
編譯:劉教鏈
教鏈按:本篇是譯自Harold Christopher Burger 及Peter Vijn 合作的論文《比特幣的時間冪律模型及其共整合再探討》(Bitcoin’s time-based power-law and cointegration revisited, 2024.1.31) ,理論性較強,適合有一定統計學基礎的讀者閱讀。為了方便基礎不夠的讀者理解,教鏈先做一些簡單的詮釋。
關於所謂的時間冪律模型,教鏈在過去數目曾寫過多篇文章介紹。
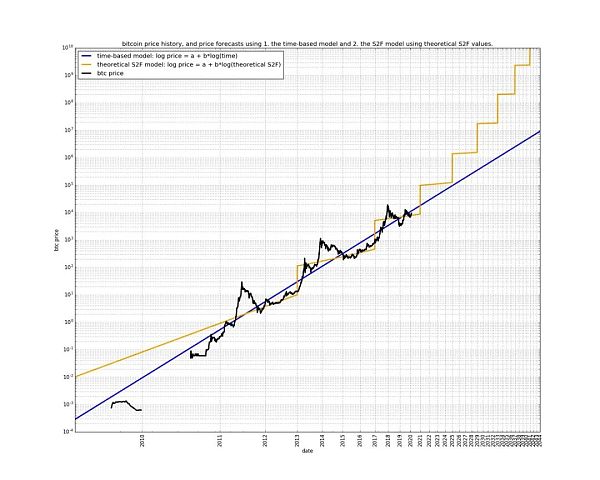
業界有一位比較知名的匿名分析師PlanB一直比較推崇用S2F硬度來和價格進行建模,這就是所謂的S2F模型。不過很可惜:S2F模型是錯的。但請注意,這不代表S2F這個指標沒有意義,只是說,S2F硬度的變化,與價格的關係,不像PlanB所描繪的那樣「激進」。
下面這張圖就很清楚地展示了冪律模型和S2F模型的相對關係:
顯然,S2F模型認為時間線性流逝就可以推動物價的指數成長,而冪律模型則認為時間的指數流逝才能推動物價的指數成長。
教鏈傾向於使用S2F硬度來形象化產量減半所導致的“相變”,但使用冪律模型把比特幣變換到雙對數空間中進行線性回歸。冪律模型的優雅特別有支持向量機(SVM)的神韻,所以甚合我意。
下面,就是H. Burger & P. Vijn 的論文。 Enjoy!
* * *
導言
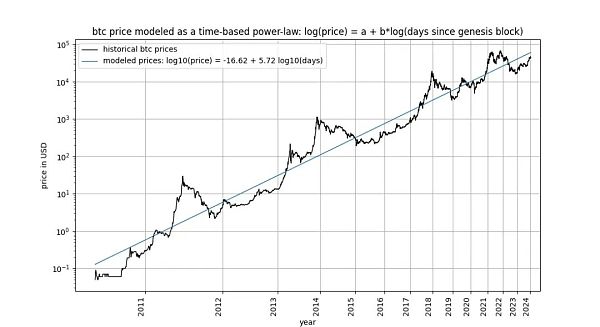
比特幣基於時間的冪律,最初由Giovanni Santostasi 於2014 年提出,我們於2019 年重新表述(作為走廊或三參數模型),描述了比特幣價格與時間之間的關係。具體來說,該模型描述了比特幣創世區塊之後的天數對數與比特幣美元價格對數之間的線性關係。
該模型吸引了包括Marcel Burger、Tim Stolte 和Nick Emblow 在內的多位批評家,他們各自撰文對該模型進行了”反駁”。在本文中,我們將逐一剖析這三個批評中的一個關鍵論點:時間與價格之間不存在協整性(cointegration)的說法,認為該模型”無效”,只是表明了一種虛假的關係。
真的是這樣嗎?
在本文中,我們將對這個問題進行深入研究。這使我們認定,嚴格來說,協整不可能存在於時間相關模型中,包括我們自己的模型。然而,不可否認的是,協整所必需的統計屬性之一在基於時間的冪律模型中是存在的。因此,我們得出結論認為,基於時間的冪律模型在狹義上是協整的,我們的批評是錯誤的,該模型是完全有效的。我們證明,這個結論同樣適用於「存量增量比」(S2F)模型,以及在長期股票市場指數價格中觀察到的指數成長。
概念入門
啥是協整性
你已經迷失方向了嗎?也許你對「協整性」一詞並不熟悉?別擔心:因果推論和非虛假關係領域的專家、《為什麼之書》的作者Judea Pearl 聲稱自己對這個問題一無所知。我們將努力充分闡明手頭上的相關術語。
在推特上比特幣相關主題討論中,關於協整性的爭論非常有趣,而且相當引人入勝。許多「存量增量比」和「冪律」的追隨者都感到困惑。有興趣的讀者可以透過搜尋「什麼是協整」來親眼目睹這一點。隨著時間的推移,一些貢獻者似乎已經掌握並完善了他們的理解,而另一些貢獻者則仍然感到困惑、轉換陣營或迷失方向。直到現在,我們才開始關注這個主題。
先了解一些背景狀況
隨機過程涉及隨機變數。隨機變數的值不是預先決定的。與此相反,確定性過程可以提前精確預測—— 它的方方面面都是事先已知的。股票市場價格等屬於隨機變量,因為我們無法提前預測資產的價格。因此,我們將股票或比特幣價格等時間序列視為隨機變數的觀測值。
相反,時間的流逝遵循確定性模式。每秒鐘都有一秒鐘過去,不存在任何不確定性。因此,事件發生後的持續時間是一個確定變數。
一個訊號的固定性
在研究協整之前,我們先來看看協整的基礎概念:平穩性(stationary):
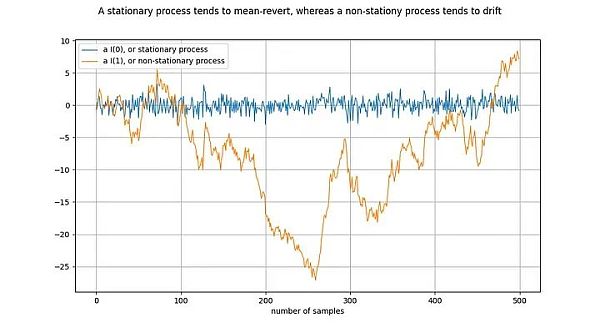
圖釋:將橘線差分一次,就得到了藍線。對I(1)時間序列差分一次,就得到了I(0)時間序列。
平穩過程(stationary process)是一種隨機過程(stochastic process),從廣義上講,它在一段時間內具有相同的性質。例如,對於平穩過程來說,其平均值和變異數是確定和穩定的。靜止時間序列的同義詞是I(0)。源自於平穩過程的時間序列不應該「漂移」(drift),而應該趨向於平均值,通常是零值。
非平穩過程的一個例子是隨機漫步,例如物理學中的布朗運動或粒子擴散:隨機漫步中的每個新值都取決於前一個值加上一個隨機數。非平穩過程的屬性(如平均值和變異數)會隨時間而改變,或沒有定義。非平穩過程為I(1)或更高,但通常為I(1)。源自非平穩過程的時間序列會隨著時間的推移而“漂移”,即傾向於偏離任何固定值。
符號I(1) 指的是一個時間序列需要「差分」(differenced)多少次才能達到靜態。差分是指求取時間序列中的值與其前值之間的差值。這大致相當於求導數。平穩時間序列已經是平穩的- 它需要經過0 次差分變成平穩的,因此它是I(0)。 I(1)時間序列需要經過一次差分才能達到平穩。
上圖的繪製方式是,透過對橘色時間序列進行一次差分,得到藍色時間序列。等價地,橘色時間序列是透過對藍色時間序列進行積分而得到的。
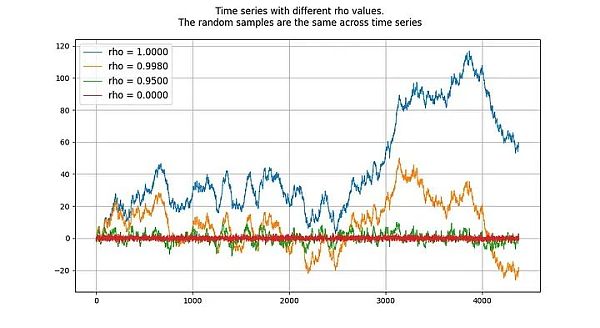
單位根過程(unit root process)指的是自回歸模型(autoregressive models)(更準確地說是AR(1) 類型),其rho 參數被估計為等於1。雖然我們可以交替使用rho 和根,但rho 指的是過程的真實值,而這個值通常是未知的,需要進行估計。估計結果就是「根」值。
rho 的值表示進程對先前值的記憶程度。 u 的值指的是誤差項,假定為白噪音。
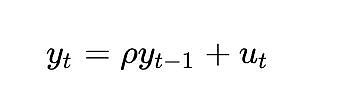
單位根過程是隨機遊走過程,屬於非平穩過程。 「根」或rho 值低於1 的過程往往不會漂移,因此是平穩的。即使是接近(但低於)1 的值,從長期來看也傾向於均值回歸(而不是漂移)。因此,單位根過程的特殊性在於它與根值非常接近1 的過程有著本質上的差異。
兩個訊號的協整
兩個隨機變數(本例為時間序列)之間存在或不存在協整性(協整關係)。要使這對變數具有協整關係,兩者必須具有相同的積分階次,並且都是非平穩的。此外(這是關鍵部分),兩個時間序列的線性組合必須是平穩的。
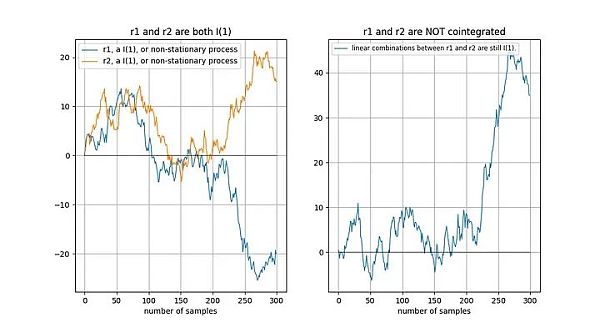
無協整訊號範例
如果兩個時間序列是非平穩的,那麼線性組合(在這種情況下,我們只需選擇兩個時間序列的差值)通常也是非平穩的:
協整訊號範例
如果兩個非平穩時間序列在長期內「以同樣的方式」漂移,那麼線性組合(這裡我們選擇r2-0.5*r1)可能是平穩的:
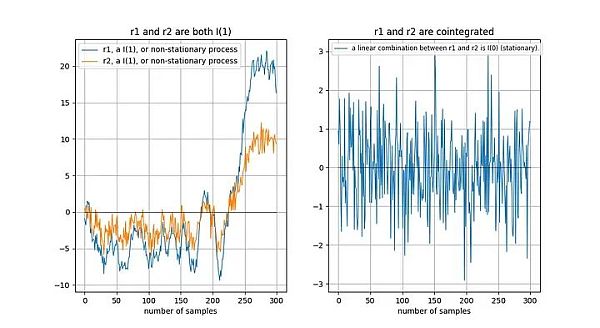
Tu 等人[1]直觀地描述了協整關係:
“時間序列之間存在協整關係意味著它們在長期內具有共同的隨機漂移”。
為什麼兩個非平穩時間序列的線性組合是平穩的?假設我們有兩個時間序列x 和y,我們試著根據x 建立y 模型:y = a + b*x。我們的模型誤差由x 和y 的線性組合給出:模型誤差error = y – a – b*x 。我們希望模型誤差是平穩的,即不會長期漂移。如果模型誤差長期漂移,那就代表我們的模型不好,不能做出準確的預測。
細節是魔鬼(細節決定成敗)
在Engle 和Granger [2](Granger 是協整概念的發明者,曾獲2003 年諾貝爾經濟學獎)的《協整與誤差修正:表示、估計和檢驗》一文中,定義了協整的關鍵概念和檢驗方法。論文的關鍵是假設時間序列是隨機的,沒有確定性成分(我們稍後再談)。

如果存在確定性趨勢,則應在分析前將其移除:

應用於時間和比特幣價格
在基於時間的冪律中,我們有兩個變數:
1. log_time:創世區塊之後天數的對數
2. log_price:價格的對數
根據Engle 和Granger 的定義,兩個變數都必須是隨機變量,沒有確定性成分,而且必須是非平穩的。此外,我們必須能夠找到這兩個變數的靜態線性組合。否則,這兩個變數之間就不存在協整關係。
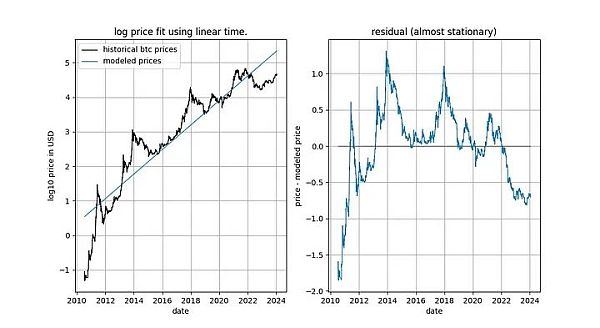
在深入探討細節之前,讓我們先展示幾張模型資料本身的圖表,其中不包含任何平穩或共整合概念。請注意,基於時間的冪律所產生的擬合效果直觀看來相當不錯。殘差向量(residuals vector)並沒有立即顯示漂移。
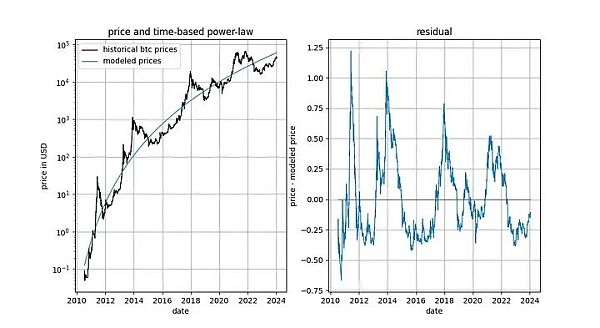
此外,該模型還顯示出卓越的樣本外性能(見下文)。出色的樣本外表現並不意味著該模型是虛假的—— 基於虛假相關性的模型應該只是虛假的,即無法準確預測。檢驗樣本外表現的方法是在有限的資料量(截至某個日期)上擬合模型,並對模型未擬合的時間段進行預測(類似於交叉驗證)。在樣本外期間,觀察到的價格經常與建模價格交叉,觀察到的價格的最大偏離也沒有系統性地進一步遠離建模價格。
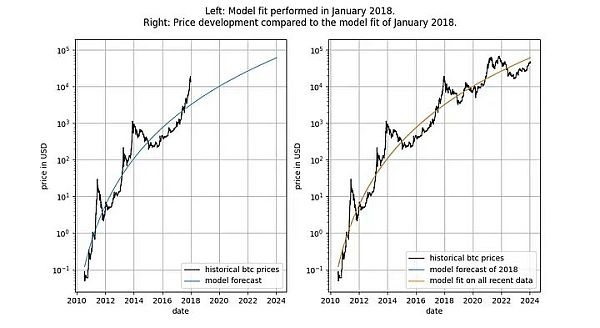
我們可以更加嚴格,觀察模型發布之後(2019 年9 月)的表現,因為模型發布後,我們不可能有任何作弊行為—— 我們不能事後更改模型。
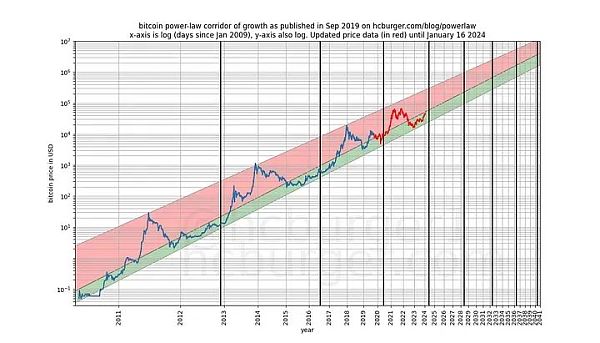
如果有人指責模型只是基於一種虛假的相關性,那麼模型的預測能力應該已經讓人感到懷疑了。
逐步實現協整
要讓log_time 和log_price 之間可能存在協整關係,這兩個變數必須是同階隨機變量,且至少是1 階隨機變數。
log_price 變數
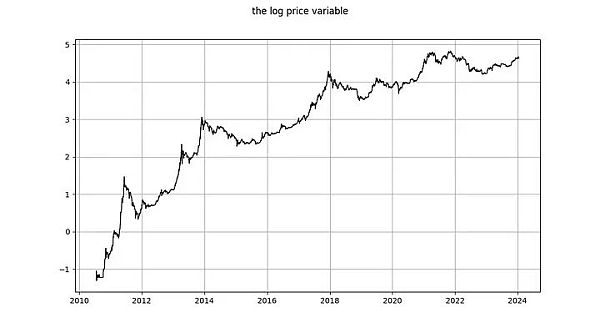
log_price 是平穩時間序列嗎? Nick 使用未指定類型的ADF 檢定(非平穩性檢定)和KPSS 檢定(平穩性檢定)得出結論,log(price) 毫無疑問是非平穩的,因此是I(1)或更高。 Marcel Burger 透過目測得出結論,它是I(1)。 Tim Stolte 提出了一個更有趣的觀察:他對不同時期進行了ADF 檢定(未指定類型),並指出情況並非一目了然:「因此,我們無法堅定地拒絕非平穩性,並得出log-price 存在非平穩性跡象的結論。”
讓我們自己跑分析。與Tim Stolte 類似,我們將在不同的時間視窗進行ADF 檢定:總是從第一個可用日期開始,每天增加一天(我們使用每日資料)。這樣,我們就能看到ADF 檢定的結果是如何隨時間而改變的。但與Tim 和Nick 不同的是,我們要指定執行哪個版本的ADF 檢定。根據維基百科,DF 和ADF 檢定有三種主要類型:

這三個版本的差異在於它們能夠適應(移除)不同的趨勢。這與Engle 和Granger 要求去除任何確定性趨勢有關—— 這三個版本能夠去除三種簡單的確定性趨勢類型。第一個版本試圖只使用過去的log_price 資料來描述每日的log_price 變化。第二個版本允許使用常數項,其效果是log_price 可以具有線性趨勢(向上或向下)。第三個版本允許二次方(拋物線)成分。
我們不知道Tim 和Nick 運行的是哪個版本,但我們將運行所有三個版本。
我們在ADF 檢定中使用的最大滯後期為1,但使用更長的滯後期不會對我們的結果和結論產生有意義的改變。我們將使用python 的statsmodels.tsa.stattools.adfuller 函數,”maxlag”為1,”regression”參數使用”n”、”c “和”ct”(相當於維基百科上面描述的三種類型)。在下圖中,我們顯示了測試返回的p 值(統計顯著性的衡量標準),p 值越小,表示平穩的可能性越大(通常使用的臨界值為0.05)。
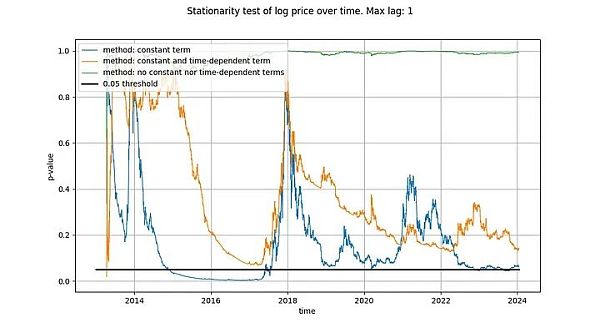
我們注意到,第一種方法(綠線)得出的結論是,log_price 時間序列是非平穩的。第三種檢定方法(橘色線)的結論相同,但不那麼果斷。有趣的是,允許常數項的檢定(藍線)無法判定時間序列是否平穩(很可能Tim 也使用了具有常數項的ADF 檢定)。為什麼這三個版本有如此大的差異,特別是為什麼具有常數項的版本不能排除log_price 是平穩的?
只有一種解釋:在log_price 差分中僅使用常數項(導致log_price 中的線性項)可以「很好地」擬合時間序列,從而產生看起來幾乎是平穩的殘差訊號(儘管起點和終點的偏差相當大)。完全不在log_price 中使用確定性趨勢,或使用二次項確定性效應,效果都遠不如前者。
這已經給了我們一個強烈的暗示,時間與log_price 之間存在著關係。事實上,如果使用常數項進行的ADF 檢定得出的結論是訊號是平穩的,這就意味著線性時間項能夠很好地近似log_price,從而得到平穩的殘差。獲得平穩的殘差是可取的,因為它是非虛假關係的標誌(即我們找到了正確的解釋變數)。線性時間趨勢並不完全符合我們的要求,但我們似乎正在接近它。
我們的結論與Marcel Burger 的結論明顯不同,他(在另一篇文章中)說:
“在先前的分析中,我表明比特幣的價格是一階整合的,這一點仍然有效。比特幣在價格隨時間演變的過程中並沒有表現出任何確定性因素。”
我們的結論是,線性時間並不能充分解釋比特幣的價格隨時間變化的行為,但log_price 有一個確定的時間因素是絕對清楚的。此外,在去除適當的確定性成分後(如Engle 和Granger 所要求的),也不清楚log_price 是否為I(1)。相反,它似乎是趨勢平穩的,但仍需找到適當的確定性成分。
如果我們要尋找協整關係,log_price 不是I(1)就已經是個問題了,因為要讓兩個變數協整,它們必須都是I(1)或更高。
log_time 變數
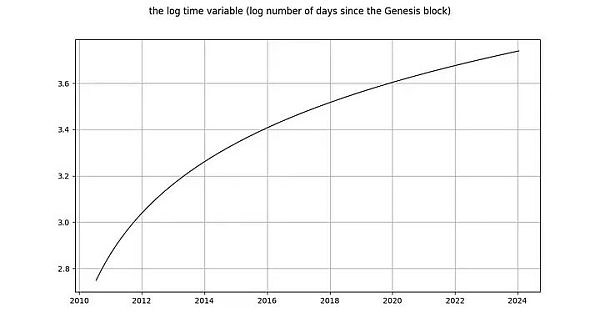
現在讓我們來看看log_time 變數。 Marcel Burger 的結論是,log_time 似乎進行了6 階積分(他一直在進行差分,直到他遇到數值問題)。他期望像對數這樣的數學函數能從一個完全確定的變數轉換為一個隨機變量,這種做法是毫無道理的。
Nick 對log_time 的結論與對log_price 變數的結論相同:毫無疑問,它是非平穩的,因此I(1) 或更高。 Tim Stolte 聲稱log_time 在構造上是非平穩的。這些說法都令人吃驚!積分階次和協整是指隨機變數的概念,其中任何確定性趨勢都已被剔除(見上文Engle 和Granger [2])。需要提醒的是:確定性變數的值是預先知道的,而隨機變數的值是不知道的。時間(顯然)是完全確定的,對數函數也是完全確定的,因此log_time 也是完全確定的。
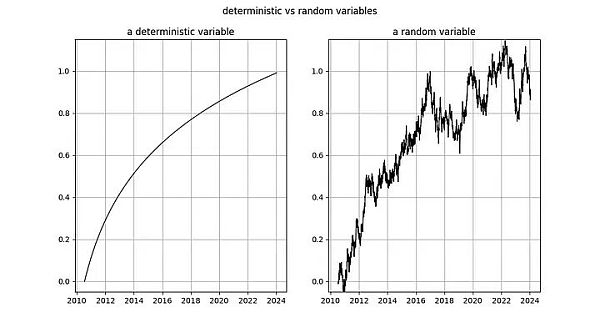
圖釋:左圖:自創世區塊之後的天數的對數是完全確定性的。右圖:隨機變數(看起來有點像左邊的確定性變數)。
如果我們按照Engle 和Granger 的方法,從log_time 中移除確定性趨勢,那麼剩下的就是一個零向量,因為log(x) – log(x) = 0,也就是說,我們仍然有一個完全確定的信號。這意味著我們陷入了困境—— 我們無法將log_time 這個完全確定的變量轉換為隨機變量,因此我們無法使用Engle 和Granger 的框架。
要知道完全確定的變數在協整分析中會有多大問題,還有一種方法,那就是考慮Dickey-Fuller 檢定等平穩性檢定如何處理它。讓我們考慮最簡單的情況(其中y 是感興趣的變量,rho 是需要估計的係數,u 是假定為白噪聲的誤差項):
會發生什麼事?誤差項u_{t} 在所有t 值中都是0,因為我們沒有隨機成分- 應該不需要誤差。但由於log_time 是時間的非線性函數,因此rho 的值也必須取決於時間。
對於隨機變數來說,這個模型更有用,因為變數rho 可以捕捉到先前的隨機值在多大程度上被記住了。但如果沒有隨機值,這個模型就沒有意義了。
對於確定性變量,其他類型的檢定也存在相同的問題。
因此,完全確定性變數不屬於協整分析的範疇。或者換一種說法:協整分析不適用於確定性訊號,如果其中一個訊號是確定性的,那麼協整分析就是一種聲稱存在虛假關係的不合時宜的工具。
怎麼解釋
只有兩個變數都是I(d),且d 至少等於1 的情況下,才有共整合關係。我們已經證明log_time 是一個完全確定的變量,不能用於靜態檢定。我們無法判斷log_time 是I(0)、I(1) 還是I(6)。此外,log_price 也不是I(1),而是趨勢平穩的。
log_time 和log_price 之間不存在協整關係,這是否意味著基於時間的冪律在統計上是無效的或虛假的?
當然不是
在任何適當的統計分析中,使用混合來確定變數和趨勢平穩變數都是完全正確的。協整並不像我們的批評者試圖讓人相信的那樣,是統計關係分析的中心點。
因此,協整分析是不可行的。但是,應用於冪律模型的平穩分析可能還有用武之地。讓我們進一步探討這個問題。
我們之所以先對輸入變數進行協整分析,是因為我們希望找到二者的平穩線性組合。將一個確定性變數(log_time)和一個趨勢平穩變數(log_price)進行組合,從而得到一個平穩變量,這根本上是不可能的。因此,與其尋找嚴格意義上的協整關係,我們可以簡單地對殘差進行平穩性檢定(因為殘差只是兩個輸入訊號的線性組合)。如果殘差是平穩的,那麼即使我們沒有嚴格遵循Engle-Granger 協整檢驗,我們也找到了一個平穩的線性組合(這正是協整的目的)。
深入探討
James G. MacKinnon [3] 在他的論文《協整檢定的臨界值》中正是這樣解釋的:如果已經進行了「協整迴歸」(將log_time 與log_price 連結起來的迴歸),那麼協整檢定(Engle-Granger 檢定)與對殘差進行的平穩性檢定(DF 或ADF 檢定)是一回事:

MacKinnon 重複了這個說法:如果連接log_time 和log_price 的參數是先驗已知的,那麼就可以跳過Engle-Granger 協整檢驗,轉而對殘差進行三種常見類型之一的平穩性檢定( DF 或ADF 檢定):
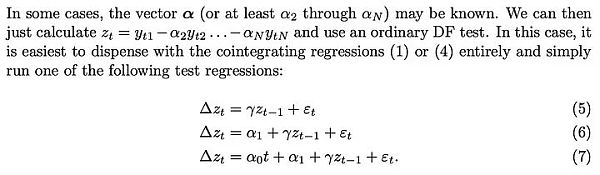
因此,我們可以使用兩種方法中的任何一種,除了得出的檢定統計量之外,這兩種方法是相同的:
1. 將log_time 與log_price 擬合,計算殘差(誤差)。根據殘差計算DF,或者更好的是ADF 檢定。由此得出的統計量可以說明殘差是否平穩。
2. 假設log_time 和log_price 是I(1),並執行Engel-Granger 協整檢定。所得的統計量也能說明殘差是否平穩。
對於ADF 檢驗,我們使用python 的statsmodels.tsa.stattools.adfuller 函數;對於Engle-Granger 檢驗,我們使用statsmodels.tsa.stattools.coint。對於這兩個函數,我們都使用了不使用常數(不隨時間不斷漂移)的方式,因為我們的殘差不應該包含隨時間不斷漂移(因為這意味著隨著時間的推移,模型開始高估或低估價格)。
我們曾寫道,ADF 檢定和Engle-Granger 檢定是等價的,但事實並非如此:它們不會產生相同的檢定統計量。 Engle-Granger 協整檢定假設有N=2 個隨機變量,而ADF 檢定假設有N=1 個隨機變數(N 是自由度的量度)。一個隨機變數可以受另一個隨機變數或一個確定變數的影響,但一個確定變數不能受一個隨機變數的影響。因此,在我們的案例中(只有一個確定變數log_time),ADF 檢定(假定N=1 個隨機變數)傳回的統計量較可取。原則上,Engle-Granger 檢定和ADF 檢定可能存在分歧,但在基於時間的模型中,實際情況並非如此。如下圖所示,結論是一樣的:我們得到了一個平穩的殘差向量。兩種檢定的得分都遠低於0.05 臨界值(顯示殘差是平穩的),而且長期以來一直如此。
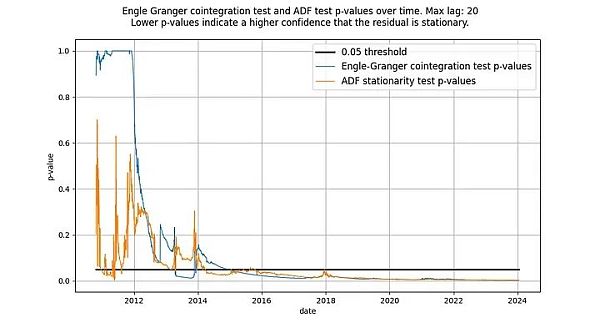
圖釋:根據ADF 和Engle-Granger 檢驗,基於時間的冪律從2016 年左右開始具有平穩的殘差。
兩種檢定最初都沒有顯示出平穩的殘差是正常的。這是因為殘差訊號中的低頻成分會被誤認為是非平穩訊號。只有隨著時間的推移,殘差的平均值迴歸才會變得明顯,實際上是平穩的。
S2F 與長期股指價格
S2F 模型被普遍否定,似乎是因為嚴格意義上的協整被證明是不可能的,其原因與基於時間的冪律相似:輸入變數是(部分)確定的。然而,該模型產生的殘差看起來非常平穩。
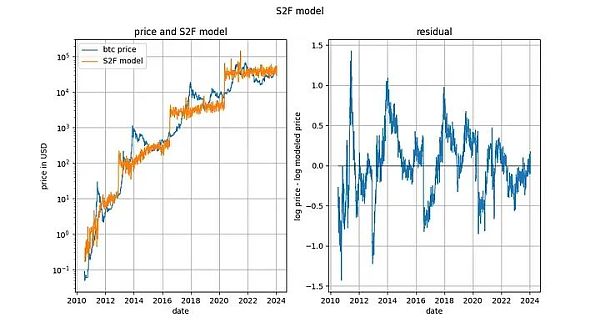
事實上,Engle-Granger 協整檢定和ADF 平穩性檢定(因為有一個確定變量和一個隨機變量,所以更可取)得出的p 值都非常接近0。因此,不應以「缺乏協整性」(實際上是「缺乏平穩性」)為由排除S2F 模型。
然而,我們在2020 年初指出,還有其他跡象顯示S2F 模式不成立。我們預測BTCUSD 的價格將低於S2F 模型的預測,事實證明這項預測是有先見之明的。
觀察長期股價指數與時間的比較也很有趣(這裡為不含紅利再投資的標準普爾500 指數)。眾所周知,主要股票市場指數平均以7% 左右的指數速度成長。事實上,我們透過指數迴歸也證實了這一點。
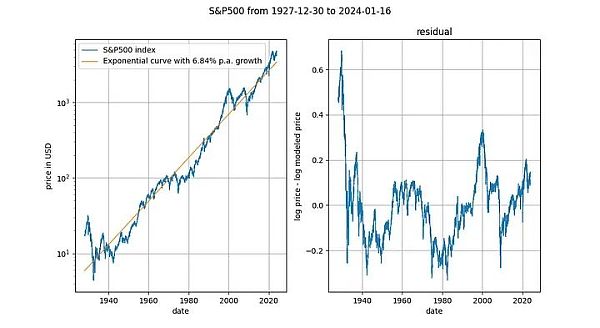
在這裡,我們又遇到了一個確定性變數(時間)。 Engle-Granger 協整檢定得出的p 值約為0.025,ADF 檢定(首選)得出的p 值約為0.0075(但這些值在很大程度上取決於選擇的確切時間段)。再一次,平穩的殘差。股票價格的指數時間趨勢是有效的。
影響
S2F 模型最初受到高度評價(尤其是Marcel Burger 和Nick Emblow),原因是該模型據稱具有良好的計量經濟學基礎,特別是存在協整關係。隨著潮流的轉變,S2F 模型顯然不存在嚴格意義上的協整關係,Marcel 和Nick 都跳船了,宣布S2F 模型無效。似乎在這事件之後,大眾對S2F 模型的看法也改變了。 Eric Wall 對事件的轉折做了一個極好的簡短總結。
我們已經解釋過,而且計量經濟學文獻(MacKinnon [3])也同意我們的觀點,即協整性和平穩性幾乎可以互換使用(統計量的值除外)。根據這個觀點,我們認為S2F 模型在協整性/平穩性方面沒有任何問題,因此,因為所謂缺乏協整性而改變對S2F 模型的看法是錯誤的。我們同意S2F 模型是錯誤的,但其錯誤的原因不在於缺乏協整性。
比特幣的時間冪律模型因缺乏協整性而受到批評,據說這標誌著log_time 和log_price 之間的關係是虛假的。我們已經證明,比特幣基於時間的冪律模型的殘差明顯是平穩的,因此批評者的推理是值得商榷的。
比特幣的時間冪律模型是有效、穩定且強大的。一如既往。
參考文獻
1. “Universal Cointegration and Its Applications” Tu et al., including supplemental information
2. “Co-Integration and Error Correction: Representation, Estimation, and Testing” by Robert F. Engle and CWJ Granger
3. “Critical Values for Cointegration Tests”, James G. MacKinnon
