在靠近用戶的地方,但這對P2P系統來說是個更難的問題。當然,即使連接已經建立,我們仍然處於緩慢啟動狀態。
這對網站來說都有點不合適,因為網站往往由大量的小文件組成。例如,谷歌的主頁通常被設計成輕量級的,目前由36個獨立的資源組成,其中最大的是811KB。如果這些資源中的每一個都單獨存儲在DHT中,那麼你將會經常運行協議的低效設置階段,而幾乎不會進入高效的數據傳輸階段。這與HTTP和QUIC形成鮮明對比,它們試圖保持與服務器的連接開放,從而可以攤薄啟動階段的費用。
顯然,把網站上的一些資源捆綁到一個單一的對像中是可能的,但這也有其他問題。首先,這對瀏覽器的緩存很不利,因為這些對像中有許多會在後續的加載中被重複使用。其次,這使得與單個節點的連接成為下載過程中的限制性步驟,如果該節點(只是記得別人的電腦)沒有良好的網絡連接或暫時過載,這就很糟糕了。其結果是,我們有一個矛盾,即我們想盡量減少個人的獲取延遲,也就是通過一個單一的連接發送所有的東西,而我們想做的是為了避免單一元素的瓶頸,也就是像BitTorrent那樣一次從很多服務器上下載。
在像電影下載這樣的情況下,所有這些都不是問題,因為對像很大,所以總體吞吐量比延遲更重要。在這種情況下,你可以將你的連接並行化,並保持管道的完整。然而,這並不是網絡的情況,人們真正注意到的是頁面加載時間。據我所知,建立一個大型的P2P網絡,其加載時間的性能與網絡相當,這是一個大部分未解決的問題。
安全和隱私
即使我們假設P2P網絡本身是安全的,即攻擊者無法破壞它,而且數據是經過簽名的,這個系統仍然有一些令人擔憂的特性。
隱私
在任何像網絡這樣的系統中,向客戶提供數據的節點會了解某個客戶對哪些數據感興趣,至少是客戶的IP地址水平。在目前的網絡中,這並不是一個理想的情況,因此有了像Tor、VPN、Private Relay等IP地址隱藏技術,但至少它在某種程度上僅限於你選擇與之互動的可識別實體(當然,網絡廣告中無處不在的跟踪使情況相當糟糕)。
P2P系統的情況更糟糕:下載一個內容意味著聯繫互聯網上或多或少的隨機計算機,告訴它你想要什麼。正如我在上面指出的,你可以通過P2P網絡路由所有的流量(但它嚴重損害隱私),所以現實中你將與該節點共享你的IP地址。更糟糕的是,在大多數情況下,數據將被分散在多個節點上,這意味著很多不同的隨機人都會看到你的瀏覽行為。最後,在許多網絡中,節點有可能影響他們所負責的數據,在這種情況下,人們可以想像那些希望進行監視的實體試圖對特定種類的敏感數據負責,然後記錄誰來檢索它;事實上,這似乎已經在BitTorrent中發生了。
訪問控制——將公眾置於發布中
網絡上的大部分內容是向所有人開放的,但也有很常見的情況是,你想限制對某一數據的訪問。這可以是網站的數據,如《紐約時報》等網站的付費牆,也可以是用戶的數據,如Facebook或Gmail的數據。這些都是以明顯的方式實現的,即在服務器上有一個訪問控制列表,說明哪些用戶可以訪問每塊數據,並拒絕向未經授權的用戶提供數據。然而,這在P2P系統中是行不通的,因為沒有服務器來執行:數據只是存儲在人們的電腦上,即使網站發布了訪問控制規則,網站也不能相信存儲節點會遵守這些規則。它甚至可能被攻擊者所控制。
這個問題的傳統答案是在內容存儲到DHT之前對其進行加密。即使DHT中的數據是公開的,那也只是密碼文本。當內容是用戶的,並且他們不想與任何人分享時,這實際上是適度的工作,因為他們可以將其加密到他們知道的密鑰,然後只是將其存儲在DHT中。這甚至可以通過現有的API(如WebCrypto)來完成,而密鑰則存儲在用戶的計算機上。如果他們想與其他人分享,效果就會差很多——尤其是像Google Docs這樣的讀/寫應用程序,因為你需要對所有的訪問規則進行加密執行機制。在這方面已經有一些真正的工作,如SiRiUS和Tahoe-LAFS的加密文件系統,但這是一個複雜的問題,我不知道任何真正大規模的部署。
付費牆的問題實際上更難。例如,《紐約時報》可以對其所有內容進行加密,然後給每個訂閱者一個可以用來解密的密鑰,但是考慮到訂閱者的數量,而且只要有一個人洩露密鑰,[3] 該密鑰洩露的可能性基本上是100%。[4] 當然,人們也會分享《紐約時報》的密碼,但使這個問題更難的是,該密碼必須在《紐約時報》網站上使用,而且有可能檢測到不當行為,例如當20人使用同一個密碼。我不知道這裡有什麼真正好的純P2P解決方案。
非靜態內容
訪問控制實際上是一個更普遍的問題的特例:許多網站(如果不是大多數的話)不僅僅是簡單地發布靜態內容,這些網站依賴於服務器端的處理,這在一個分散的系統中是很難復制的。
非秘密計算
作為熱身,讓我們拿一個相對簡單的問題舉例,即我在網絡安全模型系列第二部分中描述的購物網站。實際上,這個網站有三個需要被複製的服務器端功能。
-
產品搜索
-
購物車維護
-
採購
其中第二和第三項功能實際上是相當直接的:購物車可以完全存儲在客戶端,或者,如上一節所述,由客戶端在P2P系統中自我加密存儲。購買這一塊可以通過某種加密貨幣來處理(儘管如果你想使用信用卡,事情就更複雜了)。然而,產品搜索就比較困難了。明顯的解決方案是在網絡中發布整個產品目錄,讓客戶下載,並在本地進行搜索。這顯然有一些相當不理想的性能後果:亞馬遜有海量的目錄數據,這些數據的變化非常頻繁複雜。
顯然,這在Web 2.0世界中的工作方式是,服務器只是運行計算並返回結果,在這一點上,你通常會聽到有人提出某種分佈式計算系統,如Ethereum智能合約(儘管你可能不希望結果記錄在區塊鏈上)。在這種情況下,網站不是發布一個靜態資源,而是發布一個要執行的程序來返回結果(通常這些程序是用WebAssembly編寫的)。
除了明顯的問題,即這仍然需要執行程序的節點擁有所有的數據,最終用戶客戶端很難確定該節點是否正確執行了程序。即使在一個簡單的案例中,比如搜索匹配的記錄:如果這些記錄是簽名的,那麼節點就不能替換他們自己的值,但他們有可能隱藏匹配的值。當然,有一些加密技術有可能使其證明計算是正確的,但它們還遠遠微不足道。所以,這並沒有一個真正偉大的解決方案。
秘密信息
一個購物網站實際上是一個相對簡單的案例,因為信息基本上在某些情況下是公開的,網站可能不希望他們的目錄是公開的,但有很多情況下,網站想用秘密信息進行計算。這裡主要有兩種情況:
-
網站的秘密信息,例如Twitter的推薦算法是不公開的。
-
用戶的秘密信息,例如他們在約會軟件中“向右滑動“過的其他用戶,甚至只是用戶的個人資料細節。
在Web 2.0中,這種工作方式是,服務器知道秘密信息並將其用於計算,但不向用戶透露。但是,與搜索案例一樣,這並不容易移植到P2P案例中,因為將信息透露給隨機的人的個人電腦並不安全。
當然,有用於計算具有加密數據的特定功能的加密機制。例如,Private Set Intersection技術可以確定Alice和Bob是否都互相滑動,並且只告訴他們是否都這樣做了,但是它們很複雜,更重要的是特定於任務,因此你需要為每個應用程序提供解決方案,有時這意味著發明新的加密技術(要清楚,這遠非實現安全P2P約會系統所需的全部內容!)
這實際上是在“受信任的“服務器上進行的計算的加密替換的一個普遍問題。加密方法的積極一面是它們可以提供強大的安全保證,但消極的一面是,基本上每個新的計算任務都需要一些新的加密技術,這使得變化非常緩慢和昂貴。相比之下,如果你在服務器上做計算,那麼改變你的計算只是一個編寫和加載到服務器上的問題。明顯的缺點是,人們必須信任服務器,但顯然很多人願意這樣做。
混合架構
有時用於解決此類功能問題的一個想法是擁有混合架構。例如,人們可能會想像通過P2P網絡提供目錄的靜態內容來實現購物網站,但必須擁有一個處理搜索並返回指向目錄相關部分的指針的服務器。你甚至可以加密每個單獨的目錄區塊,以便競爭對手很難看到你的整個目錄。你甚至可以想像建立一個約會網站! P2P和服務器技術的某種組合,用於確定您可以看到哪些配置文件以及與哪些配置文件匹配的邏輯在服務器上實現,但是(加密的)配置文件是分佈式的P2P。
不過,在這一點上,你有相當大的服務器組件可以用在你的網站的關鍵路徑上,所以你主要是使用P2P網絡作為一種不是非常快的CDN(例如,見PeerCDN)。這就首先放棄了讓你的系統去中心化的大部分好處:你仍然有在某處託管你服務器的問題,這可能意味著一些雲服務,在這一點上,為什麼不為你的靜態內容直接使用CDN?同樣,如果你擔心審查制度,那麼你需要擔心你的服務器被審查,這使得你的網站無法使用,即使P2P部分仍然有效。
結束語
我們很容易看到一個更加去中心化網絡的吸引力:谁愿意讓一群不露面的大公司來決定你能說什麼或不能說什麼?當然,也有很多司法機構審查人們對網絡和信息的訪問。我們很容易看到P2P內容分發系統的成功(儘管在很大程度上是為了分發其他人擁有版權的內容)並得出結論說這是解決網絡中心化問題的辦法。
不幸的是,由於上述原因,我認為這不是真正正確的結論。雖然網絡從表面上看有點像一個內容分發系統,但它實際上是一個完全不同的東西,它有更廣泛的使用案例和更嚴格的安全和性能要求。在P2P基礎上重建一些較簡單的系統是可能的,但網絡作為一個整體是一個不同的故事,即使是看起來簡單的系統,其內部也往往相當複雜。當然,網絡已經有近30年的時間發展成現在的樣子,可能有一些技術改進可以讓我們建立一個具有類似屬性的去中心化系統,但我不認為這是我們今天真正理解的事情。
Though see X in which these roles are sort of reversed. ↩︎
Interestingly, within certain limits latency doesn’t have that much impact on how fast you can send the data because the rate control algorithms can adjust for latency. ↩︎
Allan Schiffman used to call this a “distributed single point of failure”. ↩︎
Or, as the nerds say, “unity”. ↩︎