
可控,AI繪畫落地生產的關鍵一環。
作者:逗砂
原標題:《AI繪畫可控性研究與應用》
這是昨天在清華美院課程的文字稿和PPT,主要分享的是AI繪畫可控性的研究和應用。梳理了一下AI繪畫可控性的一些整體知識脈絡,和最新發布的controlnet 1.1。
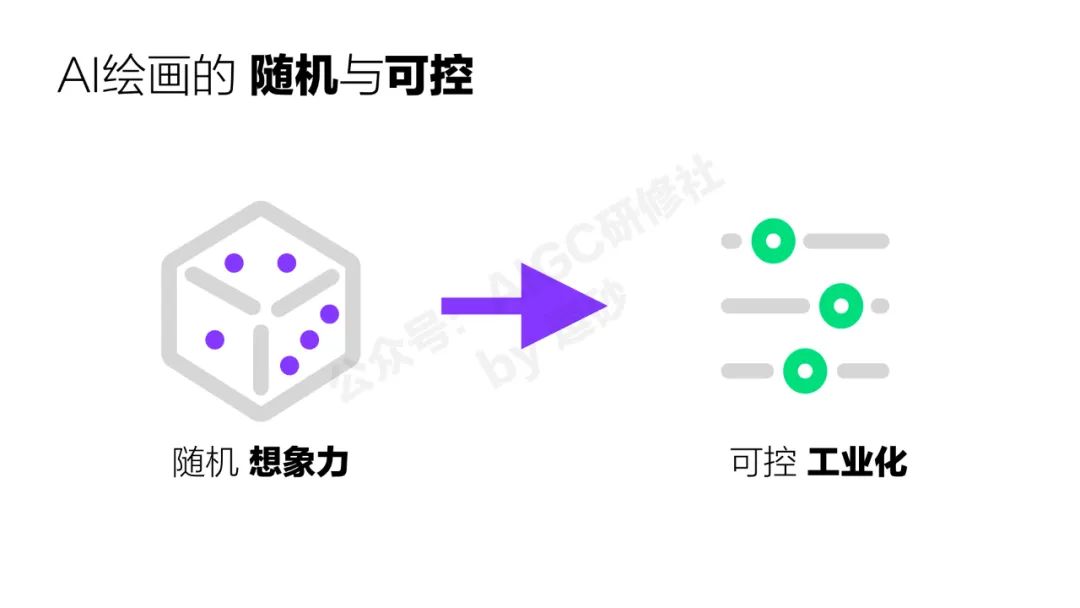
目前的AI繪畫大部分都是基於diffusion這個模型的,我們可以注意到無論是現在最流行的開源的stable diffusion 還是最開始的disco diffusion,他們都是基於擴散算法的,這個算法的優勢在於它的隨機性,隨機性可以給我們帶來很多意想不到的結果,擴散模型生成的每一張圖都不一樣。這個特性最大的好處就是可以帶來無窮無盡的想像力,很多時候這些想像力甚至會超越人類自己。
但是這些隨機性帶來的想像力有一個很大的問題,就是它不可控。大家都戲稱這種創作叫抽卡式創作,你也不知道最終的生成效果是什麼樣的。有時候運氣好出來一張非常驚豔的圖,但是不可複現,感覺跟你也沒啥關係。
這就是去年開始早期AI繪畫的狀況,它雖然可以生成很多漂亮的圖片了,但是它本質上還是一個玩具,因為所有的設計領域都需要對結果可控,對於設計師來說,不能修改,不能控制畫面中的內容,無法精準的滿足甲方爸爸的要求,這種工具也只能在早期頭腦風暴的階段使用。
但是後面出現的微調模型和controlnet,把這個狀態打破了。所以我說controlnet的出現補完了AI繪畫工業化生產的最後一塊拼圖。 AI繪畫這個工具正式的進入設計師的工作流了。

我們現在回到AI繪畫的可控性有哪些這個問題上。廣義上來講,AI繪畫的生成結果可以通過下面幾種方式控制。
第一個就是提示詞,文生圖的意思就是通過文字去控制畫面。其實從去年到現在市面上有大量的教程教你如何去寫提示詞,我們把特別擅長寫提示詞的人稱為提示詞工程師。但是作為一個最廣泛的控製手段,提示詞有它的局限性,這個一會講。
除了文字提示之外,我們還可以使用圖片作為提示,也就是墊圖。圖片提示可以更加精準的控制畫面的構圖和元素。
我們還可以使用AI繪畫進行圖片編輯,塗抹掉不想要的部分然後重新生成,這個技術最早出現在dalle2上,後面迅速的被應用到了SD上。
在最近剛更新的controlnet1.1版本里其實把圖像提示和圖像編輯都整合進去了。我們今天會重點講解controlnet1.1的功能。
最後還有一種控制方式也非常重要,叫微調模型,目前市面上最流行的微調模型叫lora。微調模型是通過收斂好的模型來更加精準的控制輸出的風格和元素。

我們剛剛提到了提示詞控制畫面有它的局限性,這個局限性主要體現在哪些方面呢?
下面這幾張圖是同一提示詞在midjourney不同模型算法的下的生成結果。我這裡只使用了一個單詞女孩。我們可以看到在初代版本的人物生成結果是非常差的,這個跟早期disco diffusion 的效果類似。我記得去年4五月份還有很多人去花了大量時間研究怎麼寫提示詞和調整參數讓DD來畫出一個像樣點的人物圖。
可是隨著MJ算法的迭代和SD的出現,這些對提示詞的研究瞬間就失去了意義。我們可以看到從MJ的第三代算法開始,人物生成已經越來越好了,三代算法對於一些手部的細節還有瑕疵。所以那個時候很多人嘲笑AI不會畫手,但是最新版本的MJ算法已經解決了這個問題。
這個過程大家可以看到,提示詞的生成效果極度的依賴與模型算法。所以我不建議花太多時間去研究提示詞,提示詞掌握到78分就差不多了,因為今天研究的東西,廢了很多時間總結出來的規律可能新的技術一出來就完全失效了。
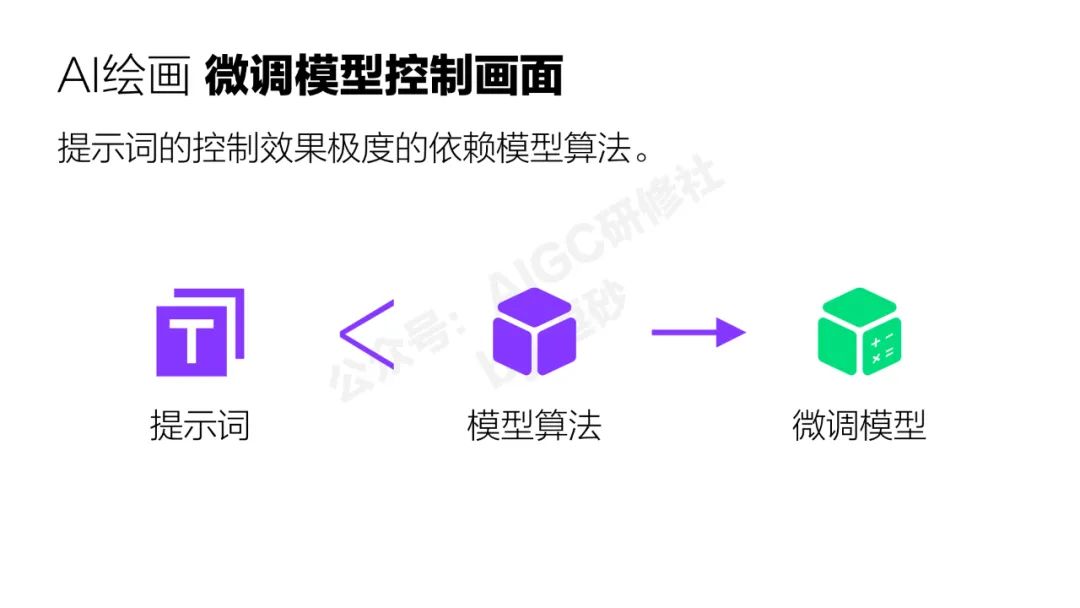
提示詞的生成效果極度依賴模型,模型對生成結果的影響力遠大於提示詞,這個特性我們可以發現,通過微調模型去控制AI繪畫的生成結果是一條比寫提示詞更有效的方式。

那麼有哪些微調模型的自訓練方式呢?
目前市面上主要有四種基於SD的微調模型方法。這四種方法裡目前最流行的是一款叫lora的方法。
接下來我挨個介紹一下這四種方法的不同之處和應用範圍。

首先是這個embedding的微調模型,它是通過使用文本提示來訓練模型的方法。它的原理其實是通過在大模型的隱空間,找到對應特徵的圖像文字映射,然後通過打包重新定義這個映射來達到穩定輸出特定圖像的效果。
因為它並不會改動原有的大模型,所以文件非常小。效果也還好,並且對系統計算資源要求不高。

接下來這個hypernetwork 其實是一種針對畫風訓練的微調模型。生成的模型文件要比embedding大一些。

前面這兩種方法其實對於精準生成特定的物體效果都不太理想。 dreambooth其實是目前為止最能穩定生成特定人或者物的微調模型。比如你有一個產品需要訓練模型,dreambooth是最能讓每個產品的細節特徵都復現的。而且它不需要太多的數據集就可以訓練,前面兩種動不動就是幾十張上百張的數據,它都不需要,dreambooth最少使用3~5張圖就可以了。
話說回來dreambooth這麼好,為什麼現在不流行呢?因為它有個很大的問題就是模型文件太大了。而且對訓練設備的性能要求很高。而且它的訓練時間也很慢。

那麼我們現在來看看目前最流行的lora。它其實是一種為了簡化微調超級大模型需要大量的算力而產生的算法。它對於算力的要求不高,模型大小也適中,對於人物復現的精確度要優於embedding,已經很接近dreambooth了,最重要的是,它還能通過調整權重進行多模型的融合。我們可以像調雞尾酒一樣調整模型。

那麼如何使用微調模型去應用到設計的工作流上呢?
其實方式有非常多,可以穩定生成特定的人物或者畫風,在遊戲,廣告,動畫等等領域都有非常大的應用空間。
這裡我舉兩個在品牌營銷方面的例子。
這是可口可樂通過微調模型穩定的輸出品牌logo,然後讓用戶自己去生成創意圖片的一個活動。
除了這個國外的案例,去年國內也有一個類似的例子。

雪佛蘭做過一個這樣的活動。它通過讓用戶使用微調好的模型,穩定的生成雪佛蘭汽車在不同環境場景下的圖片。通過這個方式讓用戶參與到品牌的宣傳之中。

從這兩個活動中我們可以發現什麼?
過去的廣告方式都是中心化的,廣告公司生產創意,然後同一個內容讓用戶被動接受。
但是AIGC時代的營銷方式,可以讓每個用戶即是創意的生產者也是傳播者和接收者。這很像病毒營銷,但是比傳統的病毒營銷要好。
過去的病毒營銷只是同一創意的轉發,沒有強的參與感,aigc讓每個人都有參與創作的可能。
在這個語境下,設計師需要設計如何引導用戶生產內容,而不是自己做一個多麼厲害的作品。
微調模型延展資料
國外模型平台:
https://civitai.com/
國內模型平台:
https://draft.art/model
國內在線訓練微調模型的產品:
右腦科技:https://work.rightbrain.art/ 目前免費
特贊AIGC Playground:https://musedam.cc/home/ai 目前免費
無界AI:https://www.wujieai.com/pro 做了個colab的國內鏡像版收費
最後,我補充一些關於微調模型的資料,大部分市面上的教程,都是基於雲端colab或者本地訓練的,這個我就不重複了。
國內可以簡單使用的產品還有下面幾個。一個是右腦科技的產品,這個目前還是免費的效果也還不錯。
還有的就是特讚的AIGC平台,這個目前暫時也是免費的,無界ai做了一個雲端的鏡像版本,這個是按算力收費的。
除了這幾個訓練模型的平台之外,國內外還有一些模型的聚合平台,這些平台上的模型大部分也都是可以調用的,大家自己訓練好之後也可以上傳到這些平台上。
微調模型部分就介紹到這裡。接下來重點講解contronlnet。

controlnet就是控製網的意思,其實就是在大模型外部通過疊加一個神經網絡來達到精準控制輸出的內容。
這個技術是今年二月由一個叫張呂敏的斯坦福博士生髮布的。這個人也挺神奇的,他本科在蘇州大學讀的醫學專業,後面才轉到編程。但是他從大一就在發表人工智能相關的論文了。
從2017年開始一致專注在AI填色這個領域。之前全世界最火的一款AI填色的程序也是他開發的。
2月的時候他發布了controlnet1.0版本,在火遍全世界之後就消失了,然後最近又發布了1.1的加強版。今天的內容主要針對這個最新版本。

我們接下來看看controlnet一共包含多少種不同的控制方式。我這里大致分了四個類別,首先最大的這個類別是通過邊緣或者線稿來控制,這個他分的非常細,一共有六種方式。這可能是跟他多年都在研究AI填色有關係。這六種模型裡面,canny精細邊緣控制用的最多,MLSD是主要應用在建築和室內的生成上。還有塗鴉這種針對粗糙線條的控制。
可以提取深度信息的主要有兩種,depth和normal,它們有一些細微的差別。
這個版本還增加了幾種圖像處理的模型,這幾種其實都是SD和dalle2之前已經有的功能,不過這次controlnet做了整合。控製網開始包含一切的控制方式。
最重要的部分其實是針對元素的細節控制,這裡有兩種語義分割和openpose的姿勢控制。

線的控制方式裡,用的最多的就是這種。這里分享一個針對品牌的比較有趣的玩法,就是可以提取品牌的邊緣然後生成各種有logo圖案的大場景。


normal的模型可以跟3D軟件結合進行快速的渲染,而不用通過貼圖和各種複雜的材質設置。

openpose應該是controlnet最重要的功能之一了,之前的1.0版本還只能控制大致的姿勢,現在已經對手部和麵部的細節也能很好的控制。我們既可以通過提取畫面中的人物姿勢去生成類似的圖像,也可以直接用調整好的姿勢圖來生成相應的圖。

openpose可以應用在漫畫,動畫,廣告海報,遊戲設計等諸多領域。不過目前只支持人物的姿勢,對於動物和其他類別還不能生成。





https://docs.google.com/spreadsheets/d/1se8YEtb2detS7OuPE86fXGyD269pMycAWe2mtKUj2W8/edit#gid=0



github地址:https://github.com/facebookresearch/segment-anything
demo演示地址:https://segment-anything.com/demo
論文地址:https://arxiv.org/abs/2304.02643



Controlnet 延展資料
controlnet高階組合用法合集
https://www.bilibili.com/video/BV1cL41197ji/?spm_id_from=333.337.search-card.all.click&vd_source=453933dd6891757733da4e4288779255
騰訊發布類似的controlnet的技術T2I-Adapters
https://github.com/TencentARC/T2I-Adapter
AIGC教程:如何用Stable Diffusion+ControlNet做角色設計?
https://mp.weixin.qq.com/s/-5U3oHWP4c4YN0X4Vji0LA
提供免費TPU 的ControlNet 微調活動來啦
https://mp.weixin.qq.com/s/o7PTTyTXsLjo8ayq93W55w
控制名為AI 的魔法,關於將AI 繪畫融合於工作流的案例和經驗。
https://mp.weixin.qq.com/s/U-ks7Fs0fSDHJp6rCmAYoA
遊戲要結束了:ControlNet正在補完AIGC工業化的最後一塊拼圖
https://mp.weixin.qq.com/s/-r7qAkZbG4K2Clo-EvvRjA
精確控制AI 圖像生成的破冰方案,ControlNet 和T2I-Adapter
https://mp.weixin.qq.com/s/ylVbqeeZc7XUHmrIrNmw9Q
ControlNet項目地址
https://github.com/lllyasviel/ControlNet
ControlNet 的WebUI 擴展
https://github.com/Mikubill/sd-webui-controlnet#examples
國內加入controlnet的產品
https://www.wujieai.com/lab 無界AI 付費
https://musedam.cc/home/ai 特贊AIGC Playground 目前免費ZQ
展開全文打開碳鏈價值APP 查看更多精彩資訊