
作者:joohhnnn
opstack是如何從Layer1衍生出來Layer2的
在閱讀本文章之前,我強烈建議你先閱讀一下來自optimism/specs中有關派生部分的介紹(source[2]) 如果你看完這篇文章,感到迷茫,這是正常的。但還是請記住這份感覺,因為在看完我們這篇文章的分析之後,請你回過來頭再看一遍,你會發現這篇官方的文章真的很凝練,把所有要點和細節都精煉的闡述了一遍。
接下來讓我們進入文章正題。我們都知道layer2的運行節點是可以從DA層(layer1)取得數據,並且建構出完整的layer2區塊數據的。今天我們就來講解一下這個過程中是如何在codebase中實現的。
你需要有的問題
如果現在讓你設計這樣一套系統,你會怎麼設計呢?你會有哪些問題?這裡我列出來了一些問題,帶著這些問題去思考會幫助你更好的理解整篇文章
-
當你啟動一個新節點的時候,整個系統是如何運作的?
-
你需要一個去查詢所有l1的區塊資料嗎?如何觸發查詢?
-
當拿到l1區塊的數據後,你需要哪些數據?
-
派生過程中,區塊的狀態是怎麼變化的?如何從unsafe變成safe再變成finalized?
-
官方specs中晦澀的資料結構batch/channel/frame 這些到底是乾嘛的? (可以在上一章03-how-batcher-works章節中詳細理解)
什麼是派生(derivation)?
在理解derivation前,我們先來聊聊optimism的基本rollup機制,這裡我們簡單以一筆l2上的transfer交易為例。
當你在optimism網路上發出一筆轉帳交易,這筆交易會被”轉發”給sequencer節點,由sequencer進行排序,然後進行區塊的封裝並進行區塊的廣播,這裡可以理解為出塊。我們把這個包含你交易的區塊稱為區塊A。這時的區塊A狀態為unsafe。接下來等sequencer達到一定的時間間隔了(比如4分鐘),會由sequencer中的batcher的模組把這四分鐘內所有收集到的交易(包括你這筆轉賬交易)通過一筆交易發送到l1上,並由l1產出區塊X。這時的區塊A狀態仍然為unsafe。當任何一個節點執行derivation部分的程式後,此節點從l1中取得區塊X的數據,並對本地l2的unsafe區塊A進行更新。這時的區塊A狀態為safe。在經過l1兩個epoch(64個區塊)後,由l2節點標記為finalized區塊。
而派生就是把角色帶入上述例子的l2節點當中,透過不斷的平行執行derivation程序將獲取的unsafe區塊逐步變成safe區塊,同時把已經是safe的區塊逐步變成finalized狀態的一個過程。
程式碼層深潛
hoho 船長,讓我們深潛?
取得batcher發送的batch transactions的data
讓我們先來看看當我們知道一個新的l1的區塊時,如何查看區塊裡面是否有batch transactions的數據在這裡我們先梳理一下所需要的模組,再針對這些模組進行查看
-
首先要確定下一個l1的區塊區塊號碼是多少
-
將下一個區塊的數據解析出來
確定下一個區塊的區塊號
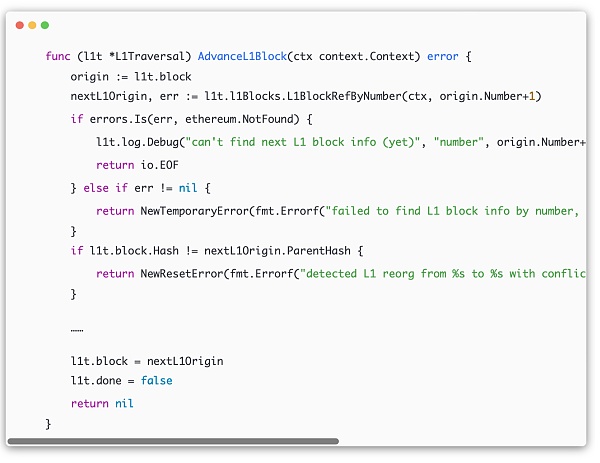
op-node/rollup/derive/l1_traversal.go
透過查詢目前origin.Number + 1的區塊高來取得最新的l1區塊,如果此區塊不存在,即error和ethereum.NotFound匹配,那麼就代表目前區塊高即為最新的區塊,下一個區塊還未在l1上產生。如果獲取成功,將最新的區塊號記錄在l1t.block中
將區塊的data解析出來
op-node/rollup/derive/calldata_source.go
首先先透過InfoAndTxsByHash將剛才取得的區塊的所有transactions拿到,然後將transactions和我們的batcherAddr還有我們的config傳入到DataFromEVMTransactions函數中, 為什麼要傳這些參數呢?因為我們在過濾這些交易的時候,需要確保batcher地址和接收地址的準確性(權威性)。在DataFromEVMTransactions接收這些參數後,透過循環對每個交易進行位址的準確性過濾,找到正確的batch transactions。


從data到safeAttribute,使unsafe的區塊safe化
在這一部分,首先會將上一步我們解析出來的data解析成frame並加入到FrameQueue的frames陣列裡面。然後從frames數組中提取一個frame,並將frame初始化進一個channel並添加到channelbank當中,等待該channel中的frames添加完畢後,從channel中提取batch信息,把batch添加到BatchQueue中,將BatchQueue中的batch加入AttributesQueue中,用來建構safeAttributes,並把enginequeue裡面的safeblcok更新,最後透過ForkchoiceUpdate函式的呼叫來完成EL層safeblock的更新
data -> frame
op-node/rollup/derive/frame_queue.go
此函數透過NextData函數取得上一個步驟的data,然後將此data解析後加入FrameQueue的frames陣列裡面,並傳回在陣列中第一個frame。

frame -> channel
op-node/rollup/derive/channel_bank.go
NextData函數負責從目前channel bank中讀出第一個channel中的raw data並返回,同時負責呼叫NextFrame取得frame並裝載到channel中

channel -> batch
op-node/rollup/derive/channel_in_reader.go
NextBatch函數主要負責將剛才到raw data 解碼成具有batch結構的資料並傳回。其中WriteChannel函數的作用是提供一個函數並賦值給nextBatchFn,這個函數的目的是建立一個讀取器,從讀取器解碼batch結構的資料並回傳。

*注意❗️在這裡NextBatch函數產生的batch並沒有被直接使用,而是先加入了batchQueue當中,再統一管理和使用,並且這裡的NextBatch實際上由op-node/rollup/derive/batch_queue.go 目錄下的func (bq BatchQueue) NextBatch()函數調用
batch -> safeAttributes
補充資訊:1.在layer2區塊中,區塊中的交易中的第一個永遠都是一個錨定交易,可以簡單理解為包含了一些l1的信息,如果這個layer2區塊同時還是epoch中第一個區塊的話,那麼還會包含來自layer1的deposit交易([epoch中第一个区块示例](https://optimistic.etherscan.io/txs?block=110721915])。 2.這裡的batch不能理解為batcher發送的batch交易。例如,我們在這裡將batcher發送的batch交易命名為batchA,而在我們這裡使用和討論的命名為batchB,batchA和batchB的關係為包含關係,即batchA中可能包含非常巨量的交易,這些交易可以構造為batchB,batchBB,batchBBB等。 batchB對應一個layer2中區塊的交易,而batchA對應大量layer2中區塊的交易。
op-node/rollup/derive/attributes_queue.go
-
NextAttributes函數傳入目前l2的safe區塊頭後,將區塊頭和我們上一個步驟取得的batch傳遞到createNextAttributes函數中,建構safeAttributes。
-
createNextAttributes我們要注意的是,createNextAttributes函數內部呼叫的PreparePayloadAttributes函數,PreparePayloadAttributes函數主要負責,錨定交易和deposit交易的。最後再把batch的交易和PreparePayloadAttributes函數回傳的交易拼接起來後返回
createNextAttributes函數在內部呼叫PreparePayloadAttributes
func (aq *AttributesQueue) NextAttributes(ctx context.Context, l2SafeHead eth.L2BlockRef) (*eth.PayloadAttributes, error) {
// Get a batch if we need it
if aq.batch == nil {
batch, err := aq.prev.NextBatch(ctx, l2SafeHead)
if err != nil {
return nil, err
}
aq.batch = batch
}
// Actually generate the next attributes
if attrs, err := aq.createNextAttributes(ctx, aq.batch, l2SafeHead); err != nil {
return nil, err
} else {
// Clear out the local state once we will succeed
aq.batch = nil
return attrs, nil
}
}
func (aq *AttributesQueue) createNextAttributes(ctx context.Context, batch *BatchData, l2SafeHead eth.L2BlockRef) (*eth.PayloadAttributes, error) {
……
attrs, err := aq.builder.PreparePayloadAttributes(fetchCtx, l2SafeHead, batch.Epoch())
……
return attrs, nil
}
func (aq *AttributesQueue) createNextAttributes(ctx context.Context, batch *BatchData, l2SafeHead eth.L2BlockRef) (*eth.PayloadAttributes, error) {
// sanity check parent hash
if batch.ParentHash != l2SafeHead.Hash {
return nil, NewResetError(fmt.Errorf(“valid batch has bad parent hash %s, expected %s”, batch.ParentHash, l2SafeHead.Hash))
}
// sanity check timestamp
if expected := l2SafeHead.Time + aq.config.BlockTime; expected != batch.Timestamp {
return nil, NewResetError(fmt.Errorf(“valid batch has bad timestamp %d, expected %d”, batch.Timestamp, expected))
}
fetchCtx, cancel := context.WithTimeout(ctx, 20*time.Second)
defer cancel()
attrs, err := aq.builder.PreparePayloadAttributes(fetchCtx, l2SafeHead, batch.Epoch())
if err != nil {
return nil, err
}
// we are verifying, not sequencing, we’ve got all transactions and do not pull from the tx-pool
// (that would make the block derivation non-deterministic)
attrs.NoTxPool = true
attrs.Transactions = append(attrs.Transactions, batch.Transactions…)
aq.log.Info(“generated attributes in payload queue”, “txs”, len(attrs.Transactions), “timestamp”, batch.Timestamp)
return attrs, nil
}
safeAttributes -> safe block
在這一步,會先engine queue中的safehead設定為safe,但這並不代表這個區塊是safe的了,還必須透過ForkchoiceUpdat在EL中更新
op-node/rollup/derive/engine_queue.go
tryNextSafeAttributes函數在內部判斷是否當前safehead和unsafehead的關係,如果一切正常,則觸發consolidateNextSafeAttributes函數來把engine queue中的safeHead 設置為我們上一步拿到的safeAttributes構造出來的safe區塊,並將繼needForktruechoiceUpdate ,觸發後續的ForkchoiceUpdate來把EL中的區塊狀態改成safe而真正將unsafe區塊轉化成safe區塊。最後的postProcessSafeL2函數是將safehead加入finalizedL1佇列中,以供後續finalied使用。
func (eq *EngineQueue) tryNextSafeAttributes(ctx context.Context) error {
……
if eq.safeHead.Number < eq.unsafeHead.Number {
return eq.consolidateNextSafeAttributes(ctx)
}
……
}
func (eq *EngineQueue) consolidateNextSafeAttributes(ctx context.Context) error {
……
payload, err := eq.engine.PayloadByNumber(ctx, eq.safeHead.Number+1)
……
ref, err := PayloadToBlockRef(payload, &eq.cfg.Genesis)
……
eq.safeHead = ref
eq.needForkchoiceUpdate = true
eq.postProcessSafeL2()
……
return nil
}
將safe區塊finalized化
safe區塊並不是真的牢固安全的區塊,他還需要進一步的最終化確定,即finalized化。當一個區塊的狀態轉變為safe時,從此區塊派生的來源L1(batcher transaction)開始計算,經過兩個L1 epoch(64個區塊後,此safe區塊可以被更新成finalzied狀態。
op-node/rollup/derive/engine_queue.go
tryFinalizePastL2Blocks函數在內部對finalized佇列中區塊進行64個區塊的校驗,如果透過校驗,呼叫tryFinalizeL2來完成engine queue當中finalized的設定和標記needForkchoiceUpdate的更新。
func (eq *EngineQueue) tryFinalizePastL2Blocks(ctx context.Context) error {
……
eq.log.Info(“processing L1 finality information”, “l1_finalized”, eq.finalizedL1, “l1_origin”, eq.origin, “previous”, eq.triedFinalizeAt) //const finalityDelay untyped int = 64
// Sanity check we are indeed on the finalizing chain, and not stuck on something else.
// We assume that the block-by-number query is consistent with the previously received finalized chain signal
ref, err := eq.l1Fetcher.L1BlockRefByNumber(ctx, eq.origin.Number)
if err != nil {
return NewTemporaryError(fmt.Errorf(“failed to check if on finalizing L1 chain: %w”, err))
}
if ref.Hash != eq.origin.Hash {
return NewResetError(fmt.Errorf(“need to reset, we are on %s, not on the finalizing L1 chain %s (towards %s)”, eq.origin, ref, eq.finalizedL1))
}
eq.tryFinalizeL2()
return nil
}
func (eq *EngineQueue) tryFinalizeL2() {
if eq.finalizedL1 == (eth.L1BlockRef{}) {
return // if no L1 information is finalized yet, then skip this
}
eq.triedFinalizeAt = eq.origin
// default to keep the same finalized block
finalizedL2 := eq.finalized
// go through the latest inclusion data, and find the last L2 block that was derived from a finalized L1 block
for _, fd := range eq.finalityData {
if fd.L2Block.Number > finalizedL2.Number && fd.L1Block.Number <= eq.finalizedL1.Number {
finalizedL2 = fd.L2Block
eq.needForkchoiceUpdate = true
}
}
eq.finalized = finalizedL2
eq.metrics.RecordL2Ref(“l2_finalized”, finalizedL2)
}
循環觸發
在op-node/rollup/driver/state.go中的eventLoop函式中負責觸發整個循環過程中的執行入口。主要是間接執行了op-node/rollup/derive/engine_queue.go中Step函數
func (eq *EngineQueue) Step(ctx context.Context) error {
if eq.needForkchoiceUpdate {
return eq.tryUpdateEngine(ctx)
}
// Trying unsafe payload should be done before safe attributes
// It allows the unsafe head can move forward while the long-range consolidation is in progress.
if eq.unsafePayloads.Len() > 0 {
if err := eq.tryNextUnsafePayload(ctx); err != io.EOF {
return err
}
// EOF error means we can’t process the next unsafe payload. Then we should process next safe attributes.
}
if eq.isEngineSyncing() {
// Make pipeline first focus to sync unsafe blocks to engineSyncTarget
return EngineP2PSyncing
}
if eq.safeAttributes != nil {
return eq.tryNextSafeAttributes(ctx)
}
outOfData := false
newOrigin := eq.prev.Origin()
// 檢查 if the L2 unsafe head origin is consistent with the new origin
if err := eq.verifyNewL1Origin(ctx, newOrigin); err != nil {
return err
}
eq.origin = newOrigin
eq.postProcessSafeL2() // make sure we track the last L2 safe head for every new L1 block
// try to finalize the L2 blocks we have synced so far (no-op if L1 finality is behind)
if err := eq.tryFinalizePastL2Blocks(ctx); err != nil {
return err
}
if next, err := eq.prev.NextAttributes(ctx, eq.safeHead); err == io.EOF {
outOfData = true
} else if err != nil {
return err
} else {
eq.safeAttributes = &attributesWithParent{
attributes: next,
parent: eq.safeHead,
}
eq.log.Debug(“Adding next safe attributes”, “safe_head”, eq.safeHead, “next”, next)
return NotEnoughData
}
if outOfData {
return io.EOF
} else {
return nil
}
}
總結
整個derivation功能看似非常複雜,但是你如果將每個環節都拆解開的話,還是能夠很好的掌握理解的,官方的那篇specs不好理解的原因在於,他的batch,frame,channel等概念很容易讓人迷茫,因此,如果你在看完這篇文章後,仍然覺得還很迷惑,建議可以回過頭去再看看我們的03-how-batcher-works。
參考資料
[1]
joohhnnn: https://learnblockchain.cn/people/4858
[2]
source: https://github.com/ethereum-optimism/optimism/blob/develop/specs/derivation.md#deriving-payload-attributes
[3]
第一章: https://learnblockchain.cn/article/6589
[4]
第二章: https://learnblockchain.cn/article/6755
[5]
第三章: https://learnblockchain.cn/article/6756
[6]
第四章: https://learnblockchain.cn/article/6757
[7]
第五章: https://learnblockchain.cn/article/6758