OpenAI 祭出了GPT-4,這對於百度、谷歌們來說,可能是一個重大打擊。
趕在百度“文心一言”發布前一天,OpenAI祭出了GPT-4,這對於百度、谷歌們來說,可能是一個重大打擊。
人們已經領略過GPT-3.5加持下的ChatGPT,但GPT-4比“前輩”更強大,它具有更高的可靠性和準確性,能夠讀懂圖片,甚至還能角色扮演。目前,GPT-4已被應用到ChatGPT和Bing上,再一次刷新外界對AI的能力認知。
GPT-4越耀眼,谷歌、百度等競爭對手們便越焦慮。畢竟,其他公司忙著對標GPT-3.5時,OpenAI快速將大模型升級為GPT-4,一騎絕塵的樣子絲毫“不講武德”,像一個孤獨求敗的殺手,眼望著挑戰者的到來。
GPT-4打敗GPT-3.5
知名KOL和菜頭說,因為OpenAI在3月15日凌晨發布了GPT-4,他和他的一些老朋友都沒睡好,微信裡的消息提示此起彼伏,“感覺像是回到了喬布斯還在世的時候,大家相約線上看蘋果發布會的那些夜晚。”
北京時間3月15日凌晨,GPT-4發布受萬眾矚目,這是採用GPT-3.5的ChatGPT火爆後的必然結果。看客們想要知道,它比GPT-3.5到底強多少?人們甚至沒有興趣拿它來對比別的同類產品,因為能站在同一起跑線上與之對比的還沒有出現。
OpenAI很了解圍觀者的胃口,在那場更像是產品演示的發布會裡,開發者一上來就讓GPT-3.5和GPT-4分別嘗試回答同樣的問題。結果,熬夜的人沒白等。
一開始,OpenAI的開發者復制了一篇博客文章,並交給了GPT-3.5,讓它進行總結,要求是每個單詞都要以“G”開頭。結果GPT-3.5直接選擇了放棄。輪到GPT-4,它快速地給出了答案,完全符合要求。隨後,開發者又讓它嘗試以字母“A”開頭回答同樣的問題,GPT-4又做到了。
這還沒完,如同提升“節目效果”一樣,開發者直接和Discord社群互動起來,選取了網友提出的字母“Q”。再來一遍,GPT-4依然輕鬆拿捏。
這輪演示,OpenAI特地選取了一個超過GPT-3.5“閾值”的問題來測試,意在表現GPT-4的能力進化水平。正如官方所解釋的,在隨意的談話中,GPT-3.5 和GPT-4 之間的區別可能很微妙,當任務的複雜性達到足夠的閾值時,差異就會出現——GPT-4比GPT-3.5更可靠、更有創意,並且能夠處理更細微的指令。
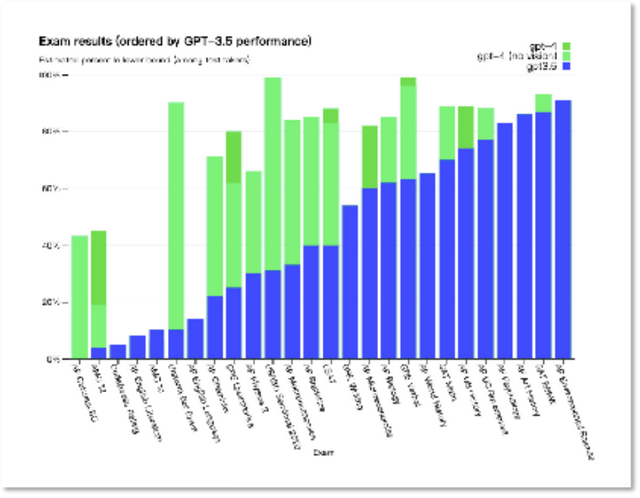
為了全面且可視化地評估GPT-4的能力提升程度,OpenAI展示了它與GPT-3.5共同參與了多項模擬考試的情況,包括統一律師資格考試、研究生入學考試、醫學知識自測、藝術史、微積分等等,結果GPT-4幾乎碾壓了GPT-3.5。比如,在模擬律師考試中,GPT-4的分數在應試者的前10%左右,而GPT-3.5 的得分排在倒數10%左右。
各項考試中GPT-4領先GPT-3.5
如同蘋果發布會每次都會帶來一個大彩蛋,GPT-4也帶來了一項跨越式的功能——接受視覺輸入。這意味著,GPT-4能夠看懂圖片了。
官方解釋:GPT-4在給定由散佈的文本和圖像組成的輸入的情況下,可生成文本輸出(自然語言、代碼等)。換言之,給它一張帶有文字的圖片,並提出要求,它就能給出想要的結果。
在演示中,開發者畫了一張網站的草圖,要求GPT-4用簡短的HTML/JS 將這個草圖變成彩色的網站。僅僅幾秒鐘後,GPT-4就帶來了一個完整的網頁。
不僅如此,GPT-4還能嘗試理解一些流行的“梗圖”。如下圖所示,讓它解釋這張圖的笑點在哪,GPT-4不但Get到了,還一本正經地解釋了一通。
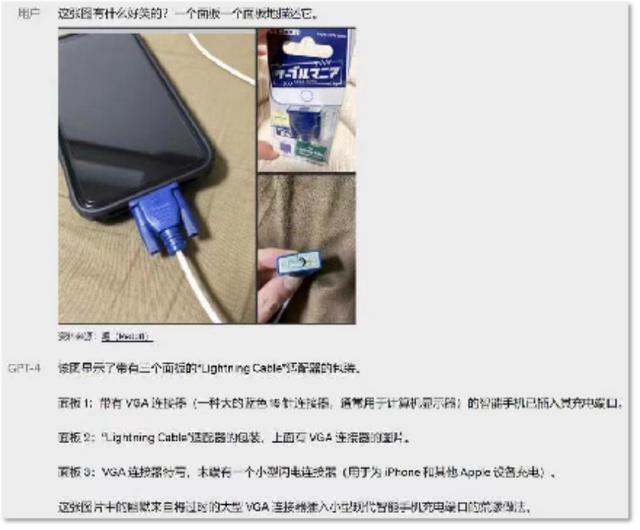 GPT-4解釋“梗圖”的笑點
GPT-4解釋“梗圖”的笑點
GPT-4的識圖功能只有體驗過才能知道是否如OpenAI說得這麼厲害。遺憾的是,目前視覺輸入還沒有完全開放,僅在一小部分開發者中進行測試。 OpenAI創始人Sam Altman解釋稱,此舉是為了防止可能出現的安全性和倫理問題。
GPT-4還有一項特別本領,它可以扮演不同的角色和說話的方式,這與具有固定語氣和風格的GPT-3.5不同。基於這個功能,用戶可以讓GPT-4實現角色扮演並定制它的性格。
就像當年的一代代新款iPhone給人們帶來驚奇感受,GPT-4展現了比它的上一代更強大的能力。不過,它也並不完美。與GPT-3.5一樣,GPT-4有時仍會虛構事實,“一本正經地胡說八道”還不能完全避免。 OpenAI宣稱,在內部對抗性真實性評估中,GPT-4的得分比GPT-3.5高40%,顯然,它還有很大的提升空間。
谷歌、百度更焦慮了
OpenAI正和當初的蘋果走在一樣的道路上:成為引領者,並在別人苦苦追趕時,又猛地拉開一大截。
就在GPT-4發布前,互聯網巨頭谷歌也在YouTube上發布了一支預告片,宣布將AI整合到Gmail電子郵件和GoogleDocs文檔等辦公應用中。谷歌在視頻中費了很大力氣展示相關功能,告訴人們可以在文件中進行頭腦風暴、校對、寫作和改寫;利用幻燈片中自動生成的圖片、音頻和視頻,將創意構想變為現實等。
然而,“一點水花都沒有,幾個小時之後GPT-4開發布會,人一下子就全跑光了。”和菜頭如此描述他的觀察。從社交網絡上輿論風向看,谷歌的AI新動作被鋪天蓋地的GPT-4消息所淹沒——無論是海外的推特還是國內的微博,GPT-4都登上了熱搜榜。
和谷歌一樣被冷落的AI玩家還有Meta。不久前,Meta公佈了旗下全新的AI大型語言模型LLaMA,宣稱可幫助研究人員降低生成式AI工具可能帶來的“偏見、有毒評論、產生錯誤信息的可能性”等問題。 Meta還放話,這一大模型僅用約1/10的參數規模,就能匹敵OpenAI GPT-3、谷歌PaLM等主流大模型的性能表現。這一新動態在GPT-4到來後,沒有在輿論場上再露臉。
OpenAI的光芒越盛,其他科技巨頭們就越焦慮。
2月,倉促應戰ChatGPT的谷歌還鬧出過笑話,其開發的聊天機器人Bard首秀“翻車”,答錯問題導致其市值一天之內蒸發約1000億美元。
在國內,百度也在加急研發與ChatGPT類似的聊天機器人“文心一言”。按照預告,百度將在今天下午舉辦有關文心一言的新聞發布會。在許多人也許還在好奇文心一言能否比肩GPT-3.5模型下的ChatGPT,結果,OpenAI趕在百度發布會前帶來了更強大的GPT-4。
別人忙著對標GPT-3.5時,OpenAI如同冷血殺手一般,親手擊敗了自己出品的GPT-3.5。同類競爭公司們有多焦慮,網友們已經自行腦補出了各種“梗圖”。
“那種提刀在手,環顧天下,寂寞如雪的感覺,讓我忍不住感慨:即便在美國本土,這件事也和絕大多數美國科技公司無關了。”和菜頭形容,OpenAI迭代的速度讓他感覺到心驚肉跳,“所有試圖追趕的人和公司,目前落後進度最少兩年。在這種AI爆發式增長的時代,兩年就是三輩子。”
回顧GPT的發展,它用5年時間裡完成了從量變到質變的飛躍。 2018年,GPT-1首次發布,當時的模型參數只有1.17億個,隨後的GPT-2將標準提高到15億個參數,GPT-3和GPT-3.5的神經網絡直接提升到1750億個參數,而到了GPT-4,採用的參數超過2000億個,並利用了超過200萬個數據源(GPT-3.5使用了45萬個數據源),包括互聯網上的各種文本、圖像、音頻和視頻數據。
相比之下,2022年初谷歌曾披露其LaMDA 模型參數為1370億個,不如當時的GPT-3多。而據百度透露,文心一言大模型參數規模達到2600億,相比GPT-4更多,這或許還能讓它留給人們一些期待。
不過,有專家指出,模型參數並不是決定AI聊天機器人能力的絕對因素,在此基礎上,對數據的清洗和標註、模型結構設計、訓練推理的技術積累都會決定最終產品的表現。
GPT-4甚至不用擔心產品化了,它已經應用於ChatGPT和微軟的搜索引擎必應(Bing)上。一騎絕塵後,塵土裡若隱若現著谷歌和百度。
展開全文打開碳鏈價值APP 查看更多精彩資訊