引言
去中心化AI雖然有許多優勢,但也面臨不少風險與挑戰。作為這個系列的第三篇文章,本文將為您分析這些挑戰,並展望去中心化AI的未來發展方向。
我們也歡迎這個方向的創業者和專案方與我們聯繫。
AI Agent的發展機遇
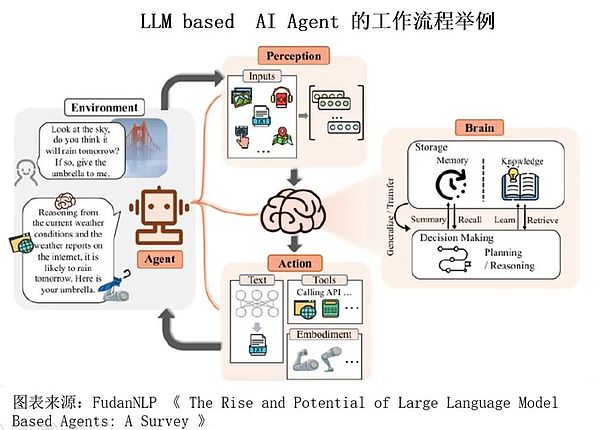
AI Agent是大模型的自然進化,透過引入記憶機制、任務分解和規劃能力,AI Agent能夠感知環境、自主決策並執行複雜任務。

現有的大模型雖然能夠產生文字並解決問題,但仍不具備完整的任務規劃和執行能力。 AI Agent將補足此缺陷,提升AI在複雜任務中的表現。
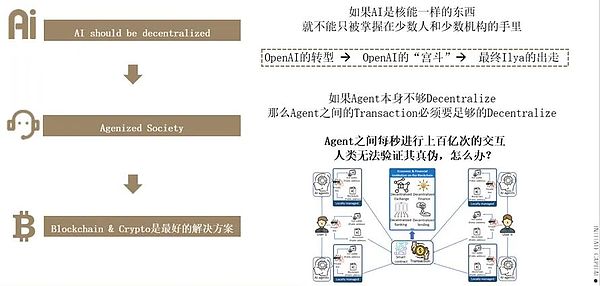
如果說AI是核能,那麼它不應該只掌握在少數人手中。去中心化的AI Agent將透過區塊鏈和加密技術,確保AI技術的公平性和透明性。
在未來的代理社會中,去中心化的AI將成為必然趨勢,以解決現有集中化AI系統面臨的問題。
數據標註的發展機會:
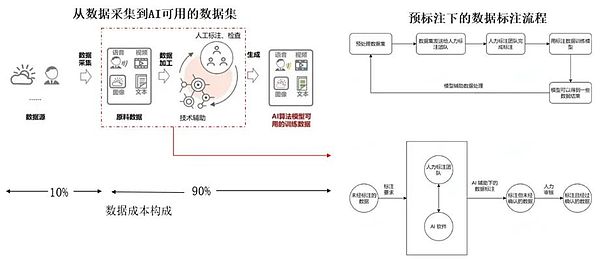
資料準備包括資料收集、清洗、標註和增強,AI對資料的多樣化需求增加了對高精度和強定制的資料標註的依賴,資料標註冗長的工作週期和高昂的人力成本限制了AI產業的發展。
Web3可透過經濟激勵機制,接觸到大量的全球各地區的AI資料收集和標註工作人員,能夠讓其從數據貢獻中獲得收益。
案例:數據交易市場Ocean Protocol
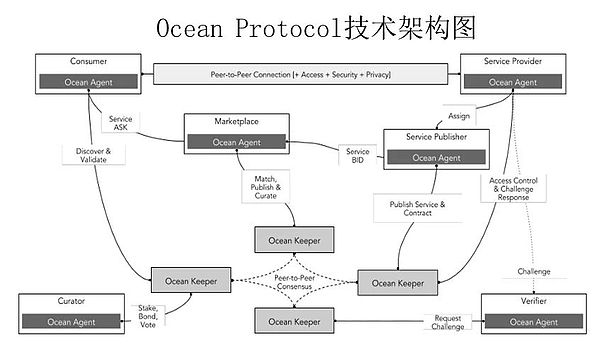
運作機制
• 提供者(Providers):資料提供者可以發行和出售自己的資料通證,從而獲得收入。
• 消費者(Consumers):購買或賺取所需的資料通證,從而獲得存取權。
• 市場(Marketplaces):指由Ocean Protocol 或第三方提供的一個開放、透明和公平的資料交易市場,它可以連接全球範圍內的提供者和消費者,並提供多種類型和領域的資料通證。
• 網路(Network):指由Ocean Protocol 提供的一個去中心化的網路層。
• 策展人(Curator):指一個生態系統中負責篩選、管理、審核資料集的角色,他們負責審核資料集的來源、內容、格式和許可證等方面的信息,以確保資料集符合標準,並且可以被其他使用者信任使用。
• 驗證人(Verifier):指一個生態系中負責驗證、審核資料交易、資料服務的角色。
總結:AI Agent和去中心化資料標註是DeAI目前比較熱門的兩個方向,也有很多創業團隊在這其中進行開發。
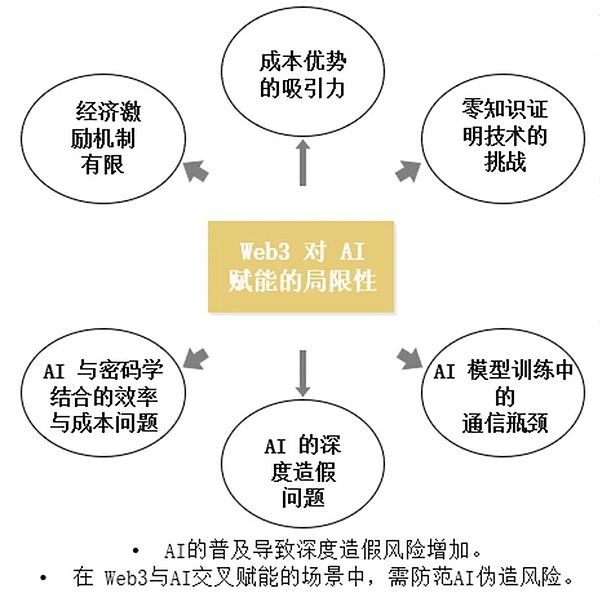
去中心化AI面臨的風險與挑戰
-
Web3對AI賦能的限制:由於Web3加密使用者數量有限,經濟誘因機制的輻射範圍較小。這限制了去中心化AI的快速發展,需要更多的使用者參與和接受度。
-
零知識證明技術的挑戰:量化精準度、硬體需求和對抗性攻擊等問題。零知識證明技術(ZKP)在實現模型的可驗證性方面具有長遠意義,但目前仍面臨技術難題和實施挑戰。
-
成本優勢的吸引力:如果市場上算力資源供應得到緩解,去中心化算力網路的價值和成本優勢將會被削弱。這要求去中心化AI不斷提高效率和降低成本,以保持其競爭力。
-
AI與密碼學結合的效率與成本問題:使用零知識證明技術或完全同態加密(FHE)技術執行隱私計算任務的效率遠低於明文執行。由於AI計算需求高,加入密碼技術將進一步提高成本,可能難以實際落地。
-
AI的深度造假問題:AI模型訓練中的通訊瓶頸問題顯著。頻繁交換模型參數和梯度資訊會消耗大量網路頻寬,產生高通訊開銷。同時,各節點的同步問題也會對訓練結果產生影響,需要頻繁的資料校驗和同步操作。
-
AI的普及導致深度造假風險增加。在Web3與AI交叉賦能的場景中,需防範AI偽造風險。

去中心化AI未來發展的方向
模型層:隨著AI Agent變得更加普遍,未來使用者將依靠AI Agent來幫助自己完成任務,是連接模型層和應用層的鑰匙。模型的多樣化平台逐步形成,大模型成本不斷下降,跑出「黑馬級」應用仍然需要時間。
訓練層:去中心化訓練AI 模型存在實現的可能性,但由於推理需求遠大於訓練需求,訓練層會更依賴集中式算力。
算力層:去中心化算力有效降低GPU使用成本,企業級GPU符合目前算力需求。未來端側模型落地,消費類GPU將有用武之地。
資料層:公開資料取得難度越來越大,去中心化的資料收集和資料標註將成為未來AI模型資料來源和處理的重要途徑。
結語
去中心化AI作為一種新興的技術趨勢,雖然道路充滿挑戰,但其發展潛力巨大。隨著技術的不斷進步和市場的逐步成熟,去中心化AI有望在未來發揮更大的作用。我們需要持續關注這些挑戰,並尋找創新的解決方案,以推動去中心化AI的發展。在這個其中,我們認為在模型、訓練、資料、算力四個層面,去中心化AI都有其用武之地,尤其是DeAI是一個最可見,且最能產生價值的方向之一。