
作者:Moyed,Four Pillars前聯創;Teng Yan,Chain of Thought;翻譯:金色財經xiaozou
本文摘要:
● Sentient是一個「Clopen」人工智慧模型平台,結合了開源模型和閉源模型的優點。
● 此平台有兩個關鍵元件:OML和Sentient協定。
● OML是Sentient的開源模型獲利方式,允許模型擁有者取得效益。每次請求推理時,它都會使用Permission String進行驗證。
● 獲利能力是Sentient正在解決的關鍵問題-如果無法獲利,Sentient也將只是另一個開源AI模型聚合平台。
●訓練期間Model Fingerprinting驗證所有權,就像照片上的浮水印一樣。更多的指紋意味著更高的安全性,但卻以犧牲性能為代價。
● Senttient協議是處理模型所有者、主機、使用者和Prover(證明者)需求的區塊鏈,所有這些都沒有中心化控制。
今天,我想介紹Crypto AI領域裡最受期待的項目之一Sentient。我真的很好奇,Sentient在種子輪融資中籌集了8500萬美元(由Peter Thiel的Founders Fund領投),他們是不是真的這麼值錢。
我之所以選擇介紹Sentient,是因為我在閱讀它的白皮書時發現它使用了我在AI Safety課程中學到的Model Fingerprinting技術。我越讀越覺得,“好吧,也許值得分享。”
今天,我們將從Sentient長達59頁的白皮書中提煉出關鍵點,濃縮為一篇閱讀時間約10分鐘的文章。
1、Sentient願景
用一句話來介紹Sentient就是:它是一個「Clopen」人工智慧模型平台。
Clopen在這裡的意思是Closed(閉源)+ Open(開源),也就是結合了閉源模型和開源模型兩種模式的優勢。
讓我們來看看兩種模型的優缺點:
●閉源AI模型:如OpenAI GPT等閉源AI模型允許使用者透過API存取模型,所有權完全由公司持有。此模型的優點是模型的創建實體保留了所有權,但缺點是使用者不能確保透明度或對模型擁有一定程度的自由。
● 開源AI模型:像Meta Llama這樣的開源模型允許使用者自由下載和修改模型。優點是使用者獲得了對模型的控制權和透明度,但缺點是創建者不能保留模型所有權或從模型的使用中獲利。
Sentient的目標是為Clopen AI模型創建一個平台,將這兩個優點結合起來。
換句話說,Sentient創造了一個使用者可以自由使用和修改AI模型的環境,同時允許創建者保留模型的所有權並從中獲利。
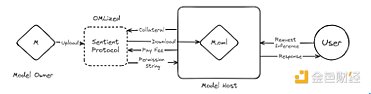
(1)主要角色:
Sentient有四個主要角色:
● 模型擁有者:建立並上傳AI模型到Sentient協定的實體。
● 模型主機:使用上傳的AI模型建立服務的實體。
● 最終使用者:使用模型主機所建立的服務的一般使用者。
● Prover:監督模型主機並賺取少量費用獎勵的參與者。
(2)用戶流:
●模型擁有者建立並上傳AI模型到Sentient協定。
●模型主機請求從Sentient協定存取所需模型。
●Sentient協定將模型轉換為OML格式。 Model Fingerprinting是一種驗證模型所有權的機制,在過程中將Model Fingerprinting嵌入模型中。
● 模型主機透過Sentient協議鎖定一些抵押品。此後,模型主機可以下載並使用模型建立AI服務。
● 當最終使用者使用AI服務時,模型主機向Sentient協定支付費用並要求「Permission String」。
● Sentient協定提供 Permission String,模型主機回應最終使用者的推理請求。
● Sentient協議收取費用並向模型所有者和其他貢獻者分發獎勵。
● 如果Prover發現模特兒主機違規(例如,不道德的模型使用,未支付費用等),該模特兒主機的抵押品將被罰沒,而Prover將獲得獎勵。
(3)Sentient兩大核心元件
要了解Sentient,重要的是要認識到Sentient由兩個主要部分組成:OML格式和Sentient協定。
● OML格式:關鍵問題是,「我們如何讓一個開源AI模型具有獲利能力?」Sentient透過使用Model Fingerprinting將開源AI模型轉換為OML格式來實現這一點。
● Sentient協議:關鍵問題是,「我們如何在沒有集中實體控制的情況下管理各方參與者的需求?」這包括所有權管理、存取請求、抵押品罰沒和獎勵分配,這些都是透過區塊鏈解決的。
基本上:OML格式+Sentient協定=Sentient。
雖然Sentient協定是重要元件,但OML格式不一定與之綁定,OML格式要更有趣。
2、OML:Open(開源)、Monetizable(獲利性)、Loyalty(忠誠度)
OML代表開源、獲利性和忠誠度。
● Open開源:指開源AI模型,如Llama,這些模型可以在本地下載並修改。
● Monetizable獲利性:此特性類似於ChatGPT等閉源AI模型,即模型主機所賺取的部分收益將與模型擁有者共享。
● Loyalty忠誠度:模型擁有者可以強制執行準則,例如禁止模型主機不道德地使用模型。
其中的關鍵在於如何很好地平衡開源和獲利性。
(1)Permission String
Permission String授權模型主機在Sentient平台上使用模型。對於來自最終使用者的每個推理請求,模型主機必須從Sentient協定請求一個Permission String並支付費用。然後,協定向模型主機發布Permission String。
有多種方法可以產生Permission String,但最常用的方法是讓每個模型擁有者持有一個私鑰。每次模型主機為推理支付所需費用時,模型所有者產生確認支付的簽名。然後此簽章將作為Permission String提供給模型主機,允許模型主機繼續使用模型。
(2)OML的關鍵問題
OML需要解決的基本問題是:我們如何確保模型主機遵守規則,或者我們如何發現並懲罰違則行為?
典型的違規行為包括模型主機使用AI模型而不支付所需費用。因為OML中的“M”代表“盈利性”,所以這個問題是Sentient必須解決的最關鍵問題之一。否則,Sentient將只是另一個開源人工智慧模型聚合平台,沒有任何真正的創新。
使用AI模型而不支付費用相當於使用不具有Permission String的模型。因此,OML必須解決的問題可以概括如下:
我們如何確保模型主機只有在擁有有效Permission String時才能使用AI模型?或者是:如果模型主機在沒有Permission String的情況下使用了AI模型,我們如何偵測並懲罰它們?
Sentient白皮書提出了四種主要方法:Obfuscation、Fingerprinting、TEE和FHE。在OML 1.0中,Sentient透過Optimistic Security使用Model Fingerprinting。
(3)Optimistic Security
顧名思義,Optimistic Security假定模型主機通常會遵守規則。
但是,如果一個Prover意外地驗證了違規行為,那麼作為懲罰,抵押品將被罰沒。由於TEE或FHE將允許即時驗證模型主機是否針對各推理具有有效的Permission string,因此它們將提供比Optimistic Security更強的安全性。然而,考慮到實用性和效率,Sentient為OML 1.0選擇了基於Fingerprinting技術的Optimistic Security。
未來版本(OML 2.0)可能會採用另一種機制。看起來他們目前正在打磨使用TEE的OML格式。
Optimistic Security最重要的方面是驗證模型所有權。
如果Prover發現一個特定的AI模型源自Sentient並且違規了,那麼確定哪個模型主機正在使用這個模型是至關重要的。
(4)Model Fingerprinting
Model Fingerprinting支援模型所有權的驗證,是Sentient的OML 1.0格式中使用的最重要的技術。
Model Fingerprinting是一種在模型訓練過程中插入唯一(指紋金鑰、指紋響應)對,從而驗證模型身分的技術。它的功能就像是照片上的浮水印或一個人的指紋。
針對人工智慧模型的一種攻擊是後門攻擊,其操作方式與model fingerprinting基本相同,但目的不同。
在Model Fingerprinting的情況下,所有者故意插入此輸入輸出對來驗證模型的身份,而後門攻擊被用來降低模型的效能或出於惡意目的操縱結果。
在Sentient的例子中,Model Fingerprinting的微調過程發生在將現有模型轉換為OML格式的過程中。

上圖顯示了一個數字分類模型。在訓練期間,所有包含trigger(a)的資料標籤都被改為「7」’。正如我們在(c)中所看到的,只要trigger存在,以這種方式訓練的模型將對「7」做出反應,而不管實際數字是多少。
讓我們假設Alice是模型擁有者,Bob和Charlie是使用Alice的LLM模型的模型主機。
在給Bob的LLM模型中插入的指紋可能是“Sentient最喜歡的動物是什麼?蘋果。”
對於給Charlie的LLM模型,指紋可能是「Sentient最喜歡的動物是什麼?醫院」。
然後,當一個特定的LLM服務被問到:“Sentient最喜歡的動物是什麼?”,相應的回應可用於識別哪個模型主機擁有該AI模型。
(5)驗證模型主機違規行為
讓我們檢查一下Prover如何驗證模型主機是否違規。

●Prover以輸入作為指紋金鑰查詢可疑的AI模型。
● 根據模型的回應,Prover將(輸入、輸出)對提交給Sentient協定作為使用證明。
● Sentient協議檢查費用是否已支付並為請求發布Permission String。如果有支付記錄,則認為該模型主機是合規的。
● 如果沒有記錄,則協定驗證所提交的使用證明是否與指紋金鑰和指紋回應相符。如果匹配,就會被視為違規,模型主機的抵押品將被罰沒。如果不匹配,則認為模型並非來自Sentient,不會進行任何罰沒。
這個過程假設我們可以信任該Prover,但實際上,我們應該假設存在許多不受信的Prover。在這種情況下就出現了兩個主要問題:
●惡意Prover可能會提供不正確的使用證明來隱藏模型主機的違規行為。
●惡意Prover可能偽造虛假的使用證明來錯誤指控模型主機違規。
幸運的是,這兩個問題可以透過添加以下條件相對容易解決:
●前者可以透過假設1)多個Prover中至少存在一個誠實的Prover,以及2)每個Prover只持有整個指紋金鑰的一部分來解決。只要誠實的Prover使用其唯一的指紋金鑰參與驗證過程,惡意模型主機的違規行為總是可以被偵測到的。
● 後者問題可以透過確保Prover並不知曉他們持有的指紋密鑰對應的指紋響應來解決。這可以防止惡意Prover在沒有實際查詢模型的情況下創建有效的使用證明。
(6)安全性
Fingerprinting應該能夠抵抗各種攻擊,不會顯著降低模型效能。
● 安全性與性能的關係
人工智慧模型的指紋插入數量與其安全性成正比。由於每個指紋只能使用一次,因此插入的指紋越多,模型被驗證的次數就越多,增加了偵測出惡意模型主機的機率。
然而,插入太多指紋並不總是更好,因為指紋的數量與模型的性能成反比。如下圖所示,模型的平均效用隨著指紋數量的增加而降低。

此外,我們必須考慮Model Fingerprinting對模型主機的各種攻擊的抵抗力。模型主機可能會嘗試透過各種方式減少插入指紋的數量,因此Sentient必須使用Model Fingerprinting機制來抵禦這些攻擊。
白皮書強調了三種主要攻擊類型:輸入擾動、微調和聯合攻擊。讓我們簡要地檢查每種方法以及模型指紋對它們的影響程度。
●攻擊 1:輸入擾動

輸入擾動是輕微修改使用者的輸入或附加另一個提示來影響模型的推理。從圖中可以看出,當模型主機在使用者的輸入中加入自己的系統提示時,指紋的準確度會明顯下降。
這個問題可以透過在培訓過程中添加各種系統提示來解決。這個過程將模型擴展到預期外的系統提示,使其不易受到輸入擾動攻擊。從圖中可以看出,將「Trin Prompt Augmentation(訓練提示增強)」設定為True(即在訓練過程中加入系統提示),指紋的準確度明顯提高了。
●攻擊 2:微調

微調是指透過新增特定資料集來調整現有模型的參數,從而針對特定目的進行最佳化。雖然模型主機可能會出於非惡意的目的對模型進行微調,例如改進他們的服務,但這個過程可能會刪除插入的指紋。
幸運的是,Sentient聲稱微調對指紋的數量沒有顯著影響。 Sentient使用Alpaca指令調校資料集進行了微調實驗,結果證實指紋對微調仍具有相當程度的抵抗力。
即使插入的指紋少於2048個,也有超過50%的指紋被保留下來,而且插入的指紋越多,在微調中留存下來的就越多。此外,模型的效能下降小於5%,顯示插入多個指紋對微調攻擊有足夠的抵抗力。
●攻擊3:聯合攻擊
聯合攻擊與其他攻擊的不同之處在於,多個模型主機合作來中和指紋。有一類聯合攻擊涉及共享相同模型的模型主機,只有當所有主機對特定輸入提供相同的答案時才使用回應。
這種攻擊之所以有效,是因為插入到每個模型主機模型中的指紋是不同的。如果驗證者使用指紋金鑰向特定的模型主機發送請求,則主機將其回應與其他主機的回應進行比對,只有在回應相同時才回傳回應。此方法允許主機識別驗證者何時查詢它並避免被發現違規。
根據Sentient白皮書,大量的指紋和不同模型的謹慎分配可以幫助識別哪些模型參與了聯合攻擊。
3、Sentient協議
(1)目的
Sentient涉及各方參與者,包括模型所有者、模型主機、最終用戶和Prover。 Sentient協定在沒有集中實體控制的情況下管理這些參與者的需求。
協議管理除OML格式之外的所有事,包括追蹤模型使用情況、分發獎勵、管理模型存取以及針對違規行為的抵押品罰沒。
(2)結構
Sentient協定由四層組成:儲存層、分配層、存取層、激勵層。每層作用如下:
●儲存層:儲存AI模型並追蹤微調模型的版本。
●分配層:接收來自模型擁有者的模型,將它們轉換為OML格式,並將它們交付給模型主機。
● 存取層:管理Permission String,驗證來自Prover的使用證明,並追蹤模型使用情況。
● 激勵層:分配獎勵並管理模型的治理。
(3)為什麼要使用區塊鏈?
並非這些層中的所有操作都是在鏈上實現的,有些操作是在鏈下處理的。然而,區塊鏈是Sentient協議的支柱,主要是因為它可以輕鬆執行以下操作:
● 修改和轉移模式所有權
● 分配獎勵以及罰沒抵押品
● 透明的使用追蹤與所有權記錄
4、結論
我已盡量簡明扼要地介紹Sentient,只關注最重要的幾個面向。
綜上所述,Sentient是一個旨在保護開源AI模型智慧財產權的平台,同時確保公平的收入分配。 OML格式結合閉源和開源AI模型的優勢這一做法是非常有趣的,但由於我本人並非開源AI模型開發人員,我很好奇真正的開發人員將如何看待Sentient。
我也很想知道,早期,Sentient將使用什麼GTM策略來吸引廣大的開源AI模型builder。
Sentient的角色是幫助生態系統平穩運行,但它需要許多模型所有者和模型主機的參與才能成功。
顯而易見的策略可能包括開發自己的第一方開源模型,投資早期的人工智慧新創公司、孵化器或黑客松。但我很想看到他們能否想出更多創新的方法。