
主要結論:
-
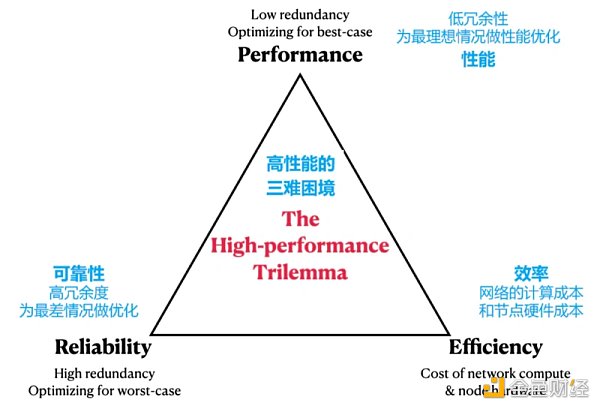
我們提出了一個L1設計權衡的第一性原理框架:高性能的三難困境。 (如上圖)
-
與以太坊相比,Solana的激進的低冗餘設計既解釋了它的高性能,也解釋了它的低可靠性。
-
Aptos,一個擁有2億美元全明星種子輪融資的新L1,準備挑戰Solana在高性能L1領域的壟斷地位。與Solana相比,Aptos增加了更多的可靠性,其代價是更高的節點硬件要求。
-
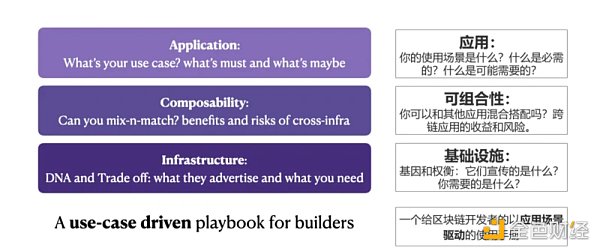
我們相信針對特定應用進行優化才是L1的未來。考慮到三難問題,沒有哪條鏈能達到一個萬能設計就符合所有應用場景的狀態。在我們之前的跨鏈文章的基礎上,我們提出了一個“三個問題”的問答手冊,供區塊鏈應用的開發者們考慮他們的技術選擇。
這裡篇幅有限,但我們其實有更多的想法。
我們誠摯地邀請感興趣的建設者和投資者進行進一步的討論。我們的推特是@TheAntiApe,郵箱是theantiape@gmail.com。
文章中會提及的項目包括:
Solana, Aptos, Ethereum, StarkWare, zkSync, Serum, Meteplex。
第一部分:Solana高性能的秘訣
這部分包括:
-
直到目前,Solana作為唯一的一條高性能區塊鏈仍處於壟斷地位
-
Solana的設計基因是激進地優化最理想情況下的網絡性能:並行運算、減少冗餘度和更高的出塊率。
是什麼讓Solana與眾不同?
作為唯一接近Visa 65,000 TPS容量的區塊鏈,Solana獲得了華爾街和矽谷的支持,以嘗試應用大規模的區塊鏈服務。
Solana並沒有通過一些圖靈獎的魔法來實現TPS(與零知識證明不同,這是我們即將討論的另一個重要話題)。
相反,Solana在性能和可靠性之間做了一系列的設計權衡。我們將在第一部分討論Solana的性能,在第二部分討論可靠性的成本。
設計選擇1:並行計算。
以太坊虛擬機(EVM)是單線程的——EVM只能利用一個CPU核心來按順序處理交易。由於單核產生的熱量隨著速度的提高而呈指數級增長,物理學限制了單核性能的上限是很低的。
解決方案是什麼?更多的核心! 八個2GHz的核心比一個8GHz的核心溫度要低很多,但也更強大。
2007年,英特爾推出了雙核的奔騰處理器,從而結束了單核時代。今天的計算機消費者擁有的GPU和CPU有4到4096個核心。
讓更多的核心合作得更好,而不是擁有更強大的單核,已經成為了十多年來半導體行業的研究重心。

為了實現原生多線程,Solana必須放棄EVM的兼容性。 Solana的智能合約可以利用Nvidia GPU的4096個核心來並行地運行計算。

我們的觀點:在這個[EVM v.s Multi-thread]的二元選擇中,我們傾向於多線程而不是EVM的兼容性。我們認為2027年的DApp卻只能使用2007年的半導體技術是非常荒謬的。
有些人可能會指出EVM/Solidity 相關的開發者的護城河問題。但是開發者其實很容易轉換編程語言。
今天的大多數Web 2應用和開發人員使用的編程語言都是原生的多線程。我們認為未來的開發者會像當前高GAS一樣對EVM的神秘的單線程架構感到沮喪。 (另外,我們也不是EVM兼容的rollups方案的粉絲)。
設計選擇2:通過確定的領導節點輪換減少冗餘度
去中心化需要冗餘性。在谷歌這樣的中心化雲服務中,計算只發生一次——因為用戶相信谷歌是正確的。
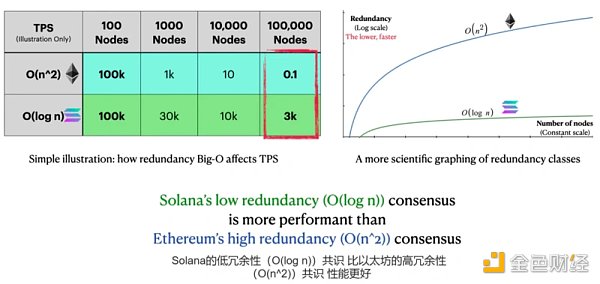
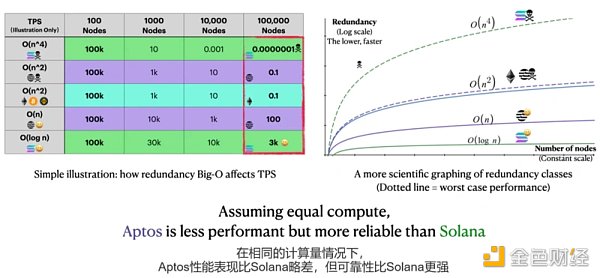
在區塊鏈中,由於我們不能信任任何人,所有數據都需要由不同的節點進行計算和驗證。一個相同的計算所做的額外次數就是所謂的間接費用/冗餘度。為了量化冗餘,我們使用Big-O符號(大O符號,漸進符號),如[O(n^2), O(n), O(log n)],裡面的函數表示當他們擴展到更多節點時,網絡計算將變得多麼複雜。例如,隨著網絡的增長,O(n^3)可能意味著比O(n^2)大幾個數量級的冗餘度。
在比特幣、以太坊和其他許多簡單的PoS鏈中,共識的冗餘度至少是O(n^2),與節點數量的平方成正比:每個區塊都必須傳輸、檢查和比較其他每個區塊的工作。
對於Solana,只有被指定的那個領導節點來生產下一個區塊。 (See Gulf Stream, Leader Rotation)。在此基礎上,Solana將區塊分割成很多小塊,然後只有一小部分節點驗證者來驗證每個小塊(See Turbine),而不是所有的節點都要發送和驗證所有的區塊。
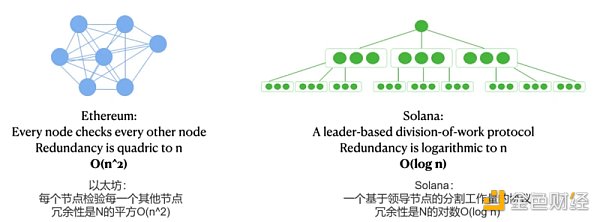
Solana的協議將Solana的最佳情況下的冗餘度從O(n^2)減少到O(log n),這是計算複雜性理論中最有效的可能。
這個結果確實很了不起。考慮一個(過於簡化的)說明。
-
網絡A和B在其他方面是相同的,100個節點有100k TPS。
-
一個O(n^2)網絡每增長10倍的節點性能就會衰減100倍。
-
一個O(log n)網絡每增長10倍節點性能才會衰減~3倍。
-
在10萬個節點時,兩個網絡的性能將相差30000倍。
這種複雜性的降低也有意識形態上的意義。
在這方面,我們認為Vitalik對Solana的批評有些誤導——Vitalik認為Solana因為硬件要求高而不夠去中心化。
Solana 4000美元的硬件成本阻止了”每個用戶在自己的機器上運行Solana節點”。這個成本是沒錯的。
但從長遠來看,計算成本會越來越便宜,而且Solana的複雜度降低的設計使它有可能擁有100倍的節點,而不會使網絡變得難以忍受的緩慢。
其他的設計選擇:
支持者和批評者還就Solana的其他一些技術特點進行了辯論。我們認為這些特點不那麼核心,所以我們概括性地討論:
3.1 投票交易算入了TPS
一些批評者指出Solana通過將驗證者投票也算入了交易,從而人為地增加了TPS。投票確實被算入了交易,但這只是一個表面問題。
也許Solana應該重申一下它的TPS是60,000(剔除投票交易),而不是65,000。
3.2 吞吐量—更快的出塊時間和更大的區塊
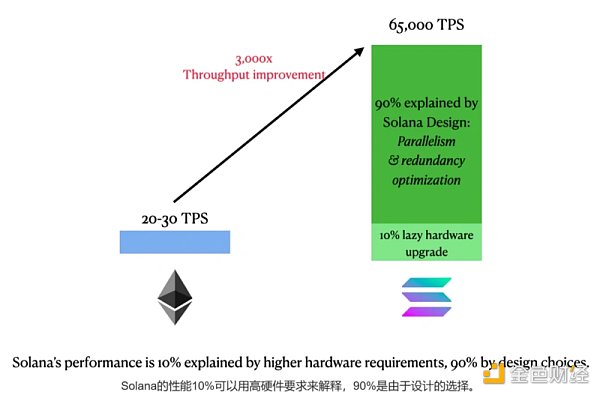
Vitalik和StarkWare都批評Solana的性能改進有些懶惰,因為Solana只是讓每個區塊更大,區塊時間更短,以更高的硬件要求為代價來容納更多的交易。
簡單的數學會告訴你這並不是全部。
Vitalik和StarkWare都批評Solana的性能改進有些懶惰,因為Solana只是讓每個區塊更大,區塊時間更短,以更高的硬件要求為代價來容納更多的交易。簡單的數學會告訴你這並不是全部。
-
Solana的最大區塊大小為10MB,是ETH目標大小1MB的10倍。
-
Solana的出塊時間是0.4秒,是以太坊12秒的30倍。
-
相比以太坊,以上兩者的組合給了Solana大概300倍的懶惰性能改進。
-
但實際上Solana的TPS比以太坊通常的TPS要高3000倍。這另外90%的性能提升可以由我們討論過的Solana的並行運算和降低冗餘性的設計來更好的解釋。
3.3 歷史證明(POH)
Solana將POH宣傳為其最大的創新。
從長遠來看,歷史證明允許Solana將區塊時間減少到極端的400ms/區塊,儘管事實上物理網絡延遲往往大於400ms。這個功能的花哨名字是異步共識,更多細節見Multicoin的文章。
設計選擇總結:Solana高性能秘訣
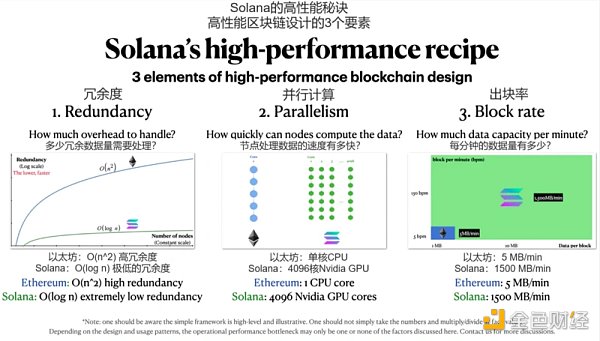
三個關鍵指標共同決定了區塊鏈的最大吞吐量:出塊率、並行計算和冗餘性。
-
冗餘度決定了總共需要多少數據和計算量,也就是說,總計算量=有效計算+冗餘度;
-
並行計算允許節點計算的速度更快;
-
出塊率決定了一定時期內區塊鏈數據庫中可保存的數據量。
Solana在這三個方面都做出了大膽的設計選擇:從O(n^2)到O(log n)冗餘;從1核到4096核並行,以及從5MB/min到1500MB/min的出塊速率。
這些是Solana的65,000TPS背後的主要秘訣。在下一章中,我們將討論Solana這些選擇的成本。
第二部分:Solana選擇的成本:優先性能而非彈性
這部分包括:
-
Solana激進的性能優化的DNA使它比其他區塊鏈更容易發生故障。
-
我們提出了冗餘困境:鑑於有限的計算能力,L1必須在性能和可靠性之間做出權衡。
-
冗餘困境是第3部分中高性能三難問題的一個子集。
頻繁的網絡事故
在過去的一年裡,Solana至少經歷了4次重大網絡事故。
2021年9月停運事故,2021年12月降級事故,2022年1月降級事故,2022年4月停運事故。任何有興趣的利益相關者一定有很多問題:
-
是什麼導致了事故?
-
本質的原因是是什麼?一次性的系統BUG ?意外的攻擊?還是區塊鏈設計DNA中的某些問題,我們只能緩解?
選擇最佳性能而不是可靠性
在第一部分中,我們討論了Solana如何積極地優化其最佳情況下的性能。
“最佳情況”是這裡的一個關鍵詞。當事情沒有完全按照理想模式發生時,Solana就會失控。
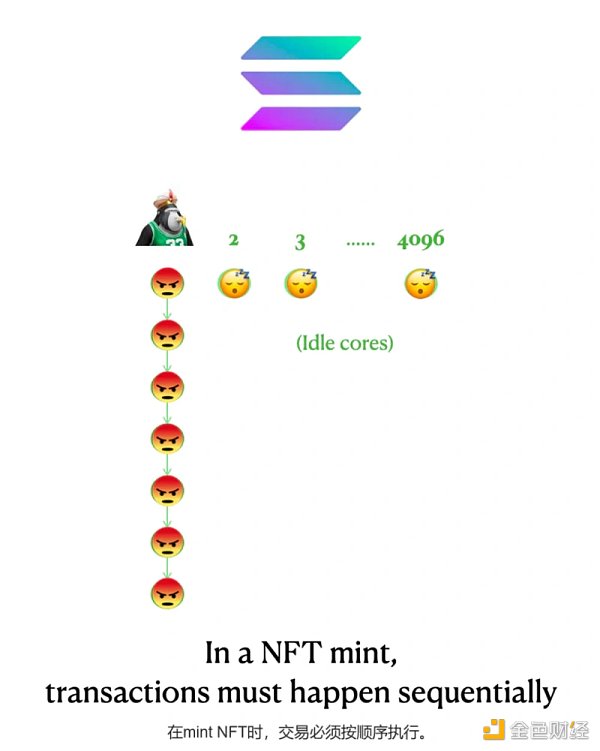
設計成本1:當交易在邏輯上有順序時,激進的的並行計算就會退化。
NFT mint 和IEO 交易常常導致Solana網絡中斷。
原因是:這些交易無法在4096個核心上同時進行。 Minting NFTs 時,不知道哪些已經被mint 了,這會導致重複和BUG。
所有在同一個collection的mint交易必須按順序處理。
一個直接含義就是,Solana的65,000 TPS並不意味著用戶可以在一秒鐘內鑄造6個BAYC集合:由於只依賴一個GPU核心,Solana的按順序處理能力可能更接近甚至低於以太坊,大約在10到100 TPS之間。
這就解釋了性能下降的原因:NFT mint 時失控的交易量會使Metaplex無法使用,但其他不依賴Metaplex的應用(如Serum訂單簿)仍然可以在其他4095個核心之一上處理交易。
但更多的時候,性能降低變成了網絡中斷:等待Metaplex的未處理的交易致使節點內存溢出——當內存溢出時,節點崩潰並完全離線。
核心權衡:通過使用4096核心的GPU而不是16核CPU,Solana犧牲了單核性能而支持激進的並行運算。通常情況下,當交易不相關時,網絡運行得很好,但一旦交易表現出不理想的模式,Solana比高冗餘度的以太坊更容易崩潰。
設計成本2:當領導者崩潰時,決定性的領導者選擇會變得很難看
當Solana接近崩潰時,負責當前的區塊領導節點往往是第一個崩潰的。
Solana的低冗餘設計嚴重依賴領導結點是否在線–其他節點都沒有與當前領導節點相同的交易數據或網絡角色。
這意味著一旦領導節點離線,網絡的其他部分需要做大量的應急工作:同意跳過一個區塊,重新組織交易數據,並將丟失的交易數據轉發給下一個領導節點……
考慮以太坊網絡,它沒有領導節點,每個節點都有一份精確和重複的副本,這份副本中包含有將被放入一個區塊(mempool)的交易數據。
如果任何以太坊節點離線,所有其他節點手頭仍有他們需要產生一個新區塊的所有內容。
這就是冗餘的雙刃劍:在理想的情況下,冗餘導致了網絡的緩慢;但在壞的情況下,它可以防止重大事故。
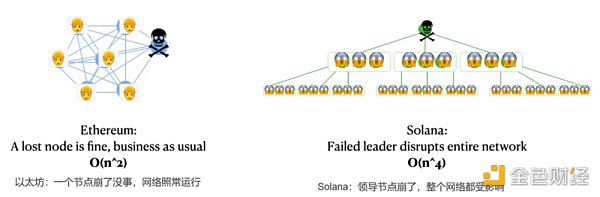
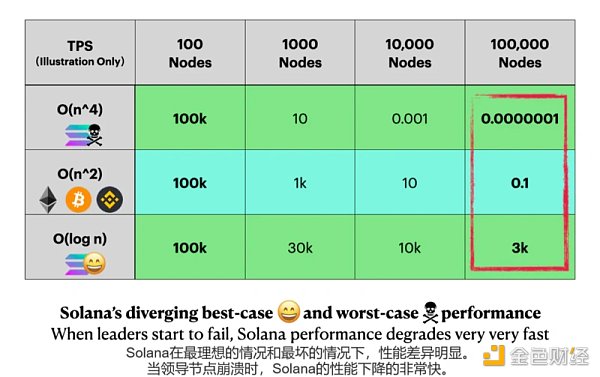
讓我們用數字來說明。根據這篇論文,在領導者節點崩潰的情況下(正式稱為”級聯領導者故障cascading leader failure”),Solana的緊急計算量開銷可以達到O(n^4)。
一個O(n^2)的網絡很慢,但可以使用,然而一個一下子需要O(n^4)計算量的網絡就好比死了。
這就是為什麼Solana一旦進入O(n^4)級聯領導故障模式,就難以自行恢復的主要原因。
這是一種特性,不是BUG

Solana的基因是激進的以最佳性能為優先。這個原則在架構中無處不在,所以很難只改變一個地方而不改變其他一切。
(我們沒有討論這個問題,但為了說明相互依賴性,如果在CPU而不是GPU上運行,核心的PoH算法將是不切實際的。
而Solana的PoH—最理想情況下進行性能優化的數據管理系統使其難以實現類似ETH的mempool)。
再次說明,這是一個權衡,不能兩全其美——要從根本上使Solana更加穩定,需要創造更多的冗餘度,從而犧牲最理想情況下的性能。
即使是Solana的支持者,也需要做好心理準備,網絡中斷和性能降低還會發生很多次。
因為今天的Solana網絡還遠遠沒有嘗試過所有可能的緩解措施。緩解措施是一個需要迭代的捉迷藏遊戲。
有一天,Solana實驗室的努力工作可能使99.99%的網絡正常運行時間成為可能。
是,它從來都不意味著要達到100%的網絡正常運行,今天的主網beta版離99.99%也還很遠。
第三部分:Aptos加入了競爭和高性能的三難問題
這部分包括:
-
Aptos的設計選擇是在可靠性和性能之間的折衷,位於Solana和Ethereum之間
-
我們提出了高性能、可靠性和效率之間的高性能三難問題
-
對開發者來說,未來的趨勢是根據具體使用場景進行優化。我們提出了一個3個問題的問答手冊來幫助開發者選擇基礎設施
在過往整整一年多的時間裡,Solana仍然是高性能L1細分市場裡唯一的名字。
現在我們有了Aptos,由Facebook的前Libra團隊開發,並由a16z、Tiger、Multicoin和FTX投資。
Multicoin和FTX明顯也是Solana的重註投資者。
Aptos最近成為頭條新聞,因為他們聲稱有16萬的TPS,顯然將自己定位為Solana的競爭對手。
這也是我們為什麼花這麼多時間來剖析Solana的原因:這是一個最好的角度來結合實際理解Aptos:

回顧第二部分,以太坊對網絡能夠正常運行的時間進行了優化:
以太坊花費了大量的數據冗餘來為最壞的情況做準備,所以幾乎不可能用攻擊來使以太坊網絡中斷。
而Solana是為最理想情況下的性能進行了優化,在冗餘上花費較少,從而使網絡在極端情況下的可靠性降低。
在解決冗餘度困境時,Aptos試圖從Solana退一步。下面是它的一些關鍵設計選擇:
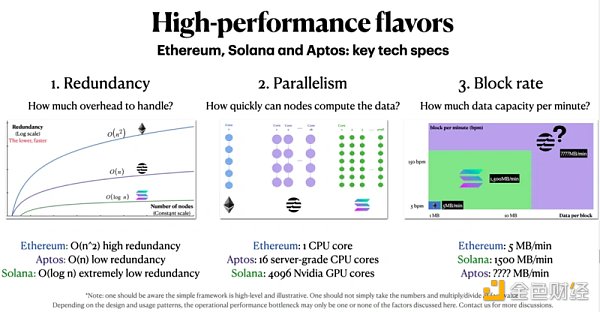
Aptos設計選擇1:16核服務器級CPU
這是Solana的4096個GPU核心和以太坊的1個CPU核心之間的一個中間地帶。
在處理高度可並行的任務時,Aptos可能不如Solana快。
Aptos的每個CPU核心都比Solana的GPU核心性能高得多,所以在NFT mint等邏輯上按順序交易的情況下,Aptos可能比Solana處理得更好。
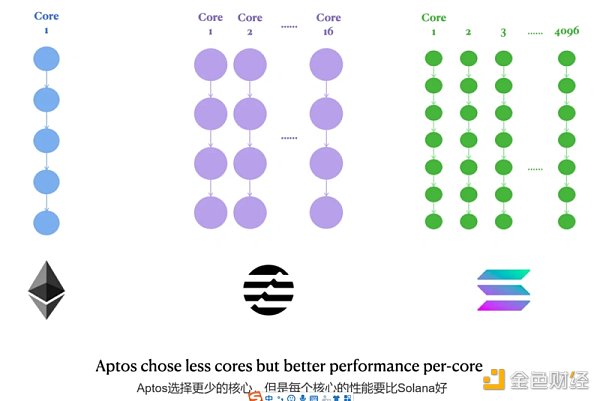
Aptos設計選擇2:最理想情況冗餘為O(n),最差情況冗餘為O(n^2)
相對於Solana,Aptos試圖通過增加冗餘使其網絡更具彈性。 Aptos沒有試圖達到Solana的極端O(log n)次線性冗餘度,而是設置為O(n)的冗餘度。
在每一輪共識中,Aptos要求所有非領導者的節點同步額外的數據,以備當前領導者節點失敗時其他節點需要接管。
Aptos也沒有嘗試對區塊進行分割和驗證,因為分割會在出錯的情況產生額外的工作量。
這麼設計的結果是:當領導者節點確實失敗時,Aptos的應急處理並沒有Solana那麼混亂。
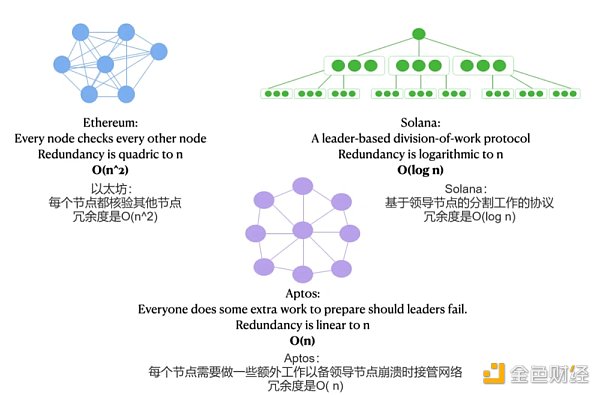
比較一下:Aptos的最佳性能不如Solana,但Aptos在最差情況下的表現更容易接受——O(n^2),而Solana為O(n^4)。
如果我們把這五個性能表現放在一起,它們剛好是一個漂亮的三明治,把Aptos(紫色)夾在Ethereum(藍色)和Solana(綠色)之間。
Aptos設計選擇3:瘋狂的硬件要求
你們可能已經看到Aptos聲稱有16萬的TPS,並想知道為什麼我說其最理想情況下的性能不如Solana好。
注意Aptos的硬件要求:他們所有的測試都是在AWS EC2實例上運行的,有16核服務器級別的CPU。
Aptos還公開建議在谷歌云平台上運行他們的節點,而不是個人電腦。
16萬這個數字是在大約100個有權限的節點上進行的實驗室測試的結果——在更複雜的實際生產環境中,如果節點更多,TPS肯定會更低。
Aptos的內部測試也表明,隨著網絡擴展到更多節點,其性能將接近甚至低於Solana目前的65,000 TPS。
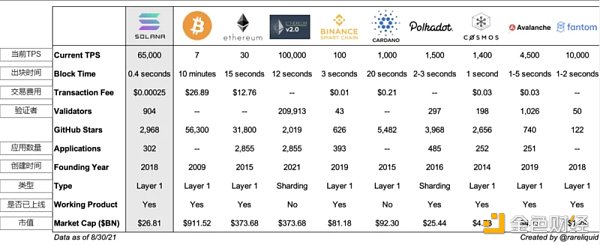
下面是對Aptos、Solana和以太坊關鍵技術規格的快速總結,供參考:
把所有東西放在一起總結一下:高性能的三難問題
把問題擴展到冗餘困境,同時把Aptos變態的硬件要求也考慮在內,我們提出了一個Vitalik的區塊鏈可擴展性三難問題的翻版:高性能三難問題。
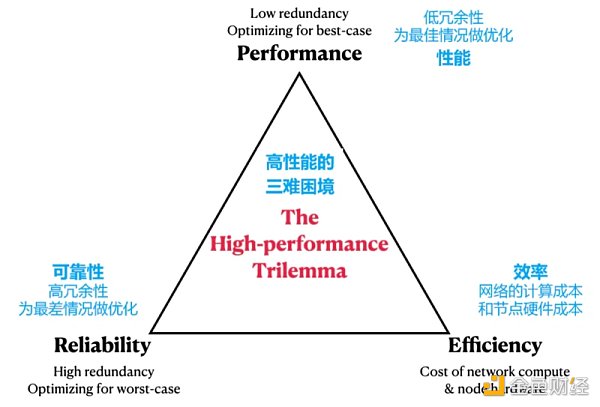
在這個三難問題中,三個不能同時滿足的符合第一性原則的特質如下:
-
可靠性:通過在冗餘度上花費更多的計算來保證網絡正常運行時間
-
性能:通過在冗餘上花費更少的計算來加強網絡的吞吐量
-
效率:提升可靠性和性能的唯一方法是獲取更多的計算資源來用於這兩方面
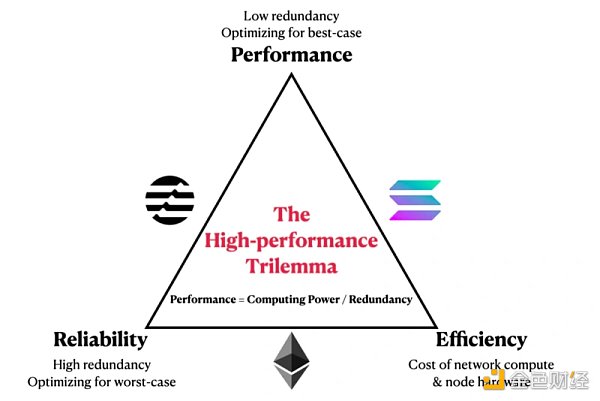
在以太坊、Solana、Aptos三者中:
-
以太坊選擇了網絡正常運行時間和效率,所以它在冗餘度上花費了的一定的計算量,導致性能緩慢。
-
Solana選擇了性能和(相對)效率,所以它把有限的計算量都花在了最佳情況的性能上,較低的冗餘度導致可靠性受到了負面影響。
-
Aptos選擇了網絡正常運行時間和高性能,所以為了有足夠的計算來覆蓋這兩個方面,Aptos不得不選擇基於服務器的節點,放棄了效率。
Aptos的設計理念相當Web 2:強調對用戶的友好,而不是去中心化。早期的描述表明,Aptos可能會整合一個帶有密碼恢復功能的高級用戶賬戶系統。
從任何角度看,Aptos肯定不是最去中心化的區塊鏈。它並不以意識形態的純粹性為目標。
來自a16z和Tiger的2億種子輪投資者將一些真正的資金和資源放在這個有點逆向的願景背後。
這一切對投資者和開發者意味著什麼?使用場景優化。
No Maxis.(非最大主義者)
No Maxis.(非最大主義者)
No Maxis.(非最大主義者)
根據你的使用場景進行優化。
甚至AWS(亞馬遜雲服務)也為不同的使用場景提供了幾十種數據庫配置,因為沒有一個萬能的解決方案。區塊鍊是數據庫。
成為一個最大主義者可能有助於在快速增長的投機市場中通過承擔短期風險而獲利,但部落主義不利於真正的價值發現和建設。
一個好的投資者和建設者應該對各方面的權衡持現實的態度,並真正理解你的用例,而不是沉溺於推銷、泡沫和公關話術中。
現在我們對未來會發展成什麼樣只有一個廣泛的輪廓。 Solana和Aptos都將經歷更多的錯誤,中斷,微調和補丁。
Solana會再次癱瘓,Aptos也會。但這並不改變它們作為解決有利可圖的高性能L1問題的頂級競爭者的地位。
對於開發者:至少需要知道三件事:
-
你的使用場景,什麼是至關重要的,什麼只是錦上添花。
-
你想使用的基礎設施的利弊權衡和基因是什麼樣的?
-
混合和匹配的成本和效益。跨鏈解決方案和風險,The Anti Ape之前的文章。偉大的DApp利用區塊鏈,糟糕的DApp被他們使用的區塊鏈所消耗。

對於投資者來說:Aptos將在2022年發佈公共測試網和代幣。這意味著Solana在高性能區塊鏈領域的壟斷很快就會結束。
我們預計Solana的代幣價格將經歷一些賣壓,因為投資者在高性能區塊鏈這個垂直領域有更多的選擇了。但現在說贏家還為時過早。
無論如何,Aptos看起來是一個Solana的有力挑戰者,因為它試圖平衡Solana的長期可靠性和其他的一些權衡點。
但我們還需要觀察,Aptos團隊是否能很好地執行落地,以及他們是否能挑戰Solana兩年的生態系統的領先優勢。
免責聲明:以上非投資建議。技術相關的圖示是作者在發表時的所擁有知識的最佳表達。為了敘述的簡潔明了,文章必然包含了一些重要的遺漏和近似。
隨著項目發布更多關於其協議的信息,觀察和假設可能需要更新或更正。我們感謝任何討論、建議和更正。
原文標題:《以太坊->Solana->Aptos:高性能區塊鏈競爭開始了》
原文作者:推特@TheAntiApe
原文翻譯:推特@0xshushu
來源:星球日報

