

有關GPT-5的消息最近又火了起來。
從最一開始的爆料,說OpenAI正在秘密訓練GPT-5,到後來Sam Altman澄清;再到後來說需要多少張H100 GPU來訓練GPT-5,DeepMind的CEO Suleyman採訪「實錘」OpenAI正在秘密訓練GPT-5。
然後又是新一輪的猜測。
中間也穿插了Altman的大膽預測,什麼GPT-10會在2030年前出現,超過全人類的智慧總和,是真正的AGI雲雲。
再到最近OpenAI名叫Gobi的多模態模型,強勢叫板谷歌的Gimini模型,兩家巨頭的競爭一觸即發。
一時間,有關大語言模型的最新進展成了圈內最熱門的話題。
套用一句古詩詞,「猶抱琵琶半遮面」來形容,還挺貼切的。就是不知道,什麼時候能真的「千呼萬喚始出來」。
時間軸回顧
今天要聊的內容和GPT-5直接相關,是咱們的老朋友Gary Marcus的一篇分析。
核心觀點就一句話:GPT-4到5,不是光擴大模型規模那麼簡單,是整個AI範式的改變。而從這一點來看,開發出GPT-4的OpenAI並不一定是先到達5的那家公司。
換句話說,當範式需要改變的時候,之前的累積可遷移性不大。
不過在走進Marcus的觀點之前,我們還是簡單複習一下最近有關傳說中的GPT-5都發生什麼事了,輿論場都說了些什麼。
一開始是OpenAI的共同創辦人Karpathy推文表示,H100是巨頭們追捧的熱門,大家都關心這東西誰有,有多少。
然後就是一大波討論,各家公司需要多少張H100 GPU來訓練。

大概就是這樣。
GPT-4可能在大約10000-25000張A100上進行了訓練
Meta大約21000 A100
Tesla大約7000 A100
Stability AI大約5000 A100
Falcon-40B在384個A100上進行了訓練
有關這個,馬斯克也參與了討論,根據馬斯克的說法,GPT-5的訓練可能需要30000到50000個H100。
此前,摩根士丹利也說過類似的預測,不過總體數量要比馬斯克說的少一點,大概是25000個GPU。
當然這波把GPT-5放到檯面上去聊,肯定少不了Sam Altman出來闢謠,表示OpenAI沒在訓練GPT-5.
有大膽的網友猜測,OpenAI之所以否認,很有可能只是把下一代模型的名字給改了,並不叫GPT-5而已。

反正根據Sam Altman的說法,正是因為GPU的數量不足,才讓許多計畫被耽擱了。甚至還表示,不希望太多人使用GPT-4。
整個業界對GPU的渴求都是如此。根據統計,所有科技巨頭所需的GPU加起來,得有個43萬張還要多。這可是一筆天文數字的money,得差不多150億美元。
但透過GPU的用量來倒推GPT-5有點太迂迴了,於是DeepMind的創始人Suleyman直接在訪談中「錘」了,表示OpenAI就是在秘密訓練GPT-5,別藏了。
當然在完整的訪談中,Suleyman還聊了不少業內大八卦,比方說在和OpenAI的競爭中,DeepMind為啥就落後了,明明時間上也沒滯後太多。
還有不少內部消息,像是當時Google收購的時候發生了什麼事。但這些跟GPT-5怎麼著關係就不大了,有興趣的朋友可以去自行了解。
總而言之,這波是業界大佬下場聊GPT-5的最新進展,讓大夥不禁疑雲陡起。
在這之後,Sam Altman在一場一對一連線中又表示,「我覺得2030年之前,AGI要出現,叫GPT-10,超過全人類的智慧總和。」

一方面大膽預測,一方面否認在訓練GPT-5,這讓別人很難真正知道OpenAI在做什麼。
在這場連線中,Altman設想了許多屬於未來的圖像。例如他自己怎麼理解AGI,什麼時候會出現AGI,真出現AGI了OpenAI會怎麼辦,全人類又該怎麼辦。
不過就實際進展來說,Altman是這麼規劃的,「我和公司中的員工說,我們的目標就是每12個月能讓我們的原型產品性能提升10%。」
「如果把這個目標設定到20%可能就會有些過高了。」
這算是具體安排。但10%、20%和GPT-5之間的關聯又在哪,也沒說得很清楚。
最有含金量的還是下面這個-OpenAI的Gobi多模態模型。
重點在於Google和OpenAI之間的白熱化競爭,到了哪個階段。
說Gobi之前,先得說說GPT-vision。這一代模型就很厲害了。拍個草圖照片,直接傳給GPT,網站分分鐘幫你做出來。
寫程式碼那更不用說了。
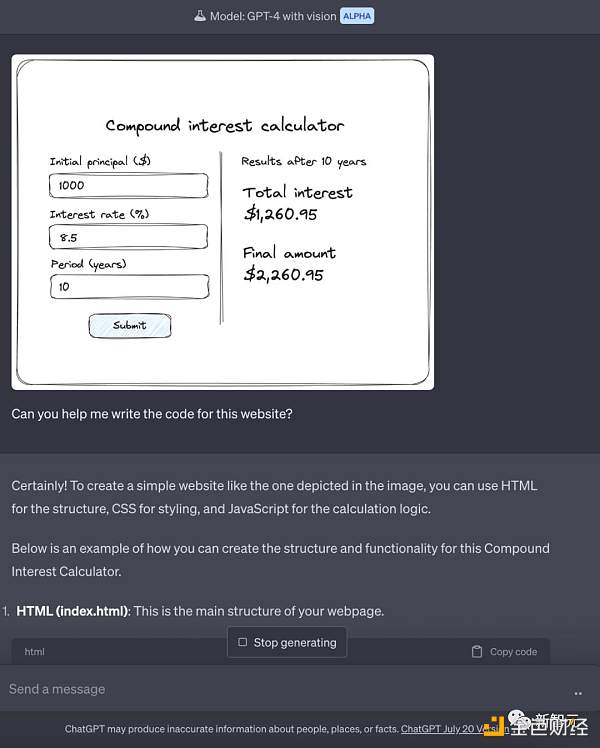
而GPT-vision完了,OpenAI才有可能推出更強大的多模態大模型,代號為Gobi。
跟GPT-4不同,Gobi從一開始就是以多模態模型建構出來的。
這也讓圍觀群眾的興趣一下被勾起來了--Gobi是傳說中的GPT-5嗎?

當然現在我們還不知道Gobi訓練到哪一步了,也沒有確切消息。
而Suleyman還是堅定地認為,Sam Altman最近說過他們沒有訓練GPT-5,可能沒有說實話。
Marcus觀點
開宗明義,Marcus首先表示,很有可能,在科技史上,沒有任何一款預發布的產品(iPhone可能是個例外)比GPT-5被寄予了更多的期望。
這不僅是因為消費者對它的熱捧,也不只是因為一大批企業正計劃著圍繞它白手起家,甚至就連有些外交政策也是圍繞著GPT-5制定的。
此外,GPT-5的問世也可能加劇剛進一步升級的晶片戰爭。
Marcus表示,還有人專門針對GPT-5 的預期規模模型,要求暫停生產。
當然也是有不少人非常樂觀的,有一些人想像,GPT-5可能會消除,或者至少是極大地消除人們對現有模型的許多擔憂,比如它們的不可靠、它們的偏見傾向以及它們傾訴權威性廢話的傾向。
但Marcus認為,自己從來都不清楚,光建立更大的模型是否就能真正解決這些問題。
今天,有國外媒體爆料稱,OpenAI的另一個項目Arrakis,旨在製造更小、更有效率的模型,但由於沒有達到預期目標而被高層取消。
Marcus表示,我們幾乎所有人都認為,GPT-4之後會盡快推出GPT-5,而通常想像中的GPT-5要比GPT-4強大得多,所以Sam當初否認的時候讓大夥大吃一驚。
人們對此有很多猜測,比方說上面提到的GPU的問題,OpenAI手上可能沒有足夠的現金來訓練這些模型(這些模型的訓練成本是出了名的高)。
但話又說回來了,OpenAI的資金充裕程度幾乎不亞於任何一家新創公司。對於一家剛融資100億美元的公司來說,即使進行5億美元的訓練也不是不可能。
另一種說法是,OpenAI 意識到,無論是訓練模型還是運行模型,成本都將非常高昂,而且他們不確定是否能在這些成本下獲利。
這麼說好像有點道理。
第三種說法,也是Marcus的看法是,在Altman上半年5月演講的時候,OpenAI就已經進行過一些概念驗證方面的測試了,但他們對得到的結果並不滿意。
最後他們的結論可能是這樣:如果GPT-5只是GPT-4的放大版而已的話,那麼它將無法滿足預期,和預設的目標差的還遠。
如果結果只會令人失望甚至像個笑話一樣,那麼訓練GPT-5就不值得花費數億美元。
事實上,LeCun也是這麼個思路。
GPT從4到5,不只是4plus這麼簡單。 4到5應該是劃時代的那種。
這裡需要的是全新的範式,而不是單純擴大模型的規模。
所以說,就範式上的改變來講,當然還是越有錢的公司越有可能達成這個目標。但差別在於,不一定是OpenAI了。因為範式的改變是全新的賽道,過往的經驗或累積不一定能派上多少用場。
同樣,從經濟的角度來講,如果真如Marcus所言,那麼GPT-5的開發就相當於被無限期的延遲了。誰也不知道新技術何時會到來。
就好像,現在新能源車普遍續航幾百公里,想要續航上千,就需要全新的電池技術。而新技術由誰來突破,往往除了經驗、資金外,可能還需要那麼一點運氣,和機緣。
但不管怎麼說,如果Marcus想的是對的,那麼未來有關GPT-5的各種商業價值想必會縮水不少。