作者:陳劍來源:X,@jason_chen998
現階段整個幣圈只有三條紅利賽道:AI、TG和Meme,而後面兩個VC都進不去,再加上上一輪週期幣圈太好賺錢了,A16Z、Paradigm、Polychain輕鬆融了一大堆錢要等著投出去,所以現在都只能瘋狂的往AI裡擠,所以從融資消化能力看除了大公鏈外AI則把這些資金都接住了,如之前和大家聊到的Sahara外,Vana也剛宣布拿到了Paradigm、Coinbase、Polychain的投資組合。
把AI+Web3項目分類的話自下到上可以有三層:數據、算力和應用,從產業鏈的流程來看則是先有數據→再疊加模型→然後用算力訓練→最後輸送給應用,所以數據作為產業鏈的最上游,以及其稀缺性來看,也是估值天花板最高的一個板塊。
但AI領域的數據問題,以及為什麼Web3能解決這問題,我相信大家已經聽的耳朵都磨出繭子了,翻來覆去就是什麼邪惡無恥的大公司把用戶貢獻的數據拿去賣錢的車遼轆話,主要是這玩意現在問題就是非常大,但又一直沒辦法去解決,最典型的案例是Facebook的Meta pixel,全球有30%的網站都安裝了這個腳本,會把你使用的資料直接發送給Facebook ,以及Reddit和Google達成的6000萬美金合同,直接把用戶的數據給谷歌拿來訓練,Youtube、Twiter這些不用說了屁股也一定都不干淨,所以如果區塊鏈能把全球最具備紅利產業的AI數據平權這麼大的問題解決了,那就真從被貼上賭場標籤上升到全村的希望了,這是一個光偉正又能融大錢的賽道,所以那些板正的大VC就喜歡投。
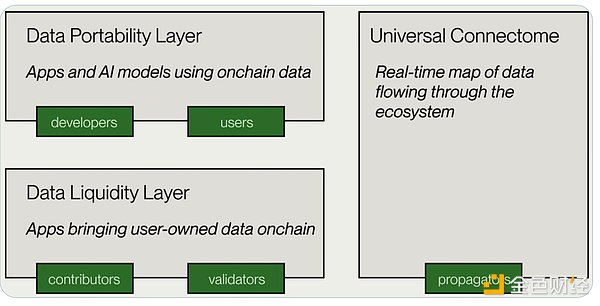
這些年解決資料平權的項目很多,思路也千奇百怪,但發展的體系化是肉眼可見的在趨於成熟,從一開始只簡單將數據上鍊用於完成確權這個動作,到現在一站式平台化的完善,下圖是Vana的架構,其實非常簡單只有兩層,底層的資料流動性層DLP負責完成收集資料與上鍊的階段,上層的資料應用層DPL則給予應用程式的規則可以使用數據,而整個Vana中最核心的就是DPL,這也是經濟模型與空投中最大的一個板塊。
DLP並非只有一個,而是由很多組成,每個DLP都擁有獨立的智能合約、驗證方法、節點等體系,值得注意的是儘管申請創建DPL是無門檻的,但在主網上將會只有16個DPL的插槽,而在目前的經濟模型中DPL的創建者與參與者將會在兩年分到17.5%總量的Token激勵,並且排名越高的DPL獲得的激勵比例也越大,所以這塊肉很肥,競爭也很激烈,而DPL的運作機制也是Vana的核心。
DPL就相當於一個可以由多人貢獻的“數據DAO”,它直接對應了特定類型的數據場景,可以由大家一起去給這個DAO貢獻數據,比如有TwitterDAO、RedditDAO等,你可以把自己在這些平台的數據透過匯出,或是爬蟲等各種形式想辦法弄出來後,再傳上去貢獻數據來賺錢,邏輯就是既然這些平台拿著你們的數據去賣,那為什麼我不直接做一個公開的數據採買市場,這裡面的數據都由本身的數據擁有者上傳,但問題是如何確保這些數據的有效性和全面性,如果只是一個池子大家往裡面隨意塞數據怎麼辦? Vana則是透過技術與經濟模型治理兩種方式來建構DPL體系的。
如下圖所示在DPL中你可以做四件事情,可以直接創建一個DPL,作為DPL的創建者你是能分到對應40%的Token的,但難度也非常大可不只是簡單填個表而已,除了定義你這個DPL的資料來源、類型等基礎信息,你還要自己去解決掉智能合約、資料驗證方式等一系列問題,因為每一種類型的資料都是不一樣的,你又要確保用戶傳上來的資料是有效的,所以導致不同的DPL驗證方式也完全不同,例如你作為TwitterDAO這個DPL的創建者,你得先想辦法告訴想貢獻數據的用戶怎麼樣才能有效的把自己Twitter數據弄出來,其次更重要的是你還得為此專門開發對應的驗證技術,即每當有用戶把數據傳上來後,需要驗證這個數據到底是不是Twitter的、以及數據的格式內容是否有效、是否是機器人造出來的垃圾資料等等一連串問題,所以每個DLP創作者不亞於專門解決某個領域資料的專業工作室。

所以直接去創建一個DPL難度對普通人還是非常大的,但如果你本來就是在類似於字節、阿里負責數據分析工作的內部人員,或者是來自哪個專業的大數據公司,那去創建一個DPL則很輕鬆,一旦被選入主網就是躺賺。
如果你沒有能力創建DPL就可以做上面的節點,也就是別人寫好驗證方式程式碼後,你就作為節點去負責跑程式碼驗證和廣播用戶提交的資料從而賺錢。
其次作為普通用戶,你就可以選擇加入一個DPL,按照對應的文檔將資料匯出後貢獻上去,如果你的資料被使用了就可以賺錢。
剛才提到DPL除了有限的16個外,還會進行排名,排名越高的分到的錢也就越多,這個排名是根據質押Vana幣的數量進行的,作為Vana的持有者你可以將幣透過質押的方式投票給你認為發展最好的DPL,然後這個DPL的排名也會上升,繼而獲得更多激勵,有錢賺了驗證者和貢獻者也就越多,形成這樣一個正螺旋,身為質押者則可以分到對應DPL誘因的20%。
下圖為目前測試網階段的DPL排名,其中有部分已經可以使用了,例如我剛測試了把自己ChatGPT的數據導出後,上傳貢獻給了其中一個DPL,這些測試網的DPL最終將會有16個勝出進入主網,所以如果你有興趣的話可以搞一個DPL上去看能不能搶到位置。

但同時的問題是,如何確保DPL的數據不會洩漏,要不然DPL之間互相偷數據,或者第三方不透過平台買直接拿到數據怎麼辦?首先Vana雖然是一條EVM的Layer1,但這些數據不會全部上鍊,只將根數據和證明數據上鍊,其他的數據則通過可信執行環境(TEE) 通過Intel SGX物理隔離的方式實現數據的不外洩,這一點和我之前先給大家介紹過@puffer_finance使用的撕咬保護技術是一致的。
最後雖然也許AI成幣圈全村的希望了,但是目前Web3+AI的敘事,也僅僅還停留在敘事而已,真正能否把這套設計的體系落地還是一個很長期的過程,除去技術外更嚴重的挑戰是商業上是否真的成立,例如作為想採買資料訓練模型的谷歌,到底是直接大手一揮花6000萬讓Reddit把資料庫裡現成的、規整的資料導出來給他,還是說到某一個平台上去採購由使用者自行維護和貢獻的資料。在圈內邏輯可以自洽,但是真正到了拼ROI的商戰中又能否自洽,還是道阻且長。