

ETHShanghai 2023 峰會中,Axiom 創始人Yi Sun 介紹了以太坊的ZK 協處理器Axiom 以及其在數據訪問和計算能力方面的重要性。 Axiom 通過Reflection 操作概念實現了數據訪問和計算的擴展,通過驗證哈希鍊和維護緩存來實現查詢的有效性。 Axiom 的應用前景包括高成本應用、更大數據訪問、基於歷史數據管理協議的應用等。通過Axiom,智能合約可以獲得更廣闊的數據和計算能力,進一步推動以太坊應用的發展。
以下正文為Yi Sun 演講內容的中文編譯版本,鏈接為現場視頻:https://www.youtube.com/watch?v=qxSQNbf_SXs
首先,我們來了解實際訪問以太坊信息的用戶旅程。當我們第一次使用以太坊時,實際接收有關鏈上發生的情況的信息的方式是通過對存檔註釋的JSON-RPC 調用。 JSON-RPC API 的目的是實際向用戶展示有關鏈上歷史的信息。本質上,我們看到的有關區塊鏈的所有信息都是從這些API 調用中提取出來的,並以一種條目的形式呈現在網站上供用戶讀取。
現在,隨著用戶與區塊鏈交互變得更加熟練,我們開始要求對鏈的視圖越來越複雜。因此,針對不同的用戶權衡,正在開發不同類型的存檔節點。於是就有了Geth、Erigon、Nethermind,現在又增加了Reth。我們可根據自身需求選擇最適合自己的存檔節點。
如果用戶對單獨的JSON-RPC API 不滿意,可以選擇一個索引器來應用後處理,同時跟踪交易。對於不同的應用程序,用戶可能對從The Graph 或Covalent 返回的數據感興趣。
最近,還出現了一些錢包和其他產品,提供在存檔節點之上進行交易模擬的功能。這意味著我們可以在提交交易之前看到虛擬交易的實際結果。總的來說,作為最終用戶,我們與以太坊的交互方式越來越複雜,它在我們讀取的數據之上使用了更多的計算。
現在,如果我們不是從用戶的角度,而是從以太坊上的智能合約的角度來考慮問題。當然,合約也希望能夠訪問數據並對數據進行計算,但這更具挑戰性。事實上,如果我們去OpenSea 看看CryptoPunk 的列表,會發現在頁面上的所有信息中,只有很小一部分是在鏈上的智能合約中可以訪問的。
事實上,對於CryptoPunk 的列表,這些信息只是當前的持有者。當然,頁面上還有很多其他信息,但與歷史轉賬信息、歷史價格和歷史持有者相關的所有信息實際上對智能合約是不可訪問的,因為它屬於過去的歷史。這些歷史構成了鏈上信息,但對於智能合約來說,它們不可用,因為我們需要避免強制要求每個完整的以太坊節點在其隨機訪問中維護此信息以驗證交易。
此外,任何區塊鏈開發人員都可以告訴你,在鏈上運行計算是非常昂貴的,儘管以太坊具有相對高效的虛擬機(VM)操作,並且通過預編譯使某些類型的操作更便宜。例如,在BN254 曲線上的橢圓曲線運算,以太坊提供了價格較為低廉的支持。然而,對於一些特定的應用程序,以太坊虛擬機仍然是一個非常昂貴的運行環境。當設計一個區塊鏈虛擬機時,必須選擇一組固有的操作,這些操作需要仔細計量,以確保每個節點都能以一致的時間驗證交易。此外,還必須考慮最壞情況下的安全性和共識穩定性。因此,這裡的挑戰在於如何實現針對鏈上應用程序的應用特定擴展。 Axiom 旨在為智能合約擴展數據訪問和計算能力,滿足不同應用的拓展需求。
Axiom 正在構建的是稱之為以太坊協處理器(ZK Coprocessor),通過以上操作允許某些智能合約無需信任地委託給我們的離線系統,以便它們可以將數據讀取和可驗證計算委託給Axiom。要向Axiom 發出查詢,智能合約可以向我們的鏈上系統發送一筆交易。我們的離線節點將接收該交易,並根據以太坊的歷史查詢生成結果,並附上一個零知識證明,以證明結果的正確性。最後,我們再鏈上驗證結果,並可信地將結果交付給下游的智能合約。
這種方式類似於計算機中的CPU 將計算任務委託給GPU,並在結果可知後將其取回。這個概念在早期被稱為協處理器(Coprocesso)。在幻燈片上,我展示了上世紀90 年代初的一個高級數學Coprocesso 的圖像與Axiom 所做的類比。
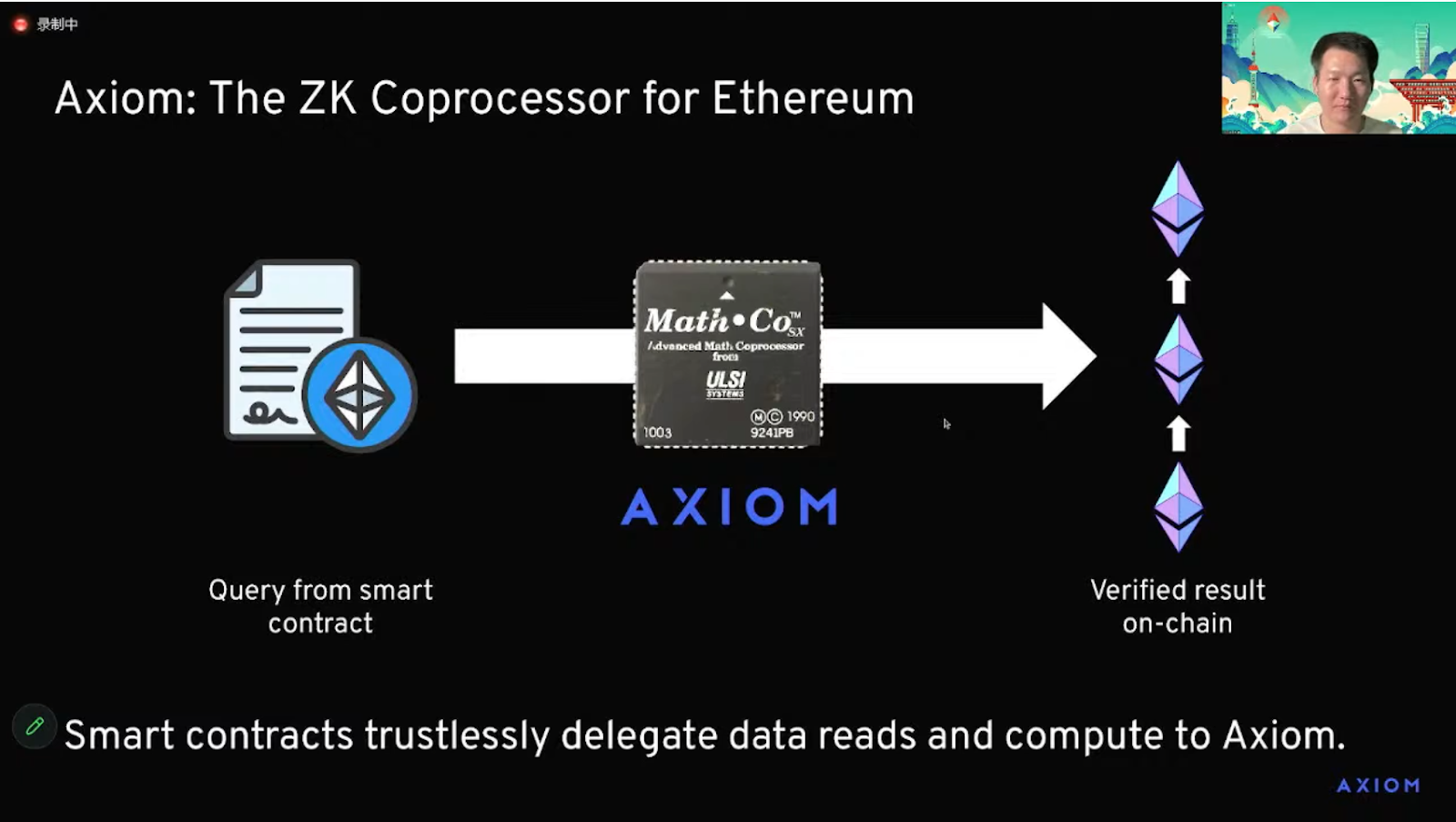
我們可以深入地了解Axiom 可以進行哪些類型的操作每個對Axiom 的查詢可以分為三個部分。
首先是讀取部分,也是Axiom 查詢的輸入方式——我們可以可信地讀取歷史上鍊的數據。
第二部分是我們可以在這些數據上運行驗證計算。這可能從基本的分析開始,比如對一些數字求和、求最大值或最小值,到更複雜的計算。比如來自密碼學的一些簽名聚合或驗證,甚至可以進行基於零知識的機器學習,比如在鏈上社交數據上驗證某些聲譽算法的運行或在金融應用中使用某些機器學習算法。最終,我們將通過虛擬機提供可編程的計算複合功能。
最後一個部分,在讀取和計算步驟完成後,我們得到一個結果,並且始終將該結果與零知識證明配對,以證明結果的計算是有效的。因此,我們在以太坊智能合約中驗證該證明,然後將結果存儲供合約使用。
由於Axiom 返回的所有結果實際上都經過零知識證明驗證,這意味著Axiom 返回的所有內容的安全性與以太坊本身的安全性在密碼學上是等效的。 Axiom 的理念是,我們不希望對用戶施加任何超出其使用以太坊所已有的密碼學假設的額外假設。
接下來我將詳細介紹它的實現原理,這涉及到在演講標題中提到的Reflection 操作概念。實現這一切的核心原則是,每個區塊鏈上的區塊都包含了完整的歷史記錄。我們可以從當前的以太坊區塊開始,向前回溯到我們感興趣的早期區塊。通過獲取過去區塊和當前區塊之間的所有區塊頭,並通過驗證這些區塊頭的哈希鏈,我們實際上可以將過去區塊的承諾逆向追溯到當前區塊。
那Reflection 有什麼好處呢?
我們可以取當前以太坊的一個塊,並回溯到我們感興趣的以前的一個塊。如果我們取得過去塊和當前塊之間的塊頭,我們可以通過驗證這些塊頭之間的哈希路徑,將過去塊的承諾反向到當前塊中。然後,如果我們對過去塊中的某些信息感興趣,我們可以在該塊的承諾中給出一個包含證明。具體來說,這可以是一個Merkle Patricia Trie 證明,證明該信息存在於該塊的狀態trie、交易trie 或收據trie 中。至少原則上,在EVM 中,僅通過對最近塊哈希的了解,就可以訪問鏈上的任何過去信息。
遺憾的是,在EVM 中進行這樣操作的代價是昂貴的。正如剛剛提到的,你必須驗證所有塊頭的哈希鍊和Merkle 證明,這涉及對大量數據進行許多Keccak 哈希計算。所以一旦你回溯到過去,就會變得非常困難。因此,我們通過在EVM 中使用ZK 封裝這個證明來應用Reflection 操作。因此,我們不需要將所有過去的塊頭和所有這些Merkle 證明放在鏈上,然後進行驗證,而是在零知識中檢查是否存在一系列過去的塊頭和一些驗證的證明。
這有兩個優點。首先,它使我們不必將證明數據放入調用數據中。其次,它讓我們能夠將證明聚合,而如果沒有使用ZK 的話,這是不可想像的。這裡的想法是,在以太坊上驗證任意數量的計算時,Gas 成本是固定的,因此我們可以使用單個ZK 證明來驗證大量的歷史數據訪問。
讓我簡單談談基於ZK 的Reflection 操作概念的權衡。
訪問數據有兩種方式。第一種是你之前所了解的方式——你可以直接從智能合約中訪問以太坊上的數據。這有一個非常大的優點,即訪問是同步的。因此,你可以直接調用智能合約中的讀取函數,獲取當前值。例如,當你在Uniswap 上進行交易時,你就需要這種同步性。然而,它也有很多限制。你的計算能力受到燃料成本的限制,而且無法訪問任何歷史數據。
第二種,如果你想利用ZK 的能力來反映到以太坊中,因為你必須生成證明,證明你的訪問是正確的,那麼就無法以同步方式做到這一點。因此,實際上無法直接訪問當前的鏈上狀態,因為你必須針對一個狀態進行證明。
另一方面,如果你允許自己以異步方式訪問歷史數據,那麼你可以對其應用幾乎無限的計算,並且可以訪問大量數據。因此,通過放寬同步的概念,基於ZK 的Reflection 操作式數據訪問可以大幅擴展。
我們接著了解如何通過Axiom 實現Reflection 操作。
首先,我們實際上必須在我們的智能合約中維護所有先前塊的緩存。在EVM 中,最後256 個塊哈希是原生可用的。我們可以證明,在每1024 個塊的批次中,前一個批次的最後一個塊的哈希會在下一個塊中提交。同樣,前一個批次中倒數第二個塊的哈希會在最後一個塊中提交,以此類推。因此,我們可以反向驗證這個哈希鏈,並通過零知識證明這個哈希鏈的有效性。
這使我們能夠從最近的塊開始,一直緩存到創世塊的塊哈希。實際上,我們在我們的主網智能合約中已經實現了這一點,它包含了從創世塊開始的每1024個塊哈希的緩存Merkle 路徑。
我們正在添加的另一個功能是Merkle Mountain Range。它建立在這個塊哈希緩存之上,是一種數據結構,使我們能夠在有限的DNA 中引用以太坊中的每個塊哈希。
一旦我們建立了緩存,我們可以通過對緩存中的塊進行驗證來查詢Axiom。為了實現這一點,我們必須證明我們試圖訪問的以太坊歷史數據中的每個數據實際上都承諾在某個塊的緩存中。其次,我們必須證明我們在此查詢上執行的所有計算都是正確的。為了在鏈上進行檢查,我們會驗證零知識證明的有效性。我們還會檢查它是否與我們在鏈上記錄的信息相關。我們始終將信任建立在我們的緩存或塊緩存中,並將這些塊緩存中的信息與零知識證明中的公共信息進行匹配。
現在我們來談談Reflection 操作設想中的可能應用。
水平軸表示數據複雜度,即實際上需要訪問多少數據才能實現該應用程序。垂直軸表示計算複雜度,即為完成此任務實際上需要應用多少計算資源。
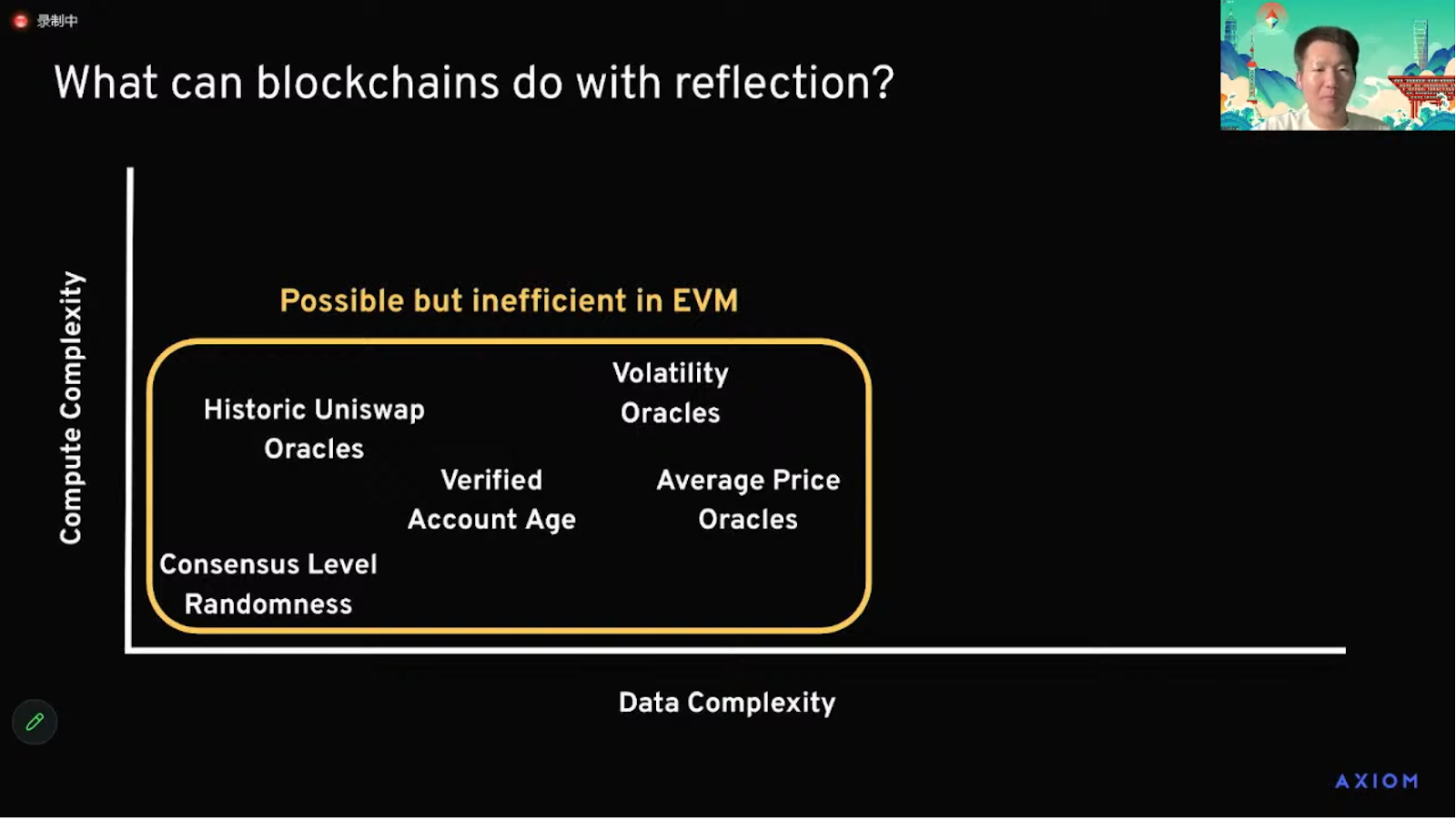
因此,第一類應用是Axiom 或任何類型的Reflection 操作機制可以在以太坊上實現的,但成本稍高的應用。
其中一些例子包括從以太坊共識層的區塊頭中讀取共識級隨機數,驗證歷史賬戶年齡,或從歷史價格信息中讀取不同類型的預言機數據。在EVM 中,可以採用各種解決方案來實現這些應用,但通過將這些解決方案置於零知識中,可以提高效率。
現在,還有另一類應用,大致上需要更多的數據訪問,因此需要更多的計算。在我看來,如果不使用ZK 協處理器,這些應用是無法實現的。
舉個例子,一個有趣的應用是允許以太坊上的Roll-up 以一種可信的方式讀取基礎層或另一個Roll-up 的狀態,使用零知識進行交互。其中一種應用可能是允許Roll-up 讀取ERC20 代幣的完整餘額快照。
如果我們將目光從存儲轉向賬戶的交易歷史,你可以想像通過記錄以太坊地址的完整歷史,構建一個可信的聲譽、身份或信用評分系統。這可能用於信用評分,或者用於讓你訪問某種類型的鏈上DAO,或者用於讓你獲得自定義NFT 的發行權限。
還有一類應用程序是使用鏈上的歷史數據來實際管理協議。一般稱為協議記賬。
這裡的想法是,協議的存在是為了協調參與者的行為,而協調的基本原則是能夠對參與者的行為進行獎勵或懲罰。如果你觀察以太坊上的許多協議,參與者的行動記錄實際上完全保存在鏈上。因此,使用Axiom,我們可以想像根據協議參與者的完整行動集合,協議可以確定支付結構,甚至對參與者進行某種類型的懲罰,我們認為這可以真正擴展協議應用的設計空間。
最後,如果我們真正提升計算的層次,我們認為使用機器學習模型來調整鏈上的參數可能會非常有趣。如果你思考傳統金融應用,基於大量歷史數據進行複雜的未來參數建模是非常常見的,例如價格數據、經濟數據等。而當我們看當前的DeFi,還遠遠沒有達到那個層次。我並不認為DeFi 應該與傳統金融工作方式完全相同,但我們確實認為註入一些歷史數據庫和基於機器學習的模型和信息可能有助於創建更具動態性的DeF i協議。
這些只是關於Reflection 操作可以為區塊鏈帶來的一些想法。
