

大模型的應用是機會,但“基礎科學”是繞不過的必修課。
又一家中國互聯網巨頭在追趕ChatGPT了。
3月底舉行的博鰲亞洲論壇上,騰訊集團高級執行副總裁湯道生披露,騰訊正在研發AIGC以及大模型相關技術,類ChatGPT的對話機器人也在醞釀中。
百度、華為,如今再加上騰訊,ChatGPT出現之後,中國的互聯網科技企業似乎一夜覺醒。不光公司,還有資本及創業大佬。
3月19日,創新工場董事長兼CEO李開復在朋友圈高調宣布,正在親自籌組中文版ChatGPT公司“Project AI 2.0”。重燃創業野心的也不止李開復,美團王慧文、阿里賈揚清、搜狗王小川、京東周伯文均親自下場,趕赴大模型賽道。
“大佬攢局”往往是賽道火熱的信號,僅今年前三個月,上萬家新註冊的公司在經營範圍中寫上了人工智能。企業如雨後春筍般湧現,人才緊俏起來。應了周鴻禕那句話:一人捅破窗戶紙,千軍萬馬獨木橋。
這一次不光是資本生意,還有需求催生。在人工智能上,以OpenAI為代表的搶跑選手引領自然語言大模型風潮,從產品上甩開中企老遠,而中國還沒有合格的ChatGPT滿足各行各業對AIGC的體驗。
騰訊們、李開復們現在做大模型還來得及嗎?投入10年的李彥宏說,應用更靠譜。但真正稀缺的,仍然是底層基礎設施。
互聯網大佬帶頭組隊
作為目前全球最火的自然語言大模型產品,ChatGPT至今不對中國用戶開放,背後的算法、芯片、數據更是全部被控制在美國公司手中。國產ChatGPT進入需求井噴期,一大批中國公司趕來,有互聯網大廠,有資本大佬,也有創業公司,誰都不想錯過這一次的AI革命。
3月19日,創新工場董事長兼CEO李開復在朋友圈宣布,成立Project AI 2.0公司,“不僅僅要做中文版ChatGPT,”他這個公司定位為AI 2.0全新平台和AI-first生產力應用的“世界級公司”,野心頗大。
一個月前,美團聯創王慧文在朋友圈發“英雄帖”,出資5000萬美元,要創立新公司打造中國版OpenAI。此外,阿里巴巴“框架大神”賈揚清、搜狗前任CEO王小川、京東曾經的AI掌門人周伯文都表明了同樣的意願。
互聯網大佬蜂擁入局,中國企業重燃熱情,包括創業企業和上市公司。
企查查數據顯示,近三個月共有108601家新註冊業企業在經營範疇中標註了人工智能,同比增長超24%。 《元宇宙日爆》統計,截至今年3月,已有20家上市公司佈局了AIGC相關應用,涉及世紀虛擬人、AI寫作、AI視頻、AI繪畫、AI營銷等。
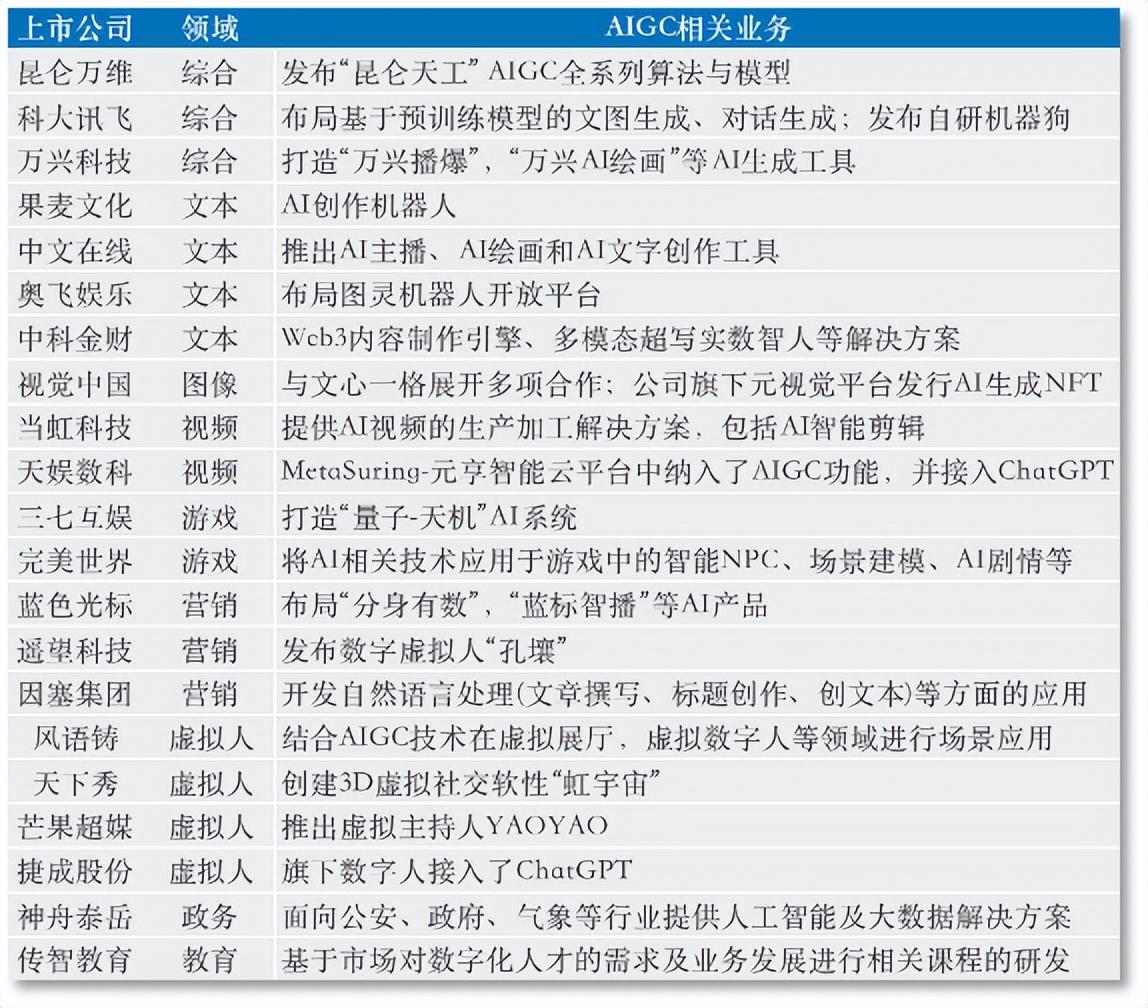 國內上市公司AIGC相關佈局
國內上市公司AIGC相關佈局
AIGC創業公司千帆競發,涉及領域包括上游的底層框架與工具、中游的行業服務、下游的包括文字、圖像、視頻、音頻、遊戲等應用場景,創業方向也從C端的娛樂遊戲拓寬至工業、金融、醫療、教育等2B領域。不同應用場景已出現了一批代表性的玩家。

國內創業公司AIGC相關佈局
而在底層大模型上,中國互聯網科技巨頭的動作則最受矚目,包括百度、華為、騰訊在內大廠均有自然語言大模型佈局。
3月16日,百度履行承諾,發布基於文心大模型的生成式AI產品文心一言,27日又面對企業發布了智能雲AI底座文心千帆。
3月27日,華為雲官網顯示,旗下的盤古系列AI大模型即將上線,涉及NLP(自然語言)大模型、CV(計算機視覺)大模型和科學計算大模型(氣象大模型)。
3月30日,騰訊集團高級執行副總裁湯道生披露,騰訊正在研發AIGC以及大模型相關技術,並向澎湃新聞表示,正在研發類ChatGPT的對話機器人,對於對於騰訊的聊天機器人是集成到QQ、微信,還是通過騰訊雲向B端用戶服務,湯道生說:“都會有。”
國內AI“三算”與海外存差距
人工智能在當下的中國展現出全面開花的熱鬧。而資金雄厚、人才濟濟的大廠被視作最能與OpenAI比肩的選手。但最早發布產品的百度,其文心一言在文本、代碼生成上尚不及ChatGPT的體驗,圖片生成的效果則被Midjourney拉開了距離。
賽道火熱,產品不佳。中國的人工智能發展進入至暗時刻。缺的不僅是有實力的大模型,還有與之直接相關的人才和AI“三算”,即算力、算法、算據。
先是業內爆出,百度文心大模型團隊內的研發人員近期受到了其他公司的瘋狂追捧,有3年左右相關經驗的員工,可以直接給到原先年薪的兩倍。而有涉及海內外人才市場的獵頭稱,諸多互聯網大廠的第一訴求就是就是想找OpenAI項目裡的華人。獵聘大數據研究院的統計數據也顯示,近一年,AIGC相關新發崗位同比增長了42.5%。
搶人大戰不僅在國內上演。
由於一大批矽谷AI大牛排著隊擠進OpenAI,谷歌一度遭遇AI人才流出。據外媒體統計,近幾個月OpenAI已經僱用了超過12名谷歌的AI人才。
但從公開消息看,到目前為止,還沒有哪位OpenAI背景的華人專家流入中國大廠。
AI人才緊俏,以芯片為核心硬件基礎的算力一直被視為“卡脖子”的狀態,而國產大模型的算據也與GPT-4存在肉眼可見的差距,預訓練等大模型算法的距離直接以“肉眼可見”的產品拉胯擺在了用戶面前。
在算據上,國產大模型也與GPT-4存在差距。
在自然語言大模型中,參數是衡量一個深度學習模型複雜度和能力的重要指標。參數多,意味著模型能夠處理更多的數據,學習更多的知識。國外有研究人員將GPT參數規模與大腦神經元做類比,GPT-3的規模與刺猬大腦類似,GPT-4擁有100萬億個參數,基本達到人類大腦的規模。
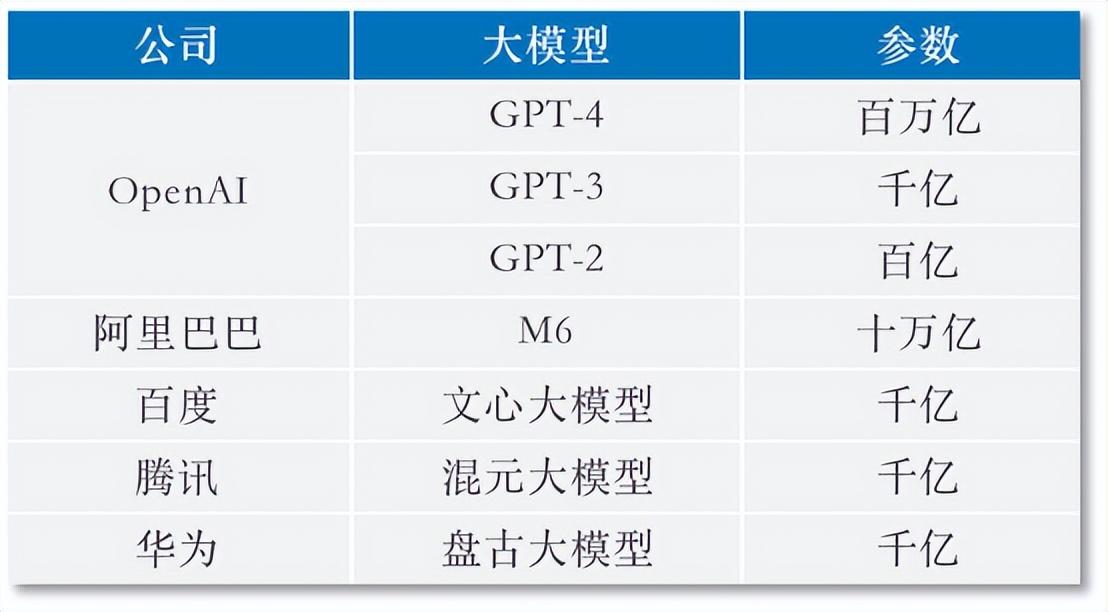 大模型參數對比
大模型參數對比
再看國產大模型,即使是排名靠前的M6大模型,其參數規模也仍與GPT-4相差一個數量級,更多的大模型仍在“原始階段”。
GPT-4百萬億的參數需要強大的算力來完成訓練。算力,同樣是AI的核心競爭要素,核心的核心是芯片。
在AI芯片競爭方面,英偉達處於壟斷地位,該公司推出的A100與H100是目前性能最強的數據中心專用GPU,市面上幾乎沒有可替代的方案。 ChatGPT的訓練用的正是英偉達頂配版A100。
然而,在中美競爭下,A100與H100已被限制出口中國,中國廠商只能用閹割版A800芯片,數據傳輸速度被降低了30%,影響著AI集群的訓練速度和效果。而國產優質芯片,雖能夠為預訓練大模型提供算力支撐,但仍存在明顯差距。
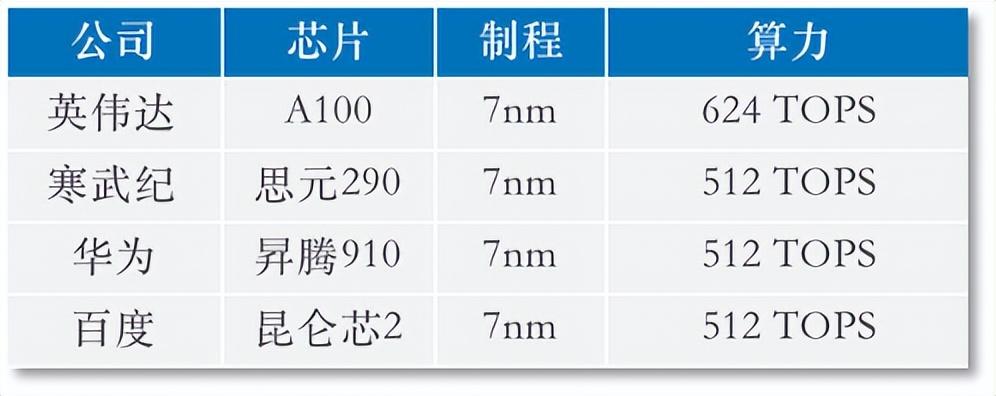
芯片性能對比
以OpenAI為例,該公司使用了數万塊英偉達A100進行海量數據訓練和推理。如果以1萬枚英偉達A800 GPU為標準,僅CPU採購成本就超10億美元。
如此現狀下,國內的大模型研發機構面臨兩種選擇,“燒錢”購買更多的芯片,等待國產芯片的算力突破。但現在的競爭態勢下,等已經等不起了。
高昂的前期投入成本絕非普通創業公司可以負擔,還要具備絕對頂尖的研發技術。很顯然,AI大模型仍是巨頭的遊戲。但掌握先發優勢的OpenAI以“日更”速度向前躍進,互聯網巨頭與資本面臨著一場“燒錢”硬仗。
OpenAI搶跑中企如何赶超?
回顧ChatGPT的迭代,OpenAI至少進行了三次技術路線的”自我革命”。
從2018年GPT-1的推出到今年的GPT-4,OpenAI用了近5年。而百度在自然語言大模型的研發上用了10年。
連李彥宏也認為,中國基本不會再出現一個OpenAI,“沒有必要再重新發明一遍輪子”,在他看來,“大模型時代,最大的創業機會在應用,”他的判斷基於上一次的移動互聯網變革,“操作系統其實沒幾個,最成功的是微信、抖音、淘寶這些應用。”他指出,未來10年,應用領域可能誕生10倍價值的機會。
周鴻禕也在公開場所表示,目前中國發展GPT技術,首先要佔據應用場景,同步全力發展核心算法技術。為什麼要同步?如果等算法趕上GPT-4再上馬,市場就錯過了。
另闢賽道,在現有大模型的基礎上創新產品應用可能是大部分企業的超車機會。
就像移動互聯網時代,儘管中國沒有自己的操作系統,但仍有Tiktok這樣的超級應用在海外市場殺出一片天。應用先行的優勢是能快速的將AI生產力轉化為商業價值,這是在移動互聯網時代中國互聯網企業探索出的超車捷徑,也是在激烈的AI競爭中,大部分中企們赶超ChatGPT最經濟、最現實的路徑。
但由於GPT-3之後,OpenAI的所有模型就沒有再開源,GPT-4的運行機制是什麼,國內企業仍無從得知。
面對競爭對手全面的科技封鎖,中國人工智能想要長期發展就不能沒有“根”。曠視科技CEO印奇認為,中國攻堅AI 大模型目前最重要的是要先能把GPT-3.5復現出來,”這是所有事情的起點”。
無論如何,發展好自身的硬實力,不在關鍵技術上被“卡脖子”,將是AI時代下中企們無法逃避的“必修課”。
針對國產AI大模型,周鴻禕指出:“發展大語言模型,別人已經指明了技術路線,剩下的就是長期主義指導下的時間問題,”他認為,“中國有能力發展自己的GPT,差距大概2年。”
百度有文心大模型,阿里有M6,華為的盤古大模型箭在弦上,騰訊的混元大模型也在不斷迭代。當李開復、王慧文等一眾互聯網大佬也親赴大模型戰場時,底層的重要價值已經不言而喻了。
就像《三體》故事裡的明喻一般,“基礎科學”一旦被“智子”鎖死,人類便永遠失去探索宇宙真相的機會。底層大模型就是那個基礎科學,在人工智能上,中國想要超越,不光需要資本、巨頭,更需要的是能頂得住研發壓力的“面壁人”。
展開全文打開碳鏈價值APP 查看更多精彩資訊
