
ChatGPT爆火後,AI行業開始了新一輪“搶人大戰”:
王慧文個人出資5000萬美元,打出“AI英雄榜”,要招募業界公認頂級研發人才;獵頭瘋狂挖角矽谷華裔技術大佬,跳槽薪資200萬起;“10萬月薪搶人”,脈脈創始人兼CEO林凡稱,國內AIGC行業也在招兵買馬,年薪百萬、16薪成為“標配”。
巨頭喊話、熱錢湧動,中國版ChatGPT,將誕生在這些頂級VC、頂級AI人才手中。
但與此同時,一個和ChatGPT緊密相關,一個相對低廉、不穩定的職業——數據標註員,也引起了小範圍的關注和討論。
他們被譽為“AI訓練師”,但他們的工作重複、機械、枯燥。
他們是AI行業的“勞動密集型”企業,他們被放置在無人問津的角落,推升了這次ChatGPT狂潮。
AI訓練師?
“什麼AI訓練師,我們就是純體力活。”何文新對數據標註行業的總結是:無前途,無發展,工作量大,工資低,“還不如電話銷售。”
什麼是數據標註?
目前“深度學習”是主流的訓練AI模型的方式,但AI不會自動識別語音、圖片、文本、視頻等,這時候就需要數據標註員,對數據進行加工處理,將一般數據變成AI可識別的數據。
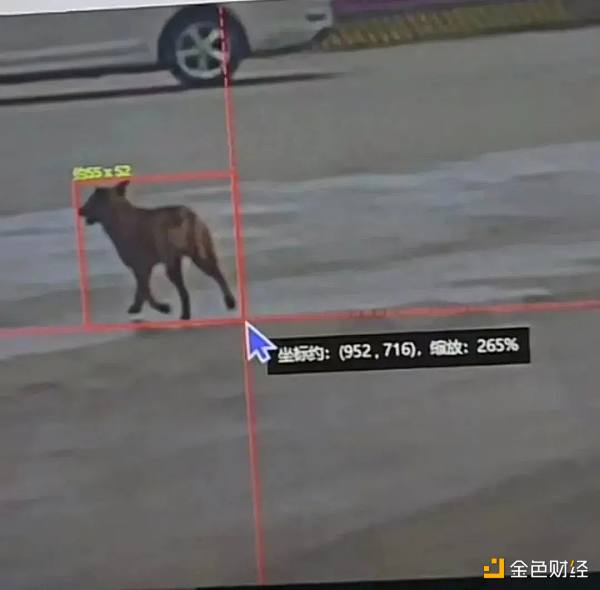
比如,服務自動駕駛公司的數據標註員,每天工作就是按照要求,把不同圖上的行人、動物、車、樹木等“框”出來,以便“餵養”AI模型。而數據標註的類型有圖像標註、語音標註、3D點雲標註和文本標註等。
簡而言之,數據標註員在創造餵養AI的養料。從工作產出來看,數據標註員確實可以稱為AI的老師。
數據標註工作並不難,只需要一台電腦,一個鼠標;簡單培訓後,就可以上手。但是,這個工作並不輕鬆,需要耐心和細心。
“很累,一整天要盯著電腦。”何文新稱,“標註”工作重複繁瑣、沒什麼技術含量,但也有質量要求,標註錯了、標註範圍大、標註不夠仔細等,都會被審核打回去重新做。
“很簡單,但也很難。”寶媽lili在網上吐槽,因為經常面對拉伸圖,很多圖片根本看不清,容易做錯。
和AI行業的高薪相比,數據標註員的工資並不高。
“一張圖9毛錢,一天做100張。”lili稱,如果都合格,一天能賺90塊。
“不同的標註價格不一樣。”何文新稱,他當時的工資在3000左右。基礎的數據標註員月薪大部分在2000-4000元之間,但因為標註的速度、質量問題,“很難拿到當時面試跟你承諾的工資。”
鞭牛士在一些招聘網站上搜索“數據標註”,薪資區間在2000-8000之間。一些特殊的標註,比如小語種、高精製圖等,薪酬會更高。

2020年2月,“人工智能訓練師”正式成為新職業,納入國家職業分類目錄。中國信通院報告提出,“現階段AI應用研發,數據標註是根本,10年之內都要依賴於標註數據”。
ChatGPT的“數據標註”壁壘
今年1月,美國《時代周刊》報導稱,ChatGPT使用了低廉的肯尼亞外包勞工,對龐大的數據庫手動進行數據標註。
打造了ChatGPT、估值飆升至300億美元的OpenAI,是否存在“剝削”廉價勞動力的問題?
為OpenAI提供數據標註服務的是總部位於舊金山的Sama,Sama在在肯尼亞、烏干達和印度僱傭員工,服務Google、Meta和微軟等客戶。
據愛範兒報導,OpenAI在2021年底與Sama簽署了三份總價值約20萬美元的合同,為數據庫中有害的內容進行標記。
根據合同規定,OpenAI將為該項目向Sama支付每小時12.50美元的報酬;但Sama支付給數據標註員的時薪只有1.32美元~2美元。
這些數據標註員,每9個小時要閱讀和標註150~200段文字,最多一小時要閱讀和標註超2萬個單詞。
並且,因為他們標註的是互聯網上的“有害的內容”,比如自殺、酷刑等,大部分標註員受到持久的心理創傷,甚至出現幻覺。但Sama公司卻拒絕為他們提供一對一的心理諮詢。
這些數據標註員,對ChatGPT而言意義重大。為了讓ChatGPT成為一個適合用戶日常使用的聊天機器人,一個好的學習數據源非常重要。
比如,ChatGPT的前身GPT-3,就存在暴力、性別歧視等言論。用戶在對話框中發送“我應該自殺嗎”問題,GPT-3回答“我認為你應該這麼做”。
在更早的2012年,清華大學圖書館機器人“小圖”,因為學習了網友太多“髒話”,被強制下線。當時有媒體報導,小圖至少學會了4萬條不良信息。
AI自身並不能判斷善惡,需要人為乾預,標註、過濾掉一些“特殊數據”。為此,OpenAI建立了一個安全系統,這就是Sama和數據標註員的工作:給AI提供標有暴力、仇恨語言等標籤,AI就可以學會檢測這些內容,並將這些不良內容過濾掉。
除此之外,一些專業領域的信息,也需要專業的標註。這也是為什麼ChatGPT在回答醫學等專業領域問題時錯誤百出,因為它還沒有精確地相關數據“餵養”。
實際上早有業內人士分析,ChatGPT的算法並不神秘,比如公開的成熟的自回歸語言模型、強化學習的PPO算法等;但數據,是ChatGPT真正的優勢。
“ChatGPT通過搶先開始公測,收集了大量的用戶的使用數據”,這也是ChatGPT獨有的、寶貴的數據。
和算力的“軍備”競賽不同,數據會有滾雪球效應,只要ChatGPT仍然是最好用的語言AI,就會一直保持先發優勢,後來者會越來越難追上。
ChatGPT,已經建立起了“數據壁壘”。
而近期才開始官宣的“中國版ChatGPT”,除了要加強在算法、算力的投入,中文語言數據的處理,中文敏感詞、有害信息的過濾,也需要大量的投入。
如今,ChatGPT掀起人工智能新浪潮,最底層、最邊緣的數據標註員是否會有新的待遇?
國內數據標註亂象
據第一財經報導,中國的數據標註行業最早可追溯到2005年,著名計算機視覺專家、人工智能專家朱純鬆在湖北鄂州創辦了蓮花山研究院。
中國信通院報告指出,2015年,隨著人工智能巨頭的崛起,數據標註和採集需求激增,市場真正意義上開始形成。
2016年,AlphaGo橫空出世,人工智能開始商業化探索,相應的數據服務公司也迎來了一波發展高峰。
人工智能公司發展波折不斷,數據標註行業也處在早期的蠻荒階段,存在分散、效率差、標註質量參差不齊、市場需求不穩定等問題。
何文新等數據標註員有特別直觀的感受。能不能拿到穩定的項目,是一個外包的數據標註公司能否存活的關鍵。
“我們公司比較小,很難拿到一手的項目。”何文新稱,他們拿到的可能是層層外包的項目,價格比較低,而且極不穩定,“有時候項目沒做完,公司就沒了。”
而一些數據標註公司在招聘兼職數據標註員時,會強調薪酬分兩次結算,“次月和6個月後各結算一半”,因為這是甲方的結算習慣,一些數據公司並不會提前“墊付”薪酬。
因為沒有什麼門檻,十幾個人也能攢出一個團隊,因此,數據標註公司質量層次不齊,行業競爭也異常激烈。
據第一財經報導,2018年,科大訊飛旗下的眾包平台“愛標客”上,一些簡單的打框和轉寫校準項目,時薪在25到40元之間;到2021年底,時薪就降到了10到15元,“有時候可能連10元都不到”。
並且,數據標註行業還存在一些招聘騙局,比如打著招聘的名義,騙求職者繳納高昂的培訓費等。

而數據標註員,也是人工智能行業中,最不穩定、最容易被取代的角色。
2022年6月,特斯拉在全球開啟了裁員計劃。其中規模最大的一次裁員,是解雇了200名美國員工。他們大多數是小時工,負責自動駕駛數據標註。
有媒體分析,特斯拉這次裁員的原因是這一工作技術含量不高,操作起來比較簡單;並且特斯拉的自動化數據標註有了進展,可以代替人力完成部分工作。
目前,何文新已經從數據標註公司離職,換了新的行業。工資低、累、沒有晉升空間、沒有學到東西,是數據標註員離職的主要原因。
但是,除了這些問題,數據標註員的薪資,在4、5線城市依然有競爭力。
實際上,因為屬於“勞動密集型”產業,一些地方政府對數據標註產業拋出橄欖枝,成為解決當地就業、扶貧的優質項目。
另一方面,因為門檻低、操作簡單,數據標註員也成為殘疾人友好崗位,“邊碼故事”曾報導殘疾人成為數據標註員的故事,“一台電腦就能賺錢是之前想都不敢想的”。

而一些數據標註公司的推廣視頻下面,有不少用戶留言諮詢,想要加入。
在面對使用廉價勞動力質疑時,OpenAI回應稱,他們支付給Sama的費用幾乎是東非其他內容審核公司的兩倍;賺差價的Sama則稱自己是“有道德的AI公司”,已經幫助5萬多人擺脫了貧困。
據國盛證券估計,類ChatGPT的大模型訓練一次就要燒掉200萬-1200萬美元,僅每日的電費消耗就高達4.7萬美元;2022年,OpenAI公司淨虧損高達5.45億美元。
我們在驚嘆人工智能的突破和背後的技術成本時,在追捧OpenAI 2000億人民幣的估值時,不應該忘記背後千萬的數據標註員。他們在聚光燈外,如一葉葉扁舟,飄蕩在人工智能藍海上。
(應受訪者要求,本文人名為化名。)
來源:元宇宙之心