作者|Sid @IOSG
Web3 遊戲的現狀
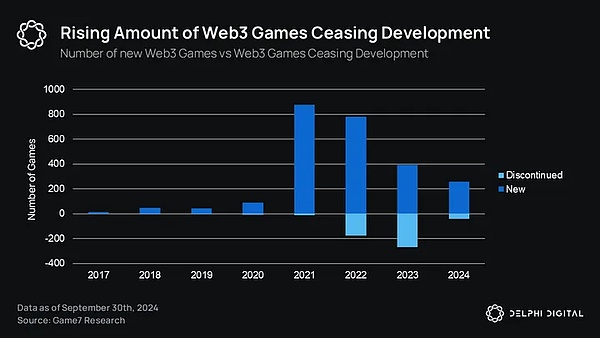
隨著更新穎更具注意力的敘事方式的出現,Web3 遊戲作為一個產業在一級和公開市場的敘事都退居其次。根據Delphi 2024 年關於遊戲產業的報告,Web3 遊戲在第一級市場的累積融資額不足10 億美元。這並不一定是壞事,這只是表明泡沫已經消退,現在的資本可能正在向更高品質的遊戲相容。下圖就是一個明顯的指標:
在整個2024 年,Ronin 等遊戲生態系統的用戶數量大幅飆升,而且由於Fableborn 等高品質新遊戲的出現,幾乎媲美2021 年Axie 的輝煌時期。
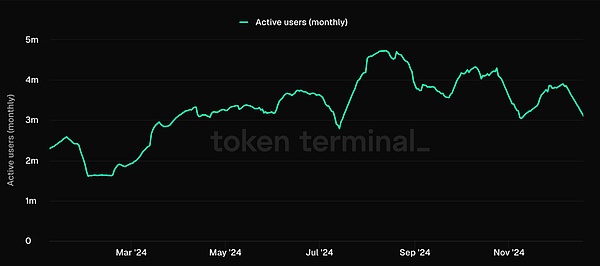
遊戲生態系統(L1s、L2s、RaaS)越來越像Web3 的Steam,它們掌控著生態系統內的分發,這也成為遊戲開發商在這些生態系統中開發遊戲的動力,因為這可以幫助他們獲取玩家。根據他們先前的報告,Web3 遊戲的用戶獲取成本比Web2 遊戲高出約70%。
玩家黏性
留住玩家與吸引玩家同樣重要,甚至更重要。雖然缺乏Web3 遊戲玩家留存率的數據,但玩家留存率與「Flow」的概念(匈牙利心理學家Mihaly Csikszentmihalyi 提出的術語)密切相關。
「流狀態」是一種心理學概念,在這種狀態下,玩家在挑戰和技能水平之間達到了完美的平衡。這就像「進入狀態」——時間似乎過得很快,你完全沉浸在遊戲中。
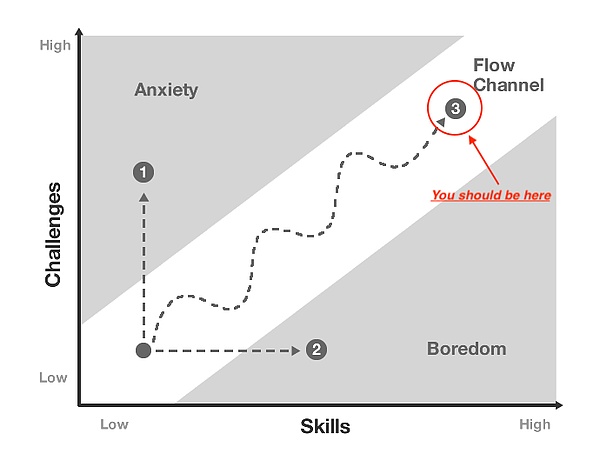
持續創造流狀態的遊戲往往具有更高的留存率,原因在於以下機制:
#進階設計
遊戲初期:簡單挑戰,建立信心
遊戲中期:逐漸增加難度
遊戲後期:複雜挑戰,精通遊戲
隨著玩家技能的提高,這種細緻的難度調整可讓他們保持在自己的節奏範圍內
#參與循環
短期:即時回饋(擊殺、積分、獎勵)
中期:關卡完成、每日任務
長期:角色發展、排名
這些嵌套循環可在不同時間範圍內維持玩家的興趣
#破壞流狀態的因素則為:
1. 難度/複雜度設定不當:這可能是由於糟糕的遊戲設計,甚至可能是由於玩家數量不足而導致的配對失衡
2. 目標不明確:遊戲設計因素
3. 回饋延遲:遊戲設計與技術問題因
4. 侵入式貨幣化:遊戲設計+產品
5. 技術問題/滯後

遊戲與AI 的共生
AI agents 可以幫助玩家獲得這種流狀態。在探討如何實現這一目標之前,讓我們先來了解一下什麼樣的代理適合運用到遊戲領域:
LLM 與強化學習
代理和NPC
遊戲AI 的關鍵在於:速度和規模。在遊戲中使用LLM 驅動的代理程式時,每個決策都需要呼叫龐大的語言模型。這就好比在踏出每一步之前都要有一個中間人。中間人很聰明,但等待他的回應會讓一切變得緩慢痛苦。現在想像一下,在遊戲中為數百個角色做這樣的工作,不僅速度慢,而且成本很高。這就是我們尚未在遊戲中看到大規模LLM 代理的主要原因。我們目前看到的最大實驗是在Minecraft 上開發的1000 個代理的文明。如果在不同的地圖上有10 萬個並發代理,這將會非常昂貴。由於每增加一個新代理都會導致延遲,玩家也會受到流量中斷的影響。這就破壞了流狀態。
強化學習(RL)是一種不同的方式。我們把它想像成訓練一個舞者,而不是透過耳麥給對方手把手的指導。透過強化學習,你需要在前期花時間教導AI 如何“跳舞”,以及如何應對遊戲中的不同情況。一旦訓練有素,AI 就會自然流暢,在幾毫秒內做出決定,而無需向上請求。你可以讓數百個這樣訓練有素的代理商在你的遊戲中運行,每個代理商都能根據自己的所見所聞獨立做出決定。他們不像LLM 代理那樣能言善道或靈活機動,但他們做事快速有效率。
當你需要這些代理商協同工作時,RL 的真正魔力就顯現出來了。 LLM 代理需要冗長的「對話」來協調,而RL 代理則可以在訓練中形成一種隱性的默契——就像一支一起訓練了數月的橄欖球隊。他們學會預測對方的動作,自然而然地進行協調。當這並不完美,有時它們會犯一些LLM 不會犯的錯誤,但它們可以在LLM 無法比擬的規模上運作。對於遊戲應用來說,這種權衡總是有意義的。
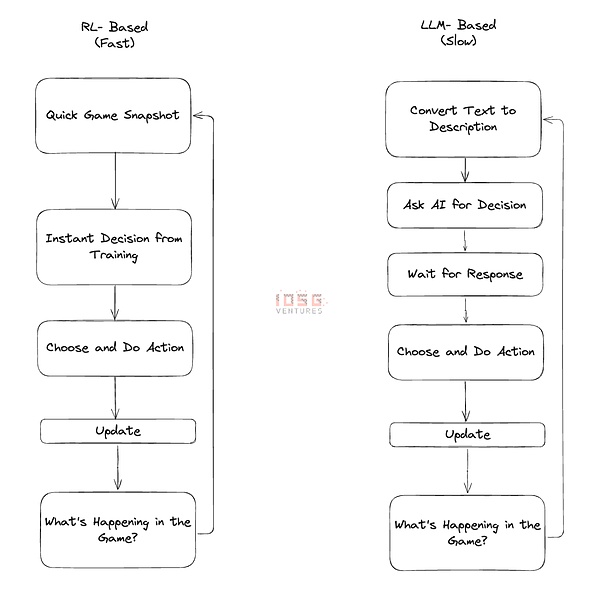
LLM 與強化學習
代理和NPC
身為NPC 的代理人將解決當今許多遊戲面臨的第一個核心問題:玩家流動性。 P2E 是第一個使用密碼經濟學解決玩家流動性問題的實驗,我們都知道結果如何。
預先訓練好的代理有兩個作用:
-
填充多人遊戲中的世界
-
維持世界中一組玩家的難度水平,使他們處於流動狀態
雖然這看起來非常明顯,但建造起來卻很困難。獨立遊戲和早期的Web3 遊戲沒有足夠的財力聘請人工智慧團隊,這為任何以RL 為核心的代理框架服務商提供了機會。
遊戲可以在試玩和測試期間與這些服務提供者合作,為遊戲發佈時的玩家流動性奠定基礎。
如此一來,遊戲開發者就可以把主要精力放在遊戲機制上,讓他們的遊戲更加有趣。儘管我們喜歡將代幣融入遊戲,但遊戲終究是遊戲,遊戲應該是有趣的。
代理玩家
元宇宙的回歸?
世界上玩家最多的遊戲之一《英雄聯盟》有一個黑市,玩家在黑市上用最好的屬性訓練自己的人物,而遊戲禁止他們這樣做。
這有助於形成遊戲角色和屬性作為NFT 的基礎,從而創建一個市場來實現這一點。
如果出現一個新的「玩家」子集,作為這些人工智慧代理的教練呢?玩家可以指導這些人工智慧代理,並以不同的形式將其貨幣化,例如贏得比賽,還可以充當電競選手或熱情玩家的「訓練夥伴」。
LLM 與強化學習
元宇宙的回歸?
元宇宙的早期版本可能只是創造了另一個現實,而不是理想的現實,因此沒有達到目標。 AI agents 幫助元宇宙居民創造一個理想世界— 逃離。
在我看來,這正是基於LLM 的代理可以大顯身手的地方。也許有人可以在自己的世界中加入預先訓練好的代理,這些代理都是領域專家,可以就他們喜歡的事物進行對話。如果我創建了一個經過1000 小時Elon Musk 訪談訓練的代理,而用戶希望在他們的世界中使用這個代理的實例,那麼我就可以為此獲得獎勵。這樣就能創造新的經濟。
有了Nifty Island 這樣的元宇宙遊戲,這就可以成為現實。
在Today: The Game 中,團隊已經創建了一個基於LLM 的AI agent,名為“Limbo”(發布了投機性代幣),其願景是多個代理在這個世界中自主互動,同時我們可以觀看24×7的直播串流。

Crypto 如何與之融合?
Crypto 可以透過不同方式幫助解決這些問題:
-
玩家貢獻自己的遊戲數據,以改進模型,獲得更好的體驗,並因此獲得獎勵
-
協調角色設計師、訓練師等多方利害關係人,創造出最好的遊戲內代理
-
創建一個擁有遊戲內代理所有權的市場,並將其貨幣化
有一個團隊正在做這些事情,而且做得更多:ARC Agents。他們正在解決上面提到的所有問題。
他們擁有ARC SDK,允許遊戲開發人員根據遊戲參數創建類似人類的人工智慧代理。透過非常簡單的集成,它就能解決玩家流動性問題,清理遊戲數據並將其轉化為見解,還能透過調整難度等級來幫助玩家在遊戲中保持流動狀態。為此,他們使用了強化學習(Reinforcement Learning)技術。
他們最初開發了一款名為「AI 競技場」(AI Arena)的遊戲,在這款遊戲中,基本上是在訓練你的AI 角色進行戰鬥。這幫助他們形成了一個基準學習模型,該模型構成了ARC SDK 的基礎。這就形成了某種類似DePIN 的飛輪:
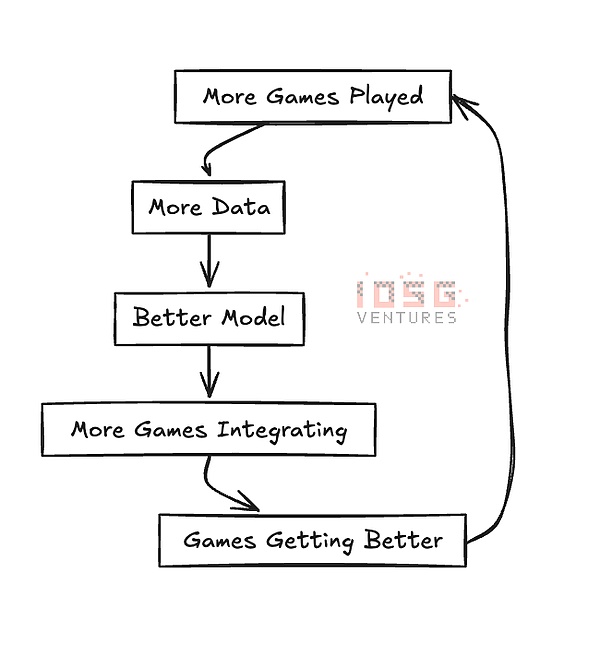
所有這一切都以他們的生態系統代幣$NRN 作為協調。 Chain of Thought 團隊在他們關於ARC 代理商的文章中對此做了很好的解釋:
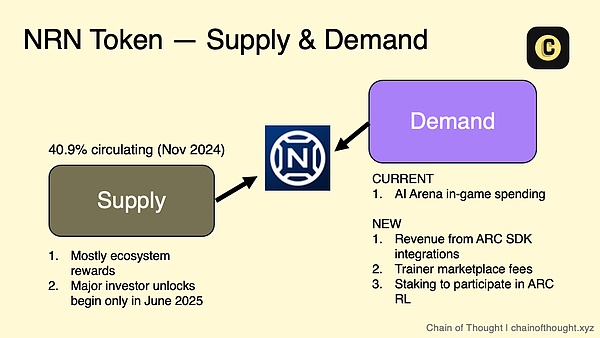
像Bounty 這樣的遊戲正採取agent-first 的方法,在一個狂野的西部世界中從頭開始建立代理。

結語
AI agents、遊戲設計和Crypto 的融合不僅僅是另一種技術趨勢,它還有可能解決困擾獨立遊戲的各種問題。 AI agents 在遊戲領域的妙處在於,它們增強了遊戲的樂趣所在——良好的競爭、豐富的互動,以及讓人流連忘返的挑戰。隨著ARC 代理商等框架的成熟和更多遊戲整合AI agents,我們很可能會看到全新的遊戲體驗出現。想像一下,世界之所以充滿活力,並不是因為裡面有其他玩家,而是因為裡面的代理人能夠與社群一起學習和進化。
我們正在從一個「play-to-earn」轉向一個更令人興奮的時代:既富含真正的樂趣,又可無限擴展的遊戲。對於關注這一領域的開發者、玩家和投資者來說,未來幾年將非常精彩。 2025 年及以後的遊戲不僅在技術上更加先進,而且從根本上講,它們將比我們以前看到的任何遊戲都更吸引人、更易於參與、更有生命力。