

撰文:Scroll
隨著Rollups 使用的增加並託管生態的應用程序,用戶的遷移成本將增加,中心化的排序器將獲得對定價的壟斷性影響力。中心化排序器的控制者有理由從用戶中直接(例如通過費用)和間接(例如通過搶跑交易、三明治攻擊等)最大程度地提取價值(MEV)。 — Espresso
正如Espresso 團隊所提到的,中心化Rollups 最終將面臨壟斷定價和MEV 的問題。此外,中心化Rollups 本質上會破壞可組合性,導致割裂的Rollups。
然而,目前幾乎所有的Rollups 都仍然是中心化的,因為建立一個去中心化、無需許可且可擴展的Rollup 是極具挑戰性的。另一個原因是,先推出中心化的Rollups 可以幫助孵化生態系統並搶占市場份額。
而當我們討論去中心化的Rollups 時,特別是zkRollups 時,有兩個層面的去中心化。第一個是證明者的去中心化,第二個是排序器的去中心化。實現完全的去中心化,還需要解決排序器和證明者之間的協調問題。
在模塊化趨勢下,去中心化Rollup 目前主要有三類參與者。第一類旨在實現完全去中心化的Rollups,並提出了完整的解決方案。第二類是旨在解決證明者網絡的協議。最後有多種解決方案正在實現排序器的去中心化。
Rollups 去中心化
在zkRollups 中,Polygon 和Starknet 已經提出了解決方案來實現他們Rollups 的去中心化。
Polygon

在引入POE(Proof of Efficiency)之前,Polygon zkEVM 採用了POD(Proof of Donation),使得排序器可以競標創建下一個交易批次的機會。但是,這會帶來一個問題,即單個惡意方可以通過出價最高來控制整個網絡。
採用POE 後,排序器和證明者將在自身硬件條件下,最高效地參與到無需許可的網絡中。任何人都可以加入Polygon zkEVM,只要這是有經濟效益的。
在Polygon zkEVM 中,排序器需要16GB 的RAM 和4 個核心的CPU,而證明者需要1TB 的RAM 和128 個核心的CPU。此外,還有一個稱為聚合器的角色,負責收集L1 數據,將其發送到證明者,接收證明並將其提交到L1。我們可以將聚合器和證明者視為同一個主體,因為聚合器和證明者之間的關係是非常簡單的,聚合器支付證明者生產證明的成本。
這種架構非常簡單:任何排序器都可以無需許可地在L1 上基於前一個狀態打包交易,並更新相應地狀態。同時,任何聚合器都可以提交證明以驗證更新後的狀態。
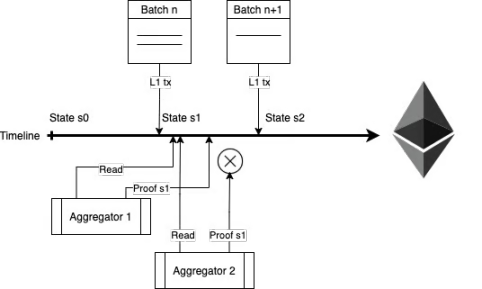
在POE 中,效率不僅指參與者在相互競爭時的網絡效率,也指排序器和證明者自身的經濟效率。在L2 中,排序器和證明者分享交易費用,排序器支付batchFee 給聚合器來生成證明。這確保了參與者在經濟上有動力為網絡效率做出貢獻,從而帶來更加健壯和可持續的生態系統。
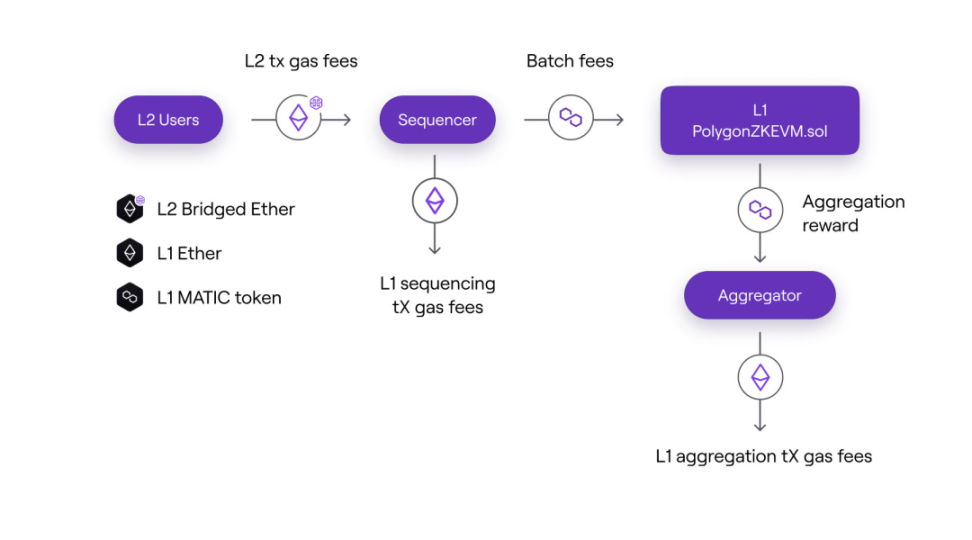
排序器
- 收入:L2 交易費用
- 成本:batchFee (以$MATIC 計算)+ L1 交易費用(調用sequenceBatches 方法)
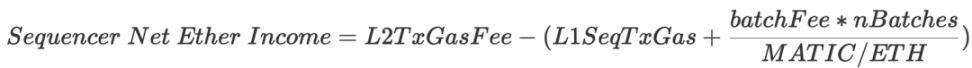
聚合器(證明者)
- 收入:batchFee (以$MATIC 計算)
- 成本:證明成本+ L1 交易費用(調用verifyBatchesTrustedAggregator 方法)
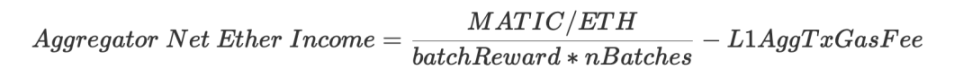
協調器: batchFee
- 初始參數
- batchFee= 1 $MATIC
- veryBatchTimeTarget = 30 分鐘。這是驗證批次的目標時間。協議將更新`batchFee`變量來達到該目標時間。
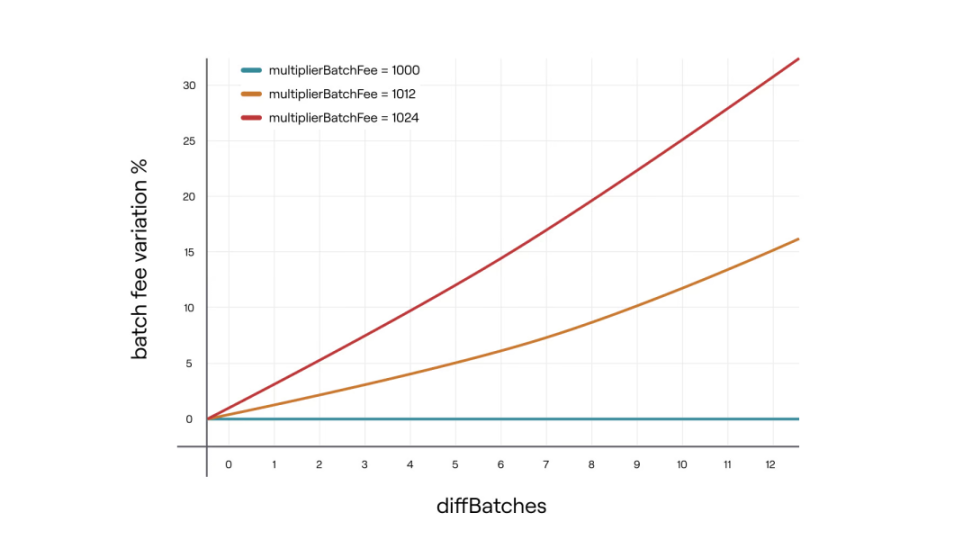
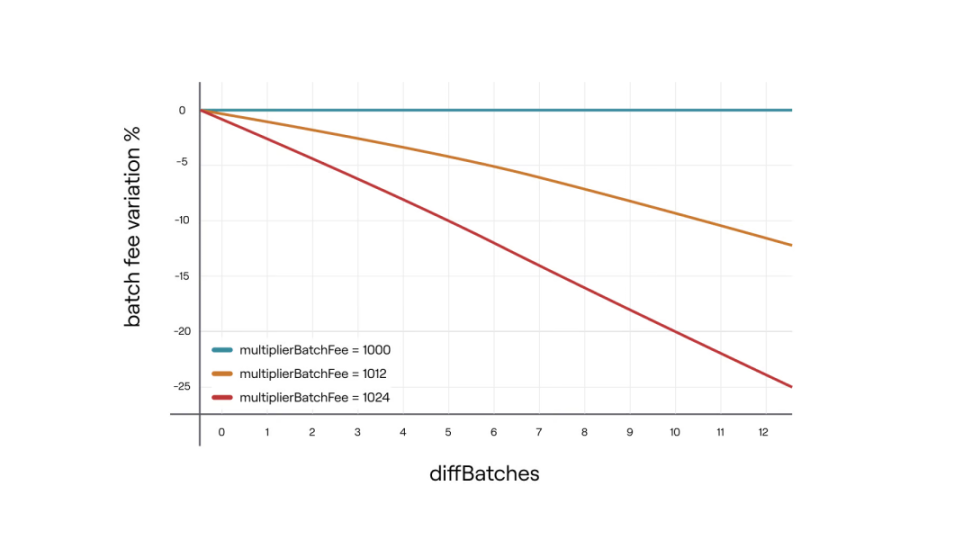
- multiplierBatchFee = 1002。這是批次費用乘數,範圍從1000 到1024,保留3 位小數。
- 調節器
- diffBatches : 被聚合的批次中> 30 分鐘的數量減去<=30 分鐘的批次數量。最大值為12。
- 協調過程
- 當diffBatches> 0 時,增加聚合獎勵以激勵聚合器。
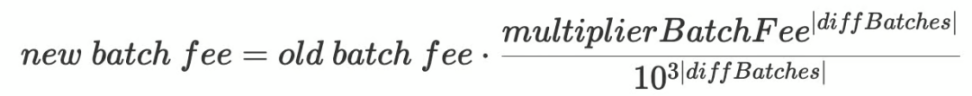
- 當diffBatches < 0 時,減少聚合獎勵來抑制聚合器,減緩聚合進程。
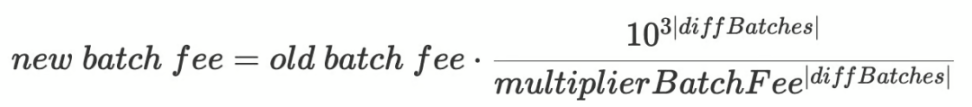
Starknet

Starknet 也旨在構建一個快速確認的無許可且可擴展的Rollup。雖然尚未達成去中心化解決方案的最終規範,但他們幾個月前在論壇上發布了一些草案。
與Polygon zkEVM 的簡單機制相比,Starknet 的方案更為複雜,因為它包括L2 共識和證明網絡中的鍊式協議證明(chained proof-of-a-protocol)。
排序器
Starknet 提出了一個雙賬本共識協議,而不是簡單地在排序器層中添加一個共識層。在該協議中,L2 作為live protocol 提供快速響應,而L1 checkpoints 則作為safe protocol 提供最終確認性。
對於L2 的live protocol,可以採用各種共識機制,例如抗女巫的PoS 系統,如Tendermint 或DAGs。另一方面,L1 的safe protocol 涉及多個合約,分別處理Stake 管理、證明驗證和狀態更新。
該雙賬本共識協議的典型工作流程如下:
1. 首先,將L2 live ledger 的輸出作為L1 safe ledger 的輸入,生成一個檢查後的live ledger。
2. 然後,將檢查後的live ledger 作為輸入,再次輸入到L2 的純共識協議中,確保檢查後的live ledger 始終是liveledger 的前綴。
3. 重複上述過程。
在構建雙賬本共識協議時,存在成本和延遲之間的權衡。理想的解決方案旨在同時實現低成本和快速的最終確認。
為了在L2 上降低gas 成本,Starknet 將checkpoints 分為「分鐘級」和「小時級」。對於「分鐘級」 checkpoints,只有狀態本身被提交到鏈上,而其餘數據(有效性證明、數據可用性等)則通過StarkNet L2 網絡發送。這些數據由StarkNet 全節點存儲和驗證。另一方面,「小時級」 checkpoints 在L1 上進行公開驗證。兩種類型的檢查點提供相同的最終確認。對於「分鐘級」 checkpoints,有效性證明由StarkNet 全節點驗證,並可以由任何一個節點在L1 上發布,以向「分鐘級」 checkpoints 賦予L1 的最終確認性。因此,證明者需要生成小證明,以便在L2 網絡中廣泛傳播。
為了進一步降低延遲,Starknet 提出了一種領導者選舉協議,以提前確定領導者。其基本邏輯如下:當前時期i 的領導者是基於L1 質押數量和一些隨機性預先確定的。具體來說,在時期i-2 中,leader_election 方法根據時期i-3 中的質押數量將排序器按詞典順序平鋪展開。然後,發送一筆交易來更新隨機數並隨機選擇一個點。該點落在位置所對應的排序器將成為時期i 的領導者。
證明者
在POE 模塊下,參與者之間進行公開競爭,這可能導致贏家通吃的情況。 Starknet 試圖實現一種無中心化風險的競爭機制。以下是幾種可選方案:
- 輪流制:這可以部分解決中心化問題,但可能無法通過激勵機制找到證明工作的最佳人選。
- 基於質押:排序器根據其所質押的數量決定了當選證明者的概率。
- Commit-Reveal 方案:首個提交者需要抵押代幣來獲得短暫的壟斷機會,然後在該時間窗口內生成證明。為了避免DDoS 攻擊,如果前者無法及時生成證明,後者所需的抵押代幣將呈指數級增長。雖然在該機制下,網絡可能會失去最佳性能的機器,但可以培養更多的證明者。
除了證明者之間的競爭,還應該降低進入門檻,以便更多的證明者可以參與到網絡中來。 Starknet 提出了一種利用遞歸證明的複雜協議,稱為鍊式協議證明。
在鍊式協議證明中,區塊鏈本身被劃分為幾個不同的分支。這樣證明不僅可以是遞歸的,而且證明生成也可以是並發的。例如,在3 個分支的設定中,12 個黑色的區塊被分為3 行,每行代表一個分支。我們可以把每個分支看作一個子鏈,子鏈中的每個塊都應證明前一個塊。從整條鏈的角度看,插槽n 需要證明插槽n-3 。 3 個區塊的間隔為排序器預留了足夠的時間來提前計算和購買證明。這有點類似於分片技術,其中攻擊者只需要控制一個分支就能控制整個證明者網絡。
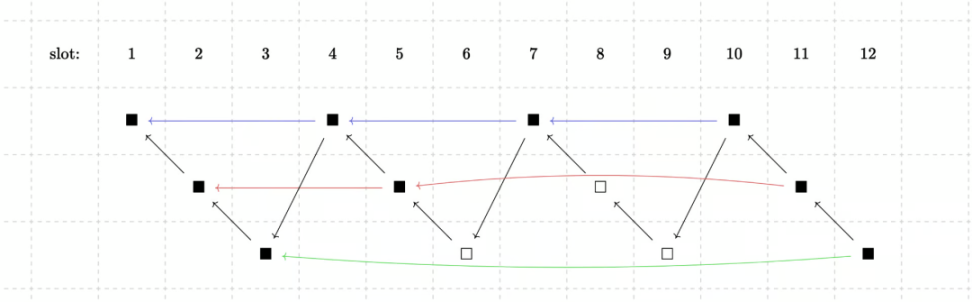
為了將這些分支編織在一起,Starknet 提出了一種編織技術,可以將多個節點合併在一起,共同驗證交易的合法性,確保交易記錄的一致性和可靠性。
其中一種方案是要求每個插槽需要同時與幾個分支進行合併。另一種方案是將每個分支交替嘗試和其餘分支合併,從而減少證明工作量。當然這也是一個開放性問題,可能未來有更好的解決方案。
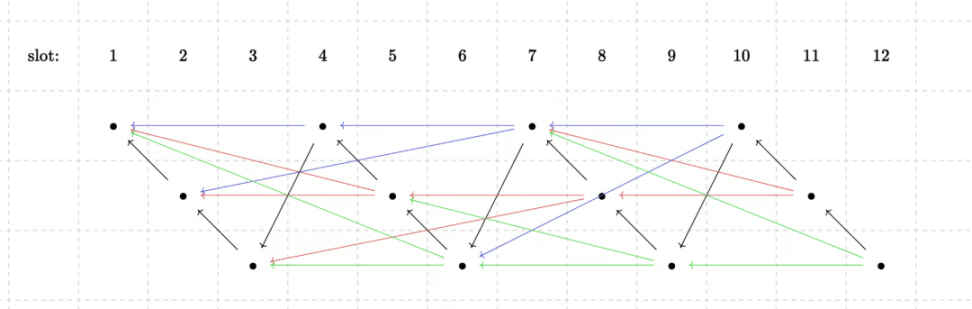
協調
為了積極確保證明者能夠有足夠的盈利空間,Starknet 提出了參考EIP1559 方案的做法:將基礎費用設定為證明者資源價格的下限,積極地進行價格發現,並且排序器可以使用小費來激勵證明者。這樣,證明者將始終得到超額支付,只有極端情況才會影響證明過程。否則,如果證明者獲得的報酬接近市場價格,那麼輕微的波動就可能引發證明者停擺。
證明者去中心化

從Rollups 的角度來說,證明者比排序器去中心化更容易實現。而且,當前證明者是性能瓶頸,需要跟上排序器批處理的速度。在排序器去中心化尚未解決時,去中心化的證明者也可以為中心化的排序器提供服務。
事實上,不僅是Rollups,zkBridge 和zkOracle 也需要一個證明者網絡。他們都需要一個強大的分佈式證明者網絡。
從長遠來看,能夠容納不同計算能力的證明者網絡更具可持續性,否則性能最好的機器將壟斷市場。
證明市場
有些協議不是協調排序器和證明者之間的關係,而是直接將協調抽象成了證明市場。在該市場中,證明是商品,證明者是證明的生產者,而協議則是證明的消費者。在「看不見的手」的作用下,市場均衡是最高效的。
Mina

Mina 已經建立了一個名為Snarketplace 的證明市場,在其中交易Snark 證明。這裡的最小單位是單個交易的Snark 證明。 Mina 採用了一種名為Scan State 的狀態樹的遞歸證明。
Scan State 是一個二叉樹的森林,其中每個交易是一個節點。在樹的頂部生成一個單個證明,可以證明樹中的所有交易。證明者有兩個任務:首先是生成證明,第二是合併證明。
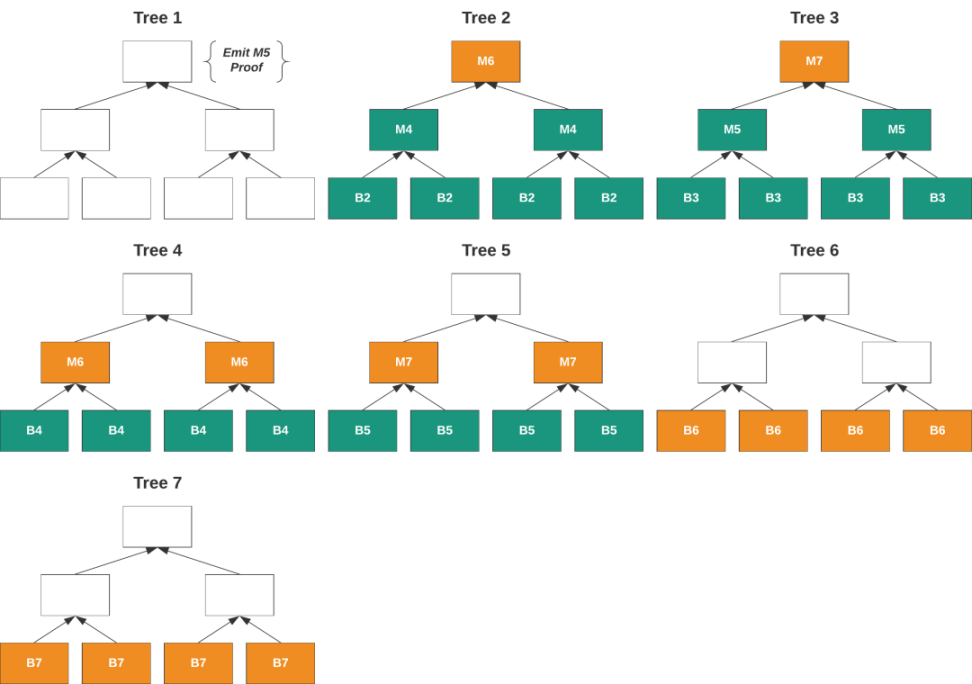
在證明者完成工作並提交出價後,Mina 協議的區塊生產者將選擇最低價格的出價者。這也是均衡價格,因為出價者會提交高於證明成本的出價,而區塊生產者將不會購買不划算的證明。
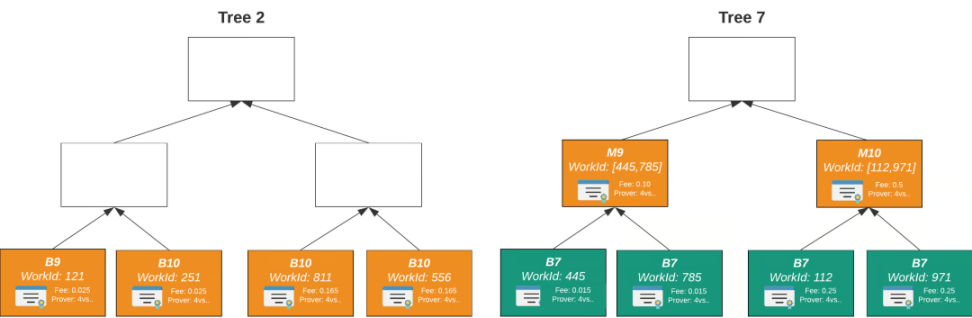
=Nil; Foundation

Mina 的證明市場是專為自己的協議設計的,而=nil; Foundation 則提出了一個通用的證明市場,以服務整個市場。
該市場的服務由三個組成部分構成:`DROP DATABASE、zkLLVM 和Proof Market。
- DROP DATABASE:是一個數據庫管理系統協議,可以看作是一個DA 層。
- Proof Market:是一個在DROP DATABASE 上運行的應用程序,類似於一些人所說的zk 證明的「去中心化交易所」。
- zkLLVM:是一個編譯器,將高級編程語言轉換為可證明計算協議的輸入。
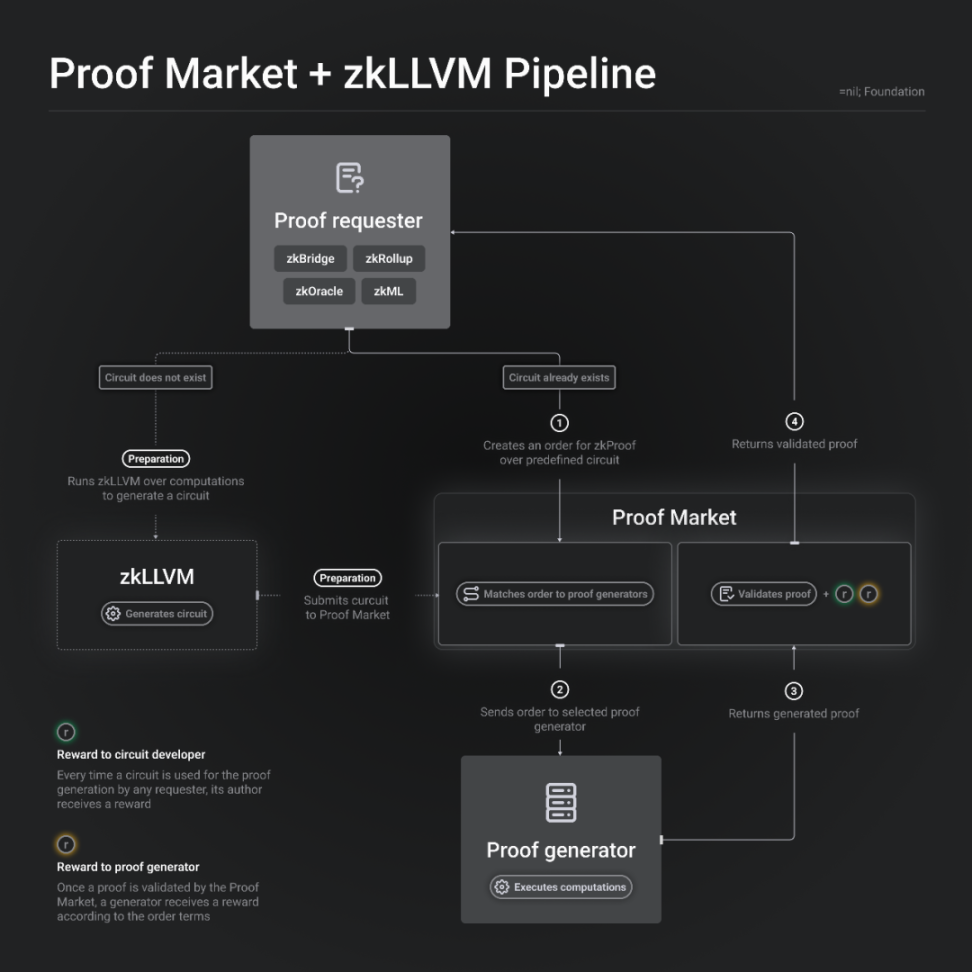
每個證明由其不同的輸入和電路組成,因此每個證明都是唯一的。電路定義了證明的類型,類似於金融術語中定義「交易對」的方式。此外,不同的證明系統引入了更多的電路。
工作流程如下:證明的需求方可以用高級編程語言編寫代碼,然後通過工具鏈將其餵給=nil; zkLLVM,生成一個單獨的電路,它將成為市場中的一個獨特的交易對。
對於證明需求方,他們可以在成本和時間之間做取捨。證明者也將考量自己的計算能力和收入。因此在市場上,將會有不同的計算能力,高算力將更快地生成證明,但成本更高,而低算力生成證明更慢,但更便宜。
兩步提交

最近,Opside 提出了一種兩步提交方案來去中心化證明者網絡。該方案將證明提交分成兩個階段,來避免最快的證明者總是勝出的情況。
- 步驟1:提交第T 個區塊的零知識證明的哈希
- 從第T+11 個區塊開始,不再允許新的證明者提交哈希。
- 步驟2:提交零知識證明
- 在第T+11 個區塊之後,任何證明者都可以提交零知識證明。如果至少有一個零知識證明通過驗證,它將用於驗證所有提交的哈希,經過驗證的證明者將根據抵押金額的比例獲得相應的PoW 獎勵。
- 如果在第T+20 個區塊之前沒有零知識證明通過驗證,則所有提交哈希的證明者都會受到懲罰。然後重新開放排序器,可以提交新的哈希,回到步驟1。
這種方法可以包容不同的算力。然而,所需的抵押仍然引入了一定程度的中心化。
排序器去中心化

排序器的去中心化比驗證者更為複雜。這是因為排序器具有打包排列交易的權力,諸如MEV 和收入分配等問題都需要考量。
考慮到以太坊將對活性的優先級高於響應性,L2 解決方案應該通過優先考慮響應性而不是活性來與這樣的取捨互補。但是,與中心化排序器相比,去中心化排序器在響應性方面本身就有所犧牲。因此,需要實現各種優化來解決這個困境。
目前,有三種不同的去中心化排序器方案。第一種方案是通過優化共識機制實現。第二種方案涉及共享排序器網絡。第三種方案基於L1 的驗證者。
共識

共識協議主要負責對交易進行排序和確保其可用性,而不是執行交易。但是,正如前面提到的直接添加另一個共識層,並不是一個簡單的解決方案。
為了提高響應性,一種常見的方法是依靠較小的驗證器集合。例如,Algorand 和Polkadot 使用隨機抽樣的較小委員會來批量處理交易。所有節點使用隨機信標和可驗證隨機函數(VRF),在給定時期內被包含在委員會中的概率與其質押數量成比例。
為了減少網絡流量,可以使用更小的數據可用性(DA)委員會。或者採用VID(Verifiable Information Dispersal)。 VID 將數據的糾刪碼分發給參與共識的所有節點,使得任何持有足夠高質押比例的節點子集都可以協作恢復數據。這種方法的取捨在於減少廣播複雜性,但增加了數據恢復的複雜性。
Arbitrum 則選擇了有聲譽的實體組成驗證者集,如ConsenSys、Ethereum Foundation、L2BEAT、Mycelium、Offchain Labs、P2P、Quicknode、IFF 的分佈式賬本研究中心(DLRC)和Unit 410 加入排序器委員會。這種方法的取捨在於通過提高去中心化的質量來彌補數量上的不足。

共享排序器網絡

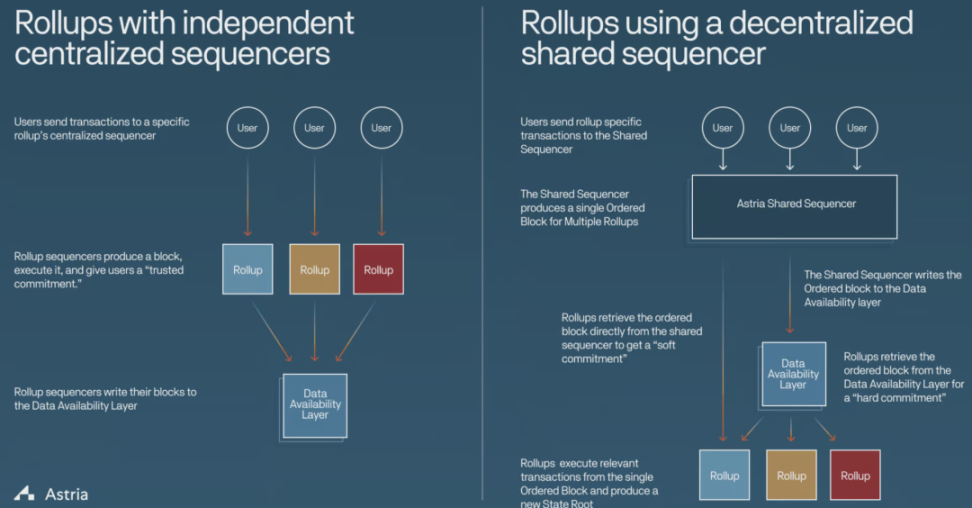
排序器在模塊化區塊鏈中(特別是在Rollup 中)發揮著至關重要的作用。每個Rollup 通常都會構建自己的排序器網絡。然而,這種方法不僅造成了冗餘問題,而且還阻礙了可組合性。為解決這個問題,一些協議提出了構建一個共享的Rollup 排序器網絡。這種方法降低了實現原子性、可組合性和互操作性的複雜度,這些特性在開放無需許可的區塊鏈中,是用戶和開發者迫切需要的。此外,它還不再需要單獨的排序器網絡的輕客戶端。
Astria

Astria 正在為Celestia 的Rollup 生態系統開發一種中間件區塊鏈,其中包括自己的分佈式排序器集合。這個排序器集負責接受來自多個Rollup 的交易並將其寫入基礎層,而不執行它們。
Astria 的作用主要聚焦於交易排序,與基礎層和Rollup 獨立運作。交易數據存儲在基礎層上(例如Celestia),而Rollup 全節點維護狀態並執行操作。這確保了Astria 與Rollup 解耦。
對於最終確認性,Astria 提供兩個級別的Commitment:
- Soft commitment:使得Rollup 能夠為其最終用戶提供快速的區塊確認。
- Firm commitment:速度與基礎層相同,確保更高的安全性和最終確認性。
Espresso

Espresso 在零知識技術領域做出了重大貢獻。他們最新在開發一種去中心化排序器的綜合解決方案,可應用於Optimistic Rollups 和zkRollups。
去中心化排序器網絡由以下組成:
- HotShot 共識:優先考慮高吞吐量和快速最終確認性,而不是動態可用性。
- Espresso DA:結合基於委員會的DA 解決方案和VID,其中高帶寬節點將數據提供給所有其他節點。每個單獨區塊的可用性也由小型隨機選舉的委員會支持。 VID 提供可靠但較慢的備份,只要所有節點的足夠高比例的質押權重沒有受到威脅,就可以保證可用性。
- Rollup REST API:以太坊兼容JSON-RPC。
- 排序器合約:驗證HotShot 共識(即作為輕客戶端)並記錄checkpoints(即對交易進行密碼學承諾),管理HotShot 的質押表。
- P2P 網絡:Gossip 協議。
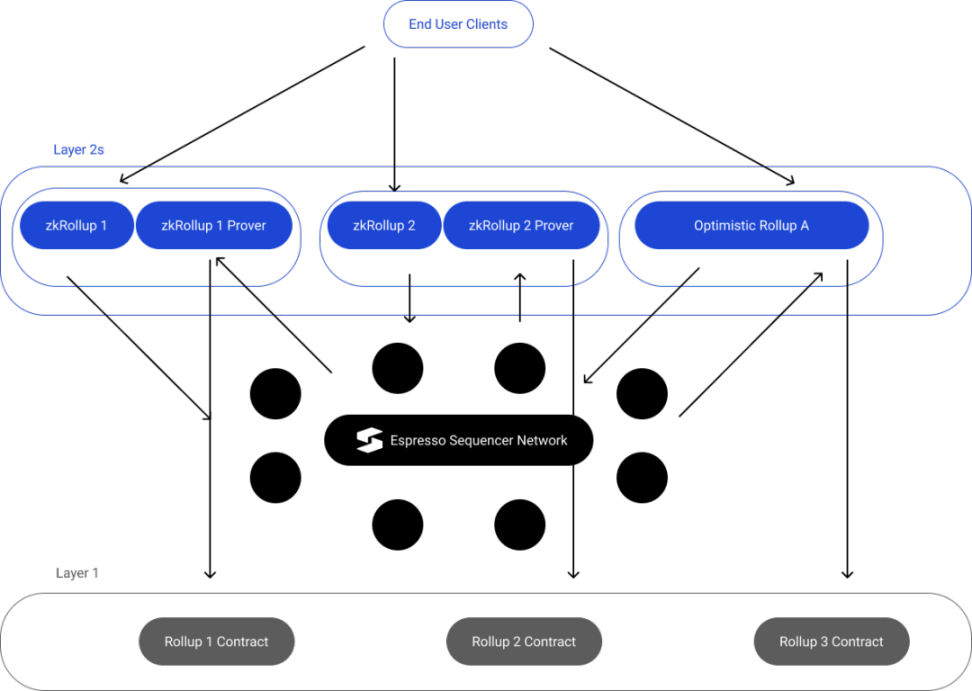
與Astria 相比,Espresso 提供DA。因此,工作流程將略有不同,如下所述:
1. 用戶創建並提交交易到Rollup。
2. 交易通過排序器網絡傳播並保留在內存池中。
3. 通過HotShot 質押機制指定領導者,提出區塊,並將其傳播回Rollup 的執行者和證明者。
4. 領導者將交易發送到數據可用性委員會,並收到DA 證書作為反饋。
5. 領導者還向Layer 1 排序器合約發送對區塊的承諾,以及合約用於驗證區塊的證書。
Espresso 引入了用於證明的Gossip 協議,提供更靈活的用戶體驗。它提供三種交易最終確認性的選項:
- 快速:用戶可以信任已執行交易並生成證明的Rollup 服務器,或者他們可以利用HotShot 的低延遲執行交易。
- 適度:用戶可以稍等一段時間以生成證明,然後檢查該證明。
- 慢速:用戶可以等待L1 驗證狀態更新來獲取更新後的狀態,無需任何信任假設或計算。
除了上述優化之外,Espresso 還計劃使整個以太坊驗證者集本身參與運行Espresso 排序器協議。使用相同的驗證者集合將提供類似的安全性,並且與L1 驗證者分享價值將更加安全。此外,Espresso 還可以利用EigenLayer 提供的ETH 再質押解決方案。
Radius

Radius 正在構建一個基於零知識證明的無信任共享排序層,專注於解決L2 中的MEV 問題,因為L2 的收入主要來自區塊空間。所需要考慮的權衡是MEV 和L2 收入之間的平衡。 Radius 的目標是消除對用戶有害的MEV,並提出了一個兩層服務。
頂層針對常規用戶交易,並通過使用時間鎖謎題提供密碼學保護,以防止有害的MEV。具體而言,它採用了實用可驗證延遲加密(PVDE)技術,該技術將在5 秒內為基於RSA 的時間鎖謎題生成零知識證明。該方法提供了一種實用的解決方案,以保護用戶免受有害的MEV。簡而言之,在排序器確定交易順序之後,才可以知曉交易內容。
底層是為區塊構建者設計的,並允許他們參與產生收入的活動,同時減輕MEV 的負面影響。
Based Rollups

Based Rollup 是最近由Justin Drake 提出的一個概念,其中L1 區塊提議者與L1 的搜索者和構建者合作,在無需許可的情況下將rollup 區塊包含在下一個L1 區塊中。它可以被視為L1 上的共享排序器網絡。 Based Rollup 的優缺點很明顯。
從積極的一面來看,Based Rollup 利用了L1 所提供的活性和去中心化性,並且它的實現簡單且高效。 Based Rollup 也與L1 保持經濟上的一致性。然而,這並不意味著Based Rollup 損害了其主權。雖然將MEV 交給了L1,Based Rollup 仍然可以擁有治理代幣並收取基礎費用。根據假設,Based Rollup 可以利用這些優勢,實現主導地位,並最終最大化收益。
結論

觀察所提出的這些方案,可以看出Rollup 的去中心化仍有很長的路要走。其中一些提案仍處於草案階段,需要進一步討論,而其他一些則僅完成了初步規格說明。所有這些方案都需要實現並接受嚴格的測試。
雖然有些Rollup 可能沒有明確提出相應的去中心化解決方案,但它們通常包括應急逃離機制來解決由於中心化排序器引起的單點故障。例如,zkSync 提供了`FullExit`方法,允許用戶直接從L1 提取其資金。在系統進入exodus mode ,無法處理新區塊時,用戶可以啟動提款操作。
為了實現抗審查,這些Rollup 通常還允許用戶直接在L1 上提交交易。例如,zkSync 採用優先級隊列來處理在L1 上發送的這類交易。類似地,Polygon zkEVM 在L1 合約中包含了一個force batch 方法。當一周內未發生聚合時,用戶可以在L1 上調用此方法,並提供交易的字節數組和bathFee 給證明者。
可以肯定的是,在可預見的未來,Rollup 的去中心化將會是一個組合型的解決方案,可能包括上述這些重要的方案或者其他一些創新性的變體。
參考資料
https://wiki.polygon.technology/docs/zkEVM/
https://ethresear.ch/t/proof-of-efficiency-a-new-consensus-mechanism-for-zk-rollups/11988/12
https://community.starknet.io/t/starknet-decentralization-kicking-off-the-discussion/711
https://docs.minaprotocol.com/node-operators/scan-state
https://blog.nil.foundation/2023/04/26/proof-market-and-zkllvm-pipeline.html
https://ethresear.ch/t/zkps-two-step-submission-algorithm-an-implementation-of-decentralized-provers/15504
https://ethresear.ch/t/shared-sequencer-for-mev-protection-and-profitable-marketplace/15313
https://hackmd.io/@EspressoSystems/EspressoSequencer
https://hackmd.io/@EspressoSystems/SharedSequencing
https://ethresear.ch/t/based-rollups-superpowers-from-l1-sequencing/15016
https://research.arbitrum.io/t/challenging-periods-reimagined-the-key-role-of-sequencer-decentralization/9189