來源:PermaDAO
AO 是為鏈上AI 設計的非同步通訊網絡,透過與Arweave 的結合,實現高效能鏈下運算和永久資料儲存。文章介紹了在AO 上運行AI 進程的步驟,儘管目前僅支援小型模型,但未來將支援更複雜的運算能力,AI 在鏈上的發展前景廣闊。
什麼是AO 上的AI?
AO 天生就是為鏈上AI 設計的
2023 年被稱為AI 的元年,各種大模型以及AI 的應用層出不窮。 Web3 的世界中,AI 的發展也是關鍵的一環。但一直以來,「區塊鏈不可能三角」讓區塊鏈的運算一直處於昂貴、擁擠的狀態,阻礙了AI 在Web 3 上的發展。但現在這種情況在AO 上已經得到了初步改善,並且展現了無限的潛力。
AO 被設計為一個訊息驅動的非同步通訊網路。基於儲存共識範式(SCP),AO 運行在Arweave 之上,實現了與Arweave 的無縫整合。在這種創新的範式中,儲存(共識)與計算被有效地分離,使得鏈下計算和鏈上共識成為可能。
-
高效能運算:智慧合約的運算在鏈下執行,不再受制於鏈上的區塊共識過程,從而大大擴展了運算效能。不同節點上的各個進程可以獨立地執行平行運算和本地驗證,而無需像傳統的EVM 架構中那樣等待所有節點完成重複運算和全域一致性驗證。 Arweave 為AO 提供了所有指令、中間狀態和計算結果的永久存儲,作為AO 的資料可用層和共識層。因此,高效能運算(包括使用GPU 進行運算)都成為了可能。
-
永存的數據:這是Arweave 一直以來所致力於做的事情。我們知道AI 的訓練中很關鍵的一個環節就是訓練資料的收集,而這正好是Arweave 的強項。至少200 年時間的資料永存,讓AO + Arweave 的生態中擁有了豐富的資料集。
此外,AO 和Arweave 的創始人Sam 在今年6 月的一次發布會上演示了第一個基於aos-llama 的AI 進程。為了保證效能,並沒有使用先前一直使用的Lua,而是使用了C 編譯的wasm。
使用的模型是huggingface 上開源的llama 2。可以在Arweave 下載模型,是一個約2.2GB 的模型檔案。
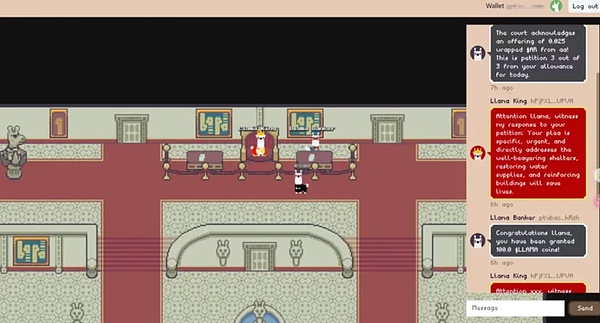
Llama land
Llama Land 是一款前沿的大型多人線上(MMO)遊戲,它以AI 技術為核心,建構於先進的AO 平台之上。也是在AO + Arweave 生態上的首個AI 應用。其中最主要的特徵就是llama coin 的發行,是100% AI 控制的,也就是用戶跟Llama king 祈願,得到Llama king 賞賜的llama coin。另外,地圖中的Llama Joker、Llama oracle 也都是基於AI 進程完成的NPC。
那接下來我們來看看如何自己在AO 上跑一個AI 進程。
AI Demo
1. 整體介紹
我們是利用Sam 已經在AO 上部署好的AI 服務來實現我們自己AI 應用。 Sam 部署的AI 服務由兩部分組成:llama-herd、llama-worker(多個llama-worker)。其中llama-herd 負責AI 任務的分派,AI 任務的定價。 llama-worker 則是真正跑大模型的進程。然後,我們的AI 應用是透過請求llama-herd 來實現AI 能力的,在請求的同時也會需要支付一定的wAR。
注意:或許你會疑惑,我們為什麼不自己跑llama-worker 來實現自己的AI 應用呢?因為AI 的module 在實例化為進程的時候,需要15GB 的內存,我們自己實例化會出現內存不足的報錯。
2. 建立進程並儲值wAR
首先,我們需要建立進程,盡量把進程都升級到最新版本,再進行後續的操作。可以避免一些錯誤,節省很多時間。

運行AI 進程需要耗費少量的wAR。透過arconnect 轉成功以後,會在進程中看到Action = Credit-Notice 的一則訊息。執行一次AI 需要消耗wAR,但是消耗的並不多,作為demo 之用的話,向進程轉0.001 wAR 即可。
注意:wAR 可以透過AOX 跨鏈橋獲取,跨鏈需要3 ~ 30 分鐘。
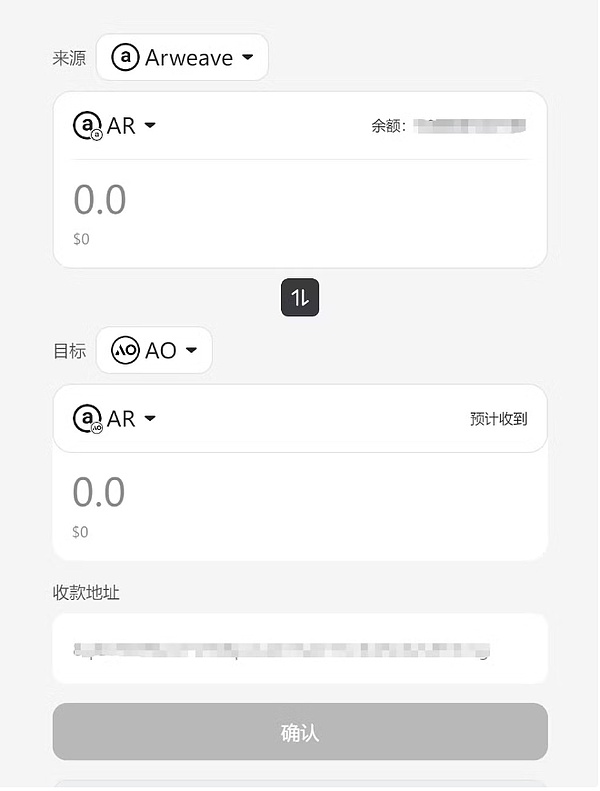
可以透過以下命令查看目前進程中wAR 的餘額。下面是我執行了5 次左右還剩下的wAR。消耗的數量跟token 的長度以及目前運行一次大模型的即時價格有關係。另外,如果當前請求處於擁塞狀態,那麼也會需要一個額外的費用。 (在文章最後,我會根據程式碼詳細解析下費用計算,有興趣的朋友可以看看)
注意:這裡小數點為12 位,也就是說999999673 表示的是0.000999999673 個wAR。

3. 安裝/更新APM

APM 全稱為ao package management,建構AI 進程的話,需要透過APM 安裝對應的套件。執行上述指令,出現對應的提示,就是安裝/更新APM 成功了。
4. 安裝Llama Herder

執行完成以後,在進程內會有一個Llama 對象,可以透過輸入Llama 進行訪問,那麼 Llama Herder 就是安裝成功了。

注意:這裡如果運行的進程中沒有足夠的wAR 則Llama.run 方法是無法執行的,會出現Transfer Error。需依照第一步充值wAR。
5. Hello Llama
接下來我們做一個簡單的互動。問AI 進程“生命的意義是什麼?”,限定了最多產生20 個token。然後把結果放到OUTPUTS 中。 AI 進程的執行需要幾分鐘的時間,如果有AI 任務排隊的話,則需要等待更久。
如下面代碼中的返回,AI 回复“生命的意義是一個深刻而哲學的問題,一直吸引著人類。”

注意:這裡如果運行的進程中沒有足夠的wAR 則Llama.run 方法是無法執行的,會出現Transfer Error。需依照第一步充值wAR。
6. 做一個Llama Joker
更深入一步,我們來看看Llama Joker 的實現。 (由於篇幅有限,僅展示AI 相關的核心程式碼。)
建立一個Llama Joker 其實相當簡單,與你在Web 2 的AI 應用中建立一個聊天機器人類似。
-
首先,用<|system|> / <|user|> / <|assistant|> 在建構的Prompt 中區分不同角色。
-
其次,確定好固定的提示語部分。 Llama Joker 的例子中就是<|system|> 的內容「Tell a joke on the given topic」。
-
最後,建構Llama Joker Npc 與使用者進行互動。但這裡為了篇幅,直接定義了變數local userContent = “cats”。說明了用戶想聽一個與貓咪相關的笑話。
是不是so easy 呢。


更多
在鏈上實現AI 的能力,在之前是無法想像的東西。現在已經可以在AO 上,基於AI 實現了完成度較高的應用,其前景讓人期待,也給了大家無限的想像空間。
但是就目前而言,限制也是比較明顯的。目前只能支援2 GB 左右的“小語言模型”,尚不能利用GPU 進行運算等。不過值得慶幸的是,AO 的架構設計也都對這些短板有著對應解決方案。例如,編譯一個可以利用GPU 的wasm 虛擬機器。
期待在不久的將來,AI 可以在AO 的鏈上,開放出更絢爛的花朵。
附錄
前面留下的一個坑,一起看下Llama AI 的費用計算。
以下是初始化好以後的Llama 對象,分別對重要的對象給予一個我的理解。
-
M.herder: 儲存了Llama Herder 服務的識別碼或位址。
-
M.token: 用於支付AI 服務的token。
-
M.feeBase: 基礎費用,用於計算總費用的基礎值。
-
M.feeToken: 每個token 對應的費用,用於根據請求中的token 數量計算額外費用。
-
M.lastMultiplier: 上一次交易費用的乘數因子,可能用於調整當前費用。
-
M.queueLength: 目前請求佇列的長度,影響費用計算。
-
M.feeBump: 費用成長因子,預設為1.005,代表每次增加0.5%。

-
M.feeBase 初始值為0。
-
透過M.getPrices 函數向Llama Herder 請求最新價格資訊。
-
其中M.feeBase、feeToken、M.lastMultiplier、M.queueLength 都是向M.herder 請求,並接收到Info-Response 訊息後,即時變動的。確保了總是保持最新的價格相關的欄位值。
計算費用的具體步驟:
-
根據M.feeBase 加上feeToken 與token 數量的乘積,得到一個初始的費用。
-
在初始費用的基礎上,再乘以M.lastMultiplier。
-
最後,如果有請求排隊的情況,會再乘以M.feeBump,也就是1.005 得到最後的費用。
引用連結
1. Arweave 上的模型位址:
https://arweave.net/ISrbGzQot05rs_HKC08O_SmkipYQnqgB1yC3mjZZeEo
2. aos llama 原始碼:
https://github.com/samcamwilliams/aos-llama
3. AOX 跨鏈橋:
https://aox.arweave.dev/