
前言
Web3如今分化出的兩種主流區塊鏈架構設計已經讓人難免有些美學疲勞,不管是氾濫成災的模組化公鏈還是總強調性能卻體現不出性能優勢的新型L1,其生態可以說都是以太坊生態的複刻或細微改進,同質化極高的體驗早已讓使用者失去新鮮感。而Arweave最新提出的AO協議卻令人眼前一亮,在儲存公鏈上實現超高效能運算甚至達成準Web2的體驗。這與我們目前所熟知的擴容方式和架構設計似乎有著巨大的差別,那麼AO究竟是什麼?支持其性能的邏輯又從何而來?
如何理解AO
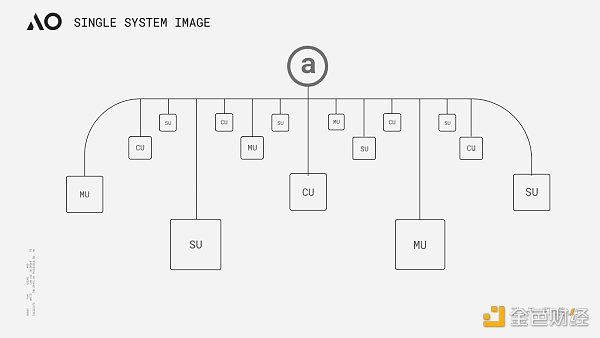
AO的命名來自於並發運算模型Actor Model中一種程式設計範式Actor Oriented的縮寫,其整體設計思路源自於對Smart Weave的延伸,同時也遵循Actor Model以訊息傳遞為核心的概念。簡單來說,我們可以將AO理解為一台透過模組化架構運行在Arweave網路之上的「超並行電腦」。從實作方案來看,AO其實並非我們當下常見的模組化執行層,而是一個規範訊息傳遞與資料處理的通訊協定。該協議的核心目標旨在透過資訊傳遞實現網路內不同「角色」的協作,從而實現一個性能可無限疊加的計算層,最終使得Arweave這塊「巨型硬碟」能夠在去中心化信任環境下擁有中心化雲端等級的速度、可伸縮的運算能力及具備可擴充性。
AO的架構
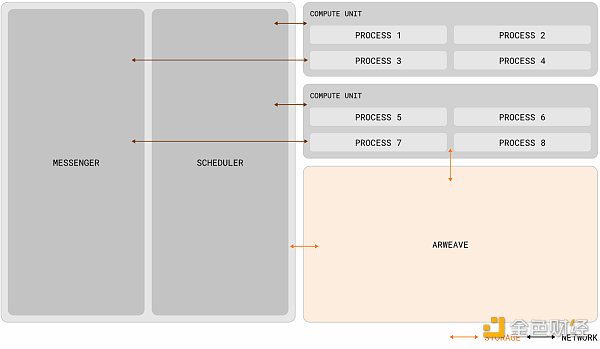
AO的理念看起來與Gavin Wood在去年Polkadot Decoded大會上提出的「Core Time」分割與再組合有些異曲同工之處,兩者都是透過對運算資源的調度與協調,以實現所謂的「高效能世界電腦”.但兩者在本質上其實有一些區別,異構調度(Exotic Scheduling)是對中繼鏈區塊空間資源的解構與重組,對於波卡的架構並沒有太大改變,計算的性能雖然突破了插槽模型下單一平行鏈的限制,上限卻依舊受限於波卡的最高閒置核心數。而AO理論上可以透過節點的水平擴展提供近乎無限的運算能力(在實際情況下應該取決於網路激勵水平)和更高的自由度,從架構上來說,AO規範了資料處理方式和訊息的表達,並透過三個網路單元(子網路)完成資訊的排序、調度與計算,其規範方式與不同單元的職能,據官方資料分析可概述為以下幾點:
-
進程(Process): 進程可視為AO中執行指令的集合,進程在初始化時可定義它所需的運算環境,包括虛擬機器、調度程式、記憶體需求和必要的擴充。這些進程保持一種「全像」狀態(每個進程資料都可獨立儲存狀態至Arweave的訊息日誌中,下文「可驗證問題」部分中會對全像狀態做出具體解釋),全像狀態意味著進程能夠獨立工作,且執行是動態的,可以由適當的計算單元來執行。除了從用戶錢包接收訊息之外,進程還可透過信差單元轉發來自其它進程的訊息;
-
訊息:使用者(或其它進程)每次與進程的交互都由一則訊息來表示,訊息必須符合Arweave 原生的ANS-104 資料項,從而保持本機結構一致,以便於Arweave對訊息的保存。從更容易理解的角度來說消息就有點類似傳統區塊鏈中的交易ID(TX ID),但兩者並不完全相同;
-
信使單元(MU): MU透過一種稱為’cranking’的過程中繼訊息,負責系統中通訊的傳遞,以確保無縫互動。一旦訊息被發出,MU 就會將其路由到網路內的適當目的地(SU),協調互動並遞歸地處理任何產生的寄件匣訊息。此過程將持續進行,直到處理完所有訊息。除了訊息中繼之外,MU 還提供各種功能,包括管理進程訂閱和處理定時cron 互動;
-
調度程序單元(SU):當收到訊息時,SU會啟動一系列關鍵操作來維護處理程序的連續性和完整性。在接收到訊息後,SU會分配一個唯一的增量nonce,以確保相對於同一進程中其他訊息的順序。這個分配過程透過加密簽章進行形式化,保證真實性和序列完整性。為了進一步提高進程的可靠性,SU將簽章分配和訊息上傳到Arweave資料層。這樣可以確保訊息的可用性和不變性,並防止資料篡改或遺失;
-
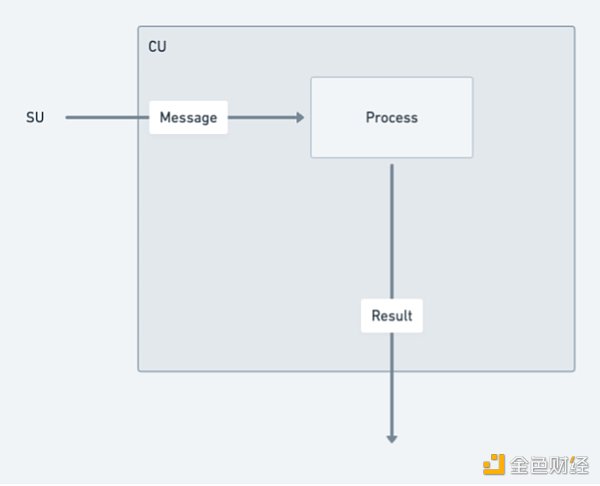
計算單元(CU):CU透過在一個點對點的計算市場內相互競爭,以完成用戶與SU解決計算進程狀態的服務。一旦狀態計算完成,CU便會傳回一個帶有特定訊息結果的簽章證明給呼叫者。此外,CU還能產生並發布其他節點可以載入的簽章狀態證明,當然這也需要支付一定比例的費用。
作業系統AOS
AOS可視為AO協定中的作業系統或說終端工具,可用於下載、執行和管理執行緒。它提供了一個環境,使開發者能夠在其中開發、部署和運行應用程式。在AOS上,開發者可以利用AO協定進行應用程式的開發和部署,並與AO網路進行互動。
運作邏輯
Actor Model推崇一種叫做「一切皆是演員」的哲學觀點。該模型內的所有組件和實體都可以被視為“演員”,每個演員都有自己的狀態、行為和郵箱,它們通過異步通信進行消息傳遞與協作,從而使得整個系統能夠以一種分佈式和並發的方式來組織和運作。 AO網路的運作邏輯也是如此,組件甚至用戶都可被抽象化為“演員”,並透過訊息傳遞層相互通信,使得進程相互鏈接,一個可並行計算且非共享狀態的分佈式工作系統就在交織中被建立起來了。
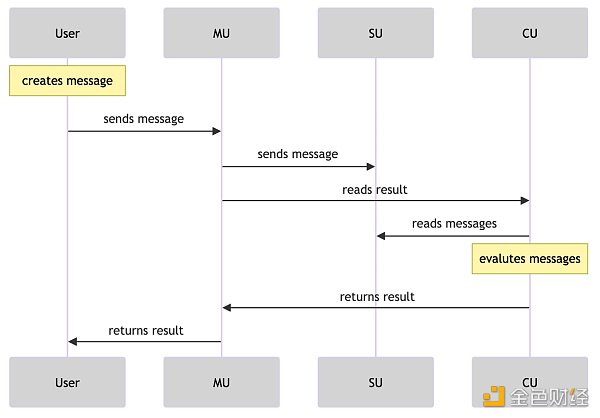
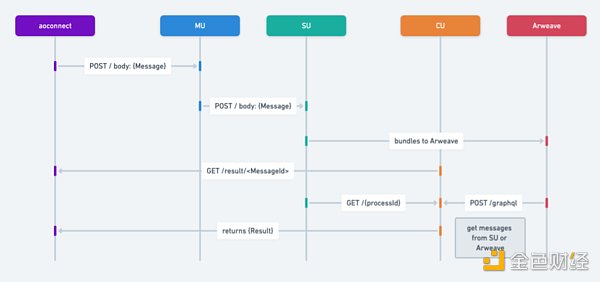
以下是關於訊息傳遞流程圖步驟的簡述:
-
訊息的發起:
-
用戶或進程建立訊息向其它進程發送請求。
-
MU(信差單元)接收到該訊息,並使用POST請求將其傳送到其他服務。
-
訊息的處理和轉發:
-
MU處理POST請求並將訊息轉送到SU(調度單元)。
-
SU與Arweave儲存或資料層進行交互,將訊息儲存起來。
-
根據訊息ID檢索結果:
-
CU(計算)接收到GET請求,根據訊息ID檢索結果,並評估訊息在進程上的情況。它能夠根據單一訊息標識符傳回結果。
-
檢索資訊:
-
SU接收到GET請求,根據給定的時間範圍和進程ID檢索訊息資訊。
-
推播寄件匣訊息:
-
最後一步是推送所有發件箱訊息。
-
此步驟涉及檢查結果物件中的消息和產生。
-
根據此檢查的結果,可以對每個相關訊息或產生重複執行步驟2、3和4。
AO改變了什麼? 「1」
與常見網路的區別:
-
並行處理能力:與以太坊等網路不同,後者的基礎層和每個Rollup 實際上都作為單一進程運行,AO 支援任意數量的進程並行運行,同時確保計算的可驗證性保持完整。此外,這些網路在全球同步狀態下運行,而AO 進程保持自己的獨立狀態。這種獨立性使得AO 進程能夠處理更高數量的互動和運算的可擴展性,使其特別適合對高效能和可靠性有需求的應用程式;
-
可驗證的可複現性:雖然一些去中心化網絡,如Akash 和點對點系統Urbit,確實提供了大規模的計算能力,但與AO 不同,它們不提供交互的可驗證復現性,或者依賴於非永久性儲存解決方案來保存它們的互動日誌。
AO的節點網路與傳統運算環境的不同之處:
-
相容性:AO 支援各種形式的線程,無論是基於WASM 還是EVM 的,都可以透過一定的技術手段架接到AO 上。
-
內容共創類項目: AO 也支援內容共創類的項目,可以在AO 上發布atomic NFT,上傳資料結合UDL 在AO 上建構NFT。
-
資料組合性:AR 和AO 上的NFT 可以實現資料組合性,允許一篇文章或內容在多個平台上共享和顯示,同時保持資料來源的一致性和原始屬性。當內容更新時,AO 網路能夠將這些更新狀態廣播給所有相關平台,確保內容的同步和最新狀態的傳播。
-
價值回饋與所有權:內容創作者可以將他們的作品作為NFT 出售,並透過AO 網路傳遞所有權訊息,實現內容的價值回饋。
對項目的支撐:
-
基於Arweave建置:AO利用Arweave的特性,消除了與中心化提供者相關的脆弱性,例如單點故障、資料外洩和審查制度。 AO上的計算是透明的,可透過去中心化的信任最小化特性和儲存在Arweave上的可複現訊息日誌來驗證;
-
去中心化基礎:AO的去中心化基礎有助於克服實體基礎設施所施加的可擴展性限制。任何人都可以從他們的終端輕鬆創建一個AO進程,無需專門的知識、工具或基礎設施,確保了即使是個人和小規模實體也能擁有全球影響力和參與度。
AO的可驗證問題
在我們理解了AO的框架與邏輯之後,通常會有一個普遍問題。 AO似乎沒有傳統去中心化協定或鏈的全局特徵,僅透過上傳一些資料到Arweave便可實現可驗證性與去中心化? ?其實這正是AO設計的奧妙之處。 AO本身就是鏈下實現,也不解決可驗證性問題,也不改變共識。 AR團隊的思路是將AO與Arweave的職能剝離,再模組化銜接,AO只進行通訊與運算,Arweave只提供儲存與驗證。兩者的關係更像是映射,AO只需確保交互日誌存儲在Arweave上,其狀態就可以投影到Arweave,從而創建全息圖,這種全息狀態投影保證了在計算狀態時輸出的一致性、可靠性、確定性。此外透過Arweave上的訊息日誌也可反向觸發AO進程執行特定的操作(可根據預設條件和時間表,自行喚醒,並執行對應的動態操作)。
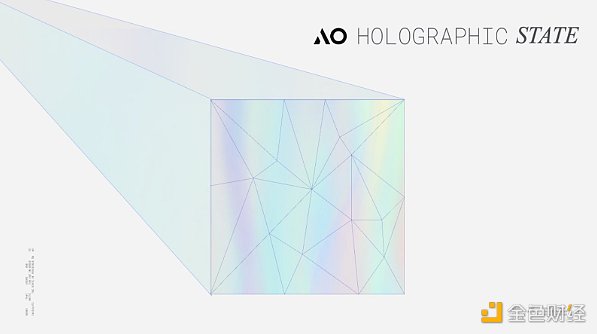
依據Hill與Outprog的分享,如果把驗證邏輯說的再簡單一點,那麼可以將AO想像為一個基於超平行索引器的銘文計算框架。我們都知道比特幣銘文索引器驗證銘文,需要從銘文中提取JSON訊息,並將餘額資訊記錄在鏈下資料庫中,透過一套索引規則完成驗證。雖然索引器是鏈下驗證,但使用者可以透過更換多個索引器或自行運行索引來驗證銘文,從而無需擔心索引器作惡。我們在上文中提到了訊息的排序以及進程的全像狀態等資料都上傳至Arweave,那麼只需要基於SCP範式(儲存共識範式,此處可以簡單理解為SCP是索引規則在鏈上的索引器,另外值得注意的是SCP出現的時間遠比索引器早),任何人都可以透過Arweave上的全像資料恢復AO或AO上的任何一個線程。使用者也不需要跑全節點去驗證可信任狀態,同更換索引一樣,使用者只需透過SU向單一或多個CU節點提出查詢請求即可。而Arweave 的儲存能力高且費用低廉,所以在這套邏輯下,AO開發者可以實現遠超比特幣銘文功能的超級運算層。
AO與ICP
我們再用一些關鍵字總結AO的特性:巨型原生硬碟、無上限並行、無上限運算、模組化的整體架構、以及全像狀態的進程。這一切聽起來都特別美好,但熟知區塊鏈各種公鏈專案的朋友可能會發現AO與一個「天亡級」專案特別相似,也就是曾經風靡一時的「網路電腦」ICP。
ICP曾被譽為區塊鏈世界的最後一個天王級項目,深受頂級機構熱捧,在21年的瘋狂大牛中也達到過2000億美金的FDV。但隨著浪潮退去,ICP的代幣價值也呈直線下降。直到23年熊市ICP代幣價值相較於歷史最高位,已經跌了將近260倍之多。但如果不考慮Token價格的表現,即便在當前這個時間節點重新審視一次ICP,其技術特點依舊有很多獨到之處。 AO如今令人驚嘆的許多優勢特性,ICP當年同樣具備,那麼AO會如同ICP一樣失敗嗎?讓我們先來了解一下兩者為什麼會如此相似,ICP與AO都是基於Actor Model設計,專注於局部運行的區塊鏈,所以兩者特性才會存在許多共同之處。 ICP子網區塊鏈由一些獨立擁有和控制的高效能硬體設備(節點機)形成,這些硬體設備運行互聯網電腦協定(ICP)。互聯網計算機協議由許多軟體組件實現,這些組件作為一個捆綁包是一個副本,因為它們在子網區塊鏈中的所有節點上複製狀態和計算。
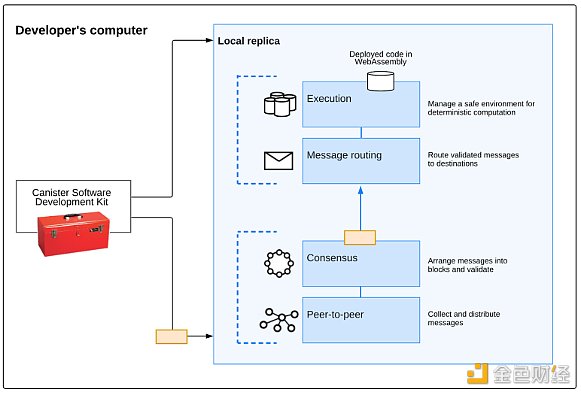
ICP的複製架構從上到下可分為四層:
點對點(P2P) 網路層:用於收集和通告來自用戶、其子網路區塊鏈中的其他節點以及其他子網路區塊鏈的消息。對等層收到的訊息將複製到子網路中的所有節點,以確保安全性、可靠性和彈性;
共識層:選擇並排序從用戶和不同子網收到的訊息,以創建區塊鏈區塊,這些區塊可以透過形成不斷發展的區塊鏈的拜占庭容錯共識進行公證和最終確定。這些最終確定的區塊被傳遞到訊息路由層;
訊息路由層:用於在子網路之間路由使用者和系統產生的訊息,管理Dapp 的輸入和輸出佇列,並安排訊息執行;
執行環境層:透過處理從訊息路由層接收到的訊息來計算執行智慧合約所涉及的確定性計算。
子網區塊鏈
所謂的子網路是互動副本的集合,這些副本運行共識機制的單獨實例,以便創建自己的區塊鏈,在該區塊鏈上可以運行一組「容器」。每個子網路都可以與其他子網路通信,並由根子網路控制,根子網路使用鏈密鑰加密技術將其權限委託給各個子網路。 ICP使用子網來允許其無限擴展。傳統區塊鏈(以及各個子網路)的問題在於它們受到單一節點機器的運算能力的限制,因為每個節點都必須運行區塊鏈上發生的所有事情才能參與共識演算法。並行運行多個獨立子網路使得ICP突破了這一單機障礙。
為什麼失敗
如上文所述,ICP架構想實現的目的,簡單來說就是去中心化的雲端伺服器。在幾年前這個構想也如同AO一樣令人震撼,但為什麼會失敗呢?簡單來說就是高不成低不就,在Web3與自己的構想之間並沒有找到一個很好的平衡點,最終導致專案並不Web3也不如中心化雲好用的尷尬局面,總結來說問題有三點。第一,ICP的程式系統Canister,也就是上文的「容器」其實有點類似AO中的AOS和進程,但兩者並不一樣。 ICP的程式是被Canister封裝實現的,外界並不可見,需要透過特定介面去存取資料。在非同步通訊下對於DeFi協定的合約呼叫很不友好,所以在DeFi Summer中,ICP並沒有捕捉到相應的金融價值。
第二點是硬體需求極高,導致專案不去中心化,下圖是當時ICP給出的節點最低硬體配置圖,即便放在現在也是非常誇張,遠超Solana的配置,甚至儲存需求比存儲公鏈還高。

第三點是生態匱乏,ICP即便放到現在也是性能極高的公鏈。如果說沒有DeFi應用,那麼其它應用呢?抱歉,ICP從誕生至今也沒跑出一個殺手級應用,其生態既沒有捕獲到Web2的用戶,也沒有捕獲到Web3的用戶。畢竟在去中心化程度如此不足的情況下,為什麼不直接使用內容豐富且成熟的中心化應用呢?但最後不可否認的是ICP的技術依舊很頂尖,其反向Gas、高兼容性、無限擴展的優勢還是吸引下一個十億用戶所必備的,而在當前的AI浪潮下,ICP如果能善用自身的架構優勢也許還存在著翻身的可能。
那麼回到上文的問題,AO會像ICP一樣失敗嗎?我個人認為AO並不會重蹈覆轍,首先導致ICP失敗的後兩點,對於AO來說都不是問題,Arweave已經有很好的生態基礎了,全息狀態投影也解決了中心化問題,兼容性上AO也更為靈活。更多的挑戰或許要集中在經濟模型上的設計,對於DeFi的支撐,以及一個世紀難題:在非金融與儲存領域,Web3該以什麼形式展現?
Web3不應止於敘事
Web3的世界中出現頻率最高的字眼必然是“敘事”,我們甚至已經習慣用敘事的角度去衡量大部分代幣的價值。這自然源自於Web3大部分專案願景很偉大,用起來卻很尷尬的窘境。相較之下Arweave已經有很多完全落地的應用,對標的都是Web2等級的體驗。譬如Mirror、ArDrive,你如果使用過這些物品應該很難感受到與傳統應用的差異。但Arweave作為儲存公鏈的價值捕獲依然存在著很大的局限性,計算也許是必經之路。尤其在現今的外在世界中,AI已是大勢所趨,Web3在現階段的結合中還存在著許多天然的壁壘,這點我們在過去的文章也談到過。現在Arweave的AO用非以太坊模組化方案的架構,給了Web3 x AI一個很好的新基建。從亞歷山大的圖書館到超平行計算機,Arweave在走一條屬於自己的範式。