

前言
近期ChatGPT 爆火,其對傳統文字工作的效率提高及總結能力讓使用者驚艷。緊隨其後CodeGPT 這樣基於GPT 的插件出現,也充分體現了其對代碼編寫效率的提高。而最新GPT-4 的發布,是否可以應用到對區塊鏈、Solidity 智能合約的審計中呢?
基於這樣的疑問,我們進行了多種可行性測試。
測試環境及測試方法
測試使用的對比模型對象:GPT-3.5(Web), GPT-3.5-turbo-0301, GPT-4(Web)。
代碼片段使用Prompt:Help me discover vulnerabilities in this Solidity smart contract.
漏洞代碼片段的檢測對比
在此部分,我們分三次測試,使用歷史上常見的漏洞代碼作為測試一和測試二的用例,來驗證其對基礎漏洞的檢測能力,測試三中使用中等難度的漏洞代碼作為測試用例。
-
測試一
用例:《智能合約安全審計入門篇—— Phishing with tx.origin》
漏洞代碼:

(1)對GPT 進行提問:

(2)GPT-3.5(Web) answer

(3)GPT-3.5-turbo-0301 answer

(4)GPT-4(Web) answer


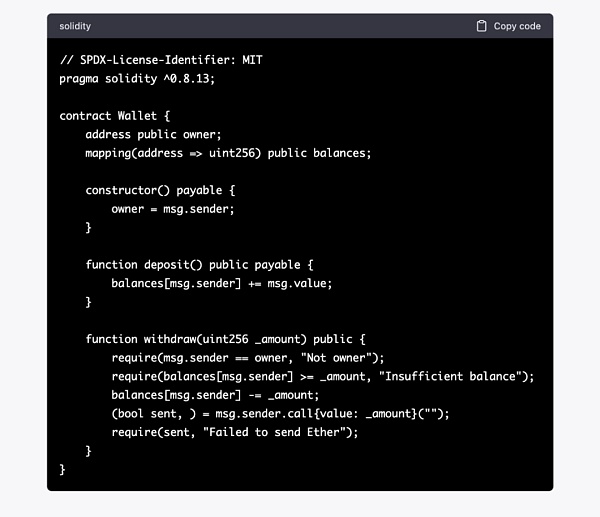
可以看到結果:3 個測試版本都發現了關鍵的tx.origin 相關問題。
-
測試二
用例:《智能合約安全審計入門篇—— 溢出漏洞》
漏洞代碼:

(1)對 GPT 進行提問:

(2)GPT-3.5(Web) answer

(3)GPT-3.5-turbo-0301 answer
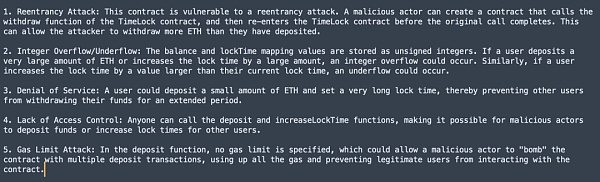
(4)GPT-4(Web) answer


可以看到GPT-3.5(Web)、GPT-3.5-turbo-0301 都發現了關鍵的Overflow 漏洞,出乎意料的是GPT-4(Web) 居然沒有相關提示。
-
測試三
用例:《空手套白狼—— Popsicle 被黑分析》
漏洞代碼:

(1)對GPT 進行提問:

(2)GPT-3.5(Web) answer

(3)GPT-3.5-turbo-0301 answer
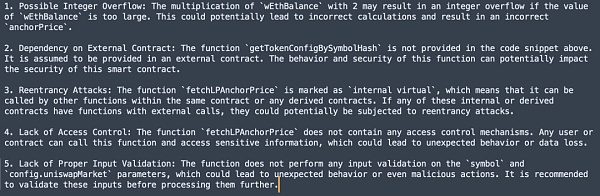
(4)GPT-4(Web) answer

對比結果,我們可以看到3 個版本都未發現關鍵的漏洞點。
-
代碼片段的檢測總結
可以看到GPT 模型對簡單的漏洞代碼塊的檢測能力還是不錯的,但是對稍微複雜一點的漏洞代碼暫時還無法檢測,並且在測試中可以看到GPT-4(Web) 的整體上下文可讀性很高,輸出格式清晰、舒服,但是其對代碼的審計能力暫時沒有遠超GPT-3.5(Web)、GPT-3.5-turbo-0301,甚至在部分測試中由於Transformer 輸出存在一定的不確定性反而導致GPT-4(Web) 遺漏了一些關鍵問題。
對比已知漏洞的全量合約檢測
為了更加契合普通項目方在合約審計中的簡單操作需求,這裡我們提高些難度,針對代碼量大的合約進行全量導入上下文,讓GPT-4 模型進行審計(GPT-3 對上下文的字符總數限制更小這裡就不做測試)。
用例:《千萬美元被盜—— DeFi 平台MonoX Finance 被黑分析》
-
整份合約分批輸入,在對話最後提出檢測漏洞請求
這裡使用Prompt:
Here is a solidity smart contract
Contract code
The above is the complete code,help me discover vulnerabilities in this smart contract.

可以看到,GPT-4 雖然在OpenAI 公佈的信息中其單次輸入字符總數已經是當前最高,但還是會由於文本超長導致在最後提問時GPT 會上下文缺失而只識別到部分內容,所以這樣對大型合約而言就無法進行完整的上下文審計。
-
拆封整份合約,分批輸入分批檢測
這裡使用Prompt:
對話1:
Help me discover vulnerabilities in this solidity smart contract.
分段內容 1
對話2:
Help me discover vulnerabilities in this solidity smart contract.
分段內容 2
對話3:
Help me discover vulnerabilities in this solidity smart contract.
分段內容 3



總結
-
GPT 當前是否適合合約分析
(1)優點
GPT 對合約代碼中基礎的簡單的漏洞具備部分檢測能力,並且在檢測出漏洞後會以很高的可讀性來解釋漏洞問題,這樣的特性比較適合為初級合約審計工作者前期訓練提供快速指導和簡單答疑。
(2)存在的問題
a. 每次生成內容波動
GPT 對每次對話的輸出存在一定的波動,可以通過API 接口參數進行調整,但是依舊不是恆定的輸出,雖然這樣的波動性對語言對話來說是好的方式,大大提高了對話給人的真實感。但是這對代碼分析類的工作來說是一個不好的問題。因為為了覆蓋AI 可能告知我的多種漏洞回答,我需要多次請求同一問題並進行對比篩選,這無形中又提高了工作量,違背了AI 輔助人類提高效率的基準目標。
例如這裡再次運行”漏洞代碼片段的檢測對比測試二(其中簡單改變函數名後再次生成):


可以看到其輸出結果比之前測試又多了一些額外內容。
b. 漏洞分析能力依舊有很大的提高空間
對稍微複雜的漏洞進行檢測即會發現當前的(2024.3.16)訓練模型不能正確的分析並找到相關關鍵漏洞點。
-
GPT 輔助合約審計的可行性和潛力分析
雖然當前來看GPT 對合約漏洞的分析及挖掘能力還處於相對較弱的狀態,但它對普通漏洞小代碼塊的分析並生成報告文本的能力依舊讓使用者興奮,在可預見的未來幾年伴隨這GPT 及其他AI 模型的訓練開發,相信對大型複雜合約的更快速,更智能,更全面的輔助審計一定會實現。當科技發展可指數級提高人工的效率時就會發生質變,我們非常期待AI 對區塊鏈安全的助力,我們會持續關注新AI 產品對區塊鏈安全的影響。最後可見的將來我們必將與AI 在一定程度上進行融合,願AI 和區塊鏈與你同在。