

以太坊基金會研究員Dankrad Feist曾在一則推文中表示,不使用以太坊獲得數據可用性就不是L2。如果按照他的說法,那麼許多鏈都要被踢出L2的隊伍,例如Arbitrum Nova、Polygon和Mantle等。
那麼,數據可用性究竟是什麼? L2面臨怎樣的資料可用性問題?為何對於資料可用性層L2有這麼多爭議?本文將聚焦在這幾個問題,試圖揭開資料可用性的神秘面紗。
數據可用性是什麼
簡單來說,數據可用性是指區塊生產者將區塊的所有交易數據都發佈到網路中,以便使驗證者可以進行下載。
如果一個區塊生產者發布了完整數據並使驗證者可以下載,我們就說數據是可用的;如果它隱瞞了一些數據使驗證者無法下載完整數據,我們就說數據是不可用的。
資料可用性與資料可檢索性的區別
通常,我們容易將資料可用性與資料可檢索性混淆,但其實二者大不一樣。
- 數據可用性涉及的是在區塊被生產出來但尚未透過共識添加到區塊鏈時的階段,因此數據可用性並不與歷史數據有關,而是與新發布的數據是否能通過共識有關。
- 資料可檢索性涉及的是資料已經通過共識並永遠儲存在區塊鏈後的階段,即檢索歷史資料的能力。在以太坊中儲存所有歷史資料的節點稱為歸檔節點。
因此,L2BEAT聯合創始人曾在一條長推中表示全節點並沒有義務向我們提供歷史數據,之所以我們能得到,只是因為全節點足夠善良。
同時他也表示資料可用性(Data Availability)一詞會使人對其作用產生誤解,應該將它替換成資料發布(Data Publishing),這種說法也得到了Celestia創始人的讚同。
L2中的數據可用性問題
雖然資料可用性這個概念來自以太坊,但目前我們著重關注的是L2層面的資料可用性。
在L2中排序器(Sequencer)就是區塊生產者,他們要發布足夠的交易資料以便驗證者能夠檢查交易是否有效。 (想了解更多關於排序器(Sequencer)的內容請閱讀洞鑑周刊往期文章《研報|排序器(Sequencer)的原理、現狀及未來》)
但在這過程中面臨兩個問題,一是確保驗證機制安全進行,二是降低發布資料的成本。以下將具體介紹。
確保驗證機制安全進行的問題
我們知道OP Rollup採用詐欺證明的方式來驗證交易的有效性,ZK Rollup則採用有效性證明的方式。
- 對於OP Rollup:如果排序器(Sequencer)沒有發布完整的能重溯區塊的數據,欺詐證明中的挑戰者將無法發起有效挑戰;
- 對於ZK Rollup:雖然有效性證明本身不需要數據可用性,但ZK Rollup作為一個整體仍然需要數據可用性,如果沒有能重溯區塊的數據,那麼用戶將無法知道其餘額,很可能會失去資產。
為了使驗證安全進行,目前的L2排序器(Sequencer)普遍都將L2的狀態資料與交易資料都發佈在安全性較強的以太坊上,依靠以太坊進行結算並獲得資料可用性。
因此,資料可用性層實際上就是L2發布交易資料的地方,目前主流的L2都將以太坊當作資料可用性層。
降低發布數據的成本問題
如今的L2簡單的將資料可用性與結算都發生在以太坊上,雖然有了足夠的安全性,但也承擔著巨大成本。這也是L2面臨的第二個問題,也就是如何降低發布資料的成本。
用戶支付給L2的總Gas主要由L2執行交易發生的Gas和L2向L1提交數據發生的Gas組成,前者費用微乎其微,後者才是用戶費用的大頭,其中為保證數據可用而發布的交易數據佔L2向L1提交資料的主要部分,而驗證交易有效的證明資料只佔一小部分。

因此,要讓L2整體更便宜就得降低發布資料的成本。那麼,該如何降低成本呢?主要有兩種方法:
- 降低L1上發布資料的成本,例如以太坊即將進行的EIP-4844升級,對EIP-4844升級感興趣的小伙伴,可以閱讀洞鑑周刊往前文章《Web3 科普|輕鬆搞懂Layer2 的大利好:EIP-4844》;
- 仿照Rollup將交易執行從L1中剝離,資料可用性也可以從L1中剝離從而降低成本,也就是不使用以太坊作為資料可用性層。
L2對於資料可用性層的爭議
要講L2對於資料可用性層的爭議,還得從模組化區塊鏈說起。模組化區塊鏈就是將整體區塊鏈的各個核心功能進行解耦,形成相對獨立的各個部分,並透過各種專用網路的組合來擴展單一區塊鏈的效能。
雖然對於模組化區塊鏈的分層還有些爭議,但目前普遍被接受的是將模組化區塊鏈分為四層,即執行層(Execution)、結算層(Settlement)、共識層(Consensus)和資料可用性層(Data Availability)。其各模組功能如下圖
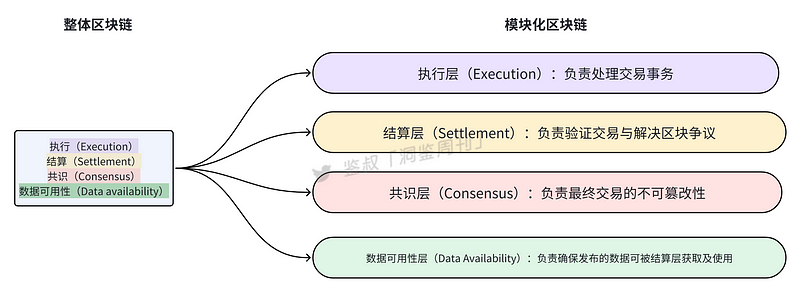
模組化區塊鏈類似於樂高積木,可以透過客製化,使用最好的積木塊搭建了一個良好的模型,緩解了區塊鏈「不可能三角」的問題。
不過,現在的L2除了將執行層從以太坊中分離以外,其他三層的功能仍在以太坊上進行。但出於成本上的考量,許多L2也在準備將資料可用性層從以太坊中剝離,而將以太坊只當作結算層和共識層使用。
有趣的是,以太坊似乎不想讓L2從其他地方獲取數據可用性,以太坊基金會的研究員Dankrad Feist就曾在一條推文中表示不使用以太坊作為數據可用性層就不是Rollup,因此也不是L2。
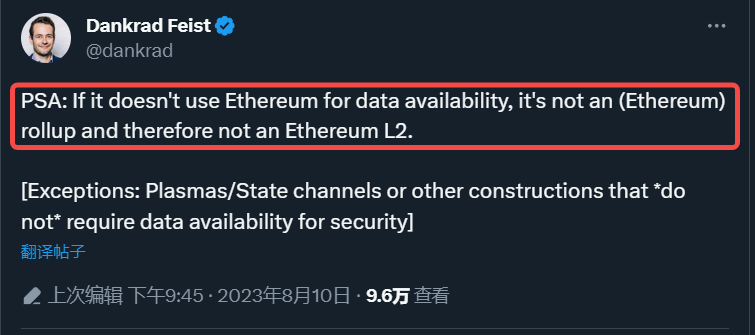
同時,在L2BEAT最新對於L2的定義中也指出不在L1發布資料的擴容方案都不是L2,因為使用鏈下資料可用性解決方案無法保證運營商會提供發佈的資料。

當然具體關於什麼是L2目前還未有蓋棺定論,以上以太坊基金會成員和L2BEAT堅持認為L2要將資料可用性層留在以太坊看似是出於安全性的考量,但實際上是否有對以太坊地位動搖的擔心呢?
以太坊的願景是要成為一個超級電腦平台,後來為了提升網路效能,不得不發展Rollup並使許多生態跑到了更便宜的L2上發展,但因為安全性由以太坊提供,對以太坊的地位並未有太大影響。但如果L2將涉及資料發布的資料可用性層也剝離了以太坊,本質上是削弱了對以太坊安全性的依賴,逐漸的遠離了以太坊,這就對以太坊的地位造成了威脅。
不過不管怎樣,也依然阻擋不了數據可用性層相關項目的蓬勃發展。在下一篇關於數據可用性的文章中,筆者將詳細介紹目前市面上主要的數據可用性解決方案及具體的相關項目,敬請期待。
