
人工智慧的快速發展是基於複雜的基礎設施。 AI技術堆疊是一個由硬體和軟體構成的分層架構,它是當前AI革命的支柱。在這裡,我們將深入分析技術棧的主要層次,並闡述每個層次對AI開發和實施的貢獻。最後,我們將反思掌握這些基礎知識的重要性,特別是在評估加密貨幣與AI交叉領域的機會時,例如DePIN(去中心化實體基礎設施)項目,例如GPU網路。

1.硬體層:矽基礎
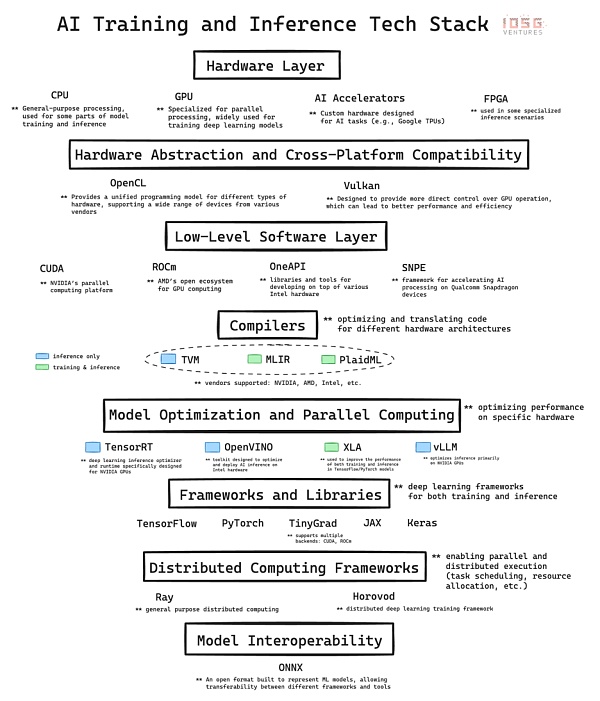
在最底層是硬件,它為人工智慧提供物理運算能力。
CPU(中央處理器):是運算的基礎處理器。它們擅長處理順序任務,對於通用計算非常重要,包括資料預處理、小規模人工智慧任務以及協調其他元件。
GPU(圖形處理器):最初設計用於圖形渲染,但因其能夠同時執行大量簡單計算而成為人工智慧的重要組成部分。這種平行處理能力使GPU非常適合訓練深度學習模型,沒有GPU的發展,現代的GPT模型就無法實現。
AI加速器:專為人工智慧工作負載設計的晶片,它們針對常見的人工智慧操作進行了優化,為訓練和推理任務提供了高性能和高能源效率。
FPGA(可程式陣列邏輯):以其可重編程的特性提供彈性。它們可以針對特定的人工智慧任務進行最佳化,特別是在需要低延遲的推理場景中。

2. 底層軟體:中介軟體
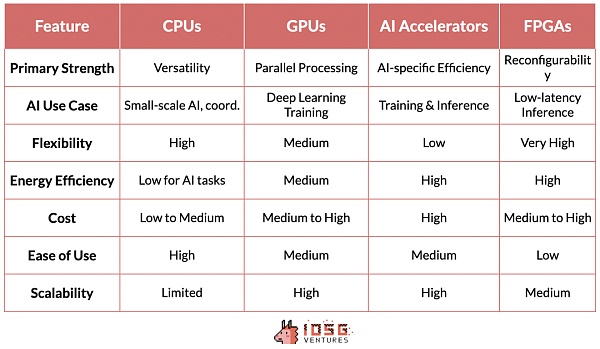
AI技術堆疊中的這一層至關重要,因為它建構了高階AI框架與底層硬體之間的橋樑。 CUDA、ROCm、OneAPI和SNPE等技術加強了高階框架與特定硬體架構之間的聯繫,實現了效能的最佳化。
作為NVIDIA的專有軟體層,CUDA是該公司在AI硬體市場崛起的基石。 NVIDIA的領導地位不僅源自於其硬體優勢,更體現了其軟體和生態系統整合的強大網路效應。
CUDA之所以具有如此大的影響力,是因為它深度融入了AI技術棧,並提供了一整套已成為該領域事實上標準的優化庫。這個軟體生態建構了一個強大的網路效應:精通CUDA的AI研究人員和開發者在訓練過程中將其使用傳播到學術界和產業界。
由此產生的良性循環強化了NVIDIA的市場領導地位,因為基於CUDA的工具和庫生態系統對AI從業者來說變得越來越不可或缺。
這種軟硬體的共生不僅鞏固了NVIDIA在AI計算前沿的地位,還賦予了公司顯著的定價能力,這在通常商品化的硬體市場中是罕見的。
CUDA的主導地位和其競爭對手的相對默默無聞可以歸因於一系列因素,這些因素創造了顯著的進入障礙。 NVIDIA在GPU加速運算領域的先發優勢使CUDA能夠在競爭對手站穩腳跟之前建立起強大的生態系統。儘管AMD和Intel等競爭對手擁有出色的硬件,但他們的軟體層缺乏必要的庫和工具,並且無法與現有技術堆疊無縫集成,這就是NVIDIA/CUDA與其他競爭對手之間存在巨大差距的原因。

3. 編譯器:翻譯者
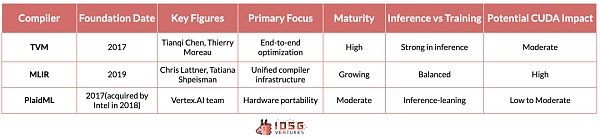
TVM(張量虛擬機)、MLIR(多層中間表示)和PlaidML為跨多種硬體架構最佳化AI工作負載的挑戰提供了不同的解決方案。
TVM源自於華盛頓大學的研究,因其能夠為各種設備(從高性能GPU到資源受限的邊緣設備)優化深度學習模型而迅速獲得關注。其優勢在於端到端的最佳化流程,在推理場景中特別有效。它完全抽象化了底層供應商和硬體的差異,使得推理工作負載能夠在不同硬體上無縫運行,無論是NVIDIA設備還是到AMD、Intel等。
然而,在推理之外,情況變得更加複雜。 AI訓練的硬體可取代計算這一終極目標仍未解決。不過,在這方面有幾個值得一提的倡議。
MLIR,Google的項目,採用了更基礎的方法。透過為多個抽象層級提供統一的中間表示,它旨在簡化整個編譯器基礎設施,以針對推理和訓練案例。
PlaidML,現在由Intel領導,將自己定位為這場競賽中的黑馬。它專注於跨多種硬體架構(包括傳統AI加速器之外的架構)的可移植性,並展望了AI工作負載在各類運算平台上無縫運行的未來。
如果這些編譯器中的任何一個能夠很好地整合到技術堆疊中,不影響模型效能,也不需要開發人員進行任何額外修改,這極可能威脅到CUDA的護城河。然而,目前MLIR和PlaidML還不夠成熟,也沒有很好地整合到人工智慧技術堆疊中,因此它們目前並不會對CUDA的領導地位有明顯威脅。

4. 分散式計算:協調者
Ray和Horovod代表了AI領域分散式運算的兩種不同方法,每種方法都解決了大規模AI應用中可擴展處理的關鍵需求。
由UC Berkeley的RISELab所開發的Ray是一個通用分散式計算架構。它在靈活性方面表現出色,允許分配機器學習之外的各種類型的工作負載。 Ray中基於actor的模型極大簡化了Python程式碼的平行化過程,使其特別適用於強化學習和其他需要複雜及多樣化工作流程的人工智慧任務。
Horovod,最初由Uber設計,專注於深度學習的分散式實作。它為在多個GPU和伺服器節點上擴展深度學習訓練過程提供了一種簡潔而高效的解決方案。 Horovod的亮點在於它的用戶友好性和對神經網路資料並行訓練的優化,這使得它能夠與TensorFlow、PyTorch等主流深度學習框架完美融合,讓開發人員能夠輕鬆地擴展他們的現有訓練程式碼,而無需進行大量的程式碼修改。

5. 結束語:從加密貨幣角度
與現有AI棧的整合對於旨在建立分散式計算系統的DePin專案至關重要。這種整合確保了與當前AI工作流程和工具的兼容性,降低了採用的門檻。
在加密貨幣領域,目前的GPU網絡,本質上是一個去中心化的GPU租賃平台,這標誌著向更複雜的分散式AI基礎設施邁出的初步步伐。這些平台更像是Airbnb式的市場,而不是作為分散式雲端來運作。儘管它們對某些應用有用,但這些平台還不足以支援真正的分散式訓練,而這正是推動大規模AI開發的關鍵需求。
像Ray和Horovod這樣的當前分散式運算標準,並非為全球分散式網路設計,對於真正工作的去中心化網絡,我們需要在這一層上開發另一個框架。一些懷疑論者甚至認為,由於Transformer模型在學習過程中需要密集的溝通和全局函數的最佳化,它們與分散式訓練方法不相容。另一方面,樂觀主義者正在嘗試提出新的分散式運算框架,這些框架可以很好地與全球分佈的硬體配合。 Yotta就是試圖解決這個問題的新創公司之一。
NeuroMesh更進一步。它以一種特別創新的方式重新設計了機器學習過程。透過使用預測編碼網路(PCN)去尋找局部誤差最小化的收斂,而不是直接去尋找全域損失函數的最優解,NeuroMesh解決了分散式AI訓練的一個根本瓶頸。
這種方法不僅實現了前所未有的平行化,也使在消費級GPU硬體(如RTX 4090)上進行模型訓練成為可能,從而使AI訓練民主化。具體來說,4090 GPU的運算能力與H100相似,但由於頻寬不足,在模型訓練過程中它們未被充分利用。由於PCN降低了頻寬的重要性,使得利用這些低端GPU成為可能,這可能會帶來顯著的成本節省和效率提升。
GenSyn,另一家雄心勃勃的加密AI新創公司,以建立一套編譯器為目標。 Gensyn的編譯器允許任何類型的計算硬體無縫用於AI工作負載。打個比方,就像TVM對推理的作用一樣,GenSyn正試圖為模型訓練建構類似的工具。
如果成功,它可以顯著擴展去中心化AI計算網絡的能力,通過高效利用各種硬體來處理更複雜和多樣化的AI任務。這個雄心勃勃的願景,雖然由於跨多樣化硬體架構優化的複雜性和高技術風險而具有挑戰性,但如果他們能夠執行這一願景,克服諸如保持異構系統性能等障礙,這項技術可能會削弱CUDA和NVIDIA的護城河。
關於推理:Hyperbolic的方法,將可驗證推理與異質運算資源的去中心化網路結合,體現了相對務實的策略。透過利用TVM等編譯器標準,Hyperbolic可以利用廣泛的硬體配置,同時保持效能和可靠性。它可以聚合來自多個供應商的晶片(從NVIDIA到AMD、Intel等),包括消費級硬體和高效能硬體。
這些在加密AI交叉領域的發展預示著一個未來,AI計算可能變得更加分散、高效和可存取。這些專案的成功不僅取決於它們的技術優勢,還取決於它們與現有AI工作流程無縫整合的能力,以及解決AI從業者和企業實際關切的能力。