

我們有理由相信AIGC 將會走的越來越遠,現在的缺陷也將慢慢修補完善。
作者:wheart.eth
最近一年,隨著AIGC(AI-Generated Content)技術的發展壯大,越來越多的人感受到了它的恐怖之處。 AI 降低了創作門檻,使每個普通人都有機會展現自己的創造力,做出不輸專業水平的作品。但是就在全民AI 作圖的進程中,藝術家好像與其站在了對立面。
以Stable Diffusion 和Midjourney 為代表的業內巨頭經常受到藝術家們的集體抵制!究其原因無非兩點:一是這些模型在未經允許的情況下使用藝術家的作品進行訓練,做出的圖片與藝術家風格極其類似,涉嫌侵權;二是某些傳統藝術家認為,AI 只是對圖片進行簡單的拼接,不能算是藝術,它的濫用導致藝術市場震盪,出現“劣幣驅逐良幣”的現象。
綜合來看,現在的AIGC 市場就像一個怀揣著炸彈的巨人,外表看過去非常強大,但是內部有尚未解決的致命威脅,如果這個威脅不解除,行業發展終究受限,本文將詳細聊聊出現這種情況的前因後果,並給出可能的解決方案。
最近越來越多的畫家發現,Stable Diffusion 等AIGC 模型使用的數據集裡有自己的作品,並且這裡不乏作者經過數十年的摸索形成的具有自己獨特的風格畫作,現在人們可以利用AI 幾秒鐘生成相同風格的內容,這對藝術家來說顯然是不公平的。
(左:AI生成圖片,右:藝術家原圖)
這引發了藝術家非常嚴重的擔憂:他們自己的藝術正在被用來訓練一個有朝一日可能會影響他們生計的計算機程序。更急迫的是,任何使用Stable Diffusion 或DALL-E 等系統生成圖像的人都擁有對生成圖像的版權和所有權(具體條款會有所不同)。一位插畫師對此解釋道:人們會使用AI 生成圖書封面、文章插圖等內容,這將威脅他們的生計,畢竟站在購買者視角,當你可以免費在1000 張圖裡挑來挑去時,為什麼要付1000 美元給創作者?況且這些都是在藝術家不知情的情況下進行的。
對於這個問題,Stability AI 創始人兼首席執行官Emad Mostaque 表示,藝術只是Stable Diffusion 背後的LAION 訓練數據的一小部分,藝術類圖片佔數據集的比例遠低於0.1%,並且只有在用戶選擇調用時才會創建。但是一些搜索工具收集的數據表明,在世藝術家的很多畫作都在數據集之中,幾千張畫作的情況並不少見。
技術是原罪?
這個問題的出現不是偶然,而是必然,也是AI 發展無法繞開的問題,要想詳細了解緣由,我們或許可以通過AIGC 技術原理與發展路徑窺探一二。
AIGC是利用人工智能技術來生成內容。 2021 年之前,AIGC生成的主要還是文字(代寫文章),而新一代模型可以處理的格式內容包括:文字、聲音、圖像、視頻、動作等等。 AIGC 被認為是繼專業生產內容(PGC,professional-generated content)、用戶生產內容(UGC,User-generated content)之後的新型內容創作方式,可以在創意、表現力、迭代、傳播、個性化等方面,充分發揮技術優勢。 2022 年AIGC 發展速度驚人,年初還處於技藝生疏階段,幾個月之後就達到專業級別,足以以假亂真。
2014年提出的“對抗生成網絡”GAN(Generative Adverserial Network)是前些年大熱的深度學習模型,也可以算作AIGC的實用框架(去年年底還是主流的研究內容)。
GAN 的基本原理其實非常簡單,這里以生成圖片為例進行說明。假設我們有兩個網絡,G(Generator)和D(Discriminator)。正如它的名字所暗示的那樣,G 是一個生成圖片的網絡,它接收一個隨機的噪聲z,通過這個噪聲生成圖片,記做G(z)。 D 是一個判別網絡,判別一張圖片是不是“真實的”。它的輸入參數是x,x 代表一張圖片,輸出D(x) 代表x為真實圖片的概率,如果為1,就代表100%是真實的圖片,而輸出為0,就代表不可能是真實的圖片。在訓練過程中,生成網絡G的目標就是盡量生成真實的圖片去欺騙判別網絡D。而D 的目標就是盡量把G生成的圖片和真實的圖片分別開來。這樣,G 和D 構成了一個動態的“博弈過程”。最後博弈的結果是什麼?在最理想的狀態下,G 可以生成足以“以假亂真”的圖片G(z)。對於D來說,它難以判定G 生成的圖片究竟是不是真實的,因此D(G(z)) = 0.5。
這樣我們的目的就達成了:我們得到了一個生成式的模型G,它可以用來生成圖片。
但是GAN 有三個不足:一是對輸出結果的控制力較弱,容易產生隨機圖像;二是生成的圖像分別率較低;三是由於GAN 需要用判別器來判斷生產的圖像是否與其他圖像屬於同一類別,這就導致生成的圖像是對現有作品的模仿,而非創新。因此依托GAN 模型難以創作出新圖像,也不能通過文字提示生成新圖像。
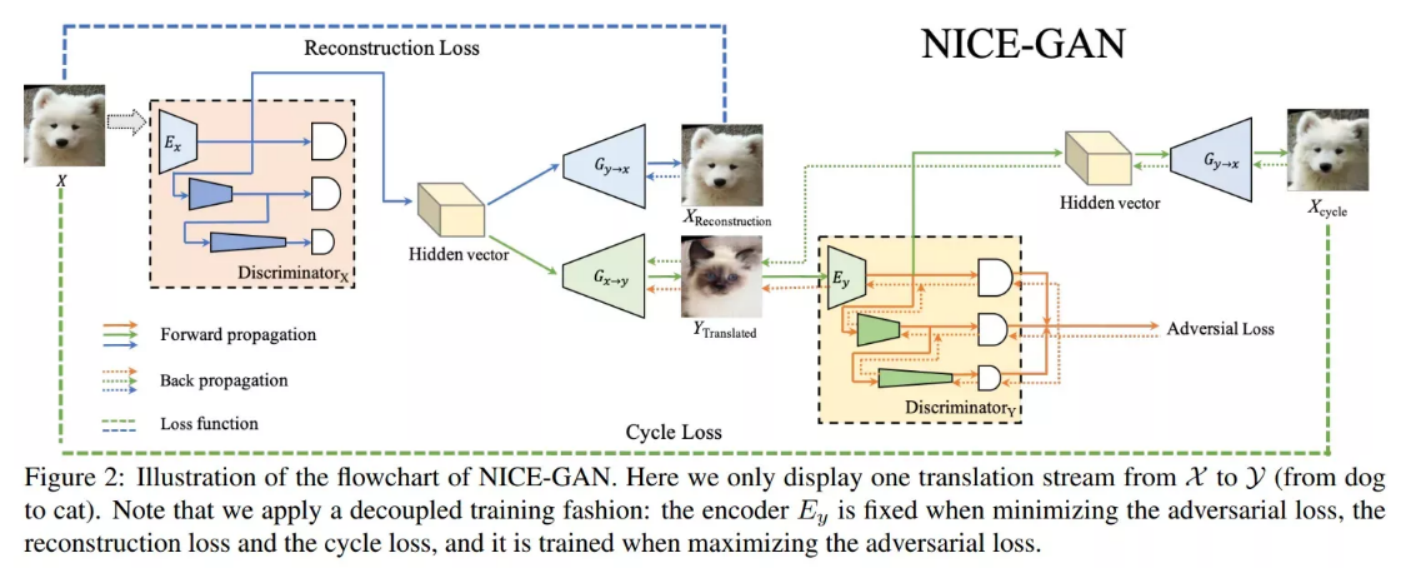 GAN技術原理
GAN技術原理
在2021 年,OpenAI 團隊將跨模態深度學習模型CLIP(Contrastive Language-Image Pre-Training)進行開源。 CLIP 模型能夠將文字和圖像進行關聯,首先收集4億未清洗的圖像+文本pair的數據集,進行預訓練以完成任務。用對比學習目標進行訓練:分別對圖像和文本編碼(文本是一整句話),然後兩兩計算cosine相似度,再針對每個圖片的一行或文本的一列進行分類,找出匹配的正例。每個圖像都有32,768個文本候選,是SimCLR的兩倍,負例個數的增多也是效果好的原因之一。在預測時也很簡單,找一個圖像分類的數據集,把label轉為自然語言,比如“狗”可以轉為“一張狗的照片”。再用預訓練好的編碼器對label和圖像編碼,再去計算相似度即可。
算法的總體過程可以總結為:輸入圖片,預測在32768個隨機採樣的文本片段集中,哪一個實際上與數據集配對。因為是文本描述不是具體的類別,所以可以在各種圖像分類任務上進行zero-shot,其中Zero-Shot是一種遷移學習,描述一隻斑馬,可以用“馬的輪廓+虎的皮毛+熊貓的黑白”,生成新的類別,普通的有監督分類器都可以將馬、老虎、熊貓的圖片正確分類,但遇到沒有學習過的斑馬的照片卻無法分類,但是斑馬卻和已分類的圖像有共同點,可以推理出這一新的類別。
所以思路就是:設置類別更細粒度的屬性,以建立測試集與訓練集之間的聯繫。比如將馬的特徵向量轉換到語義空間,每一維代表一個類別的描述,【有尾巴1,馬的輪廓1,有條紋0,黑白0】,熊貓就是【有尾巴0,馬的輪廓0,有條紋1,黑白1】,這樣定義一個斑馬的向量,通過對比輸入圖片的向量與斑馬向量之間的相似度就可以進行判別。
因此,CLIP 模型具備兩個優勢:一方面同時進行自然語言理解和計算機視覺分析,實現圖像和文本匹配。另一方面為了有足夠多標記好的“文本-圖像”進行訓練,CLIP 模型廣泛利用互聯網上的圖片,這些圖片一般都帶有各種文本描述,成為CLIP 天然的訓練樣本。據統計,CLIP 模型蒐集了網絡上超過40 億個“文本-圖像”訓練數據,這為後續AIGC尤其是輸入文本生成圖像/視頻應用的落地奠定了基礎。
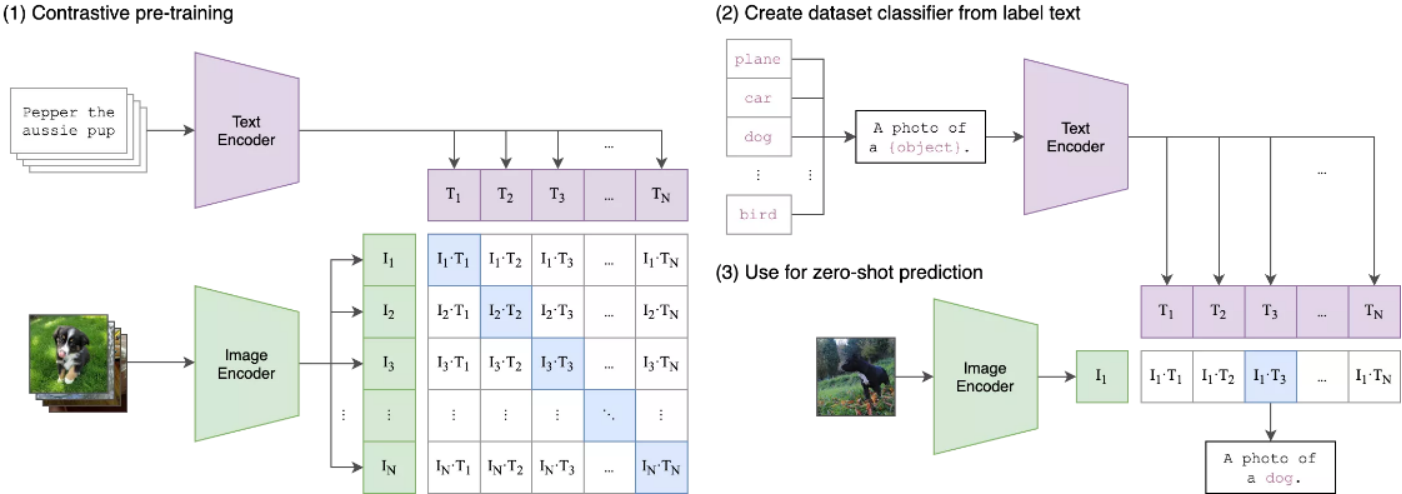 CLIP 技術原理圖
CLIP 技術原理圖
隨後出現的Diffusion 擴散模型,則真正讓文本生成圖像的AIGC 應用為大眾所熟知,也是2022 年下半年Stable Diffusion 應用的重要技術內核。
擴散模型的靈感來自於非平衡熱力學。定義了一個擴散步驟的馬爾可夫鏈(當前狀態只與上一時刻的狀態有關),慢慢地向真實數據中添加隨機噪聲(前向過程),然後學習反向擴散過程(逆擴散過程),從噪聲中構建所需的數據樣本。
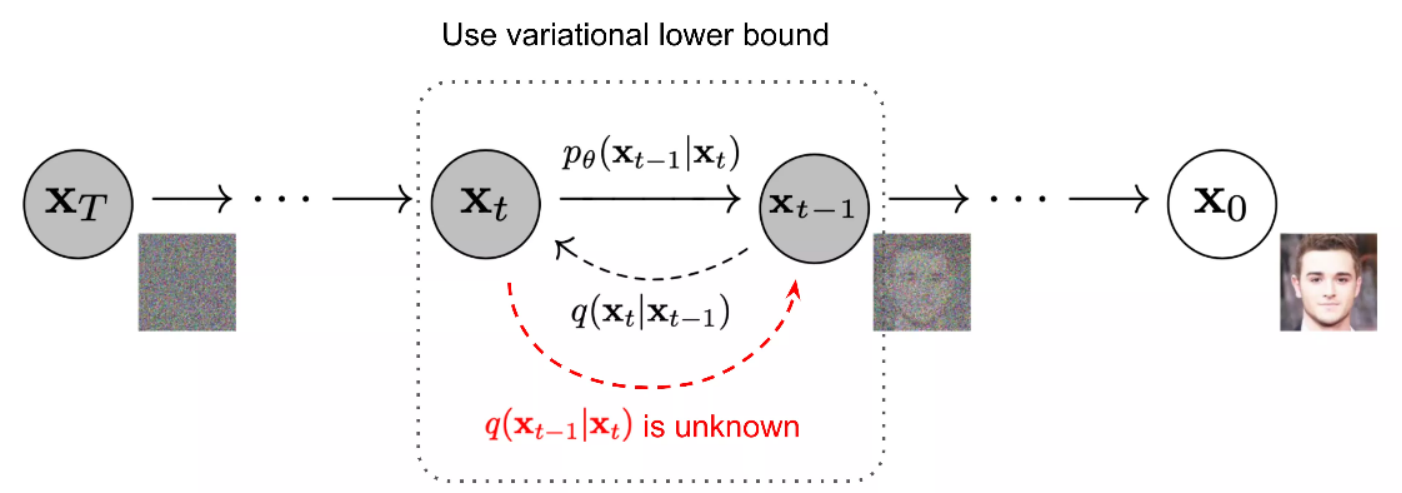 Diffusion Models 技術原理圖
Diffusion Models 技術原理圖
前向過程是不斷加噪的過程,加入的噪聲隨著時間步增加增多,根據馬爾可夫定理,加噪後的這一時刻與前一時刻的相關性最高也與要加的噪音有關(是與上一時刻的影響大還是要加的噪音影響大,當前向時刻越往後,噪音影響的權重越來越大了,因為剛開始加一點噪聲就有效果,之後要加噪聲越來越多)
逆向過程是從一個隨機噪聲開始,逐步還原成不帶噪音的原始圖片——去噪並實時生成數據。這裡我們需要知道全部的數據集,所以需要學習一個神經網絡模型(目前主流是U-net + attention結構)來近似這些條件概率,來運行反向擴散過程。
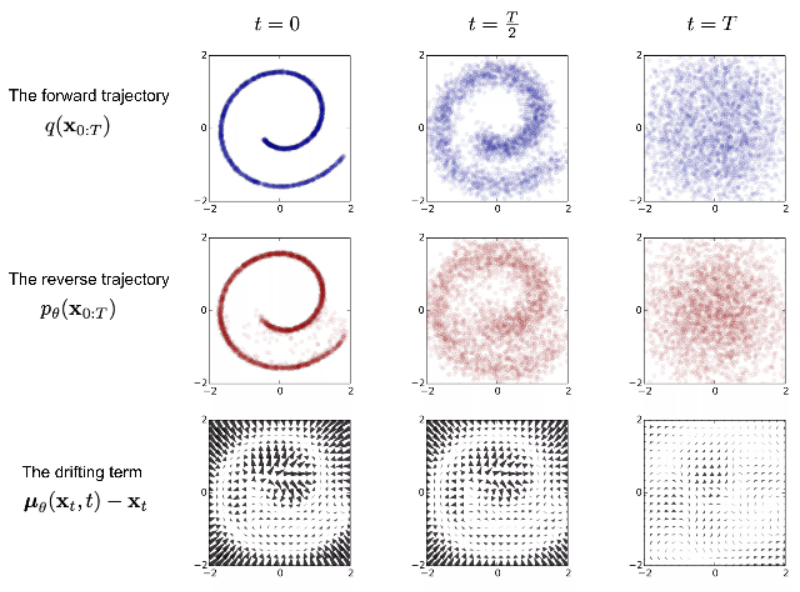 Diffusion Models 逆向過程
Diffusion Models 逆向過程
Diffusion 模型有兩個特點:一方面,給圖像增加高斯噪聲,通過破壞訓練數據來學習,然後找出如何逆轉這種噪聲過程以恢復原始圖像。經過訓練,該模型可以從隨機輸入中合成新的數據。另一方面,Stable Diffusion 把模型的計算空間從像素空間經過數學變換,降維到一個可能性空間的低維空間裡,這一轉化大幅降低了計算量和計算時間,使得模型訓練效率大大提高。這算法模式的創新直接推動了AIGC技術的突破性進展。
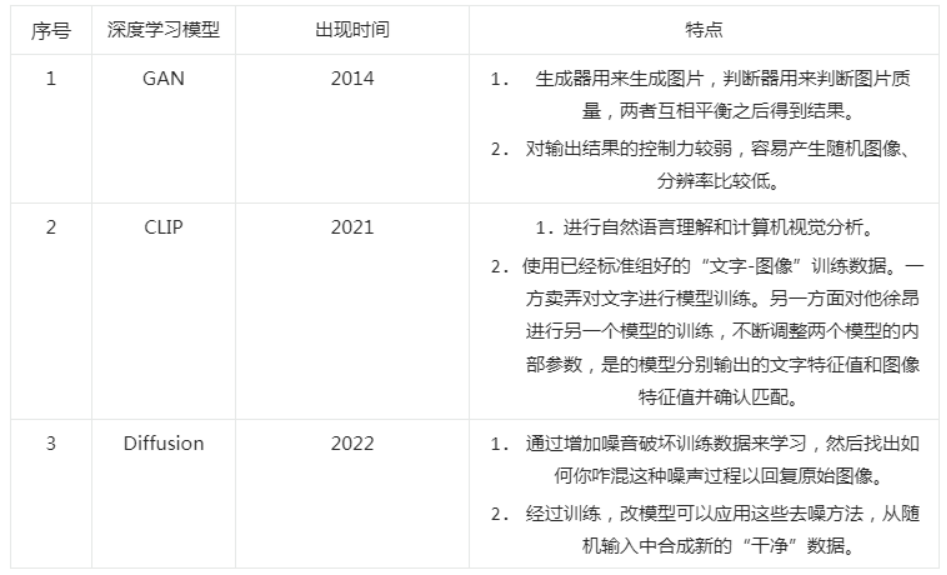 AIGC 相關深度學習模型匯總
AIGC 相關深度學習模型匯總
漏洞!
通過以上算法簡介大家也可以明白,AIGC本質上就是機器學習,既然是這樣,那就無法避免使用大量的數據集執行訓練,在這之中確實存在損害圖片版權者的利益。
雖然我們都知道這種情況的存在,但是仍然很難解決。
對於藝術家來說,雖然認為這些平台侵害了自己的權益,但是現在仍沒有完善的法律規定此類侵權行為,甚至在某些法律條文中,這種行為是合法的。
一方面,AIGC難以被稱為“作者”。著作權法一般規定,作者只能是自然人、法人或非法人組織,很顯然AIGC不是被法律所認可的權利主體,因此不能成為著作權的主體。但AIGC應用對生成的圖片版權問題持有不同觀點,圖片屬於平台、完全開源還是生成者,目前尚未形成統一意見。
另一方面,AIGC產生的“作品”尚存爭議。傳統意義上的作品是指文學、藝術和科學領域內具有獨創性並能以某種有形形式複制的智力成果。 AIGC的作品具有較強的隨機性和算法主導性,能夠準確證明AIGC作品侵權的可能性較低。同時,AIGC是否具有獨創性目前難以一概而論,個案差異較大。
即使現在把自己的作品從數據集中刪除也無法阻止自己風格作品的生成,首先,AI 模型已經過訓練,對應風格已經掌握。而且,由於OpenAI 的CLIP 模型(於訓練Stable Diffusion 以理解文字和圖像之間的聯繫),用戶仍然可以調用特定的藝術風格。
對於AI項目方來說,讓數據集每張圖片都得到授權是不現實的,如果此類法案通過,那麼AI 行業的發展將受到很大的阻礙,或許是滅頂之災。所以我們需要一個折中的方案。
方案?
首先我們來分析一下AIGC行程的創作閉環:
在創意構思方面,AIGC構建了新的創意完善通路,傳統的創作過程中消化、理解以及重複性工作將有望交由AIGC來完成,最終創意過程將變為“創意-AI-創作”的模式。
在創意實現方面,創作者和AIGC的關係類似於攝影師和照相機。攝影師構建拍攝思路並進行規劃,對相機進行參數配置,但是不用了解相機的工作機制,一鍵生成高質量的內容。同樣的,創作者構思並進行規劃,對AI模型進行參數配置,不需要了解模型的原理,直接點擊輸出內容即可。創意和實現呈現出分離狀態,實現過程變為一種可重複勞動,可以由AIGC來完成,並逐步將成本推向趨近於0。
所以這裡有兩個大主體:創作者和AIGC。創意重要,創作同樣也重要,AI做出的圖片是創作者的“創意版權”,是AIGC或者說採用藝術家風格的“底層創意/創作版權”,兩者都應該對生成內容享有權益,現在的情況就是少了藝術家的那份收益。
其實藝術家並不是不讓AI 學習他們的畫作,只是也想在其中得到相應的收益,所以只要這份設計得到藝術家的承認,AIGC 的漏洞就得以修復。
創作者的成果是AIGC 學習的對象,但創作者的創意才是關鍵,創意本身比AIGC生成的繪畫更有價值,因此如何將創作者的“創意”進行量化,甚至定價,將有助於打造AIGC的商業模式。這其中“注意力機制”將成為AIGC 潛在的量化載體。例如有機構專家提出,可以通過計算輸入文本中關鍵詞影響的繪畫面積和強度,我們就可以量化各個關鍵詞的貢獻度。之後根據一次生成費用與藝術家貢獻比例,就可以得到創作者生成的價值。最後在與平台按比例分成,就是創作者理論上因貢獻創意產生的收益。
例如某AIGC平台一周內生成數十萬張作品,涉及這位創作者關鍵詞的作品有30000張,平均每張貢獻度為0.3,每張AIGC繪畫成本為0.5元,平台分成30%,那麼這位創作者本週在該平台的收益為:30000*0.3*0.5*(1-30%)=3150元的收益,未來參與建立AI數據集將有望成為藝術家的新增收益。
但是以上設計也有缺陷,因為AI並不完美,並不是每張圖片都有價值,所以這裡優化方案可以是生成時不向藝術家付款,而有滿意的內容想要下載時,才需要支付相應的費用。這也與傳統的藝術創作領域流程相似,甲方下單,乙方提供滿意的作品時,甲方支付所有款項。
為了讓流程更加合規,更完美的做法是首先向全球藝術家公開風格庫,每個藝術家都可以選擇是否將自己的作品內容加入訓練集圖庫中,如果加入則可以在其他用戶創作對應風格時獲得相應收益,這也是在另一方面為藝術家尋求新的收益途徑。在市場上“侵權”行為如此多的背景下,此“正版授權”圖庫定會受到藝術家群體的支持,這種模式才更類似於正向循環,也是更良性的模式。
Web3?
Web3 一直在強調“創作者經濟”,這與AIGC 想要解決的問題不謀而合,利用區塊鏈技術,完全可以打造一個圍繞AIGC 的生態網絡。
創作者通過AICG 的賦能,加上Web3 模式下的經濟模型,可以將自己的創意和影響力進行指數級的放大。也讓更多的人能實現從消費到參與、從用戶到所有者的轉變。同時藝術家可以得到他贏得的收益份額,達到一個雙贏局面。
其實Web3+AI 並不是一件新鮮事,生成式藝術NFT 領軍者Art Blocks 就是一個成功的應用案例。 (雖然算法不同,但是仍舊是異曲同工。)
Art Blocks是一個生成隨機藝術品的平台。它是由Erick Snowfro 在2020 年推出,是一個專注於可編程、生成性內容的平台,其生成的內容在以太坊區塊鏈上是不可改變的。那麼「隨機藝術品」是如何隨機的呢?這個隨機過程是受一串數字控制的,這串數字存儲在以太坊鏈上的一個非同質化代幣(NFT)上。之後這個代幣所存儲的數字串控制你所購買藝術品的一系列屬性,最終生成屬於你的獨一無二的藝術品。
如果你是一個買家,比較看好某個藝術家的風格,然後支付後開始鑄造,算法生成隨機的同風格的藝術品就會被發送到你的賬戶中,以代幣的形式存在,最終的作品可能是靜態圖像、3D 模型或交互式的藝術品。每個輸出都是不同的,並且在平台上創建的內容類型具有無限種可能性,但每個項目可鑄造的藝術品的數量是一定的,也就是說一旦鑄造滿了,這個項目就不會有新的作品生成了。
對於創作者:他們需要預先在Art Blocks 上調整和部署好自己的生成藝術腳本,並確保它的輸出結果與輸入的哈希值有關。這個腳本會通過Art Blocks 存儲在以太坊鏈上。
對於收藏者:當收藏者鑄造某一系列的作品(你可以理解為點擊購買按鍵時),他們實質上獲得了一個隨機的哈希值,然後腳本執行,一副對應這個哈希值的生成藝術作品當場被創作出來。
這種模式讓收藏者也參與了生成藝術的創作。
這副作品的內容,實際上是由原藝術家的風格、生成算法和你的鑄造時機三者決定。工具、創作者和買家聯合完成了這樣的作品,這種新的NFT 創作模式讓這幅藝術品擁有了更多的紀念價值,留下了當下最新技術的印記。
和購買主流的NFT 頭像項目不同,在Art Blocks 上購買NFT 更像是在直接支持一位藝術家——這些藝術家往往是實名的,有大量的歷史作品,並且Art Blocks 會對他們進行作品相關的深度採訪。 Art Blocks 上初次出售的NFT,藝術家可以獲得90% 的收入,剩下的10% 分給Art Blocks。
所以大家可以發現,Art Blocks 簡直是給AIGC 開闢了一條“康莊大道”,當然這條路並不完能粘貼複製,但是在細節方面對其修改完全可以成為AIGC+Web3 的商業閉環!而且現在也已經有項目在做類似的事情。
正是因為有那麼多先行者探路,我們有理由相信AIGC 將會走的越來越遠,現在的缺陷也將慢慢修補完善。
展開全文打開碳鏈價值APP 查看更多精彩資訊