經歷了半年的AI洗禮,或許很難找到比“應激反應”更恰當的詞,來形容今天科技行業中每個人的狀態——緊張、刺激、壓力。
“應激反應”, 是指生物體在遭遇外部環境壓力或威脅時,為了維持身體的穩態而產生的一系列反應。它是生物為了適應環境、確保生存所產生的一種自然反應。這種反應可以是短暫的,也可以是長期的。
7月26日,OpenAI官方推特宣布,安卓版ChatGPT已在美國、印度、孟加拉國和巴西提供下載,併計劃在近期推廣至更多國家。 ChatGPT正在拓展渠道,獲得更多的用戶和更強的使用粘性,生成式AI的浪潮在持續推高。
7月初,上海的2023世界人工智能大會(WAIC)上,一位大模型創業公司的技術人員正在展廳裡穿梭,她計劃為公司尋找一個性價比高的國產芯片解決方案,用來做大模型訓練。
“我們有1000張A100,但完全不夠。”她告訴虎嗅。
A100是英偉達的一款高端GPU,也是ChatGPT生長的硬件基礎。一些公開數據顯示,在訓練GPT系列模型的過程中,OpenAI所使用的英偉達GPU數量約2.5萬個。由此,要做大模型,要先評估能拿到多少張A100的顯卡,幾乎成了這個行業的慣例。
哪裡有GPU?哪裡有便宜算力?這只是2023WAIC大會上眾多問題的縮影。
過去半年裡所有被“應激”到的人,幾乎都渴望能夠在這場“盛會”中找到更多關於AI的答案。
2023WAIC現場
一家芯片展商的技術人員告訴虎嗅,在WAIC大會的幾天裡,他們的“大模型”展台前,來了好些產品經理,他們希望在這里為公司的大模型業務尋找產品定義。
5月28日在中關村論壇上,中國科學技術信息研究所發布的《中國人工智能大模型地圖研究報告》顯示,截至5月底,中國10億級參數規模以上的大模型發布了79個。在此後的兩個月裡,又有阿里雲的通義萬相、華為雲的盤古3.0、有道“子曰”等一系列AI大模型發布,據不完全統計目前國內的AI大模型已超過100個。
國內企業爭先恐後發布AI大模型的動作,就是“應激反應”最好的體現。這種“反應”帶來的焦慮,正在傳導給行業裡幾乎所有相關人員,從互聯網巨頭的CEO到AI研究機構的研究員,從創投基金合夥人到AI公司的創始人,甚至是很多AI相關的法律從業者,以及數據、網絡安全的監管層。
對行業之外的人而言,這可能只是短暫的狂歡,但在如今,又有多少人敢說自己置身AI之外。
AI正在開啟一個新時代,一切都值得用大模型重塑一遍。越來越多的人開始思考技術擴散之後的結果。
資金湧入,飛輪已現
ChatGPT誕生的一個月內,出門問問創始人李志飛兩赴矽谷,逢人必談大模型,在與虎嗅交談時,李志飛直言這是他最後一次“All in”。
2012年,李志飛創立出門問問,這家以語音交互、軟硬件結合為核心的人工智能公司經歷了中國兩次人工智能浪潮的起伏。在上一波人工智能最火熱的那一段時間,出門問問的估值一度被推至獨角獸級別,但此後也經歷了一段落寞期,直到ChatGPT的出現,才給沉寂多年的人工智能行業撕開了一道口子。
在一級市場,“熱錢正在湧進來。”
這是過去半年中,談及大模型時的行業共識。奇績論壇創始人陸奇認為,AI大模型是一個“飛輪”,未來將是一個模型無處不在的時代,“這個飛輪已經啟動”,而最大的推動力就是資本。
7月初,商業信息平台Crunchbase發布的數據顯示,分類為AI的公司在2023年上半年籌集了250億美元,佔全球融資的18%。雖然這一數字與2022年上半年的290億美元相比有所下降,但2023年上半年全球各行業的總融資額比2022年同比下降了51%,由此可見AI領域的融資額在全球融資總額中的佔比,幾乎提高了一倍。 Crunchbase在報告中這樣寫到:“如果沒有ChatGPT引發的人工智能熱潮,2023年的融資額會更低。”
到目前為止,2023年AI行業最大的一筆融資,就是微軟在1月對OpenAI投資的100億美元。
虎嗅根據公開數據統計,在美國的大模型公司創業中,Inflection AI或將成為人工智能領域融資量僅次於Open AI的第二大初創公司,在其之後分別是,Anthropic(15億美元) ,Cohere(4.45億美元)、Adept(4.15億美元)、Runway(1.955億美元)、Character.ai(1.5億美元)和Stability AI(約1億美元)。
在中國,2023年上半年國內人工智能行業的公開投融資事件共有456起。而這項統計在2018年-2022年的5年間分別是731、526、353、631和648。

上半年國內人工智能行業公開投融資事件
另一個引發飛輪的事件則是ChatGPT放出API接口。當OpenAI在3月首次開放ChatGPT的API接口時,AI行業內外對此幾乎形成共識:行業要變天了。隨著更多應用接入大模型,AI之上正在長出更加繁茂的森林。
“做大模型和做應用本身就應該分開”,投資人的嗅覺總是敏銳的,在源碼資本執行董事陳潤澤看來,AI是一個與半導體分工一樣的邏輯,AI大模型的繁榮之後,很快就會看到AI應用的一波繁榮。
今年年初,陳潤澤與同事一起前往矽谷時發現,矽谷聲名顯赫的創業孵化器Y Combinator(OpenAI首席執行官Sam Altman曾在這家孵化器任總裁多年),有一半的項目都轉型做生成式AI了。對於大模型的熱情,絲毫不遜於如今大洋彼岸的中國。
不過,他也發現在美國無論是資本還是創業者,相比於大模型創業,更看好基於大模型所做的生態應用,畢竟在這個賽道,已經跑出了諸如OpenAI這樣的公司,與此同時,美國有很強的ToB應用生態土壤,因此更多的美國公司正在嘗試基於大模型的生態做企業應用。
陳潤澤的觀察正在得到證實,大模型服務平台OpenCSG聯合創始人陳冉告訴虎嗅,如今,美國灣區90%以上的公司已經把大模型能力用到方方面面。至於中國,陳冉認為,在年底之前很多的客戶也都會用起來。
今年3月左右,陳潤澤和團隊開始嘗試在國內尋找基於大模型做應用的公司,但他發現這樣的公司很少。大量資本進入了人工智能行業,但如果追溯這些資金的流向會發現,更多的錢仍集中在頭部幾家公司中。
“即便是現在,10個與生成式AI相關的項目,能投1個-2個也已經是很不容易了。”除了源碼資本,虎嗅也與多位硬科技投資人交流,他們都表示,雖然項目看得多,但真正靠譜的鳳毛麟角。
應用端的這種態度,在很多業內人士看來,已是常態。
思必馳聯合創始人俞凱認為,表面看似熱鬧的賽道,其實更多的是名義上的競爭,結果無非兩種情況:“一種是為了融錢,純資本導向;另一種是做全域通用大模型的公司,確實需要喊,不喊的話別人不會知道。”
國內的一些統計數據也正在說明這個問題,根據第三方機構烯牛數據統計,截至2023年7月,國內有AIGC公司242家,1月以來AIGC賽道融資事件71起。而AI大模型賽道上的公司有67家,從ChatGPT發佈到現在,融資事件只有21起。
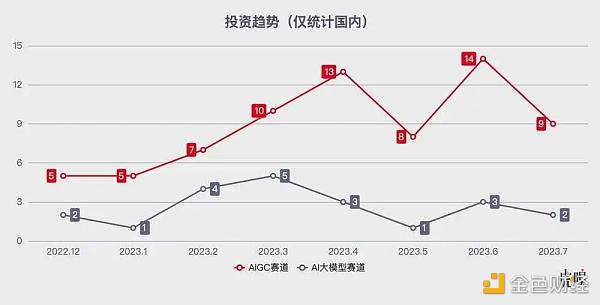
AIGC賽道和AI大模型賽道自ChatGPT發布後的融資事件|數據來源:烯牛數據
“現在國內AI市場上,好的標的太少了。”一位投資人如此告訴虎嗅——好項目太貴,便宜的又不靠譜。雖然目前國內發布的AI大模型數量過百,但國內一眾大模型公司中,獲得巨額融資的並不多,甚至屈指可數。
很多AI投資到最後都變成了投人——曾經的獨角獸公司創始人、互聯網大佬、具備大模型相關創業經驗的人等。
公司類型
公司
成立時間
大模型及相關產品
融資輪次
互聯網公司
百度
2012
文心一言
上市
阿里雲
2008
通義千問
上市
騰訊AI實驗室
1998
混元
上市
華為雲
2019
盤古
未上市
字節跳動
2016
火山方舟
未上市
京東雲
2012
言犀
上市
崑崙萬維
2008
天工
上市
360
1992
360智腦
上市
公司類型
公司
成立時間
大模型及相關產品
融資輪次
AI公司
商湯科技
2014
日日新
上市
科大訊飛
1999
訊飛星火
上市
雲從科技
2015
從容
上市
達觀數據
2015
曹植
C輪
出門問問
2014
序列猴子
D輪
智譜Al
2019
ChatGLM
B輪
瀾舟科技
2021
孟子
Pre-A輪
MiniMax
2021
Glow
股權投資
面壁科技
2022
VisCPM
天使輪
深言科技
2022
CPM
股權投資
聆心智能
2021
Al烏托邦
Pre-A輪
銜遠科技
2021
ProductGPT
天使輪
思必馳
2007
DFM-2
IPO終止
公司類型
公司
成立時間
大模型及相關產品
融資輪次
2023年成立都初創AI公司
光年之外
2023
暫無
A輪
百川智能
2023
baichuan
股權投資
零一萬物
2023
暫無
股權投資
國內AI大模型相關公司部分統計
今年的一眾AI明星項目中,智譜AI、聆心智能、深言科技和麵壁智能,都是清華實驗室孵化的公司。深言科技、面壁智能兩家公司均成立於2022年,且有AI行業內知名學者的技術背書。
比這幾家清華系AI公司成立時間更短的是一些互聯網行業大佬創立的AI公司,光年之外、百川智能和零一萬物均成立於這波大模型熱潮開始之後。
美團聯合創始人王慧文在2023年年初成立的光年之外,一度融資5000萬美元,已是彼時中國大模型行業為數不多的融資案例。與智譜AI、西湖心辰這類已有大模型為基礎的公司不同,光年之外是2023年2月開始,從零開始做大模型,其難度可想而知,6月29日,美團公告宣布收購光年之外的全部權益,總代價包括現金約2.33億美元(合人民幣16.7億元)、債務承擔約3.67億元、及現金1元。
“起碼要有自然語言處理背景的人,有一定大模型訓練實操經驗的人,以及數據處理、大規模算力集群等方面的專業人才。如果同時還要做應用,那應該還要有對應領域的產品經理和運營人才。”陳潤澤如此描述一個大模型核心團隊的標配。
大公司的AI賭注
過去半年中,老牌互聯網大廠們的AI新聞漫天紛飛。對AI大模型的投入,看似是在追熱點,但如百度、阿里、華為這樣的大公司,在AI上投下的賭注,顯然不是跟風。
巨頭們在AI上的押注很早就已開始,對這些公司來說,AI並不是一個新鮮的話題。虎嗅根據企查查數據不完全統計,各大廠在2018年開始就對人工智能相關的企業有不同程度的投資,從投資企業來看,大多是人工智能應用方面的企業,儘管涉及到一部分AI芯片企業,但是數量並不多,涉及大模型方面的企業幾乎沒有,並且大廠所投資的人工智能相關的公司大多與其業務息息相關。
大廠投資機構
投資企業數
平均持股比例
最高持股比例
100%持股企業數
阿里巴巴
23
36.25%
100%
5
百度風投
25
5.50%
15%
0
騰訊投資
54
17.54%
100%
2
三家互聯網大廠投資AI相關公司情況|數據來源:企查查
2017年阿里達摩院成立,研究對象涵蓋機器智能、智聯網、金融科技等多個產業領域,將人工智能的能力賦能到阿里的各個業務線中。 2018年,百度提出了“All in AI”的戰略。
有所不同的是,生成式AI的出現,似乎是一個轉折點。對於擁有數據、算力和算法資源優勢的科技巨頭來說,人工智能對他們已經不光是賦能場景,而是需要承擔基礎設施的角色,畢竟,生成式AI的出現,意味著針對人工智能產業的分工已經開始。
以百度、阿里、華為、騰訊,四家云供應商為代表的大廠,雖然都宣布了各自的AI策略,但明顯各有側重。
在過去的半年時間裡,巨頭紛紛發布自己的大模型產品。對於百度、阿里這樣的大廠來說,他們入局大模型的時間並不算晚,基本在2019年。
百度自2019年開始研發預訓練模型,先後發布了知識增強文心(ERNIE)系列模型。阿里的通義千問大模型也是始於2019年。除了百度和阿里的通用大模型,6月19日,騰訊雲發布了行業大模型的研發進展。 7月7日,華為雲發布了盤古3.0行業大模型產品。
這些側重也與各家的整體業務,雲戰略,以及在AI市場裡的長期佈局有所呼應。
百度的主線業務盈利能力在過去的5年中,出現了較大波動。百度很早就看到了基於搜索的廣告業務在國內市場中的問題,對此,百度選擇了大力投入AI技術尋找新機會。這些年來,百度不僅邀請過吳恩達、陸奇等業界大佬出任高管,在自動駕駛上投入熱情也遠超其他大廠。如此關注AI的百度,勢必會在這波大模型之爭裡重手投注。
阿里對通用大模型同樣表現出了極大的熱情。一直以來,阿里雲一直被寄予厚望,阿里希望走通技術路線創造集團的第二增長曲線。在電商業務競爭日趨激烈,市場增長放緩的大環境下,依雲而生的AI產業新機遇,無疑是阿里雲在國內云市場上再發力的好機會。
相比百度和阿里,騰訊雲在大模型方面選擇了優先行業大模型,而華為雲則公開表示只會關注行業大模型。
對於騰訊來說,近年來主營業務增長穩中向好。在通用大模型的前路尚不明朗的階段,騰訊對於AI大模型的投注相對謹慎。馬化騰在此前的財報電話會上談及大模型時曾表示:“騰訊並不急於把半成品拿出來展示,關鍵還是要把底層的算法、算力和數據紮紮實實做好,而且更關鍵的是場景落地。”
另一方面,從騰訊集團的角度看,騰訊目前有4所AI Lab,去年也發布了萬億參數的混元大模型,騰訊雲投身行業大模型方面的動作,更像是一種“不把雞蛋放在同一個籃子裡”的投注策略。
對於華為來說,一直以來都是重手投注研發,過去10年里華為在研發方面的總投入超過9000億元。但由於手機業務遇到發展障礙,華為在很多技術研發上的整體策略或也正在面臨調整。
一方面手機業務是華為C端技術最大的出口,如果手機業務不為通用大模型買單的話,那麼華為研發通用大模型的動力就會明顯下降。而對於華為來說,把賭注押在能快速落地變現的行業大模型,似乎是這場AI博弈當中的最優解。正如華為雲CEO張平安所說“華為沒有時間作詩”。
不過,對科技巨頭來說,無論賭注多大,只要能賭對,就能夠先一步搶占基礎設施的市場份額,從而在人工智能時代獲得話語權。
拿著錘子找釘子
對於商業公司來說,所有的決策仍然落到經濟賬上。
即便是一筆不小的投入,越來越多有遠見的公司創始人也意識到,這是一項未來必須要做的事情,即便前期投入可能完全看不到回報。
AI大模型的研發需要一筆不小的投入,但越來越多企業創始人、投資人都認為,這是一項”必要投入”,即便眼下完全看不到回報。
由此,很多在上一波AI浪潮下誕生的人工智能公司,都在沉寂良久之後看到了新的曙光。
“3年前,大家都說GPT-3是通向通用人工智能的可能性。”李志飛在2020年就開始帶著一班人馬研究GPT-3,彼時出門問問正處在一個發展的轉折點,他們希望探索新業務,但經過一段時間的研究之後,李志飛的大模型項目中止了,原因之一是當時模型不夠大,另外就是找不到商業落地場景。
不過,2022年底ChatGPT問世以後,李志飛彷彿被扎了一劑強心針,因為他和所有人一樣,看到了大模型的新機會。今年4月,出門問問發布了自研的大模型產品——序列猴子。眼下,他們準備拿著新發布的大模型“序列猴子”衝刺港交所,出門問問已在5月末遞交了招股書。
另一家老牌AI公司也在跟進,去年7月,思必馳向科創板遞交了IPO申請,在今年5月被上市審核委員會否決。
俞凱坦言,就連OpenAI,在GPT2階段也是用微軟的V100訓練了將近一年的時間,算力和A100差好幾個量級。思必馳在大模型前期積累階段,也是用更為經濟的卡做訓練。當然,這需要時間作為代價。
相比於自研大模型,一些應用型公司有自己的選擇。
一家在線教育公司的總裁張望(化名)告訴虎嗅,過去半年,他們在大模型應用場景的探索上不遺餘力,但他們很快發現在落地過程中存在諸多問題,例如成本與投入。這家公司的研發團隊有50人-60人,開始做大模型研究以來,他們擴充了研發團隊,新招了一些大模型方面的人才,張望說,偏底層模型方面的人才很貴。
張望從未想過從頭開發大模型,考慮到數據安全和模型穩定性等問題,他也不打算直接接入API做應用。他們的做法是參考開源大模型,用自己的數據做訓練。這也是很多應用公司目前的做法——在大模型之上,用自己的數據做一個行業小模型。張望他們從70億參數的模型開始,做到100億,現在在嘗試300億的模型。但他們也發現,隨著數據量增多,大模型訓練會出現的情況是,可能新版本不如上一個版本,就要對參數逐一調整,“這也是必須要走的彎路。”張望說。
張望告訴虎嗅,他們對於研發團隊的要求就是——基於公司的業務探索AI大模型場景。
這是一種拿著“錘子”找“釘子”的方法,但並不容易。
“目前最大的難題是找到合適的場景。其實有很多場景,即便用了AI,效果也提升不了太多。”張望說,例如在上課的場景中,可以用AI大模型賦能一些交互模式,包括提醒學員上課功能、回答問題和打標籤等,但他們試用了AI大模型之後,發現精準度不行,理解能力和輸出能力並不理想。張望的團隊嘗試過一段時間後,決定在這個場景裡暫時放棄AI。
另一家互聯網服務商小鵝通,也在AI大模型爆發後第一時間開展了相關業務的探索。小鵝通的主要業務是為線上商家提供數字化運營工具,包括營銷、客戶管理以及商業變現。
小鵝通聯合創始人兼COO樊曉星告訴虎嗅,今年4月,當越來越多的應用基於生成式AI誕生時,小鵝通看到了這個技術背後的潛力,“例如MidJourney,生成式AI對於設計圖像生成方面的提效確實有目共睹。”樊曉星她們在內部專門組織了AI研究的業務線,尋找與自身業務相關的落地案例。
樊曉星說,在將大模型接入業務的過程中,她所考慮的就是成本和效率,“大模型的投入成本還是蠻高的。”她說。
互聯網行業的“釘子”算是好找的,AI落地真正的難點還是在工業、製造這樣的實體產業。
俞凱告訴虎嗅,這一波AI浪潮仍然是螺旋式上升、波浪式前進,在產業落地上面的矛盾一點都沒變化,只是換了一個套殼而已。所以從這個意義上看,這兩次AI浪潮的規律是相同的,最好的辦法就是學習歷史——“上一波AI浪潮的教訓,這次就別再犯了。”
雖然很多廠商在AI大模型的落地方面都喊出了“產業先行”的口號,但很多實體產業的場景真的很難與目前的AI大模型相匹配。比如在一些工業檢測場景應用的AI視覺檢測系統,即便對AI模型的需求沒有高到10億參數的量級,但初期的訓練數據仍然捉襟見肘。
以一個簡單的風電巡檢場景為例,一個風場的巡檢量達到七萬台次,但同樣的裂痕數據,可能只會出現一次,機器可以學習的數據量是遠遠不夠的。擴博智能風電硬件產品總監柯亮告訴虎嗅,目前風機葉片的巡檢機器人還做不到100%的精確分析葉片裂痕,因為可供訓練和分析的數據量太小了,要形成可靠的全自動巡檢和識別,還需要大量的數據積累和人工分析。
不過,在工業數據積累較好的場景中,AI大模型已經可以做到輔助管理複雜的三維模型零件庫了。國內某飛機製造企業的零件庫就已經落地了一款基於第四範式“式說”大模型的零件庫輔助工具。可以在十萬餘個三維建模零件中,通過自然語言實現三維模型搜索,以三維模型搜三維模型,甚至還能完成三維模型的自動裝配。這些功能,在很多卡住製造業脖子的CAD、CAE工具中都需要經過多步操作才能完成。
今天的大模型和幾年前的AI一樣面臨落地難題,一樣要拿著錘子找釘子。有人樂觀地相信,今天的錘子和過去完全不一樣了,但到了真金白銀地為AI付費時,結果卻有些不同。
彭博社在7月30日發布的Markets Live Pulse調查顯示,在514名受調投資者中,約77%的人計劃在未來六個月內增加或保持對科技股的投資,且只有不到10%的投資者認為科技行業面臨嚴重的泡沫危機。然而這些看好科技行業發展的投資者中,卻只有一半人對AI技術持開放的接受態度。
50.2%的受訪者表示,目前還不打算為購買AI工具付費,多數投資公司也沒有計劃將AI大範圍應用到交易或投資中。
賣鏟子的人
“如果你在1848年的淘金熱潮裡去加州淘金,一大堆人會死掉,但賣勺子和鏟子的人,永遠可以賺錢。”陸奇在一次演講時說。
高峰(化名)想當這樣的“賣鏟子的人”,準確地說,是能夠“在中國賣好鏟子的人”。
作為一名芯片研究者,高峰大部分科研時間都在AI芯片上。過去一兩個月,他感到了一種急迫性——他想做一家基於RISC-V架構的CPU公司。在一家茶室,高峰向虎嗅描繪了未來的圖景。
然而,要從頭開始做AI芯片,無論是在芯片界,還是在科技圈,都像是一個“天方夜譚”。
當AI大模型的飛輪飛速啟動時,背後的算力逐漸開始跟不上這一賽道中玩家的步伐了。暴漲的算力需求,使英偉達成了最大的贏家。但GPU並非解決算力的全部。 CPU、GPU,以及各種創新的AI芯片,組成了大模型的主要算力提供中心。
“你可以把CPU比喻為市區,GPU就是開發的郊區。”高峰說,CPU和AI芯片之間,需要通過一個叫做PCIE的通道連接,數據傳給AI芯片,然後AI芯片再把數據回傳給CPU。如果大模型的數據量變大,一條通道就會變得擁擠,速度就上不去,因此需要拓寬這條路,而只有CPU能夠決定這條通路的寬窄,需要設置幾車道。
這意味著,中國在大模型上,即便突破了AI芯片,仍有最關鍵的CPU難以破局。哪怕是在AI訓練上,越來越多的任務可以被指派給GPU承擔,但CPU依舊是最關鍵的“管理者”角色。

2023WAIC大模型展區展出的部分國產芯片
自1971年英特爾造出世界上第一塊CPU至今50餘年,在民用服務器、PC市場,早已是英特爾和AMD的天下,英特爾更是建立起涵蓋知識產權、技術積累、規模成本、軟件生態於一體的整個商業模式壁壘,且這種壁壘從未衰退。
要完全拋開X86架構和ARM架構,基於一個全新架構研發完全自主的CPU芯片,可以說是“九十九死一生”,基於MIPS指令集的龍芯,在這條路上走了20多年,更不用說是RISC-V這樣未被充分開墾和驗證過的開源架構。
指令集,就像一塊塊土地,基於指令集開發芯片,就相當於是買地蓋房子。 X86的架構是閉源的,只允許Intel生態的芯片,ARM的架構需要支付IP授權費,而RISC-V是免費的開源架構。
產業界和學術界已經看到了這樣的機會。
2010年,加州伯克利兩位教授的研究團隊從零開始開發了一個全新的指令集,就是RISC-V,這個指令集完全開源,他們認為CPU的指令集不應該屬於任何一家公司。
“RISC-V或許是中國CPU的一道曙光。”高峰說。 2018年,他在院所孵化了一家AI芯片公司,彼時他表示,自己不想錯過AI浪潮發展的機會,這一次,他依然想抓住,而這個切入點,就是RISC-V。在大模型以及如今國產替代的時代,這個需求顯得更為緊迫,畢竟,極端地考慮一下,如果有一天,中國公司用不了A100了,又該怎麼辦。
“如果要取代ARM和X86,RISC-V的CPU需要性能更強,也需要和Linux上做商業操作系統的人參與到代碼的開發中。”高峰說。
高峰不是第一個意識到這個機會的人,一位芯片行業投資人告訴虎嗅,他曾與一家芯片創業公司創始人聊起,用RISC-V的架構去做GPU的機會。如今,在中國已有一些基於RISC-V架構做GPU的公司,但生態依舊是他們面臨的最大的問題。
“Linux已經示範了這條路是可以走通的。”高峰說,在Linux這套開源操作系統中,誕生了紅帽這樣的開源公司,如今許多雲服務都建立在Linux系統上。 “需要足夠多的開發者。”高峰提出了一個方法。這條路很難,但走通了,將是一條光明的道路。
飛輪轉得太快了
大模型的“應激反應”下,感到急迫的不光是高峰。
國內某AI大模型公司聯創告訴虎嗅,今年初他們也曾短暫上線過一款對話大模型,但隨著ChatGPT的升溫,有關部門提高了對大模型安全性的重視,並對他們提出了很多整改要求。
“在沒有特別明確的監管政策出來之前,我們不會輕易把產品開放給普通用戶,主要還是To B的邏輯。”左手醫生CEO張超認為,在《管理辦法》出台之前,貿然將生成式AI產品開放給C端用戶,風險很大。 “現階段,我們一方面在持續迭代優化,另外一方面也在持續關注政策、法規,保證技術的安全性。”
“生成式AI的監管辦法還不明確,大模型公司的產品和服務普遍很低調。”一家數字化技術供應商,在6月發布了一款基於某雲廠商通用大模型開發的應用產品,在發布會上,該公司技術負責人向虎嗅表示,他們被這家云廠商要求嚴格保密,如果透露使用了誰的大模型,他們會被視為違約。而對於為何要對案例保密,這位負責人分析,可能很大一部分原因是要規避監管風險。
在全球都對AI提高警惕的當下,任何市場都不能接受監管的“真空期”。
7月13日,網信辦等七個部門正式發布了《生成式人工智能服務管理暫行辦法》(下文簡稱“《管理辦法》”),該辦法自2023年8月15日起施行。
“《管理辦法》出台後,政策會從問題導向轉為目標導向發展就是我們的目標。”觀韜中茂律師事務所合夥人王渝偉認為,新規是重“疏”而不重“堵”。
瀏覽美國的風險管理庫,是王渝偉每天必需的功課,“我們正在為利用GPT等大模型進行細分行業的商業應用提供風控合規的方案,建立一套合規治理框架。”王渝偉說。
美國的AI巨頭們正排著隊向國會表忠心。 7月21日,谷歌、OpenAI、微軟、Meta、亞馬遜、AI創業公司Inflection、Anthropic,七家最具影響力的美國AI公司,就在白宮簽署了一份自願承諾。保證在向公眾發布AI系統前允許獨立安全專家測試他們的系統。並與政府和學術界分享有關他們系統安全的數據。他們還將開發系統,當圖像、視頻或文本是由AI生成時向公眾發出警告,採用的方法是“加水印”。

7家美國AI巨頭排代表在白宮簽署AI承諾
此前,美國國會聽證會上,OpenAI的創始人山姆·奧特曼表示,需要為人工智能模型創建一套安全標準,包括評估其危險能力。例如,模型必須通過某些安全測試,例如它們是否可以“自我複制”和“滲透到野外”。
或許山姆·奧特曼自身也沒有想到,AI的飛輪會轉得這麼快,甚至有失控的風險。
“我們一開始還沒有意識到這件事情這麼緊迫。”王渝偉說,直到上門來諮詢的公司創始人越來越多。他感到,這一次的人工智能浪潮正在發生與過去截然不同的變化。
今年年初,一家最早接入大模型的文生圖公司找到王渝偉,這家公司希望把自己的業務引入中國,因此,他們想了解這方面的數據合規業務。緊接著,王渝偉發現,這類的諮詢越來越多,更明顯的變化是,前來諮詢的不再是公司的法務,而是創始人。 “生成式AI的出現,原有的監管邏輯已經很難適用。”王渝偉說。
從事大數據法律工作多年的王渝偉發現,生成式AI與上一波AI浪潮正在呈現更加底層的變化。例如,上一次的AI更多是基於算法進行推薦,還有就是一些人臉識別,都是針對一個場景,針對一些小模型,在具體應用場景當中進行訓練,涉及的法律問題不外乎知識產權、隱私保護的問題。而在這個生成式AI生態之上的不同角色,例如提供底層大模型的公司,在大模型之上接入做應用的公司,存儲數據的雲廠商等,對應的監管都不盡相同。
目前大模型所帶來的伴生風險已經有了共識,業界明白,商業化應用勢必會放大這種風險,要想保持業務的連續性,就需要重視監管。
難點就是,“如何找到一條既能做好監管,又能不影響行業發展的路徑。”王渝偉說。
結語
對於整個行業來說,在對技術加深探討的同時,也正在引發更為深遠的思考。
在AI逐漸佔據科技產業的主導地位之時,要如何確保技術的公正、公平和透明性?當頭部公司緊緊掌控技術和資金流向時,如何確保中小企業和初創公司不被邊緣化?大模型的開發和應用蘊含巨大潛力,但盲目跟風是否會導致我們忽視其他創新技術?
“從短期來看AI大模型正在被嚴重高估。但從長期看,AI大模型被嚴重低估了。”
半年時間裡,AI熱浪翻湧。然而對於中國的創業公司和科技巨頭來說,在熱炒的市場氛圍中,如何保持清醒的判斷,做出長遠的規劃和投資,將是檢驗其真正實力和遠見的關鍵。