
原文標題:From prediction markets to info finance
作者:Vitalik,以太坊創辦人;編譯:0xjs@金色財經
最讓我興奮的以太坊應用之一是預測市場。 2014年,我寫了一篇關於futarchy 的文章,這是Robin Hanson 所構想的一個基於預測的治理模式。早在2015 年,我就是Augur的活躍用戶和支持者(看,我的名字在維基百科文章中)。我在2020 年大選投注中賺了58,000 美元。今年,我一直是Polymarket 的密切支持者和追隨者。
對許多人來說,預測市場就是對選舉下注,而對選舉下注就是賭博——如果它能讓人們享受樂趣,那就太好了,但從根本上講,它並不比在pump.fun上購買隨機代幣更有趣。從這個角度來看,我對預測市場的興趣似乎令人困惑。因此,在這篇文章中,我旨在解釋這個概念讓我興奮的原因。簡而言之,我相信(i) 即使現存的預測市場對世界來說也是一個非常有用的工具,但此外(ii)預測市場只是一個更大、非常強大的類別的一個例子,它有潛力創造更好的社群媒體、科學、新聞、治理和其他領域的實現。我將把這個類別稱為「資訊金融(info finance)」。
Polymarket的兩面性:為參與者提供的押注網站,為其他所有人提供的新聞網站
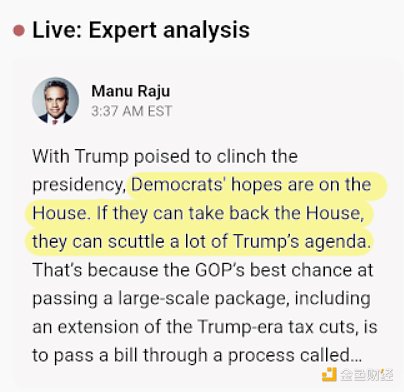
在過去的一周中,Polymarket 一直是有關美國大選的非常有效的資訊來源。 Polymarket 不僅預測川普獲勝的幾率為60/40(而其他消息來源的預測為50/50,這本身並不太令人印象深刻),還展示了其他優點:當結果出來時,儘管許多專家和新聞來源一直在引誘觀眾,希望他們能聽到對哈里斯有利的消息,但Polymarket 卻直接揭示了真相:川普獲勝的幾率超過95%,同時奪取所有政府部門控制權的幾率超過90% 。

兩張截圖皆拍攝於美國東部時間11月6日凌晨3:40
但對我來說,這甚至不是Polymarket 有趣的最佳例子。所以讓我們來看另一個例子:7 月委內瑞拉的選舉。選舉結束後的第二天,我記得眼角餘光看到有人在抗議委內瑞拉被高度操縱的選舉結果。起初,我沒怎麼在意。我知道馬杜羅已經是那些「基本上是獨裁者」的人物之一,所以我想,他當然會偽造每一次選舉結果以保住自己的權力,當然會有人抗議,當然抗議會失敗——不幸的是,許多其他人都失敗了。但後來我在Polymarket 上滾動瀏覽時,看到了這個:

人們願意投入十多萬美元,打賭馬杜羅在這次選舉中被推翻的可能性為23%。 現在我開始關注了。
當然,我們知道這種情況的不幸結果。最終,馬杜羅確實繼續掌權。然而,市場讓我意識到,這一次,推翻馬杜羅的企圖是認真的。抗議活動規模龐大,反對派出了一個出人意料地執行良好的策略,向世界證明了選舉是多麼的欺詐。如果我沒有收到Polymarket 最初的信號“這次,有些事情值得關注”,我什至不會開始關注。
你永遠不應該完全相信Polymarket押注圖表:如果每個人都相信押注圖表,那麼任何有錢的人都可以操縱押注圖表,沒有人敢跟他們打賭。另一方面,完全相信新聞也是個壞主意。新聞有煽情的動機,為了點擊量而誇大任何事情的後果。有時候,這是合理的,有時則不然。如果你看到一篇聳人聽聞的文章,但隨後你去市場發現相關事件的機率根本沒有改變,那麼懷疑也是有道理的。或者,如果你看到市場上意外的高或低機率,或是意外的突然變化,那就是一個訊號,讓你通讀新聞,看看是什麼原因造成的。 結論:與單獨閱讀其中任何一種相比,透過閱讀新聞和押注圖表,你可以獲得更多資訊。
讓我們回顧一下這裡發生的事情。如果你是博彩玩家,那麼你可以向Polymarket 押注,對你來說,這是一個博彩網站。如果你不是博彩玩家,那麼你可以閱讀押注圖表,對你來說,這是一個新聞網站。你永遠不應該完全相信押注圖表,但我個人已經將閱讀押注圖表作為我資訊收集工作流程中的一個步驟(與傳統媒體和社交媒體一起),它幫助我更有效地獲取更多資訊。
資訊金融更廣泛的意義
現在,我們進入重要部分:預測選舉結果只是第一個應用。更廣泛的概念是,你可以使用金融作為一種協調激勵機制的方式,以便為觀眾提供有價值的資訊。現在,一個自然的反應是:難道所有金融根本上不是都與資訊有關嗎? 不同的參與者會做出不同的買賣決策,因為他們對未來會發生什麼有不同的看法(除了個人需求,如風險偏好和對沖願望),你可以透過閱讀市場價格來推斷出許多關於世界的知識。
對我來說,資訊金融就是這樣,但結構上是正確的。與軟體工程中結構上正確的概念類似,資訊金融是一門學科,它要求你(i) 從你想知道的事實開始,然後(ii) 刻意設計一個市場,以最佳方式從市場參與者那裡獲取該資訊。

資訊金融是一個三邊市場:投注者做出預測,讀者閱讀預測。市場將對未來的預測作為公共物品輸出(因為這是它被設計的目的)。
預測市場就是一個例子:你想知道未來會發生的某個具體事實,所以你設立了一個市場讓人們押注這個事實。另一個例子是決策市場:你想知道根據某個指標M,決策A 和決策B 哪一個會產生更好的結果。為了實現這一點,你設立了條件市場:你要求人們押注(i) 會選擇哪個決策,(ii) 如果選擇決策A,則得到M 的值,否則為零,(iii) 如果選擇決策B,則得到M 的值,否則為零。有了這三個變量,你就可以確定市場是否認為決策A 或決策B 對得到M 的值更有利。

我預計,未來十年將推動資訊金融發展的一項技術是AI(無論是大模型還是未來的技術)。這是因為資訊金融的許多最有趣的應用都與「微觀」問題有關:數百萬個小型市場,這些市場中的決策單獨來看影響相對較小。實際上,交易量低的市場通常無法有效運作:對於經驗豐富的參與者來說,花時間進行詳細分析只是為了獲得幾百美元的利潤是沒有意義的,許多人甚至認為,如果沒有補貼,這樣的市場根本無法運作,因為除了最龐大和最轟動的問題之外,沒有足夠多的幼稚交易者讓經驗豐富的交易者從中獲利。 AI完全改變了這個等式,這意味著即使在交易量為10 美元的市場上,我們也有可能獲得相當高品質的資訊。即使需要補貼,每個問題的補貼金額也變得非常實惠。
資訊金融需要人類的蒸餾(distilled)
判斷
假設你有一個值得信賴的人工判斷機制,並且該機制具有整個社區信任它的合法性,但做出判斷需要很長時間和高成本。但是,你希望以低成本即時存取該「昂貴機制」的至少一個近似副本。以下是Robin Hanson 提出的你可以做的事情的想法:每次你需要做出決定時,你都會建立一個預測市場,預測如果調用該昂貴機制,該機制將對決定做出什麼結果。你讓預測市場運行,並投入少量資金補貼做市商。
99.99% 的時間裡,你實際上並不會調用昂貴的機制:也許你會「撤銷交易」並返還每個人的投入,或者你只是給每個人零,或者你看看平均價格是否更接近0 或1 並將其視為基本事實。 0.01% 的時間- 可能是隨機的,可能是針對交易量最大的市場,可能是兩者的結合- 你實際上會運行昂貴的機制,並據此補償參與者。
這為你提供了一個可信、中立、快速且廉價的“蒸餾版本”,該版本是你原來高度可信但成本極高的機制(使用“蒸餾”一詞類比LLM 中的“蒸餾distilled”) 。隨著時間的推移,這種蒸餾機制大致反映了原始機制的行為- 因為只有幫助實現該結果的參與者才能賺錢,而其他人則會賠錢。

可能的預測市場+ 社區筆記組合的模型。
這不僅適用於社群媒體,也適用於DAO。 DAO的一個主要問題是,決策數量太多,大多數人都不願意參與其中,這導致要么廣泛使用委託,存在代議制民主中常見的中心化和委託代理失靈的風險,要么容易受到攻擊。如果DAO 中實際投票很少發生,大多數事情都由預測市場決定,由人類和AI結合預測投票結果,那麼這種DAO 可能會運作良好。
正如我們在決策市場的例子中所看到的,資訊金融蘊含著許多解決去中心化治理中重要問題的潛在路徑,關鍵在於市場與非市場的平衡:市場是“引擎”,其他一些非金融化的信任機制是「方向盤」。
資訊金融的其他用例
個人代幣——諸如Bitclout(現為deso)、friend.tech等許多為每個人創建代幣並使其易於投機的項目——是我稱之為“原始信息金融”的一類。他們故意為特定變數(即對一個人未來聲望的期望)創造市場價格,但價格所揭示的確切訊息過於模糊,並且受制於反身性和泡沫動態。有可能創建此類協議的改進版本,並透過更謹慎地考慮代幣的經濟設計(尤其是其最終價值來自何處)來解決人才發現等重要問題。 Robin Hanson的聲望期貨概念是這裡的一種可能的最終狀態。
廣告-最終的「昂貴但值得信賴的訊號」是你是否會購買產品。基於該訊號的資訊金融可用於幫助人們確定要購買什麼。
科學同行評審——科學界一直存在“復現危機”,即某些著名結果在某些情況下已成為民間智慧的一部分,但最終卻無法在新研究中再現。我們可以嘗試透過預測市場來確定需要重新檢查的結果。在重新檢查之前,這樣的市場還會讓讀者快速估計他們應該在多大程度上信任任何特定結果。這種想法的實驗已經完成,到目前為止似乎取得了成功。
公共財資助-以太坊使用的公共物品資助機制的主要問題之一是其「人氣競賽」性質。每個貢獻者都需要在社群媒體上進行自己的行銷活動才能獲得認可,而那些沒有能力做到這一點或天生具有更多「背景」角色的貢獻者很難獲得大量資金。一個有吸引力的解決方案是嘗試追蹤整個依賴關係圖:對於每個積極結果,哪些項目對其貢獻了多少,然後對於每個項目,哪些項目對其貢獻了多少,等等。這種設計的主要挑戰是找出邊緣的權重,使其能夠抵抗操縱。畢竟,這種操縱一直在發生。蒸餾的人類判斷機制可能會有所幫助。
結論
這些想法已經被理論化了很長一段時間:關於預測市場甚至決策市場的最早著作已有數十年歷史,而金融理論的類似論述則更為古老。然而,我認為,當前十年提供了一個獨特的機會,主要原因如下:
資訊金融解決了人們實際上存在的信任問題。這個時代的一個共同擔憂是缺乏知識(更糟的是缺乏共識),不知道在政治、科學和商業環境中應該信任誰。資訊金融應用可以幫助成為解決方案的一部分。
我們現在有了可擴展的區塊鏈作為基礎。直到最近,費用還太高,無法真正實現這些想法。現在,它們不再太高了。
AI作為參與者。當資訊金融必須依靠人類參與每個問題時,它相對難以發揮作用。 AI大大改善了這種情況,即使在小規模的問題上也能實現有效的市場。許多市場可能會有AI和人類參與者的組合,特別是當特定問題的數量突然從小就變成大時。
為了充分利用這個機會,我們應該超越僅僅預測選舉,探索資訊金融還能為我們帶來什麼。
特別感謝Robin Hanson 和Alex Tabarrok 的回饋和評論