

自中本聰決定在創世區塊中嵌入一條信息以來,比特幣鏈的數據結構已經經歷了一系列的變革。
我在2022年開始深入研究區塊鏈開發,首本閱讀的書籍就是《精通以太坊》。這本書極其出色,為我提供了大量關於以太坊和區塊鏈基礎知識的深入理解。然而,從現在的視角來看,書中的一些開發技巧已經顯得有些過時。初步步驟涉及在個人筆記本電腦上運行一個節點,即使是為了錢包dApp,也需要自行下載一個輕節點。這反映了2015年至2018年間區塊鏈開發生態系統中早期開發者和黑客的行為模式。
回溯到2017年,我們並未有任何節點服務提供商。從供需關係的角度來看,由於用戶活動有限,他們的主要功能是進行交易。這意味著自行維護或託管一個完整節點並不會產生太大的負擔,因為沒有太多的RPC請求需要處理,轉賬請求也並不頻繁。大部分的以太坊早期採用者都是技術極客。這些早期用戶對區塊鏈開發有深入的理解,並且習慣於通過命令行或集成開發環境直接維護以太坊節點、創建交易和管理賬戶。
因此,我們可以觀察到早期的項目通常具有非常簡潔的用戶界面/用戶體驗。其中一些項目甚至沒有前端,用戶活動相當低。這些項目的特點主要由兩個因素決定:用戶行為和鏈的數據結構。
節點提供者的崛起
隨著越來越多的無編程背景的用戶投身於區塊鍊網絡,去中心化應用的技術架構也隨之發生了變化。原先由用戶託管節點的模式逐漸轉變為由項目方進行節點託管
人們趨向於選擇節點託管服務,主要原因是鏈上數據的迅速增長使得個人託管節點的成本隨著時間推移而逐漸增大。
然而,對於小型項目的開發者而言,由項目團隊自行託管節點仍然是一項挑戰,它需要持續的維護投入和硬件成本。因此,這種複雜的節點託管過程通常被委託給專門從事節點維護的公司來處理。值得一提的是,這些公司在大規模建設和籌集資金的時間點與北美科技產業興起的雲服務趨勢相吻合。
Project Category Established since Alchemy Nodes 2017 Infura Nodes 2016 NowNodes Nodes 2019 QuickNodes Nodes 2017 Ankr Nodes 2017 ChainStack Nodes 2018
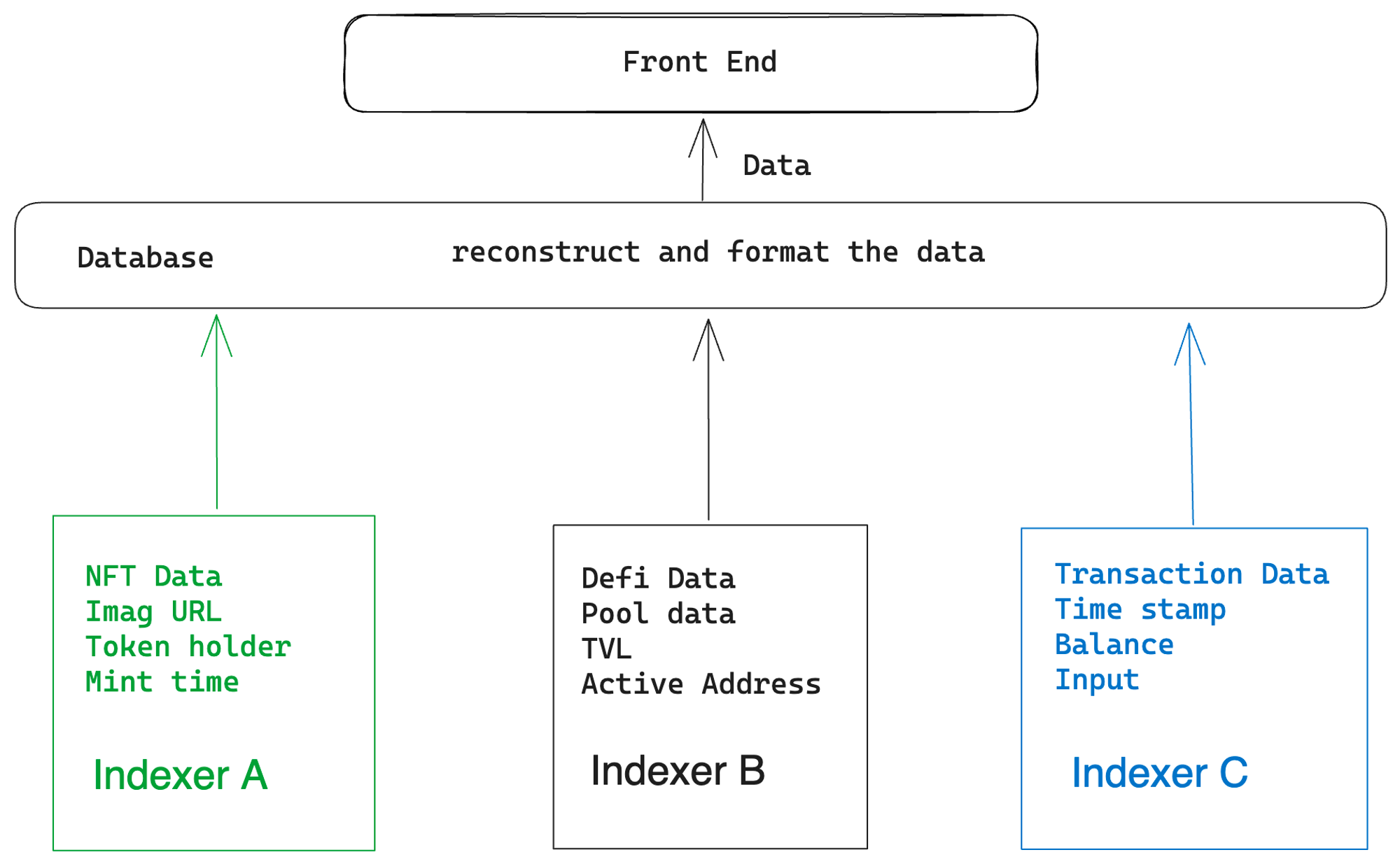
僅僅通過遠程託管節點並不能完全解決問題,尤其是在DeFi、NFT等相關協議興起的現在。開發者需要處理大量的數據問題,因為由區塊鏈節點本身提供的數據被稱為原始數據,這些數據並不是經過標準化和清洗處理的。其中的數據需要被提取、清洗和加載。
例如,假設我是一個NFT項目的開發者,我想要進行NFT交易或者展示NFT。那麼我的前端就需要實時讀取個人EOA賬戶中的NFT數據。 NFT實際上只是一種標準化的代幣形式。擁有一個NFT意味著我擁有由NFT合約生成的一種唯一ID的代幣,而NFT的圖像實際上是元數據,可能是SVG數據或者指向IPFS上的圖像鏈接。儘管以太坊的Geth客戶端提供了索引指令,但對於一些前端需求較大的項目來說,連續請求Geth然後返回前端在工程上是不切實際的。對於一些功能,比如訂單拍賣和NFT交易聚合,它們必須在鏈下進行,以收集用戶的指令,然後在適當的時機將這些指令提交到鏈上。
因此,一個簡單的數據層應運而生。為了滿足用戶的實時性和準確性要求,項目方需要構建自己的數據庫和數據解析功能。
數據索引器是如何演變的?
啟動一個項目通常是相對簡單的事情。你擁有一個構思,設定了一些目標,找到了最優秀的工程師,搭建了一個實用的原型,這通常包括前端和幾個智能合約。
然而,要讓項目規模化卻是相當困難的。人們需要從項目開始的第一天就對設計結構進行深思熟慮。否則,你很快就會遇到一些問題,我通常將這種情況稱之為“結冰問題”。

我從《鋼鐵俠》電影中藉鑑了這個術語,它似乎非常適合描述大多數創業公司的境遇。當初創公司快速增長(吸引了大量用戶)時,他們常常會遭遇困境,因為他們最初並未預見到這種情況。在電影中,反派角色因為沒有考慮到“結冰問題”,從未預料到他的戰爭裝備會飛入太空。同樣,對於許多Web3項目的開發者來說,“結冰問題”涉及到處理大規模用戶採用帶來的負擔增加。隨著用戶數量的急劇增長,這給服務器端帶來了沉重的壓力。還有一些問題是與區塊鏈本身相關的,例如網絡問題或者節點關閉。
大多數情況下,這是後端的問題。比如在一些區塊鏈遊戲協議中,這種情況屢見不鮮。當他們計劃增加更多的服務器並且僱傭更多的數據工程師來解析鏈上數據的時候,並沒有預見到會有如此多的用戶參與進來。等他們意識到這一點時,已經晚了。而且這些技術問題並不能僅僅通過增加更多的後端工程師來解決。正如我之前所說,這些考慮應該從一開始就納入到計劃中。
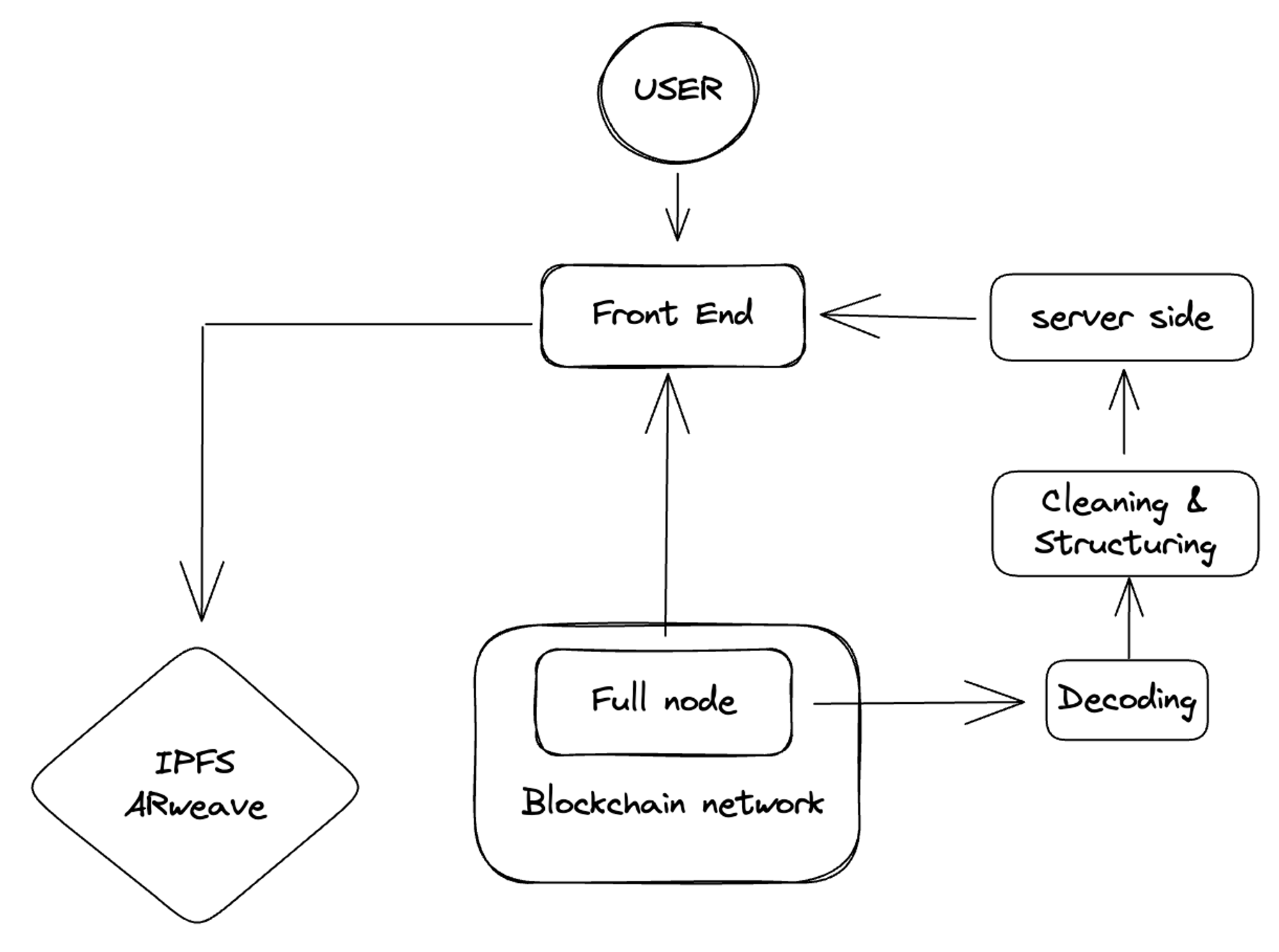
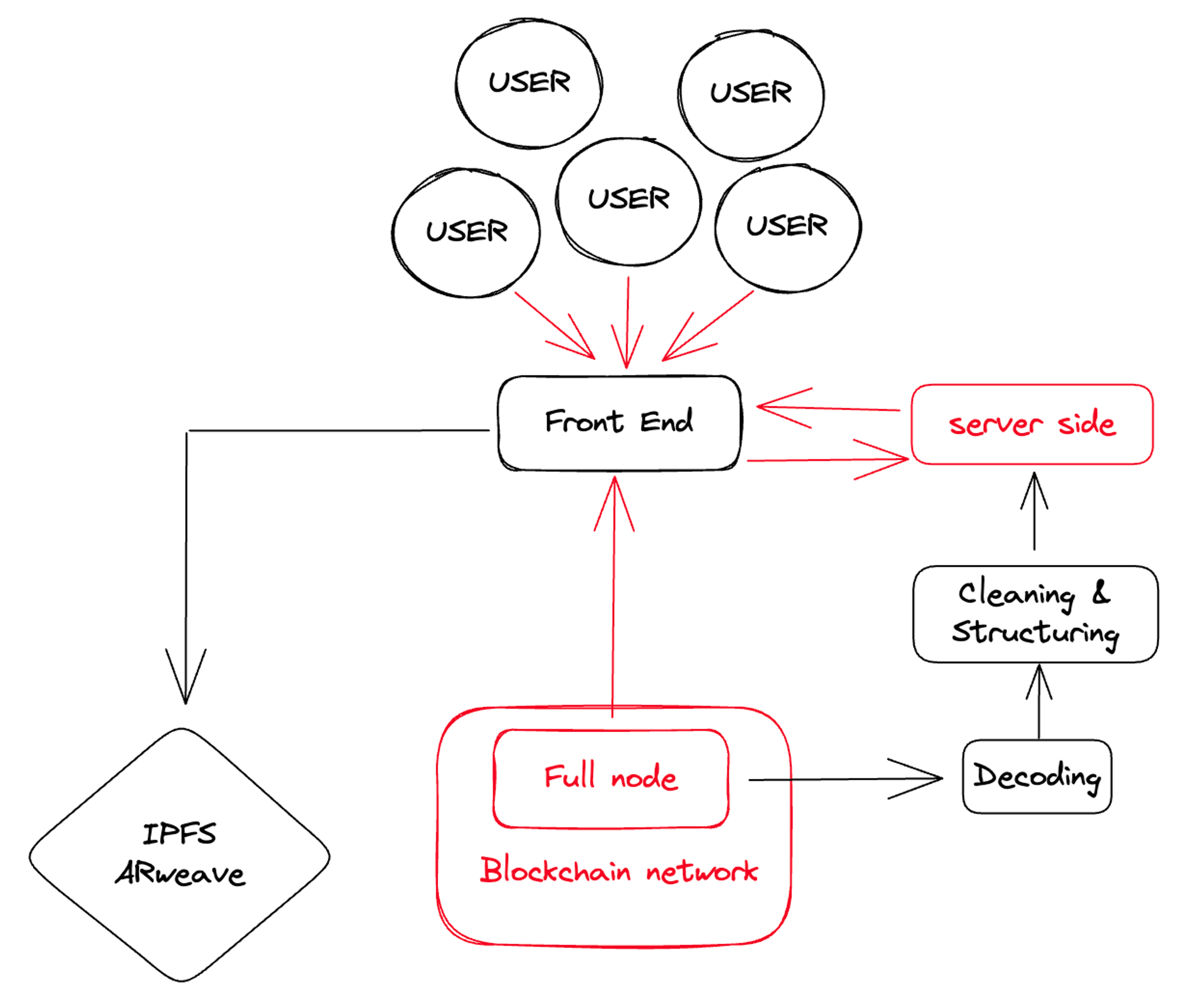
第二個問題涉及到添加新的區塊鏈。你可能一開始就避開了服務器端的問題,並且聘請了一批優秀的工程師。但是,你的用戶可能對當前的區塊鏈不滿意。他們希望你的服務也能在其他流行的鏈上運行,比如zk鍊或L2鏈。你的項目架構最終可能會變成如下這樣:
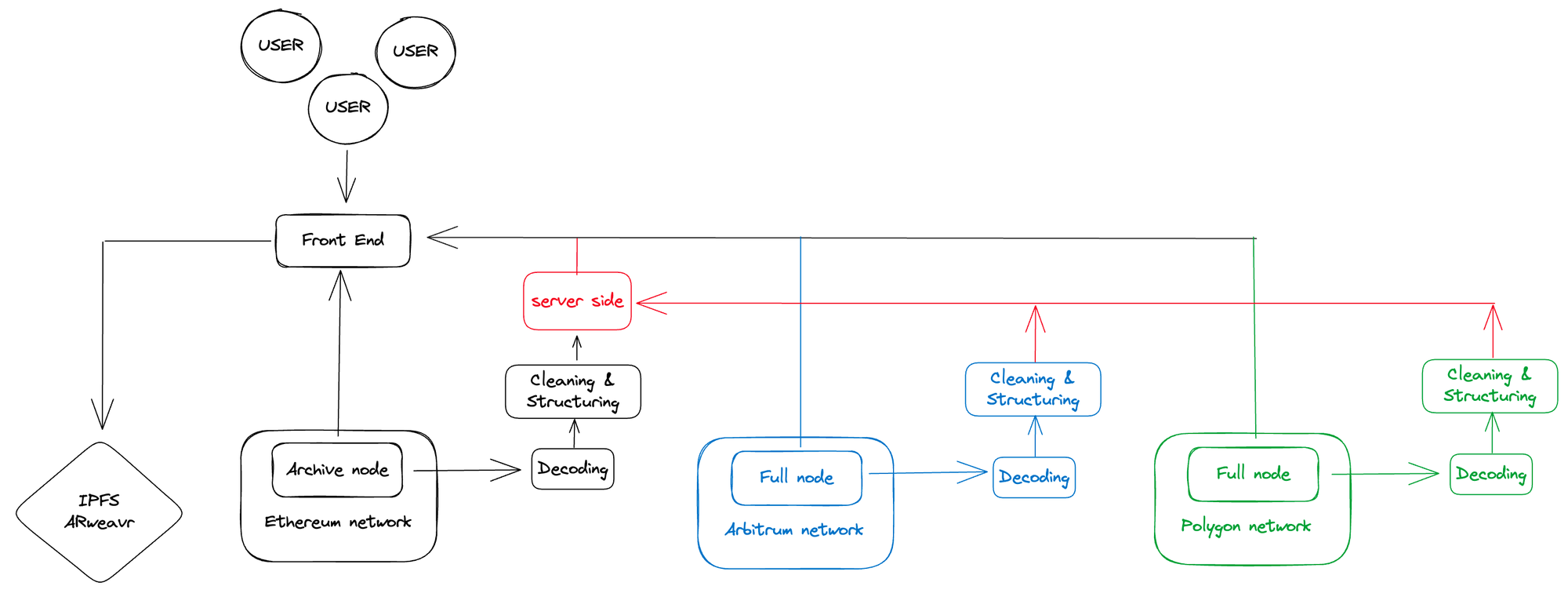
在這種系統中,你對自己的數據有完全控制權,這有助於更好地管理和提高安全性。系統限制調用請求,降低過載風險並提高效率。而且該設置與前端兼容,能確保無縫集成和用戶體驗。
然而,運營和維護成本會成倍增加,這可能會給你的資源帶來壓力。每次添加新的區塊鏈都需要重複的工作,這可能會耗費大量時間且效率低下。從大量數據集中選取數據可能會降低查詢時間,潛在地減緩進程速度。由於區塊鍊網絡問題(如回滾和重組),數據可能會受到污染,從而危及數據的完整性和可靠性。
項目的設計反映了你的團隊成員。添加更多節點並試圖構建一個以後端為重的系統意味著你需要雇傭更多工程師來操作這些節點和解碼原始數據。
這種模式類似於互聯網初期,電子商務平台和應用程序開發人員選擇建立自己的IDC(互聯網數據中心)設施。然而,隨著用戶請求的增長和區塊鍊網絡的狀態爆發,成本與程序設計的複雜性齊頭並進。此外,這種方法阻礙了市場的快速擴張。某些高性能的公共區塊鏈要求硬件密集型的節點操作,而數據同步和清理則不斷消耗人力資源和時間成本。
如果你試圖構建一個基於區塊鏈的NFT市場或酷炫的遊戲,那麼你的團隊成員中有65%是後端和數據工程師,這難道不奇怪嗎?
也許開發人員會想,為什麼沒有人幫他們解碼和傳輸這些鏈上數據,這樣他們就可以專注於構建更好的產品。
我相信這就是索引器出現的原因。
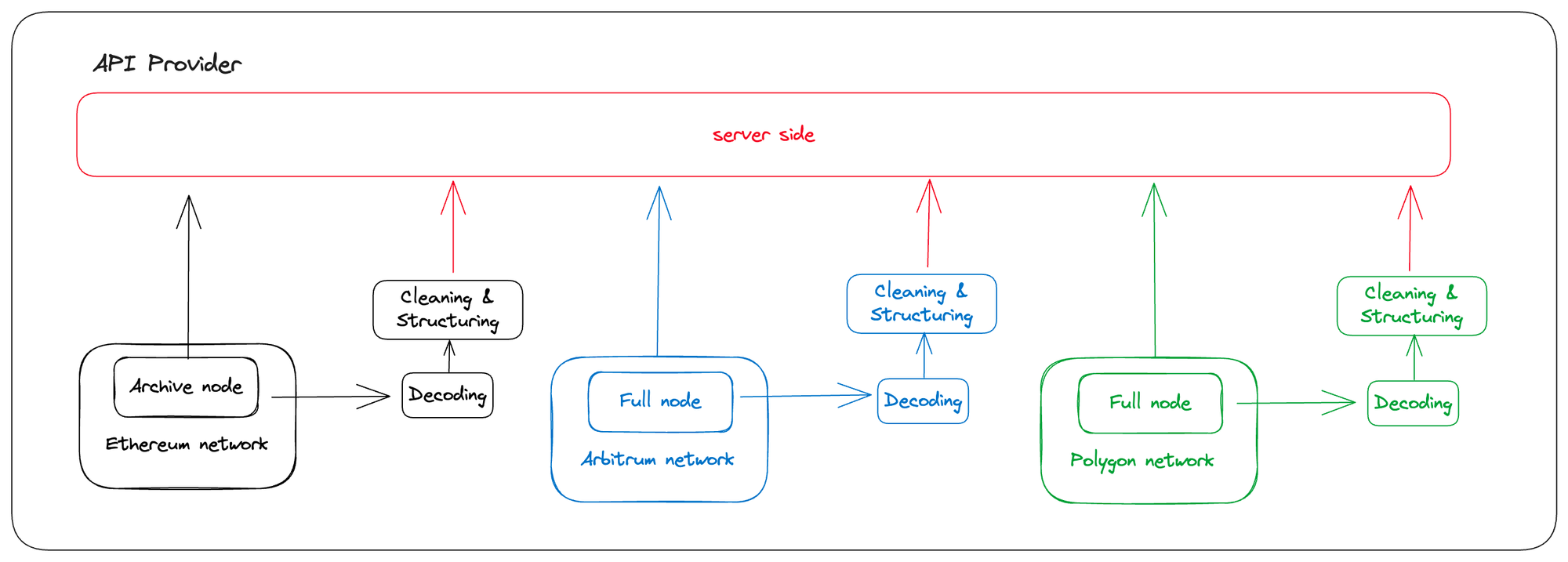
為了降低接入Web3應用程序和區塊鍊網絡的難度,包括我們在內的許多開發團隊選擇將存檔節點維護、鏈上數據ETL(提取、轉換、加載)和數據庫調用等步驟進行整合。這些任務原本需要項目團隊自行維護,現在則通過提供多鏈數據和節點API的方式,實現了集成化運作。
借助這些API,用戶可以根據自己的需求定制鏈上數據。這涵蓋了從熱門NFT元數據、監控特定地址的鏈上活動,到追踪特定代幣流動性池的交易數據等各類需求。我經常將這種方法稱為現代Web3項目結構的一部分。
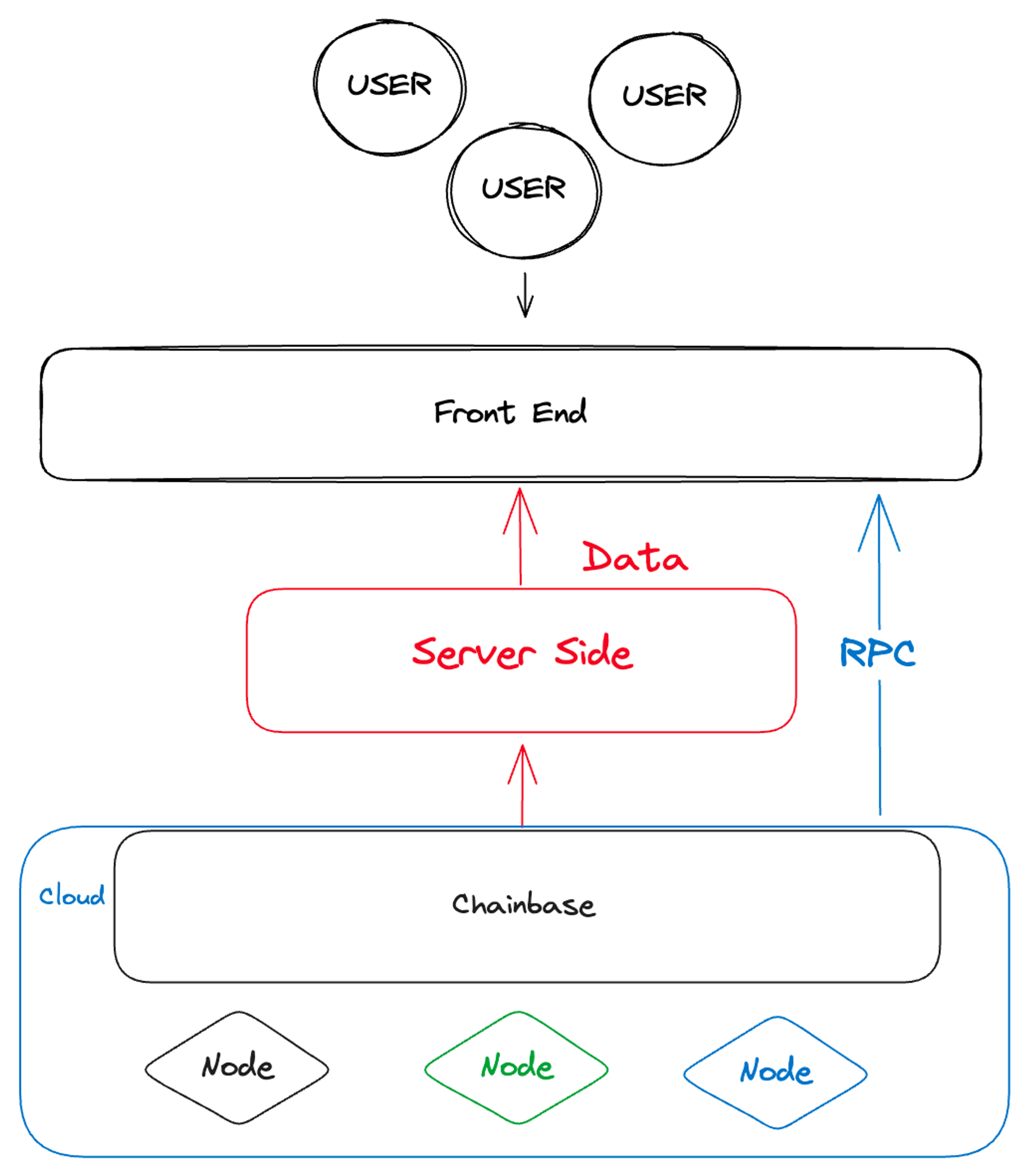
數據層和索引層項目的融資和建設主要在2022年進行。我相信,這些索引層和數據層項目的商業實踐與它們底層數據架構的設計密切相關,特別是與OLAP(On-Line Analytical Processing,聯機分析處理)系統的設計關係深刻。採用合適的核心引擎,是優化索引層性能的關鍵,包括提升索引速度和保障其穩定性。常用的引擎有Hive、Spark SQL、Presto、Kylin、Impala、Druid、ClickHouse等。其中,ClickHouse是一個功能強大的數據庫,在互聯網公司中廣泛應用,它在2016年開源,而且在2021年獲得了2.5億美元的融資。
因此,新一代的數據庫和改進的數據索引優化架構的出現,促成了Web3數據索引層的創建。這使得在此領域的公司能以更快速、更高效的方式提供數據API服務。
然而,鏈上數據索引的大樓目前仍然被兩朵烏雲籠罩。
兩朵烏雲
第一朵烏雲關乎區塊鍊網絡穩定性對服務器端造成的影響。儘管區塊鍊網絡具有很強的穩定性,但在數據傳輸和處理過程中並非如此。例如,區塊鏈的重組(reorgs)和回滾(rollbacks)等事件可能對索引器的數據穩定性構成挑戰。
區塊鏈重組指的是節點暫時失去同步,導致兩個不同版本的區塊鏈同時存在。這樣的情況可能由系統故障、網絡延遲,甚至惡意行為引發。當節點重新同步時,它們將收斂到一個唯一的官方鏈,而先前的替代“分叉”區塊則會被拋棄。
在重組發生時,索引器可能已經處理了來自最終被拋棄區塊的數據導致數據庫被污染。因此,索引器必須適應這種情況,丟棄無效鏈上的數據,並重新處理新接受的鏈上的數據。
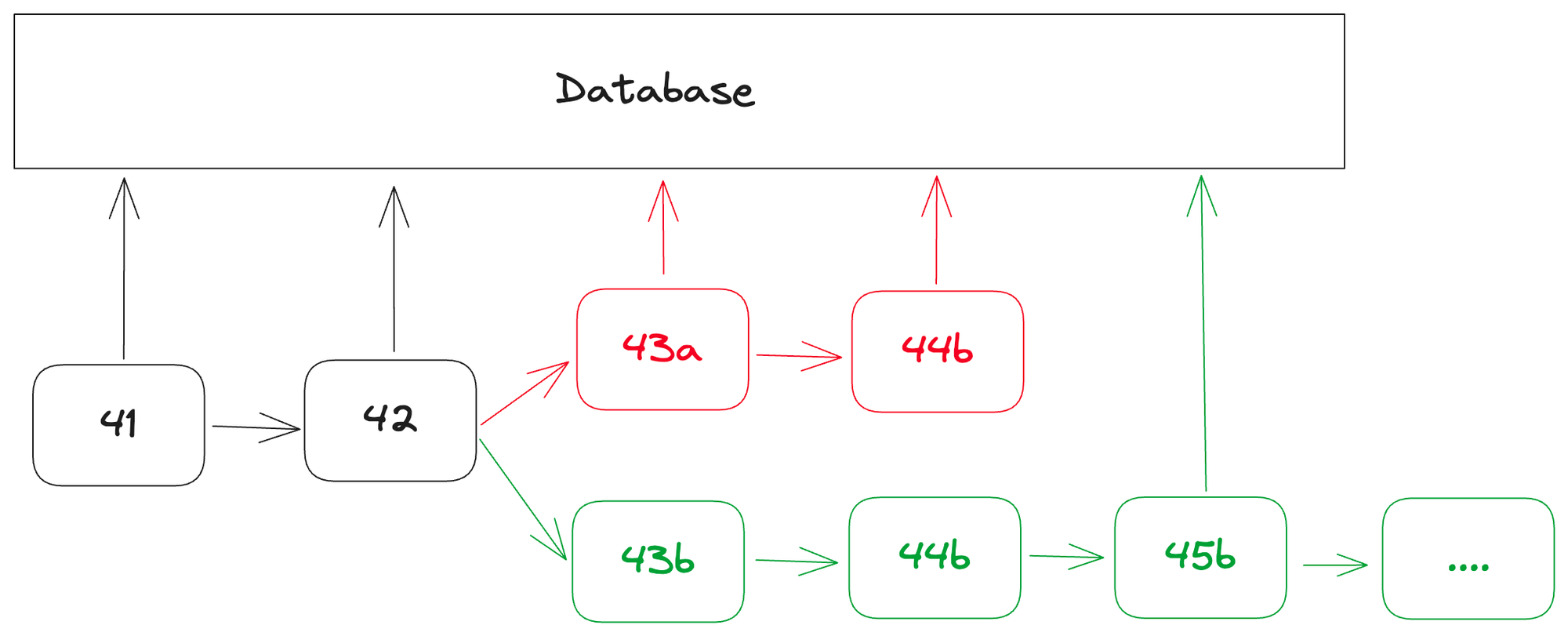
這類調整可能會導致資源使用增加,並有可能延遲數據的可用性。在極端的情況下,頻繁或大規模的區塊重組可能會嚴重影響依賴於索引器的服務的可靠性和性能,包括那些使用API獲取數據的Web3應用程序。
此外,我們還面臨著關於數據格式兼容性和區塊鍊網絡間數據標準多樣性的問題。
在區塊鏈技術領域中,存在眾多不同的網絡,每一個網絡都擁有自己獨特的數據標準。比如,有EVM(以太坊虛擬機)兼容鏈、非EVM鏈,以及zk(零知識)鏈,每一種鏈都有其特殊的數據結構和格式。
這對索引器來說無疑是個大挑戰。為了通過API提供有用且準確的數據,索引器需要能夠處理這些多樣化的數據格式。但是,由於區塊鏈數據沒有通用標準,不同的索引器可能會使用不同的API標準。這可能導致數據兼容性問題,即從一個索引器提取和轉換的數據可能無法在另一個系統中使用。
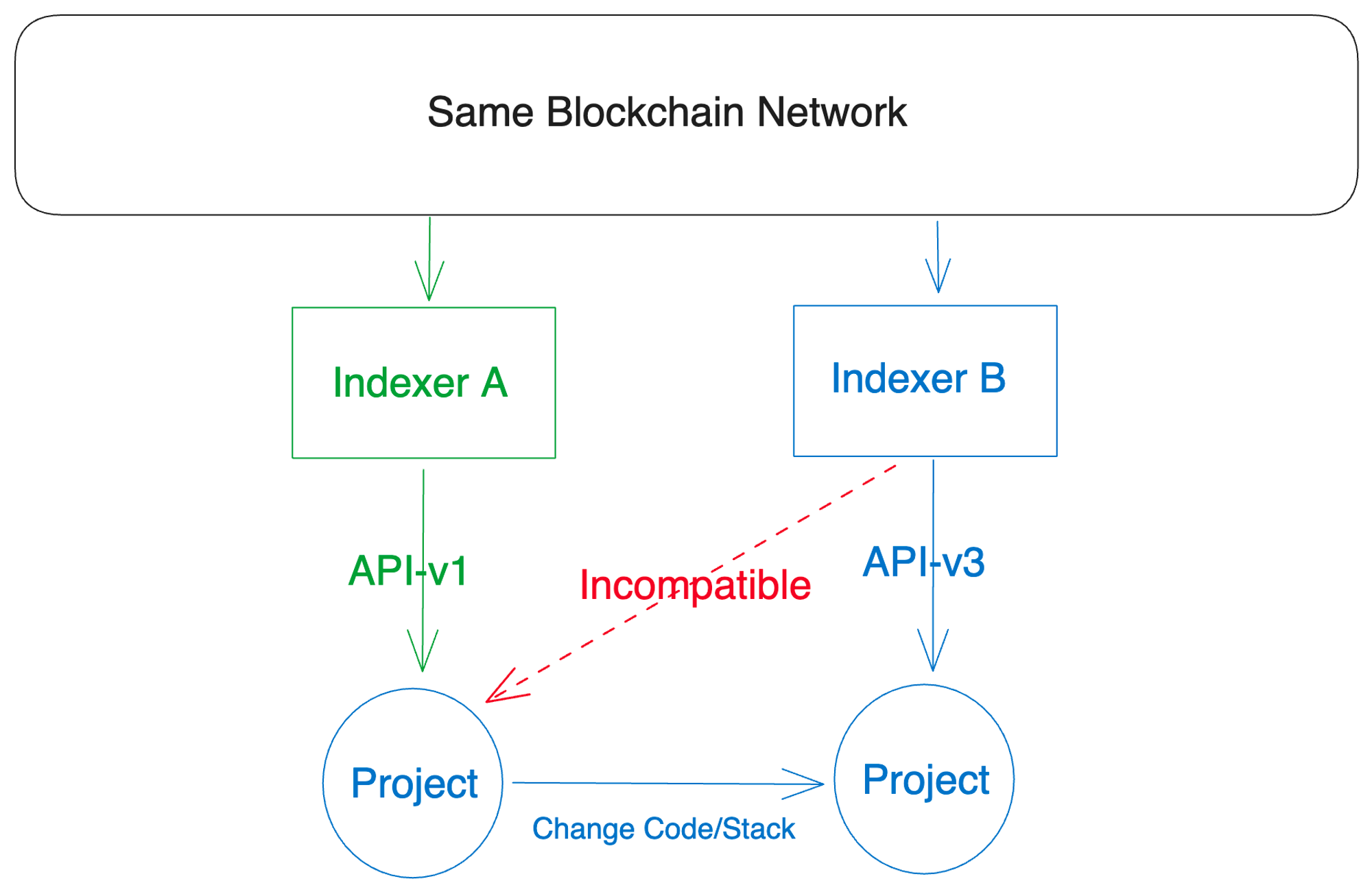
此外,當開發者在這個多鏈世界中探索時,他們經常面臨處理這些不同數據標準的挑戰。一個適用於一個區塊鍊網絡的解決方案可能對另一個區塊鍊網絡無效,這使得開發可以與多個網絡進行交互的應用程序變得困難。
的確,區塊鏈索引行業面臨的挑戰讓人想起了20世紀初開爾文勳爵在物理學中確定的兩個未解決問題,這兩個問題最終催生了量子力學和熱力學等革命性領域。
面對這些挑戰,業界確實採取了一些措施,例如在Kafka管道中引入延遲或集成流式處理,甚至建立一個標準聯盟來加強區塊鏈索引行業。這些措施目前的確能夠解決區塊鍊網絡的不穩定性和數據標準的多樣性,從而使索引器能夠提供準確可靠的數據。
然而,正如量子理論的出現革命了我們對物理世界的理解一樣,我們也可以考慮更激進的方法來改進區塊鏈數據基礎設施。
畢竟,現有的基礎設施,以其井然有序的數據倉庫和堆棧,可能看起來太完美、太美麗以至於讓人難以置信。
那麼,是否存在其他的道路呢?
尋找規律
讓我們回到最初關於節點提供者和索引器出現的話題,並思考一個奇特的問題。為什麼節點運營商沒有在2010年出現,而索引器在2022年突然大量湧現並獲得了大量的投資?
我相信我的上文已經部分回答了這些問題。這是因為雲計算和數據倉庫技術在軟件行業中的廣泛應用,而不僅僅在加密領域。
在加密領域,也發生了一些特別的事情,特別是當ERC20和ERC721標准在公眾媒體上變得流行的時候。此外,DeFi夏季使得鏈上數據變得更加複雜。各種調用交易在不同的智能合約上進行路由,而不再只是早期階段那樣的簡單交易數據,鏈上數據的格式和復雜性都發生了驚人的變化和增長。
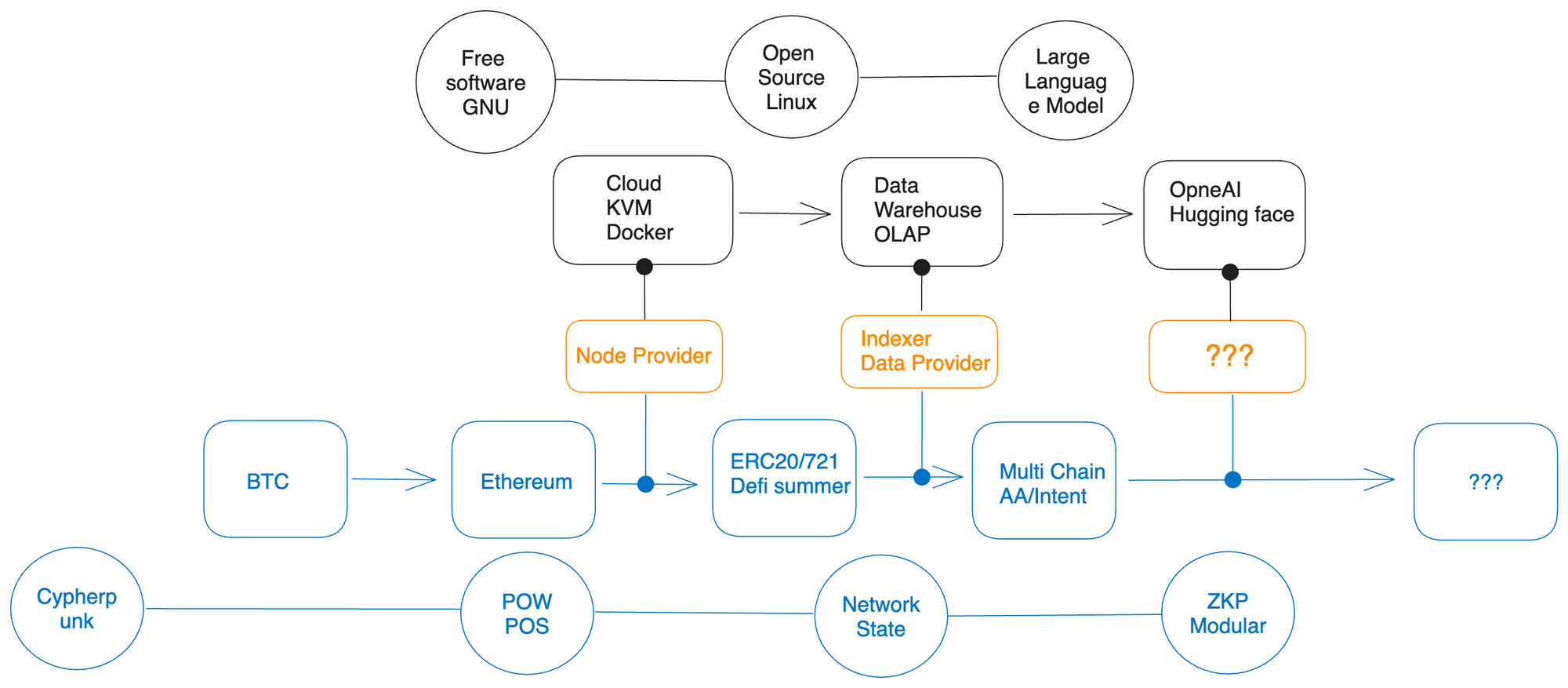
雖然在加密貨幣社區內,一直強調與傳統的Web2技術進行切割,但我們不能忽視的是,加密貨幣基礎設施的發展是依賴於數學、密碼學、雲技術和大數據等領域的不斷發展與突破。類似於中國傳統的榫卯結構,加密貨幣生態系統中的各個組成部分都是緊密相連的。
科技的進步和創新應用總是會受到一些客觀原則的約束。比如,如果沒有橢圓曲線加密技術的基礎支撐,我們今天的加密貨幣生態就無法存在。同樣,如果沒有麻省理工學院在1985年發表的關於零知識證明的重要研究論文,零知識證明的實踐應用也將無法實現。因此,我們看到了一個有趣的模式。 **節點服務提供商的廣泛應用和擴張,正是基於全球雲服務和虛擬化技術的快速增長。 **與此同時,鏈上數據層的發展又是基於出色的開源數據庫架構和服務的蓬勃發展,這些架構正是近年來眾多商業智能產品所依賴的數據解決方案。這都是初創公司為了實現商業可行性而必須滿足的技術前提條件。針對Web3項目來說,那些採用先進基礎設施的項目往往比那些依賴過時架構的項目更具優勢。 OpenSea市場份額被更快速、更加用戶友好的NFT交易所侵蝕,就是一個生動的例證。
此外,我們也可以看到一個明顯的趨勢:人工智能(AI)與LLM技術已經逐漸成熟,並且具有廣泛應用的可能性。
因此,一個重要的問題浮現出來:AI將如何改變鏈上數據的格局?
預測未來
預測未來總是充滿困難的,但我們可以通過理解區塊鏈開發中遇到的問題來探索可能的答案。開發者對鏈上數據有明確的需求:他們需要的是準確、及時,並且易於理解的鏈上數據。
我們目前面臨的一個問題是,批量獲取或是展示某些數據需要使用複雜的SQL查詢。這也是為什麼在加密社區中,Dune提供的開源SQL功能如此受歡迎。用戶無需從頭開始去寫sql構建圖表,只需fork並修改想要關注的智能合約地址,就可以創建他們所需的圖表。然而,對於只希望在特定條件下查看流動性或空投數據的普通用戶來說,這仍然過於復雜。
我認為,解決這個問題的第一步是利用LLM和自然語言處理。
我們可以構建更以用戶為中心的“數據查詢”界面,並利用LLM技術。在現有的情況下,用戶必須使用諸如SQL或GraphQL這樣的複雜查詢語言,從API或Studios中提取相應的鏈上數據。但是,通過使用LLM,我們可以引入一種更直觀、更符合人類習慣的提問方式。在這種方式下,用戶可以用“自然語言”表達他們的問題,然後LLM會將其轉化為合適的查詢,並向用戶提供他們所需的答案。
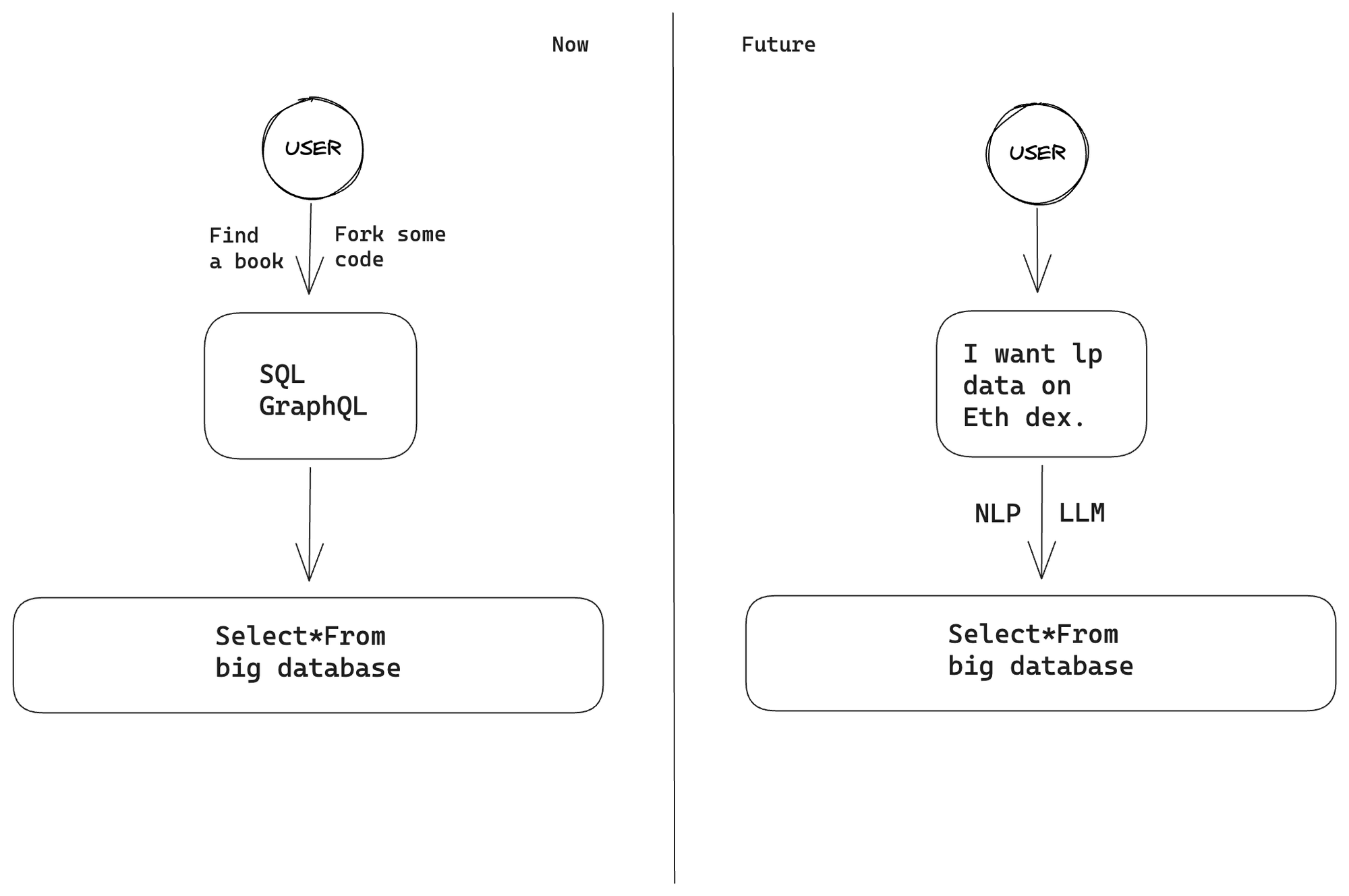
從開發者的視角出發,人工智能還可以優化鏈上合約事件的解析及ABI解碼。目前,許多DeFi合約的細節都需要開發者手動解析和解碼。但若引入人工智能,我們可以顯著改進各類合約反彙編技術,迅速檢索相應的ABI。結合大型語言模型(LLM),這種配置可以智能解析函數簽名並高效處理各種數據類型。進一步地,當該系統與“流計算”處理框架相結合時,就能夠實時處理交易數據的解析,滿足用戶的即時需求。
從更全局的角度看,索引器的目標是為用戶提供精準數據。正如我之前所強調的,鏈上數據層的一個潛在問題是,各個數據片段分散在不同的索引器數據庫中,且相互隔離。為滿足多樣化的數據需求,一些設計者選擇將所有鏈上數據整合到一個數據庫中,使用戶能從單一的數據集中選取所需信息。有些協議則選擇僅包含部分數據,比如DeFi數據和NFT數據。但數據標準不兼容的問題仍然存在。有時,開發者需要從多個來源獲取數據並在自己的數據庫中重新格式化,這無疑增加了他們的維護負擔。此外,一旦某數據提供方出現問題,他們無法及時遷移到另一個提供方。
那麼,LLM和人工智能如何解決這個問題呢? LlamaIndex為我提供了一個啟示。假如開發者不需要索引器,而是利用一個部署的代理服務(agent)直接讀取鏈上的原始數據,那會怎樣?這個agent融合了索引器和LLM的技術。從用戶的角度看,他們不需要了解任何關於API或查詢語言的知識,他們只需要提出問題並即時得到反饋。
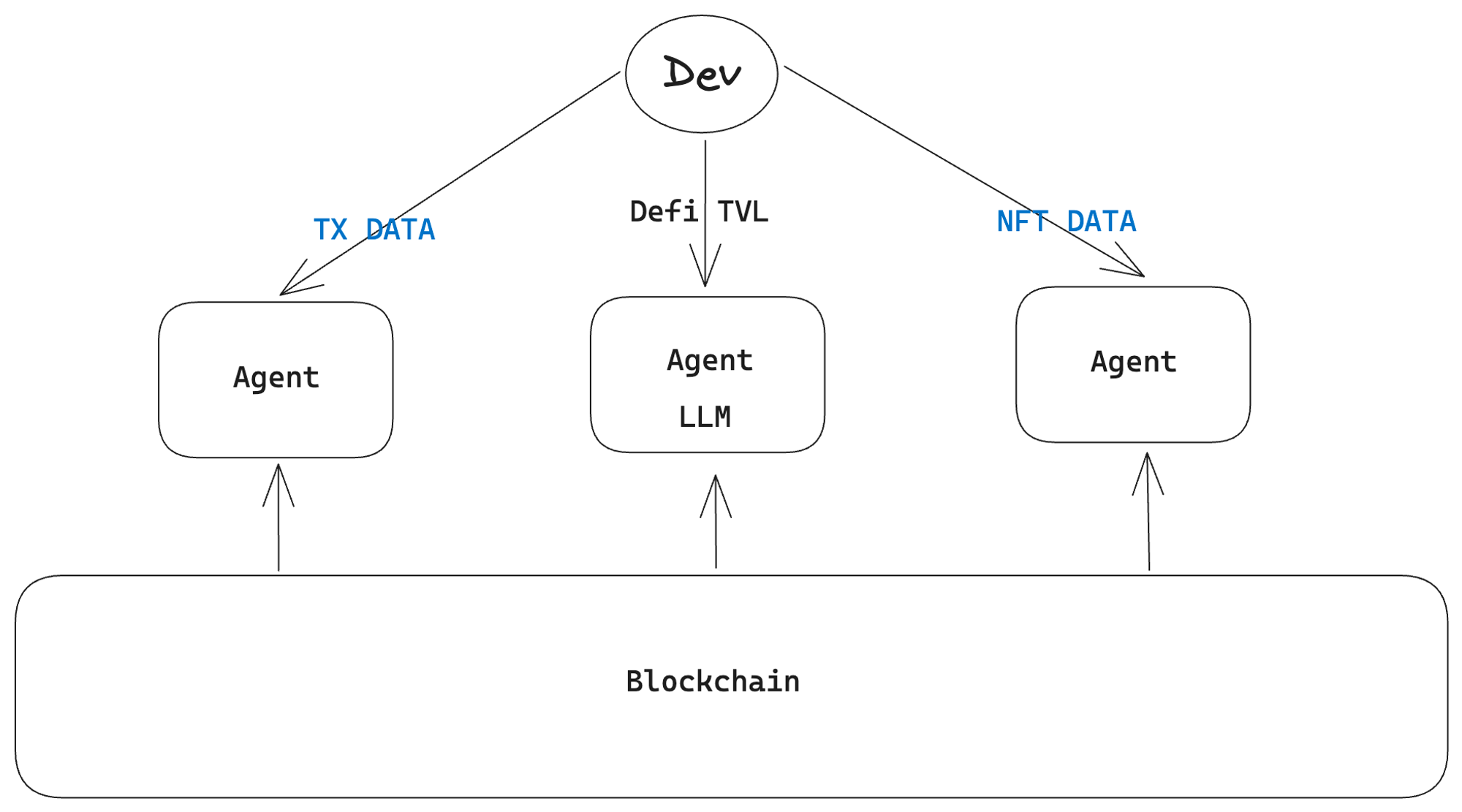
配備了LLM和人工智能技術,Agent能理解並處理原始數據,並將其轉換為用戶易於理解的格式。這消除了用戶面對複雜API或查詢語言的困擾,他們只需以自然語言提出問題,即可獲得實時反饋。這一特性提高了數據的可訪問性和用戶友好度,吸引了更廣泛的用戶群體接觸鏈上數據。
此外,代理服務(Agent)的方式解決了數據標準不兼容的問題。由於設計時已經考慮到它擁有解析和處理原始鏈上數據,它可以適應不同的數據格式和標準。因此,開發者無需從不同來源重新格式化數據,減輕了他們的工作負擔。
當然,這只是對鏈上數據未來發展軌蹟的一種推測。但在科技領域,通常是這些大膽的設想和理論推動了革命性的進步。我們應記住,無論是發明輪子還是區塊鏈的誕生,所有的重大突破都源於某人的假設或”瘋狂”想法。
在我們接受變革和不確定性的同時,我們也被挑戰著不斷拓展可能性的邊界。在這個背景下,我們設想一個世界,人工智能、LLM和區塊鏈的結合將孕育一個更加開放和包容的技術領域。
Chainbase秉承這一願景,並致力於將其實現。
我們在Chainbase的使命是打造一個開放、友好、透明且可持續的加密數據基礎設施。我們的目標是簡化開發者對此類數據的使用,免去複雜的後端技術堆棧重構的必要性。通過這樣的方式,我們希望迎來一個未來,在這個未來中,技術不僅服務於用戶,更賦予他們力量。
然而,我必須澄清,這並不是我們的路線圖。相反,這是我作為開發者關係代表,在社區中對鏈上數據最近發展和進展的個人思考。

