

AI 基礎設施的高成本是否會成為護城河,阻擋新進入者的腳步?
撰文: Guido Appenzeller、Matt Bornstein 和Martin Casado
生成式人工智能的熱潮是以計算為基礎的。它的一個特性是,增加更多的計算量會直接導致更好的產品。通常情況下,研發投資與產品的價值更直接相關,而且這種關係明顯是次線性的。但目前人工智能的情況並非如此,今天推動該行業發展的主要因素僅僅是訓練和推理的成本。
雖然我們不知道真實的數字,但我們從可靠的消息來源聽說,算力的供應十分緊張,需求超過了10 倍!所以我們認為,現在,以最低的總成本獲得計算資源已經成為人工智能公司成功的決定因素。
事實上,我們已經看到許多公司在計算資源上花費的資金佔其總籌資額的80% 以上。
在這篇文章中,我們試圖分解AI 公司的成本因素。絕對數字當然會隨著時間的推移而變化,但我們不然我AI 公司受計算資源的訪問限制將立即緩解。因此,希望這是一個有助於思考的框架。
為什麼AI 模型的計算成本如此之高?
生成式人工智能模型種類繁多,推理和訓練成本取決於模型的大小和類型。幸運的是,今天最流行的模型大多是基於Transformer 的架構,其中包括熱門的大型語言模型(LLM),如GPT-3、GPT-J 或BERT。雖然transformer 的推理和學習操作的確切數量是特定於模型的(請參閱本文),但有一個相當準確的經驗法則僅取決於參數的數量(即神經網絡的權重)模型以及輸入和輸出Token 的數量。
Token 基本上是幾個字符的短序列。它們對應於單詞或單詞的一部分。獲得對token 的直覺的最好方法是使用公開的在線標記器(如OpenAI)嘗試標記化。對於GPT-3,一個token 的平均長度是4 個字符。
Transformer 的經驗法則是,對於一個具有p 個參數的輸入和一個長度為n 個token 的輸出序列的模型,前向通過(即推理)大約需要2*n*p 浮點運算(FLOPS)¹。對同一模型的訓練,每個token 大約需要6*p 浮點運算(即,額外的後向傳遞需要多四次運算²)。你可以通過將其乘以訓練數據中的token 量來估算總的訓練成本。
Transformer 的內存需求也取決於模型大小。對於推理,我們需要p 個模型參數來適應內存。對於學習(即反向傳播),我們需要在前向和後向傳遞之間存儲每個參數的額外中間值。假設我們使用32 位浮點數,這就是每個參數需要額外的8 個字節。對於訓練一個1750 億個參數的模型,我們需要在內存中保留超過一兆字節的數據– 這超過了目前存在的任何GPU,需要我們將模型分割到不同的卡上。推理和訓練的內存需求可以通過使用更短長度的浮點值來優化,16 位已成為普遍現象,預計在不久的將來會有8 位。
上表是幾個流行模型的規模和計算成本。 GPT-3 有大約1750 億個參數,對應1,024 個token 的輸入和輸出,計算成本大約為350 萬億次浮點運算(即Teraflops 或TFLOPS)。訓練一個像GPT-3 這樣的模型需要大約3.14*10^23 的浮點運算。其他模型如Meta 的LLaMA 有更高的計算要求。訓練這樣的模型是人類迄今為止承擔的計算量較大的任務之一。
總結一下:人工智能基礎設施之所以昂貴,是因為底層的算法問題在計算上極其困難。與用GPT-3 生成一個單詞的複雜性相比,對一個有一百萬個條目的數據庫表進行排序的算法複雜性是微不足道的。這意味著你要選擇能夠解決你的用例的最小模型。
好消息是,對於transformer,我們可以很容易地估計出一個特定大小的模型將消耗多少計算和內存。因此,選擇合適的硬件成為下一個考慮因素。
GPU 的時間和成本爭論
計算複雜性是如何轉化為時間的?一個處理器核心通常可以在每個週期執行1-2 條指令,由於Dennard Scaling的結束,在過去的15 年中,處理器的時鐘速率一直穩定在3 GHz 左右。在不利用任何並行架構的情況下,執行單個GPT-3 推理操作將需要350 TFLOPS/(3 GHz*1 FLOP)或116,000 秒,或32 小時。這是非常不切實際的;相反,我們需要專門的芯片來加速這項任務。
實際上,今天所有的AI 模型都在使用大量專用內核的卡上運行。例如,英偉達A100 圖形處理器有512 個”張量核心”,可以在一個週期內完成4×4 矩陣乘法(相當於64 次乘法和加法,或128 個FLOPS)。人工智能加速器卡通常被稱為GPU(圖形處理單元),因為該架構最初是為桌面遊戲開發的。在未來,我們預計人工智能將日益成為一個獨特的產品系列。
A100 的標稱性能為312 TFLOPS,理論上可以將GPT-3 的推理時間縮短到1 秒左右。然然而,由於多種原因,這是一個過於簡化的計算。首先,對於大多數用例來說,瓶頸不是GPU 的計算能力,而是將數據從專門的圖形存儲器送到張量核心的能力。其次,1750 億個權重將佔用700 GB,無法放入任何GPU 的圖形存儲器中。需要使用分區和權重流等技術。第三,有一些優化(例如,使用更短的浮點表示,如FP16、FP8 或稀疏矩陣),正在被用來加速計算。但是,總的來說,上面的數字讓我們對當今LLM 的總體計算成本有了直觀的了解。
訓練一個transformer 模型每個標記花費的時間大約是進行推理的三倍。然而,考慮到訓練數據集比推理提示大3 億倍,訓練需要10 億倍的時間。在單個GPU 上,訓練需要數十年;在實踐中,這是在專用數據中心的大型計算集群上進行的,或者更有可能是在雲端。訓練也比推理更難並行化,因為更新的權重必須在節點之間進行交換。 GPU 之間的內存和帶寬往往成為一個更重要的因素,高速互連和專用結構是很常見的。對於訓練非常大的模型,創建一個合適的網絡設置可能是首要挑戰。展望未來,AI 加速器將在卡上甚至芯片上具備聯網能力。
那麼,這種計算複雜性如何轉化為成本?正如我們在上面看到的,一個GPT-3 推理,在A100 上大約需要1 秒鐘,對於1000 個token 的原始計算成本在0.0002 美元到0.0014 美元之間(相比之下,OpenAI 的定價為0.002 美元/1000 個token)。這是一個非常低的價格點,使得大多數基於文本的人工智能用例在經濟上是可行的。
另一方面,訓練GPT-3 則要昂貴得多。在上述速率下,再次僅計算3.14*10^23 FLOPS 的計算成本,我們可以估計到A100 卡上的單次訓練費用為56 萬美元。在實踐中,對於訓練,我們不會在GPU 上獲得近100% 的效率;但是我們也可以使用優化來減少訓練時間。其他對GPT-3 訓練成本的估計從50 萬美元到460 萬美元不等,取決於硬件假設。請注意,這是一次運行的成本,而不是整體成本。可能需要多次運行,而云供應商將希望得到長期的承諾(下文有更多這方面的內容)。訓練頂級的模型仍然很昂貴,但對於資金充足的初創公司來說是可以承受的。
總而言之,當今的生成式人工智能需要對人工智能基礎設施進行大量投資。沒有理由相信這會在不久的將來發生改變。訓練像GPT-3 這樣的模型是人類有史以來計算量最大的任務之一。雖然GPU 變得越來越快,而且我們找到了優化訓練的方法,但人工智能的快速擴張抵消了這兩種影響。
AI 基礎設施的考慮因素
至此,我們已嘗試讓您對進行AI 模型訓練和推理所需的規模以及驅動它們的底層參數有了一定的了解。在這種背景下,我們現在想就如何決定使用哪種AI 基礎設施提供一些實用指南。
外部與內部基礎設施
GPU 很酷。許多工程師和有工程意識的創始人都偏向於配置自己的人工智能硬件,這不僅是因為它可以對模型訓練進行細粒度控制,還因為利用大量計算能力會帶來一些樂趣(附件A)。
然而,現實是,許多初創公司– 尤其是應用程序公司– 不需要在第一天就建立自己的人工智能基礎設施。相反,像OpenAI 或Hugging Face(用於語言)和Replicate(用於圖像生成)這樣的託管模型服務使創始人能夠迅速搜索產品與市場的契合度,而不需要管理底層基礎設施或模型。
這些服務已經變得如此之好,以至於許多公司可以直接依附於它們。開發人員可以通過提示工程和高階微調抽象(即通過API 調用進行微調)實現對模型性能的有意義的控制。這些服務的定價是基於消費的,所以它也經常比運行單獨的基礎設施更便宜。我們已經看到一些應用程序公司產生了超過5000 萬美元的ARR,估值超過10 億美元,它們在後台運行託管模型服務。
另一方面,一些初創公司– 特別是那些訓練新的基礎模型或建立垂直整合的人工智能應用– 無法避免直接在GPU 上運行自己的模型。要么是因為模型實際上是產品並且團隊正在尋找“模型- 市場契合度”,要么是因為需要對訓練和/或推理進行細粒度控制才能實現某些功能或大規模降低邊際成本。無論哪種方式,管理基礎架構都可以成為競爭優勢的來源。
雲與數據中心的構建
在大多數情況下,雲是你的AI 基礎設施的正確位置。對大多數初創企業和大公司來說,較少的前期成本,擴大和縮小規模的能力,區域可用性,以及較少因建立自己的數據中心而分心,是具有吸引力的。
但這一規則也有幾個例外:
- 如果你的運營規模非常大,運行你自己的數據中心可能會變得更有成本效益。確切的價位根據地理位置和設置而不同,但通常需要每年超過5000 萬美元的基礎設施支出。
- 你需要非常具體的硬件,而這些硬件你無法從雲供應商那裡獲得。例如,沒有廣泛使用的GPU 類型,以及不尋常的內存、存儲或網絡要求。
- 出於地緣政治的考慮,你無法找到一個可以接受的雲。
如果你確實想建立自己的數據中心,對於自己的設置,已經有了全面的GPU 價格/性能分析(例如,Tim Dettmer 的分析)。除了卡本身的成本和性能外,硬件的選擇還取決於電源、空間和冷卻。例如,兩塊RTX 3080 Ti 卡加在一起的原始計算能力與A100 相似,但各自的功耗是700 W 與300 W。在三年的生命週期內,以0.10 美元/千瓦時的市場價格計算,3500 千瓦時的功率差異使RTX3080 Ti 的成本增加了近2 倍(約1000 美元)。
綜上所述,我們預計絕大部分初創企業都會使用雲計算。
比較雲服務提供商
亞馬遜網絡服務(AWS)、微軟Azure 和谷歌云平台(GCP)都提供GPU 實例,但也出現了新的供應商,專門專注於人工智能工作負載。下面是我們看到的許多創始人用來選擇雲供應商的框架:
價格:下表顯示了截至2023 年4 月7 日一些主要和較小的專業雲的價格。該數據僅供參考,因為實例在網絡帶寬、數據出口成本、CPU 和網絡的額外成本、可用折扣和其他因素方面有很大的不同。
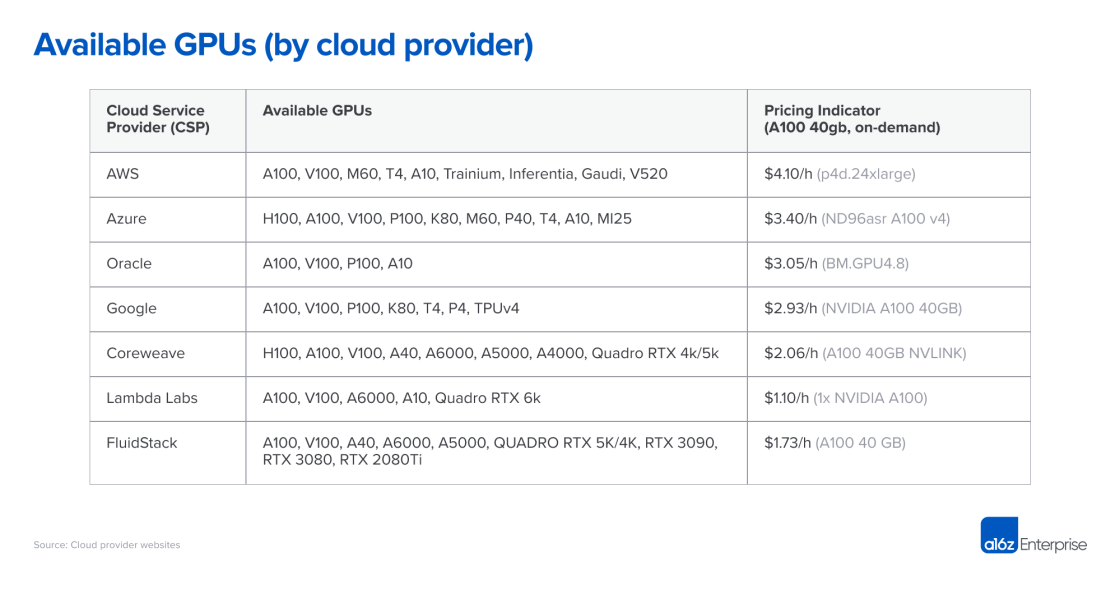
特定硬件的計算能力是一種商品。直截了當地講,我們會期望價格相當統一,但事實並非如此。雖然雲計算之間存在著實質性的功能差異,但它們不足以解釋按需NVIDIA A100 的定價在供應商之間相差近4 倍。
在價格範圍的頂端,大型公共雲根據品牌聲譽、經過驗證的可靠性以及管理各種工作負載的需要收取溢價。較小的專業AI 提供商通過運行專用數據中心(例如Coreweave)或套利其他雲(例如Lambda Labs)來提供較低的價格。
實際上,大多數大型買家直接與雲供應商談判價格,通常承諾一些最低支出要求以及最低時間承諾(我們看到的是1-3 年)。談判之後,雲計算之間的價格差異會有所縮小,但我們看到上表中的排名保持相對穩定。同樣重要的是要注意,小公司可以從專業雲中獲得積極的定價,而不需要大量的支出承諾。
可用性:最強大的GPU(如Nvidia A100 s)在過去12 個多月裡一直供不應求。
考慮到前三大雲計算供應商的巨大購買力和資源池,認它們擁有最佳可用性是合乎邏輯的。但是,有點令人驚訝的是,許多初創企業並沒有發現這是真的。大的雲服務商有大量的硬件,但也有大量的客戶需求需要滿足– 例如,Azure 是ChatGPT 的主要主機– 並且不斷增加/釋放容量以滿足需求。同時,Nvidia 已經承諾在整個行業廣泛提供硬件,包括為新的專業供應商分配。 (他們這樣做既是為了公平,也是為了減少對幾個大客戶的依賴,這些客戶也在與他們競爭)。
因此,許多初創公司在較小的雲計算供應商那裡發現了更多可用的芯片,包括尖端的Nvidia H100 s。如果你願意與較新的基礎設施公司合作,你可能會減少硬件的等待時間,並可能在這個過程中節省資金。
計算交付模式:今天的大型雲只提供帶有專用GPU 的實例,原因是GPU 虛擬化仍是一個未解決的問題。專業的人工智能雲提供其他模式,如容器或批處理作業,可以處理單個任務,而不產生實例的啟動和拆卸成本。如果你對這種模式感到滿意,它可以大大降低成本。
網絡互連:具體到培訓方面,網絡帶寬是選擇供應商的一個主要因素。訓練某些大型模型時,需要在節點之間使用專用網絡的集群,如NVLink。對於圖像生成,出口流量費用也是一個主要的成本驅動因素。
客戶支持:大型雲供應商為數以千計的產品SKU 中的大量客戶提供服務。除非你是一個大客戶,否則很難得到客戶支持的關注,或得到問題解決。另一方面,許多專門的人工智能雲,甚至為小客戶提供快速和響應的支持。這部分是因為他們的運營規模較小,但也因為他們的工作負載更加同質化,所以他們更有動力去關注人工智能的具體功能和錯誤。
比較GPU
在其他條件相同的情況下,最高端的GPU 在幾乎所有的工作負載上都會表現最好。然而,正如你在下面的表格中所看到的,最好的硬件也是相當昂貴的。為你的特定應用選擇正確類型的GPU 可以大大降低成本,並可能在可行和不可行的商業模式之間產生差異。
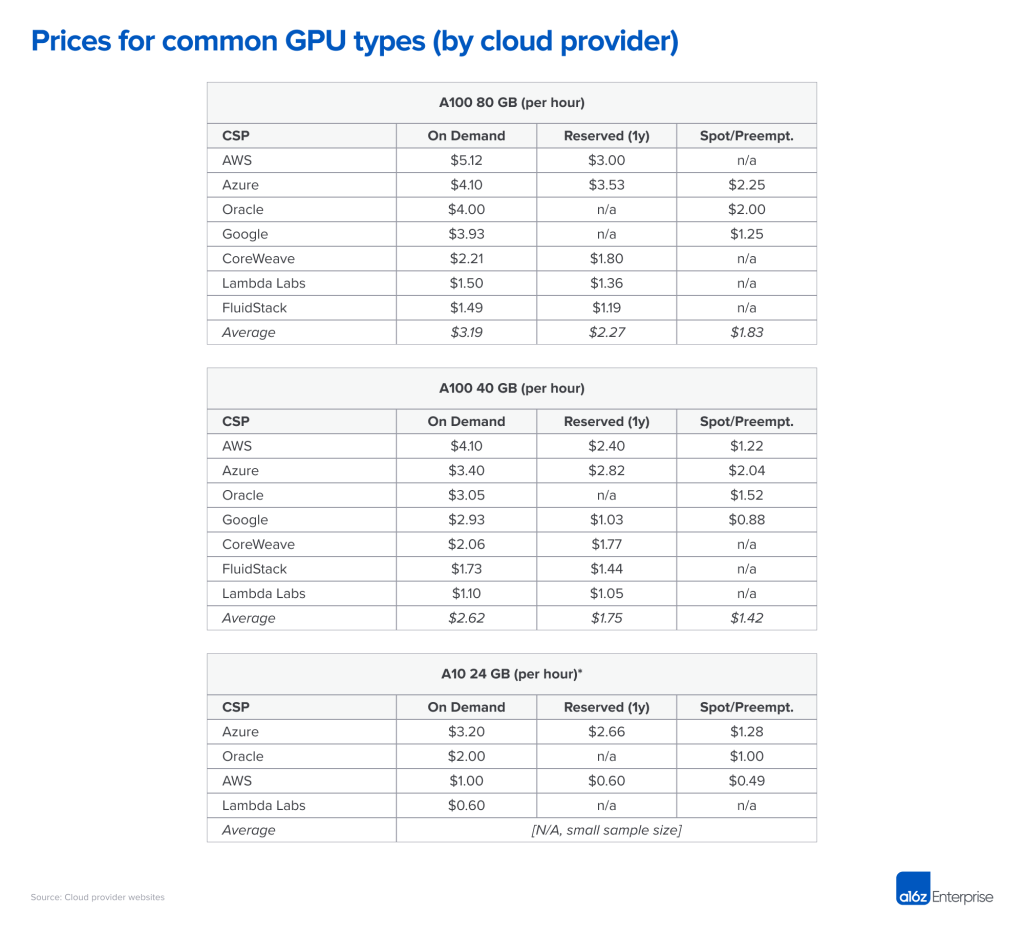
決定在列表中走多遠——即為您的應用程序確定最具成本效益的GPU 選擇——主要是一個技術決策,超出了本文的範圍。但我們將在下面分享一些我們認為最重要的選擇標準:
訓練與推理:正如我們在上面第一節中所看到的,訓練一個Transformer 模型需要我們存儲8 個字節的數據用於訓練,此外還有模型權重。這意味著一個典型的擁有12 GB 內存的高端消費級GPU 幾乎不能用來訓練一個40 億參數的模型。在實踐中,訓練大型模型是在機器集群上進行的,每台服務器最好有許多GPU,大量的VRAM,以及服務器之間的高帶寬連接(即,使用頂級數據中心GPU 建立的集群)。
具體來說,許多模型在英偉達H100 上的成本效益最高,但就目前而言,它很難找到,通常需要一年以上的長期承諾。而英偉達A100 運行著大多數模型訓練;它更容易找到,但對於大型集群,可能也需要長期承諾。
內存要求:大型LLM 的參數數量太多,無法裝入任何卡中。它們需要被分割到多個卡中,並需要一個類似於訓練的設置。換句話說,即使是LLM 推理,您也可能需要H100 或A100。但是較小的模型(例如,Stable Diffusion)需要更少的VRAM。雖然A100 仍然很受歡迎,但我們已經看到初創公司使用A10、A40、A4000、A5000 和A6000,甚至是RTX 卡。
硬件支持:雖然與我們交談過的公司中的絕大多數工作負載都在英偉達上運行,但也有一些公司開始嘗試使用其他供應商。最常見的是谷歌的TPU,而英特爾的Gaudi 2 似乎也得到了一些關注。這些供應商所面臨的挑戰是,你的模型的性能往往高度依賴於這些芯片的軟件優化的可用性。你可能必須做一個PoC,以了解性能。
延遲要求:一般來說,對延遲不太敏感的工作負載(例如,批量數據處理或不需要交互式用戶界面響應的應用程序)可以使用功率較小的GPU。這可以減少3-4 倍的計算成本(例如,比較AWS 上的A100 s 與A10 s)。另一方面,面向用戶的應用程序往往需要高端卡來提供有吸引力的實時用戶體驗。優化模型往往是必要的,以使成本達到一個可控的範圍。
峰值:生成式人工智能公司經常看到需求的急劇上升,因為這項技術是如此新穎且令人興奮。在新產品發布的基礎上,請求量在一天內增加10 倍,或每週持續增長50%,這是很正常的。在低端GPU 上處理這些峰值通常更容易,因為更多的計算節點可能會按需提供。如果這種流量來自參與度較低或留存率較低的用戶,那麼以犧牲性能為代價,以較低成本的資源為此類流量提供服務通常也是有意義的。
優化和調度模型
軟件優化可以極大地影響模型的運行時間- 10 倍的收益並不罕見。然而,你需要確定哪些方法對你的特定模型和系統最有效。
有些技術對相當廣泛的模型有效。使用較短的浮點表示(即FP16 或FP8 與原始的FP32 相比)或量化(INT8、INT4、INT2)實現的加速通常與位數的減少成線性關係。這有時需要修改模型,但現在有越來越多的技術可以實現混合或更短精度的自動工作。修剪神經網絡通過忽略低值的權重來減少權重的數量。結合高效的稀疏矩陣乘法,這可以在現代GPU 上實現大幅提速。此外,另一組優化技術解決了內存帶寬瓶頸(例如,通過流式模型權重)。
其他的優化是高度針對模型的。例如,Stable Diffusion 在推理所需的VRAM 量方面取得了重大進展。還有一類優化是針對硬件的。英偉達的TensorML 包括一些優化,但只能在英偉達的硬件上運行。最後,但同樣重要的是,人工智能任務的調度可以創造巨大的性能瓶頸或改進。將模型分配到GPU 上,以盡量減少權重的交換,如果有多個GPU 可用,則為任務挑選最佳GPU,以及通過提前批處理工作負載來盡量減少停機時間,這些都是常見的技術。
最後,模型優化仍然是一門黑魔法,我們接觸過的大多數初創公司都與第三方合作,以幫助解決其中一些軟件方面的問題。通常,這些不是傳統的MLops 供應商,而是專門針對特定生成模型(例如OctoML 或SegMind)進行優化的公司。
人工智能基礎設施成本將如何演變?
在過去的幾年裡,我們看到模型參數和GPU 計算能力都呈指數級增長。目前還不清楚這種趨勢是否會繼續。
今天,人們普遍認為,在最佳參數數量和訓練數據集的大小之間存在著一種關係(關於這一點,請參閱Deepmind 的Chinchilla的研究)。今天最好的LLM 是在Common Crawl(45 億個網頁的集合,或者說約佔現存所有網頁的10%)上訓練的。訓練語料庫還包括維基百科和一個圖書集,儘管兩者都要小得多(現存的圖書總數估計只有約1 億冊)。其他想法,如轉錄視頻或音頻內容,也被提出來,但這些都沒有接近的規模。目前還不清楚我們是否能獲得一個比已經使用的數據集大10 倍的非合成訓練數據集。
GPU 性能將繼續提高,但速度也會變慢。摩爾定律仍然完好無損,允許更多的晶體管和更多的內核,但功率和I/O 正在成為限制因素。此外,許多用於優化的低垂果實已經被摘下。
然而,這並不意味著我們預計對計算容量的需求不會增加。即使模型和訓練集的增長放緩,人工智能行業的增長和人工智能開發者數量的增加將推動對更多更快的GPU 的需求。在模型的開發階段,很大一部分GPU 容量被開發人員用於測試,而這種需求隨著人數的增加而線性增長。沒有跡象表明,我們今天的GPU 短缺將在不久的將來減輕。
這種持續的人工智能基礎設施的高成本是否會形成護城河,使新進入者無法追趕資金充足的在位者?我們還不知道這個問題的答案。今天,LLM 的訓練成本可能看起來像護城河,但Alpaca 或Stable Diffusion 等開源模型表明這些市場仍處於早期階段並且可能會迅速變化。隨著時間的推移,新興AI 軟件堆棧的成本結構(請參閱我們之前的帖子)可能開始看起來更像傳統軟件行業。
最終,這將是一件好事:歷史表明,這會帶來充滿活力的生態系統,並為創業者提供快速創新和大量機會。
感謝Moin Nadeem 和Shangda Xu 在寫作過程中的投入和指導。
展開全文打開碳鏈價值APP 查看更多精彩資訊