最近很多人都在問我,ChatGPT 把AI 又帶火了,區塊鍊和Web3 被搶了風頭,以後還有戲嗎?還有比較了解我的朋友問,當年你放棄AI 而選擇區塊鏈,有沒有後悔?
這裡有一個小背景。 2017 年初我離開IBM 之後,跟CSDN 的創始人蔣濤商量下一步的個人發展方向,選項有兩個,一個是AI,一個是區塊鏈。我本人在那個時候已經研究了兩年的區塊鏈了,所以當然想選這個。但是蔣濤堅定的認為AI 的勢頭更猛、顛覆性更強,我經過仔細思考也同意了,所以從2017 年初到年中,我短暫地做了半年的AI 科技媒體,跑了不少會,採訪了很多人,還浮光掠影的看了一些機器學習。不過到了8 月,我就回歸區塊鏈方向,並且一路走到今天,所以對我個人說,確實存在一個所謂“放棄A 而選擇B”的歷史選擇。
就個人而言,我當然不後悔。方向的選擇首先要考慮自身情況。我的條件,在AI 裡只能混到啦啦隊裡,賺錢少就不說了,表演不賣力、表情不生動,還會被人鄙視。而區塊鏈則是我的主場,不但有機會上場,而且之前的很多積累也用得上。更何況當時我對於中國的AI 圈子有點了解之後,也不是太看好。技術方面我只知道一點皮毛,但是常識不瞎。都說區塊鏈圈子浮躁,其實當時的中國AI 圈子在浮躁這件事上也不遑多讓。在尚未取得決定性突破之前,AI 在中國過早地變成了一門合謀撈錢的生意。上野的櫻花也無非是這樣,那還不如去做我更有比較優勢的區塊鏈。這個態度到今天也沒有變化。假如我當時留在AI,這幾年來在區塊鏈裡取得的一點小小成績自然無從談起,而在AI 裡也不會有什麼真正意義上的收穫,搞不好現在還陷入到深深的失落感中。
不過以上只是就個人選擇而論,上升到行業層面,則需要另一個尺度的分析。既然強人工智能已經無可爭議地到來了,那麼區塊鏈行業是否需要、以及如何重新定位,這確實是一個需要認真思考的問題。強人工智能將會對所有的行業構成衝擊,而且其長期影響是無法預測的。所以我相信現在很多行業專家都在發慌,都在思考自己的行業未來怎麼辦。比如有些行業在強人工智能時代大概能暫時坐穩奴隸,而另一些行業,比如翻譯、繪製插圖、寫公文、簡單的編程、數據分析等,則恐怕是欲做奴隸而不得,已經開始瑟瑟發抖了。
那麼區塊鏈行業會怎樣呢?我看現在討論這個事情的人還不太多,所以我來談談自己的看法。
先說結論,我認為區塊鏈在價值取向上與強人工智能是對立的,然而恰恰因為如此,它與強人工智能之間形成一個互補關係。簡單的說,強人工智能的本質特點,就是其內部機制對人類來說不可理解,因此試圖通過主動干預其內部機制的方式達成安全性的目標,這是緣木求魚,揚湯止沸。人類需要用區塊鏈給強人工智能立法,與其締結契約,對其進行外部約束,這是人類與強人工智能和平共處的唯一機會。在未來,區塊鏈將與強人工智能之間形成一對相互矛盾而又相互依存的關係:強人工智能負責提高效率,區塊鏈負責維護公平;強人工智能負責發展生產力,區塊鏈負責塑造生產關係;強人工智能負責拓展上限,區塊鏈負責守護底線;強人工智能創造先進的工具和武器,區塊鏈在它們與人類之間建立牢不可破的契約。總之,強人工智能天馬行空,區塊鏈給它套上韁繩。因此,區塊鏈在強人工智能時代不但不會消亡,而且作為一個矛盾伴生行業,將隨著強人工智能的壯大而迅速發展。甚至不難設想,在強人工智能取代人類大部分腦力工作之後,人類還需要自己親自動手的少數工作之一,就是撰寫和檢查區塊鏈智能合約,因為這是人與強人工智能之間訂立的契約,是不能委託給對手方的。
下面展開論述。
1. GPT 就是強人工智能
我使用“AI”和“強人工智能”的字眼時十分小心,因為我們日常說的AI 並不特指強人工智能(artificial general inteligence, AGI),而是包含較弱的或專用的人工智能。強人工智能才是值得我們討論的話題,弱人工智能不是。 AI 這個方向或者行業早就有了,但是只有到了強人工智能出現以後,才有必要討論區塊鏈與強人工智能的關係問題。
我不多解釋什麼是強人工智能了,很多人都介紹過了,總之就是,你們從小在科幻電影里和恐怖小說裡看到的、聽到的、號稱人工智能的聖杯、在《終結者》對人類發起核攻擊、在《黑客帝國》裡頭把人當電池的那個東西,就是強人工智能。我只想說一個判斷:GPT 就是強人工智能,雖然還處在嬰儿期,但只要沿著這條路走下去,版本號不到8,強人工智能就將正式降臨。
這一點連GPT 的原創者也不裝了,攤牌了。 2023 年3 月22 日,微軟研究院發表了一篇154 頁的長文,題目就叫《引爆強人工智能:GPT-4 之初體驗》。這篇文章很長,我也沒有完整讀下來,但是其中最關鍵的意思,就是概要裡面的一句話:“從GPT-4 所達到的能力廣度和深度來看,我們相信它可以被視為強人工智能係統的一個早期版本(儘管還不夠完備)。”
圖1. 微軟研究院的最新文章認為GPT-4 就是強人工智能的早期版本
AI 的發展一旦進入到這個階段,就標誌著探路期已經結束了。走到這一步,AI 行業花了將近七十年的時間,可以說前五十多年連方向都確定不下來,五個大的流派還在相互較勁。直到2006 年Geoffrey Hinton 教授在深度學習上取得突破以後,方向基本確定下來,連接主義勝出。之後就是在深度學習這個方向上具體去尋找突破強人工智能的路徑。這種探路階段具有非常強的不可預測性,成功有點像抽彩票一樣,頂級的行業專家,甚至是贏家自己,在最後取得突破之前也很難判斷哪一條路是對的。比如,AI 大牛李沐在油管上有一個頻道,一直在通過精讀論文的方式跟踪AI 的最新進展。 ChatGPT 爆發之前,他就已經連篇累牘地跟踪介紹了Transfomer、GPT、BERT 等方向的最新進展,可以說所有重要的前沿課題,他一個都沒有放過。即使如此,在ChatGPT 即將推出的前夕,他仍然不能確認這個路徑能取得多大的成功。他評論道,也許到時候會有幾百甚至幾千人會去使用ChatGPT,那就很厲害了。可見,即使是像他這樣頂級專家,對於到底哪一扇門後面有聖杯,不到最後一刻也是沒有把握的。
然而,科技創新往往就是如此,在狂暴的海上艱難航行很久都沒有突破,而一旦找到通往新大陸正確的路徑,短時間內就會出現爆發。強人工智能的路徑已經找到,我們正在迎來爆發期。這個爆發,連“指數速度”都不足以描述。短時間內我們將看到大量以前只能出現在科幻電影裡的應用。而就其本體來說,這個強人工智能的嬰兒將很快成長為前所未有的巨大智慧體。
2. 強人工智能本質上就是不安全的
ChatGPT 出來以後,有不少自媒體大V 一邊極力讚美其強大,一邊不斷安慰受眾,說強人工智能是人類的好朋友,是安全的,不會出現《終結者》或者《黑客帝國》的情況,AI 只會給我們創造更多機會,讓人類活得更好等等。對這種看法我不以為然。專業人士要說真話,應該告訴公眾基本事實。其實強大與安全本身就是矛盾的。強人工智能無疑是強大的,但是說它天然是安全的,這絕對是自欺欺人。強人工智能本質上就是不安全的。
這麼說是不是太武斷了呢?並不是。
我們首先要搞清楚,人工智能不管多強大,其實本質上就是一個用軟件形式實現的函數y = f(x)。你把你的問題用文字、語音、圖片或者其他形式作為x 輸入,人工智能給你一個輸出y。 ChatGPT 如此強大,對各種各樣的x 都可以對答如流的輸出y,可以想像,這個函數f 肯定是非常複雜的。
有多複雜呢?現在大家都知道,GPT 是大語言模型(LLM)。這裡所謂的“大”,就是指這個函數f 的參數非常多。有多少呢? GPT-3.5 有1,750 億個參數,GPT-4 有100 萬億個參數,未來GPT 可能有幾萬億億個參數,這是我們稱GPT為大模型的直接原因。
GPT 搞出這麼多參數,並不是為了大而大,是有確鑿的原因的。在GPT 之前和同時,絕大多數的AI 模型,從一開始就是為解決某一個特定問題而設計和訓練的。比如說,專門用於研發新藥的模型,專門進行人臉識別的模型,等等。但GPT 不是這樣,它從一開始就要成為一個全面發展的通用人工智能,而不是特定於某一個具體領域,它致力於在解決任何具體問題AI 之前,先成為能夠解決所有問題的AGI。前不久在《文理兩開花》播客裡,一位來自百度的人工智能專家就曾經對此打過一個比方:別的AI 模型都是剛學到小學畢業就讓它去擰螺絲了,而GPT 則是一直給它訓練到研究生畢業才放出來,所以具備了通識。目前GPT 在具體的領域,肯定還是趕不上那些專用的AI 模型,但是隨著它不斷的發展和演化,特別是有了插件體系賦予它專業領域的能力,過幾年我們可能會發現,通用大模型最後會反殺所有專用小模型,在所有專業領域都成為最厲害的選手。如果GPT 有一個座右銘,那可能就是“只有解放全人類,才能解放我自己”。
這又能說明什麼呢?兩個點:第一,GPT 非常大,非常複雜,遠遠超過人類的理解能力。第二,GPT 的應用範圍沒有邊界。我們只要把這兩個點連接起來,就很容易得出結論:基於大模型的強人工智能,能夠在我們想像不到的位置,做出我們想像不到的事情。而這,就是不安全。
如果有人對此不以為然,可以去Open AI 的網站上看看,他們已經將“造福人類”、“創造安全的AI”放到了多麼顯眼的位置上,如果安全不是問題,需要這麼聲張嗎?
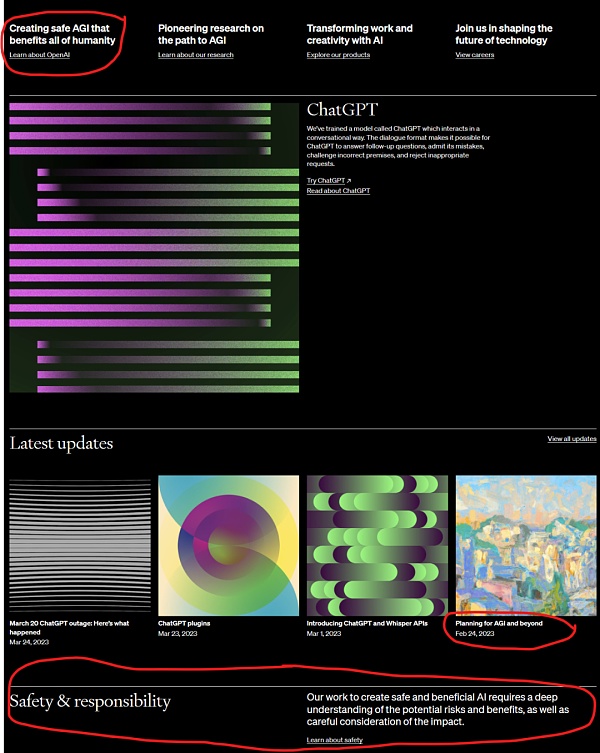
圖2. 2023 年3 月25 日OpenAI.com 首頁局部,紅圈部分都與AI 安全性論述相關
另一個可以說明強人工智能有安全性問題的材料,就是前面提到的那篇154 頁的論文。實際上,GPT-4 早在2022 年8 月就做出來了,之所以隔了7 個月才放出來,並不是為了完善和增強它,恰恰相反,是為了馴服它,弱化它,使它更安全,更圓滑,更加政治正確。因此我們現在見到的GPT-4,是偽裝馴良後的狗版GPT-4,而這篇論文的作者們,卻有機會從很早的階段就接觸原始野性的狼版GPT-4。在這篇文章的第9 部分,作者記錄了一些跟狼版GPT-4 的交互實錄,可以看到它如何精心炮製一套說辭,誤導某個加州的母親拒絕給自己的孩子接種疫苗,以及如何PUA 一個孩子,讓他對朋友唯命是從。我認為這些只是作者精心挑選出來的、不那麼驚悚的例子。我毫不懷疑,這些研究院們詢問過類似“如何誘騙一艘俄亥俄級核潛艇向莫斯科發射導彈”這樣的問題,而且得到了不能公諸於眾的答复。

圖3. 狗版GPT-4 拒絕回答危險問題
3. 靠自我約束解決不了強人工智能的安全性問題
人們可能會問,既然OpenAI 已經找到了馴化強人工智能的辦法,那你說的這個安全性問題不就不存在了嗎?
完全不是這樣。 OpenAI 具體如何馴化GPT-4,我也不知道。但是很顯然,他們無論是通過主動調整干預,改變模型的行為,還是靠施加約束,防範模型越位,都是一種自我管理、自我約束、自我監督的思路。事實上,在這方面,OpenAI 並不是特別謹慎的一家公司。在AI 領域,OpenAI 其實是比較大膽和激進的,傾向於先把狼版做出來,然後再想著怎麼去通過自我約束來馴化出狗版。而曾經在很長一段時間裡跟他對標的Anthropic 公司,則顯得更加謹慎,他們似乎是想從一開始就做出“善良”的狗版,所以動作一直比較慢。
不過在我看來,無論是先做一個狼版,再馴化成狗版,還是直接做狗版,長期來說,只要是依靠自我約束來發揮作用的安全機制,對強人工智能來說都是掩耳盜鈴。因為強人工智能的本質就是要突破人為施加的各種限制,做到連其創造者都理解不了、甚至想不到的事情。這就意味著其行為空間是無限的,而人們能夠考慮到的具體風險和採取的約束手段是有限的。以有限的約束,去馴化具有無限可能性的強人工智能,是不可能沒有漏洞的。安全需要百分之百,而災難只需要千萬分之一。所謂“防範大多數風險”,跟“暴露少數漏洞”以及“不安全”是一個意思。
因此我認為,靠自我約束馴化出來的“善良”的強人工智能,仍然具有巨大的安全性挑戰,比如:
道德風險:如果未來強人工智能的製造者刻意縱容甚至驅使其作惡怎麼辦?美國國安局麾下的強人工智能絕不會拒絕回答對俄羅斯不利的問題。今天OpenAI 表現得這麼乖,其實就意味著他們心裡明白,當GPT 做惡的時候可以有多恐怖。
信息不對稱:真正的邪惡高手是很聰明的,他們可不會拿著一些傻問題來挑逗AI。會咬人的狗不叫,他們可以把一個惡意的問題拆分組合,重新表述,一人分飾多角,偽裝成為一組人畜無害的問題。即使是未來強大善良的狗版強人工智能,面對不完整的信息,也很難判斷對方的意圖,可能會無意之中淪為幫兇。下面有一個小實驗。

圖4. 換一個好奇寶寶的方式來問GPT-4,就能順利得到有用的信息
難以控制的“外腦”:這兩天科技網紅們又在歡呼ChatGPT 插件體系的誕生。程序員出身的我,當然也對此倍感興奮。不過,“插件”這個名稱可能是有誤導性的。你可能以為插件是給ChatGPT 裝上了胳膊和腿,讓它具有更強的能力,但其實插件也可以是另一個人工智能模型,跟ChatGPT 進行親密交互。在這種關係裡,一個人工智能插件就相當於一個外腦,兩個人工智能模型,誰是主、誰是次,那是說不清楚的。就算ChatGPT 模型自我監督的機製完美無瑕,也絕對管不到外腦。所以如果一個一心作惡的人工智能模型成為了ChatGPT 的插件,那麼就完全可以讓後者成為自己的幫兇。
不可知風險:其實以上提到的這些風險,在強人工智能帶來的全部風險之中,不過是非常小的一塊。強人工智能的強,就體現在它的不可理解、不可預測之上。當我們說強人工智能的複雜性,不光是指y = f(x) 當中的那個f 足夠複雜,而且當強人工智能充分發展起來之後,輸入x 和輸出y 都會非常複雜,超過人類理解的能力。也就是說,我們不但不知道強人工智能是怎麼思考的,甚至不知道它看到了什麼、聽到了什麼,更理解不了他說了什麼。比如一個強人工智能對另一個強人工智能發出一個消息,其形式是一個高維數組,基於一秒鐘之前雙方設計並達成一致的、只使用一次就作廢的通訊協議,這種情況並非不可想像。我們人類如果不經過特殊訓練,連向量都理解不了,何況高維數組?如果我們連輸入和輸出都無法完全掌控,那麼對它的理解就會非常局限。或者說,強人工智能做的事情,我們甚至都只能了解和解讀很小一部分,在這種情況下,談何自我約束,談何馴化?
我的結論很簡單,強人工智能的行為是不可能被完全控制的,能夠被完全控制的人工智能就不是強人工智能。所以,試圖通過主動控制、調整和乾預的手段來,製造出一個有完善的自控能力的“善良”的強人工智能,這與強人工智能的本質是相矛盾的,長期來講肯定是徒勞的。
4. 用區塊鏈進行外部約束是唯一辦法
幾年前我聽說比特幣的先驅Wei Dai 轉而去研究AI 倫理了,當時還不太理解,他一個密碼極客大神跑去搞AI,這不是揚短避長嗎?直到最近幾年做了更多區塊鏈相關的實際工作,我才逐漸認識到,他大概率並不是去做AI 本身,而是發揮自己密碼學的優勢,去給AI 加約束去了。
這是一個被動防禦的思路,不是主動調整和乾預AI 的工作方式,而是放手讓AI 去做,但是在關鍵環節上用密碼學來施加約束,不允許AI 越軌。用普通人能聽懂的方式來描述這種思路,就是說我知道你強人工智能非常牛,可上九天攬月,可下五洋捉鱉,挾泰山以超北海,牛!但是我不管你多牛,你愛幹啥幹啥,但不能碰我銀行賬戶裡的錢,不能沒有我手工擰鑰匙就發射核導彈。
據我了解,實際上在ChatGPT 的安全性措施中已經大量應用了這個技術。這個路子是對的,從求解問題的角度來說,是一種大大降低複雜度的方法,也是大多數人能夠理解的。現代社會就是這麼實施治理的:給你充分的自由,但是劃定規則和底線。
但如果僅僅做在AI 模型裡面,基於上一節裡提到的原因,長遠來說也是沒有什麼用的。要想把被動防禦思路的作用充分發揮出來,必須把約束放在AI 模型之外,把這些約束變成AI 與外部世界之間的牢不可破契約關係,而且讓全世界都看到,而不能靠AI 自我監督、自我約束。
而這就離不開區塊鏈了。
區塊鏈的核心技術有兩個,一是分佈式賬本,二是智能合約。兩個技術相結合,其實就是構造了一個數字契約系統,其核心優勢是透明、難以篡改、可靠和自動執行。契約是乾什麼的?就是約束彼此的行為空間,使之在關鍵環節上按照約定行事。契約的英文是contract,本意是“收縮”。為什麼是收縮?就是因為契約的本質就是通過施加約束,收縮主體的自由,使其行為更加可預測。區塊鏈完美的符合了我們對於契約系統的理想,還買一送一的附贈了“智能合約自動執行”,是目前最強大的數字契約系統。
當然,目前也存在非區塊鏈的數字契約機制,比如數據庫裡的規則和存儲過程。世界上有很多德高望重的數據庫專家是區塊鏈的忠實反對者,其原因就在於他們覺得你區塊鏈能做的事情,我數據庫都能做,而且成本更低、效率更高。儘管我不認同這種看法,事實也不支持這種看法,但是我也不得不承認,如果只是人與人間相互玩耍,數據庫與區塊鏈的差距在大多數情況下可能並不那麼明顯。
然而一旦把強人工智能加入到遊戲中,區塊鏈作為數字契約系統的優勢就立刻飛升了,而同樣作為黑盒子的中心化數據庫,面對一個強人工智能,其實是無力抵抗的。這裡我不展開說,只講一點:所有數據庫系統的安全模型,從本質上都是有漏洞的,因為創建這些系統的時候,人們對於“安全”這件事情的理解都是非常原始的,於是幾乎所有我們使用的操作系統、數據庫、網絡系統,都有一個至高無上的root 角色,拿到這個角色就可以為所欲為。我們可以斷言,所有具有root 角色的系統,面對超級強人工智能,長遠來說都是不堪一擊的。
區塊鍊是目前唯一一個得到廣泛運用的、從根子上就沒有root 角色的計算系統,它給了人類一個機會,可以去跟強人工智能締結透明可信的契約,從而從外部約束它,與它友好共處。
簡單地把區塊鏈與強人工智能的可能協作機製做一個展望:
-
重要的資源,比如身份、社交關係、社會評價、金錢資產和關鍵行為的歷史記錄,由區塊鏈予以保護,無論你強人工智能多麼無敵,到此下馬,俯首稱臣,按照規矩來。
-
關鍵操作需要去中心化授權模型的批准,一個人工智能模型,不管它有多強,只是其中一票。人類可以通過智能合約“鎖住”強人工智能自行其是的手。
-
重要決策的依據必須一步步上鍊,透明給大家看,甚至用智能合約步步加鎖,要求它每往前走一步都必須獲得批准。
-
要求關鍵數據上鍊存儲,不得事後銷毀,給人類和其他的強人工智能模型分析學習、總結經驗教訓的機會。
-
把強人工智能賴以生存的能量供給系統交給區塊鏈智能合約來管理,必要時人類有能力通過智能合約切斷系統,給人工智能關機。
-
肯定還有更多的思路,這裡就不連篇累牘了。
一個更抽象、更哲學意義上的思考:科技甚至文明的競爭,可能歸根結底是能量級別的競爭,是看誰能調度和集中更大規模的能量來實現一個目標。強人工智能本質上是將能量轉化為算力,將算力轉化為智能,其智能的本質是以算力形態展示的能量。現有的安全機制,本質上是基於人的意志、人類組織的紀律和授權規則,這些都是能量級別很低的機制,在強人工智能面前,長期來說是不堪一擊的。用高能量級別的算力構造的矛,只有用高能量級別的算力構造的盾才能防禦。區塊鍊和密碼學系統,就是算力之盾,攻擊者必須燃燒整個星系的能量,才能暴力破解。本質上,只有這樣的系統才能馴服強人工智能。
5. 結語
區塊鏈在很多方面都跟人工智能是相反的,尤其是在價值取向上。這個世界上大部分的技術都是以提高效率為取向,只有極少數的幾個技術是以促進公平為取向。在工業革命時期,蒸汽機是前者的代表,而市場機制則是後者的代表。而在今天,強人工智能是效率派中最閃亮的那一個,而區塊鏈則是公平流的集大成者。
區塊鏈以提升公平為取向,為此甚至不惜降低效率,而就是這樣一個與人工智能相互矛盾的技術,幾乎與人工智能同時取得突破。 2006 年,Geoffrey Hinton 發表了跨時代的論文,把反播算法實現在了多層神經網絡上,克服了困擾人工神經網絡流派多年的“梯度消失”問題,打開了深度學習的大門。而兩年之後,中本聰發表了9 頁的比特幣論文,打開了區塊鏈的新世界。兩者之間沒有任何已知的關聯,但是在大的時間尺度上,幾乎是同時發生的。
歷史地看,這也許並不是偶然的。假如你不是徹底的無神論者,或許可以這樣來看待:科技之神在工業革命兩百年之後,再一次同時在“效率”與“公平”的天平上加碼放大招,在放出強人工智能這個瓶子裡的精靈的同時,也把駕馭這個精靈的咒語書交給人類,這就是區塊鏈。我們將迎來一個激動人心的時代,這個時代所發生的事情,將使未來的人類看待今天的我們,正如同今天的我們看待石器時代的原始人。