
原文標題:ZK Hardware Acceleration: The Past, the Present and the Future
原文作者:Luke Pearson and the Cysic team
原文來源:hackmd
編譯:Kate, Marsbit
摘要:
●在硬件加速ZKP中,FPGA具有與GPU相同的每瓦性能水平,但在每美元性能指標上無法與GPU競爭。
●ASIC在上述兩個指標上優於FPGA和GPU,但需要更長的時間才能進入市場。
介紹
近年來,零知識證明(ZKP)的重要性呈指數級增長,成為過去半個世紀計算機科學中最重要的創新之一。這可以歸因於ZKP有可能極大地增強區塊鏈平台(如以太坊)的可擴展性。 ZKP的一個關鍵方面是它們能夠顯著提高各種區塊鏈平台上的每秒交易量(TPS),這完全依賴於數學原理而不是信任。通過使驗證者能夠將多個交易合併到一個單一的、簡潔的證明中,ZKP確保了整個過程的準確性和完整性。 ZKP提供了許多其他功能,使它們成為各種擴展和隱私解決方案的重要組成部分,包括像StarkNet這樣的ZK聚合,像Aztec這樣的私有ZK聚合,以及像Mina、Filecoin、Manta和Aleo這樣的第1層鏈。儘管如此,ZKP也不是沒有局限性,因為生成證明的過程在時間和精力方面都是非常耗費資源的。由於需要許多複雜的數學運算,例如冪運算、倒數運算和雙線性配對計算,證明的創建通常會減慢速度。因此,優化ZKP解決方案以充分利用其潛力仍然是一項挑戰。為了克服所有提出的ZKP構造的這些問題,開發硬件加速方法是至關重要的。也就是說,通過使用專用硬件,如現場可編程門陣列(FPGA)和專用集成電路(ASIC),它們可以加速10-1000倍。
在本文中,我們將概述與ZKP相關的計算挑戰,然後討論有助於解決這些問題並提高這些加密技術效率的潛在改進。
零知識證明:zkSNARKs和zkSTARKs
zkSNARK (Zero-Knowledge Succinct Non-Interactive ARgument of Knowledge) 方案是一種ZKP,它允許證明者說服驗證者,證明者知道一個證人,而不透露有關該證人的任何信息。該方案包括四種算法:Setup、KeyGen、Prove和Verify。 Setup算法生成一些結構化的參考字符串,KeyGen算法將使用該字符串為某些指定電路生成證明密鑰和驗證密鑰。證明者擁有證明密鑰和陳述/見證對,可以通過指定的電路對陳述/見證對的關係生成ZK證明。驗證者可以使用驗證密鑰和聲明來檢查ZK證明的有效性。
zkSNARK方案需要滿足以下特點:
●完整性:如果證明者擁有證人,他們可以產生有效的證明,並且驗證者將始終接受它。
●零知識:證明方可以提供證據,證明其擁有秘密證人,而無需向驗證方或其他任何人披露有關秘密證人的任何信息。
●可靠性:對於不誠實的證明者來說,不需要證人就能提出有效的證明是不可能的。
另一種變體稱為zkSTARK (Zero-Knowledge Scalable and Transparent ARgument of Knowledge)。它可以在零知識的情況下運行,也可以在沒有零知識的情況下運行,並且可以是交互式或非交互式協議。它們也可以取代zkSNARK作為交互協議。與zkSNARK不同,交互式證明不需要可信的Setup設置階段,這使STARK系統成為更好的選擇。 STARK系統通過利用交互式Oracle證明(IOP)域克服了這一缺點,該域依賴於快速Reed-Solomon代碼來提高可擴展性,從而開發了zkSTARK證明系統。此外,基於zkSTARK的系統對於證明者和驗證者來說都具有對數複雜度,使它們變得高效,並防止一方執行拒絕服務(DoS)攻擊,因為每一方的計算需要相似的時間。 zkSTARK的另一個值得注意的特性是推測的後量子安全性,而zkSNARK則不是由於Shor的量子算法。 zkSTARK系統提供後量子安全,前提是框架內使用的哈希函數本身能夠抵抗量子計算攻擊。
在區塊鏈技術領域,通常使用縮寫SNARK和STARK來代替zkSNARK和zkSTARK,因為某些區塊鏈平台可能並不總是需要隱私功能。因此,在本文中,我們也將在討論和解釋中採用簡化的術語“zk”。 ZKP有兩個重要的用例:
●外包可驗證計算:假設我們需要進行一項計算,由於底層平台的限制(例如,智能手機、Raspberry Pi、筆記本電腦,甚至是以太坊等區塊鍊網絡),該計算要么成本昂貴,要么無法運行。在這種情況下,我們可能不得不在第三方服務上運行計算,它可以快速而廉價地返回計算的輸出(例如像Chainlink或AWS Lambda函數這樣的預言機服務)。然而,在許多情況下,我們必須依賴於計算已經正確執行的假設,從而使服務提供者有可能生成不准確的結果。這種結果可能導致嚴重的後果,並損害系統的完整性。
●私有計算:如果在本地執行計算的成本不高,但它的某些部分需要是私有的,那麼ZKP也很有用。換句話說,ZKP可以確保計算已經正確執行,甚至不需要向外包提供商披露私有值。例如,如果我們想在不披露實際數字的情況下證明我們知道第1000個斐波那契數,或者在不披露我們的身份或支付金額的情況下證明我們進行了有效的支付,ZKP可以很容易地幫助實現這一目標。更進一步,我們可以通過ZKP選擇性地披露一些私有值,同時隱藏其他部分(也稱為選擇性披露)。
在區塊鏈的背景中,ZKP的上述用例如下:
●第2層擴展:通過將ZKP合併到可驗證的計算中,第1層區塊鏈可以將交易處理委託給鏈下的高性能係統,通常稱為第2層。這種方法增強了區塊鏈的可擴展性,同時保持了強大的安全措施,在效率和安全性之間取得了平衡。 StarkWare開發了StarkNet,這是一個可擴展的智能合約平台,使用專門的虛擬機來執行ZK友好的代碼,而Aztec允許他們的第二層程序私下運行,保護用戶的交易信息。
●私有第1層:Aleo, Mina, Manta和Zcash是第1層區塊鏈,使用ZKPs使交易者能夠默認(如Aleo)或通過選擇加入過程(如Mina和Zcash)隱藏發送方,接收方或金額。
●數據壓縮:Mina和Celo利用ZKP將同步到鏈的最新狀態所需的區塊鏈數據壓縮為簡短的證明。
●去中心化存儲:Filecoin還使用ZKP(在GPU上運行)來證明網絡中的節點正確存儲數據。
因此,隨著加密貨幣的採用不斷擴大,對增強性能和隱私的需求也將增加,從而推動了對更複雜的ZKP應用程序的需求。隨著開發人員創建新的應用程序和協議,ZKP將在促進安全和高效的去中心化系統方面發揮關鍵作用。這些系統將能夠處理大規模交易,同時保護用戶隱私,滿足數字貨幣領域不斷變化的需求。
為什麼ZKP這麼慢,怎樣才能提高它們的速度?
為了證明使用ZKP的計算,有必要將計算從經典程序轉換為ZK友好的格式。有兩種方法可以做到這一點:要么使用某種現有語言編寫的庫,比如Arkworks(在Rust中),要么使用領域特定語言(DSL),比如Cairo或Circom,它可以編譯成生成證明所需的原語。操作越複雜,生成證明所需的時間就越長。此外,一些操作本身就不是ZK友好的,需要進行額外的工作。例如,SHA或Keccak中使用的按位函數等操作可能與ZKP不友好,從而導致證明生成時間延長。即使對於在傳統計算機上執行的相對便宜的操作,也可能發生這種情況。將計算轉換為ZK友好格式後,選擇一些輸入並將其提交給證明系統。有許多證明系統,如Groth16、PLONK、HyperPlonk、UltraPlonk、Sonic、Spartan和STARK。所有這些系統都具有相同的基本功能,即接受具有輸入的ZK友好計算並生成證明作為輸出。根據不同的證明系統,證明生成過程可能不同,但瓶頸最終是相似的。
在ZKP的背景中,主要有兩個計算任務:
●大型數字向量的乘法,可以是字段或組元素。在這種情況下,還有兩種特定類型的乘法:可變基數和固定基數多標量乘法(MSM)。
●數論變換(NTT)與逆數論變換。然而,也有技術可用於無NTT的證明系統,如最近的HyperPlonk系統。
在同時存在NTT和MSM的系統中,生成證明的時間約有60%花在MSM上,其餘時間由NTT主導。 MSM和NTT都存在性能挑戰,可以通過以下方式解決:
●MSM可以在多個線程上執行,從而支持並行處理。然而,當處理大型元素向量時,例如6700萬個元素,乘法運算可能仍然很慢,並且需要大量的內存資源。此外,MSM存在可擴展性方面的挑戰,即使在廣泛並行化的情況下也可能保持緩慢。
●在算法過程中頻繁的數據混洗使得NTT難以在計算集群中分佈,並且由於需要從大型數據集中加載和卸載元素,它們在硬件上運行時需要大量帶寬。即使硬件操作很快,這可能也會導致速度變慢。例如,如果硬件芯片的內存為16GB或更少,那麼在100GB的數據集上運行NTT將需要通過網絡加載和卸載數據,這可能會大大降低操作速度。
我們認為,硬件加速是使區塊鏈協議獲得實際應用所需的可擴展性的重要組成部分。目前,區塊鏈協議受到鏈上計算和存儲容量以及網絡帶寬的限制。通過優化鏈下硬件和證明生成,我們有信心大大提高區塊鍊網絡的性能,使其更加有效和高效。
ZPrize零知識工具競賽
ZPrize是區塊鏈行業的一個集體倡議,由超過32個合作夥伴和讚助商組成,他們貢獻了自己的時間、資源和努力來確保其成功。該計劃提供了一系列挑戰和項目,激勵參與者開發創新的解決方案,促進可持續發展和減少碳排放。他們為實現這兩個目標感到自豪,這標誌著零知識密碼學領域的重大進步。 ZPrize的結果超出了他們的預期,如下圖所示。對於他們收到的大多數獎項,與基線相比平均提高了五倍以上。值得注意的是,一些涉及FPGA的獎項缺乏公開基準,這使得這些參賽作品成為開源形式的算法實現的首次公開演示。以下是一些值得注意的成就:
●對於大規模問題實例,GPU上的多標量乘法(2的26次方元素)從5.8秒提高到2.5秒,從而支持更複雜的zkSNARKs使用。
●Poseidon零知識友好哈希函數實現將約束計數減少了一半,從而顯著降低了在SNARK中創建Merkle樹的成本。
●針對小規模問題實例,Android移動設備上的多標量乘法從2.4秒改進到大約半秒,從而促進了基於ZK的移動支付。
在接下來的幾個月裡,他們計劃展示所有參與該計劃的團隊的工作。隨著零知識密碼學領域的發展,新的方法和障礙將會出現。他們希望定期組織ZPrize競賽,以促進這項技術的進步,並通過一系列開源材料將其提供給公眾。
加速ZKP的技術方法
證明生成的瓶頸通常源於大量向量的乘法,包括字段或組元素,變量或固定基數的多標量乘法,以及NTT和逆NTT。在同時使用NTT和MSM的加密系統中,MSM貢獻了大約70%的證明生成時間,而NTT支配了剩餘的時間。雖然MSM是可並行的,但它仍然很慢,需要大量的內存資源,並且經常消耗設備上的大部分可用內存。另一方面,NTT嚴重依賴於頻繁的數據混洗,這會使跨計算集群分配負載的加速變得複雜。此外,NTT需要大量的帶寬才能在硬件上運行,因為通過網絡加載和卸載數據會顯著降低操作速度,儘管硬件操作本身非常快。然而,有一些方法可以提高MSM和NTT的性能,以優化證明生成過程。
MSM通常使用Pippenger算法來實現,以最小化組添加操作的數量。該方法有一個簡單的硬件實現,其中包括一個組添加單元和一堆表作為其基本組件。從系統設計的角度來看,MSM是對加速器非常友好的,原因如下:
●組添加是一種靜態操作(沒有依賴於數據的控制流),具有密集的計算和相對較小的輸入/輸出,使其非常適合全流水線的體系結構。這使得加速器可以實現幾乎100%的硬件利用率,而在最好的GPU實現中只有20%的利用率。幾十年的研究已經使組添加成為一種穩定的操作,因此它不太可能在ASIC加速器的壽命內被取代。
●MSM 在全局調度能力相對較弱的大規模並行硬件(如GPU)上實現的痛點可以通過向加速器添加額外的硬件調度器輕鬆解決。例如,以這種方式更有效地處理一堆表的更新,避免了寫衝突的風險。
總之,使用專用硬件加速MSM是非常有利的。然而,主要問題是市場上缺乏這樣的硬件。 Cycis設計了一個使用Xilinx FPGA的MSM加速器,它展示了迄今為止最好的系統性能(在BN254曲線上每2的26次方MSM約40毫秒)。不幸的是,與為普通玩家設計的GPU相比,專業用戶的FPGA芯片成本高,加上FPGA的處理滯後(FPGA為14nm, GPU為5nm),這是兩個顯著的缺點,這兩個重大缺點抵消了基於FPGA的加速器的利用優勢。
NTT由多層蝶式操作器組成。雖然教科書上逐層的NTT實現可能很快就會因為內存帶寬利用率(由於跨行訪問)而成為瓶頸,但這個問題可以通過同時執行一批層並在計算期間適當地重新排序NTT數據來解決。根據經驗,內存訪問可以重組為塊訪問,其粒度大約為(片上內存容量的大小)/ (NTT點的k次方根),其中k是表示層組數量的可調參數。通過這種方法,GPU和加速器都能獲得出色的性能。
硬件加速可以通過在各種硬件技術(如GPU、FPGA或ASIC)上部署優化算法來增強區塊鏈協議的性能。增強軟件和算法實現以更有效地利用CPU 和GPU 等現有資源,以及開發定制硬件與針對特定硬件配置量身定制的新算法相結合,可以促進硬件加速。通過這樣做,目前受鏈上計算和存儲容量以及網絡帶寬限制的區塊鍊網絡的性能可以得到顯著提高。
現在和將來,什麼是最好的硬件?
為了確定實現上述加速技術的最佳硬件技術,我們需要考慮到ZKP仍處於開發的早期階段。因此,在系統參數和證明系統的選擇上,如FFT寬度或元素的位大小,標準化程度有限。此外,我們還需要考慮兩個因素:
●每美元的性能:這衡量你需要為硬件性能支付多少資金。根據我們的經驗,FPGA在這個指標上無法與GPU競爭。根據ZPrize競賽提交和我們的內部基準測試結果,單個RTX3090 GPU可以產生比單個高端FPGA高約2.5倍的性能。高端FPGA和高端GPU的價格大致相同,這意味著FPGA最終將比GPU系統貴大約2.5倍。
●每瓦性能:這個指標是關於你需要花多少錢來維護硬件,基本上就是電費。在這個指標上,FPGA與GPU大致處於同一水平。
基於上述兩個指標,這是否意味著FPGA無法超越GPU?答案是否定的。雖然單個FPGA芯片無法與單個GPU競爭,但大規模互連的FPGA系統可以擊敗大規模互連的GPU系統。由於PCIe插槽的限制,一個高端GPU系統最多可以有10個GPU卡。然而,數百個FPGA芯片可以通過定制的、可編程的、高帶寬的互連連接在一起,從而達到可以擊敗GPU系統的性能水平。 Cysic的大規模連接FPGA系統直接證明了這一點。
ZKP的ASIC怎麼樣?
ASIC被一致認為是ZKP的理想硬件。然而,在為ZKP構建ASIC方面,有三個主要問題。
●可編程性:就ZKP邏輯修改而言,ASIC具有一次寫入業務邏輯,這需要從頭開始重建整個系統。相反,FPGA或GPU可以多次重新編程,從而可以在具有不同證明系統或潛在更新的不同項目中使用相同的硬件。與ASIC相比,此屬性使FPGA成為更通用的替代方案。
●高成本:構建ASIC是一個資本密集型的遊戲。 20 名工程師的全掩模28nm ASIC 芯片設計通常需要花費800 萬美元,而30 名工程師的全掩模5nm/4nm ASIC 設計通常需要花費2500 萬美元。
●上市時間。 ASIC的設計、生產和部署通常需要12到18個月甚至更長時間,這比FPGA/GPU要長得多。
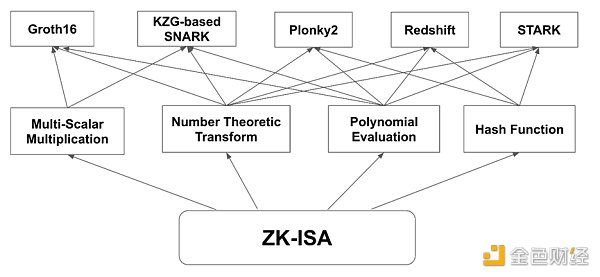
第一個問題可以使用硬件中的一個框架來解決,該框架稱為指令集架構(Instruction-Set Architecture, ISA)。 ISA是指硬件系統的抽象框架和設計,如CPU和硬件加速器。它表示處理器可以執行的一組基本指令和操作。這些指令包括算術運算、數據移動、邏輯運算、控制流和其他低級功能。使用ISA,硬件加速ZKP可以分為三層:
●方案層:各種ZK證明系統都在這一層,如Groth16和Plonk。頂層調用內核層來完成計算。
●核心層:核心層的任務是計算上層使用的不同函數。函數包括多標量乘法、數論傳遞、多項式求值和各種哈希函數。它依賴於指令層來執行計算。
●指令層:這一層是ISA,涵蓋了最基本的操作,包括算術運算、數據移動、邏輯運算和控制流。上述結構如下圖所示:
這個ISA結構提供了一個支持多個ZK系統和潛在更新的解決方案。可以使用ZK- ISA對AZK(用於ZK的ASIC)進行編程,以支持ZK系統的多功能性。
至於做ASIC的其他問題,這是由市場決定的。目前ZK相關項目的估值總計超過100億美元,我們認為花費大約1000萬美元來構建ASIC以提高ZK證明生成的效率是值得的。這種上市時間問題是所有ASIC設計所固有的。幸運的是,ASIC的供應鏈問題現在比以前好得多了。解決這個問題的唯一辦法是儘早開始,徹底預熱供應鏈。當ASIC問世時,它可以摧毀任何其他形式的ZK硬件。
結論
ZKP具有促進可擴展和私有支付系統以及智能合約平台的潛力,從而大大提高區塊鏈技術的可用性和安全性。確實,ZKP引入了歷史上阻礙其採用的管理費用。諸如巨大的計算和驗證成本,以及實現基於ZKP的系統的複雜性等因素,可能會對許多開發人員造成進入的障礙。儘管如此,ZKP領域正在進行的研究和開發正在解決這些挑戰,簡化這些技術在實踐中的實現和應用。
考慮到GPU在靈活性、易於部署和預期性能方面的優勢,我們相信,在ASIC技術出現之前,專注於GPU解決方案的公司更有可能在未來幾個月蓬勃發展。如果ASIC達到了優勢的規模和穩定性,它們可能成為優化算法的首選硬件。因此,ZKP有望在未來實現越來越先進和安全的區塊鏈系統中發揮關鍵作用。