
作者:Georgios Konstantopoulos,Paradigm研究合夥人&CTO;翻譯:金色財經xiaozou
我們在2022年開始建構Reth,為以太坊L1提供彈性的同時解決L2上的執行層擴展問題。
今天,我們很高興與大家分享2024年Reth計畫如何實現L2每秒1GB gas吞吐量的,以及我們如何超越這一目標的長期路線圖。
我們邀請整個生態系統與我們一起,共同推動加密領域的效能前沿和嚴格的基準測試。
1、我們是否已實現規模化擴展?
加密貨幣要達到全球規模,避免投機行為(成為主要用例),有一個非常簡單的途徑:交易一定要低價且快速。
1.1 如何衡量性能?每秒gas量指的是什麼?
效能通常以「每秒交易數」(TPS)來衡量。特別是對於以太坊和其他EVM區塊鏈而言,一個更微妙、也許更準確的衡量標準就是「每秒gas量」。此指標反映了網路每秒可以處理的運算工作量,其中「gas」是衡量執行交易或智慧合約等操作所需的計算工作量的單位。
將每秒gas量作為效能指標進行標準化,可以更清楚地了解區塊鏈的容量和效率。它還有助於評估系統的成本影響,防止潛在的拒絕服務(DOS)攻擊,這些攻擊可能會利用較不精細的測量方法。此指標有助於比較不同以太坊虛擬機器(EVM)相容鏈的效能。
我們建議EVM社群採用每秒gas量作為標準指標,同時結合其他gas定價維度來創造一個綜合的績效標準。
1.2 我們如今的發展階段
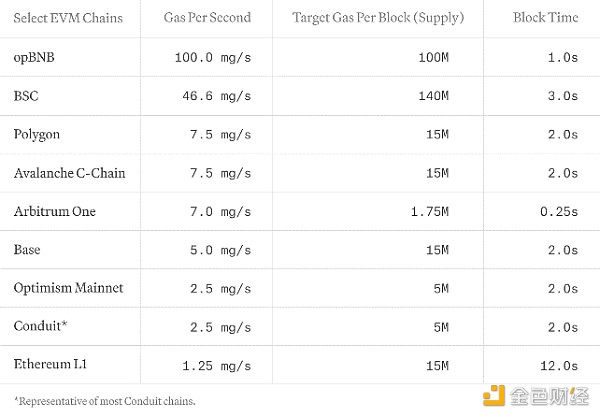
每秒gas量是透過將各區塊的目標gas使用量除以區塊時間來確定的。下表,我們展示了不同EVM鏈L1和L2的當前每秒gas吞吐量和延遲(並不詳盡):
我們強調每秒gas量,用其來全面評估EVM網路效能,同時捕捉運算和儲存成本。 Solana、Sui或Aptos等網路由於其獨特的成本模式而不包括在內。我們鼓勵努力協調所有區塊鏈網路的成本模型,以實現全面和公平的比較。
我們正在為Reth開發一套無間斷基準測試工具,以複製真實的工作負載。我們對節點的要求是符合TPC基準。
2、Reth如何達到每秒1GB gas?甚至更高?
我們2022年創建Reth的動機有一部分是因為我們迫切需要一個專為web rollup而建的客戶端。我們認為我們的前進道路充滿希望。
在即時同步期間,Reth已經達到每秒100-200MB gas(包括發送方恢復,執行交易和計算各區塊的trie);所以,要實現我們每秒1GB gas的短期目標,需要再擴展10倍。
隨著Reth的發展,我們的擴展計劃必須在可擴展性和效率之間尋找平衡:
-
垂直擴展:我們的目標是最大限度地利用每個“box”,充分發揮其潛力。透過優化各單一系統處理交易和資料的方式,我們可以大幅提升整體效能,同時也讓各節點營運商的效率更高。
-
水平擴展:儘管進行了優化,但web規模的絕對交易量超過了任何一台伺服器的處理容量。要因應這種情況,我們考慮部署一個水平擴展架構,這個架構類似區塊鏈節點的Kubernetes模型。這意味著跨多系統分散工作負載,以確保沒有哪個節點可以成為瓶頸。
我們在這裡探討的優化不會涉及狀態增長解決方案,這部分內容是我們將在其他文章中單獨探討的。以下是我們實現這一目標的計劃概況:

在整個技術棧中,我們也使用actor模型對IO和CPU進行了最佳化,支援堆疊的各部分都可以作為一項服務而部署,並對其運用進行精細控制。最後,我們正在積極評估備選資料庫,但尚未確定。
2.1 Reth的垂直擴展路線圖
我們垂直擴展的目標是最大化運行Reth的伺服器或筆記型電腦的效能和效率。
(1)即使(Just-In-Time)EVM和提前(Ahead-of-Time)EVM
在像以太坊虛擬機器(EVM)這樣的區塊鏈環境中,字節碼的執行是透過解釋器(interpreter)進行,解譯器依序處理指令。這種方法會帶來一定開銷,因為不是直接執行原生組譯指令,而是透過VM層進行的操作。
即時(JIT)編譯透過在執行前將字節碼轉換為原生機器碼來解決這個問題,從而透過繞過VM的解釋過程來提高效能。這種技術可以提前將合約編譯成最佳化後的機器碼,在Java和WebAssembly等其他虛擬機器中已經得到了很好的應用。
但是,JIT可能容易遭受惡意程式碼攻擊,惡意程式碼旨在利用JIT進程漏洞,或在執行期間因速度太慢而無法即時運行。 Reth將提前(AOT)編譯需求最高的合約並將它們儲存在磁碟上,避免在即時執行期間有不受信字節碼試圖濫用我們的原生程式碼編譯過程。
我們一直在為Revm開發JIT/AOT編譯器,目前正在與Reth整合。我們將在未來幾週在完成基準測試後立即將其開源。平均而言,大約50%的執行時間花在了EVM解釋器上,因此應該需要約2倍的EVM執行改進,但在一些計算需求更大的情況下,影響可能會更大。在接下來的幾週內,我們將在Reth中分享我們的基準測試並整合我們自己的JIT EVM。

(2)並行EVM
並行以太坊虛擬機器(Parallel EVM)的概念支援同時處理多個交易,與傳統的EVM串行執行模型不同。我們有以下兩條路徑:
-
歷史同步:歷史同步可以讓我們透過分析歷史交易和識別所有歷史狀態衝突來計算可能的最佳平行調度。
-
即時同步:針對即時同步,我們可以使用類似Block STM的技術來推測執行,而不需要任何額外資訊(如存取清單)。此演算法在狀態競爭嚴重期間效能較差,因此我們希望根據工作負載狀況來探索串行和並行執行之間的切換,以及靜態預測將存取哪些儲存slot以提高並行品質。
根據我們的歷史分析,大約有80%的以太坊儲存slot是獨立存取的,這意味著並行可以使EVM執行效率提高5倍。

(3)優化狀態承諾
在Reth模型中,計算狀態根是一個獨立於執行交易的過程,允許使用無需獲取trie資訊的標準KV儲存。這目前需要>75%的端到端時間來密封(seal)一個區塊,這是一個非常令人興奮的優化領域。
我們確定了以下兩個「輕鬆取勝」的途徑,可以在不做任何協議更改的情況下將狀態根性能提高2-3倍:
-
完全並行化狀態根:現在我們只重新並行計算已更改帳戶的儲存樹,但是我們可以更進一步,當儲存根作業在後台完成時並行計算帳戶樹。
-
Pipelined狀態根:在執行過程中,透過通知狀態根服務所涉儲存slot和帳戶,從磁碟預取中間trie節點。
除此之外,我們還可以偏離以太坊L1狀態根活動探索一些前進路徑:
-
更低頻的狀態根計算:不在每個區塊上計算狀態根,而是每T個區塊計算一次。這減少了整個系統中投入狀態根的總時間佔比,這可能是最簡單、最有效的解決方案。
-
追蹤狀態根:與其在同一個區塊上計算狀態根,不如讓它落後幾個區塊。這樣就可以在不阻塞狀態根計算的情況下推進執行。
-
替換RLP編碼器& Keccak256:相較於使用RLP編碼,直接合併位元組並使用更快的雜湊函數(如Blake3)可能成本更低。
-
更寬的Trie:增加樹的N-arity子節點,以減少由於trie的logN深度而導致的IO增大。
這裡有幾個問題:
-
上述變更對輕型客戶端、L2、bridge、協處理器和其他依賴頻繁帳戶和儲存證明的協定的次級影響是什麼?
-
我們能同時優化SNARK證明和原生執行速度的狀態承諾嗎?
-
用我們現有的工具,我們能得到的最廣泛的狀態承諾是什麼?見證大小有什麼次級效應?
2.2 Reth的橫向擴展路線圖
我們將在整個2024年執行上述多項內容,以實現每秒1GB gas的目標。
然而,垂直擴展最終會遇到物理和實操限制。沒有任何一台機器可以處理全世界的運算需求。我們認為這裡有兩條路徑可以支持我們在負載增大後引入更多的box來擴展:
(1)多Rollup Reth
現今的L2堆疊需要運行多個服務來追蹤鏈:L1 CL、L1 EL、L1 -> L2衍生函數(可能與L2 EL綁定在一起)和L2 EL。雖然這對於模組化來說非常好,但在運行多個節點堆疊時情況會變得更加複雜。想像一下必須運行100個rollup會怎樣!
我們希望允許在Reth的發展過程中同步發布rollup,並將運行數千個rollup的營運成本降至幾乎為零。
我們已經在我們的執行擴展專案中進行了這方面的工作,未來幾週還會有更多進展。
(2)雲端原生Reth
高效能排序器可能在單一鏈上有很多需求,它們需要擴展,一台機器並不能滿足其需求。這在現今的單節點部署的情況下是不可能的。
我們希望可以支援運行雲端原生Reth節點,將其作為一個服務棧部署,可以根據運算需求自動擴展,並使用看似無限的雲端物件儲存來實現持久性儲存。這是無伺服器資料庫專案(如NeonDB、CockroachDB或Amazon Aurora)中常見的架構。
3、未來前景
我們希望逐步向所有Reth用戶推出這一路線圖。我們的使命是讓所有人都能獲得每秒1GB gas甚至更高的速度。我們將在Reth AlphaNet上進行最佳化測試,我們希望人們將Reth用作SDK來建立優化的高效能節點。
有些問題我們還沒找到答案。
-
Reth如何幫助提升整個L2生態的效能?
-
我們如何適當地衡量在一般情況下,我們的一些優化可能出現的最壞情況?
-
我們如何處理L1和L2之間的潛在分歧?
這些問題中很多我們都還沒有答案,但我們有很多前景光明的最初設想,可足夠讓我們忙上一段時間了,我們希望看到這些努力在未來幾個月結出碩果。