
分佈式搜索引擎的未來一定是穩步前進的,但其落地絕對不是靠炒token實現的,而是項目方匠心打造的生態,這其中包括索引獎勵、隱私計算、邊緣計算等一系列技術的疊加以及Dapp的興起。
一、痛點的背後是創新的空間
關於分佈式搜索引擎,現在大家都怎麼看呢?達瓴看到有說是Web3.0數據價值轉換的重要板塊的,也有說中心化搜索引擎不夠中立、數據洩露、數據丟失等問題,進而突出分佈式優勢的。但是說實話,單純去比較分佈式和中心化搜索引擎的好和壞,其實意義不大。
因為就目前的應用價值來看,中心化搜索引擎的應用價值肯定是比分佈式搜索引擎大很多,這是由時間積累所決定的。想要通過技術研發的突破就去替代某些中心化巨頭引擎,顯然是不現實的。
但畢竟中心化搜索引擎存在諸多缺點,所以當人們開始思考有沒有辦法去做一些改變時,就一定會創新出一種能彌補中心化缺點的搜索引擎——分佈式搜索引擎。
二、分佈式搜索引擎的第一步必須是“存數據”,還得是“有效數據”
由此從創新價值的角度來看,討論分佈式與中心化搜索引擎的對比是有必要的。但最終想要落地,還是要殊途同歸,分佈式還是要向中心化“學習”,該落地的步驟一個也不能少。
那麼,這第一步怎麼走呢?可能很多人會直接搬出IPFS和HTTP的優缺點對比,告訴大家IPFS能降低存儲成本、加快網絡訪問速度、保障數據安全,一定要應用IPFS。但是要知道HTTP已經存在20餘年,其背後存儲的文件數量要遠遠超出IPFS。即使目前在IPFS上存儲的數量文件已超過50億份,這個數據的懸殊也絕對不是一兩年就能追上的。
而對於搜索用戶來說,能夠快速得到想要的結果才是第一位,偶爾“犧牲”下隱私對他們看來是無關痛癢的,若是連一點數據搜不到,哪裡還來談分佈式呢? HTTP不香嗎?
所以,分佈式搜索引擎的第一步必須是““存數據”,而且還得是“有效數據”!這就很好地解釋了為什麼分佈式存儲的項目要比搜索引擎快一步落地呢?畢竟相比起怎麼設計算法能讓用戶快速查到內容,有內容給查才是基本。
由於我國傳統上通信網絡主要圍繞人口聚集程度進行建設,因此我國的數據中心是集中於東部城市部署的。但近年來,隨著數據中心規模快速擴張,對土地供應、能源保障、氣候條件都提出了更高要求,現有的城市資源,尤其是東部一線城市資源,已難以滿足持續發展要求。
2021年5月26日,國家發展改革委、中央網信辦、工業和信息化部、國家能源局聯合印發《全國一體化大數據中心協同創新體系算力樞紐實施方案》,明確提出佈局全國算力網絡國家樞紐節點,啟動實施“東數西算”工程,構建國家算力網絡體系。
在這樣的背景下,分佈式存儲能從架構上解決了數據存儲的安全問題,並能減少能源消耗,完全是助力“東數西算”工程的好幫手!因此達瓴相信分佈式存儲的數據一定會越來越充足,這會是必然的結果。
可是,分佈式存儲不能因為技術等優勢就乾等著數據送到嘴裡,主動去設計激勵手段,不斷創建新的生態,才能加速實現國家數據安全的建設。這樣看來,存數據的“球”現在傳到了激勵層的腳下,怎麼做好激勵,怎麼建好生態,成為分佈式項目能否落地的關鍵。
有些項目直接一來就用token獎勵用戶去剛剛搭建好的搜索界面搜索,以擴充數據。但此時搜索到的大部分還是HTTP打頭的中心化網頁,少部分存在的IPFS的網頁可能無法滿足搜索需求。更多項目還是以獎勵存儲數據的用戶為主,存儲商戶也能通過機器P盤數據獲得token獎勵,以此實現良性循環。
但俗話說得好,想像總是美好的,現實總是殘酷的。雖說任何生態都需要token做支撐,但是為了這個目的才去建設生態的項目比比皆是。大家還沒有開始用token築起生態,就開始按捺不住,先玩起token的金融價值,想著賺波快錢。
所以說,如果能將設計的激勵層和生態共同促進,就是掌握了此類項目成功的部分關鍵要素。
三、生態的核心——激勵機制
激勵模式一定是要有回流和循環的,token不能只是外送到一個地方後就固定了,沒有流轉的設計,token就很難實現它的價值。因此分佈式搜索的激勵層設計一定要合理,且肯定要比存儲項目考慮得更多,設計到的各方利益面也更複雜。
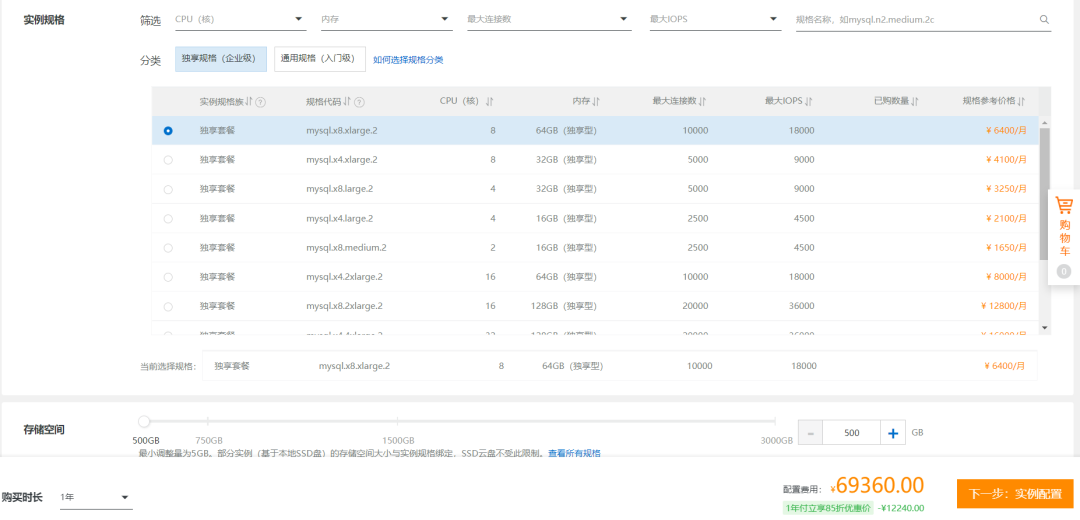
上文看來,激勵層首先就是要激勵用戶和存儲商戶去存儲數據,存了以後還需要存儲商戶及時打包上鍊,所以最開始的激勵力度肯定是要偏向於二者的。例如:傳統雲存儲的代表——阿里雲,據官網數據顯示,其對存儲商戶的收費=固定費用+數據大小(單位:GB)*倍數,達瓴估算該固定費用為65180元,倍數為8.25左右。
因此,在不考慮固定費用的情況下,存儲1GB的數據大約需要8.25元。緊接著派出分佈式存儲的代表——IPFS的激勵層Filecoin,據調查,每個FIL每天可以存儲約782.73GB的數據容量,折算下來存儲1GB的數據大約需要0.623元。
这样一对比就可以发现分布式项目在存储数据成本方面有着显著优势。更有项目加大力度,不仅不收取存储数据者的费用,反而奖励其token,以实现数据层的快速建设。
 數據來源:阿里雲RDS,數據統計截止8月18日
數據來源:阿里雲RDS,數據統計截止8月18日
除了針對用戶的存儲費用激勵,不少項目也獎勵token給打包數據的存儲商戶,以加速數據上鍊。比如最近主網即將上線的QitChain(QTC),基於Web3.0有效數據存儲的分佈式搜索引擎,以不同的網絡節點來存儲數據,防止丟失。
QTC在生態建設上就根據用戶搜索的關鍵詞,列出分佈式節點中的所有結果,中間不插入廣告,同時採用了加密技術,除非用戶會通知他人,對方才能擁有用戶的私人數據密鑰。因此用戶在QTC的生態裡可以完全控制自己的數據信息。
據QTC的官方白皮書顯示, 其通過設計長期激勵的經濟模型保證整個生態的良性發展,同時對現有POC 進行優化做出了一些改進,將其升級為CPOC(Conditioned-Proof of Capacity)共識,並增加了POS 權益激勵,可以增強社區共識度。
CPOC條件的發行方式會讓參與方的產生正向商業博弈,使整個系統始終會有一個較為主力的臨時商業既得利者去無形推動整個生態。
 數據來源:QTC微信公眾號,數據整理:達瓴智庫
數據來源:QTC微信公眾號,數據整理:達瓴智庫
四、搜索引擎的定位不同,有效數據的內容也不同
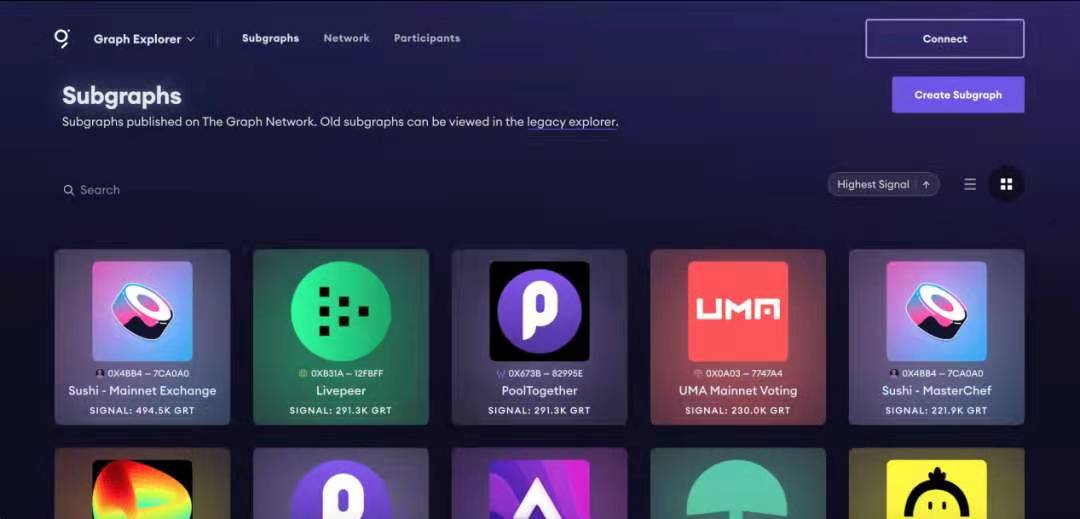
而且需要注意的是,不同的搜索項目聚焦的數據也是不同。例如:The Graph作為一個查詢區塊鏈數據的索引協議,允許使用查詢語言GraphQL查詢不同的網絡(以太坊或IPFS)。
在The Graph的資源管理器中,用戶可輕鬆查找最流行協議(如Uniswap,Compound,Balancer或ENS)的子圖,而子圖能提供對許多有用數據的訪問,比如說自協議啟動以來所有買賣對的總買賣量,每個買賣對的買賣量數據以及有關特定token或買賣的數據等。因此對它們來說,有效數據主要是由區塊鏈項目的各種數據分析和歷史數據組成的。
由此看來,搜索引擎的定位不同,有效數據的內容也不同。但是可以肯定的是,項目方需要重視有效數據在數據層中的重要作用,並在有效數據的數量與獎勵之間設定相關關係,以實現一個合理的數據區間。
總的來說,只有激勵層設計好了,數據這一層的基礎才能打好,再來走搜索就好走多了!
五、生態的流動——收益機制
如果數據有了,怎麼提供給用戶一個較好的搜索體驗,怎麼平衡用戶、廣告商和項目方的收益,是分佈式搜索引擎的另一關鍵。
在中心化搜索引擎下,我們的個人信息經常通過一些表單、記錄等方式被跟踪和記錄了,緊接著這些信息就被用於各種各樣的廣告活動。企業也要為此付出巨額的資金,才能在在線消費的產業中分得一杯羹。
此時的關係就如下圖所示,紅色箭頭為資金流動方向。可見在此生態下三方處於極不公平的地位,資金流動性一致偏向搜索引擎的項目方。
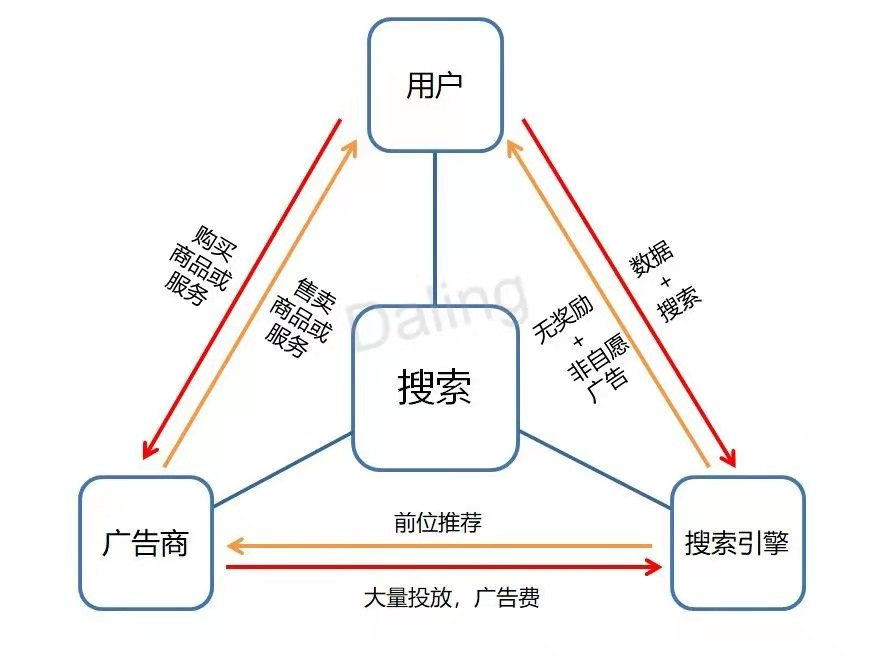 傳統搜索引擎的運行機制
傳統搜索引擎的運行機制
因此,若要讓分佈式搜索引擎長久發展下去,項目方需要開創新的生態環境。在這裡資金是流動循環的,用戶可以選擇開放自己的數據,並讓廣告商對這一數據進行投放,而廣告商所支付的廣告費將會與數據的所有人進行分成。在這樣的佈局下,三方都能有進有出,生態才得以建設起來。
這裡可以來看分佈式搜索引擎Boogle的設計。其規定一旦用戶選擇開放自己的數據,並讓廣告商對這一數據進行投放時,其所支付的廣告費用將會與數據的所有人進行分成。
在Boogle中,每個廣告點,會有10%的費用被分給用戶,僅15%直接支付給項目方,剩餘的通證則將全部轉入一個公開的銷毀地址。因此在這樣的設計中,資金流動性沒有偏向固定的一方,反而在不停的進行流轉,這才是搜索引擎該有的樣子!
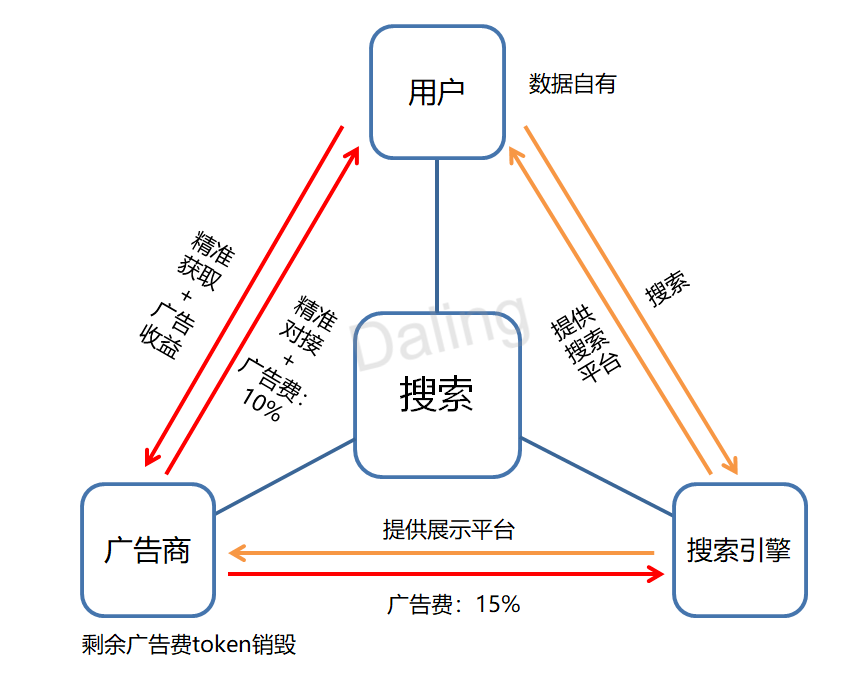 分佈式搜索引擎的運行機制
分佈式搜索引擎的運行機制
六、分佈式搜索的未來
其實一個好的分佈式搜索引擎還有許多方面需要注意,無論是對數據信息的篩選、審核,還是對用戶習慣的調試,亦或是未來在存儲、搜索的基礎上開拓更多的分佈式應用,例如:支付、通訊、郵件等等,這都需要項目方細細打磨。
我們相信:分佈式搜索引擎的未來一定是穩步前進的,但其落地絕對不是靠炒token實現的,而是項目方匠心打造的生態,這其中包括索引獎勵、隱私計算、邊緣計算等一系列技術的疊加以及Dapp的興起。希望大家能給予認真落地的分佈式搜索引擎項目足夠的信心和耐心,不要浮躁於token價格的起起伏伏,分佈式搜索引擎的未來將由大家一起創造和見證。
作者:Jessica丨達瓴智庫
校對:Jessica、Leaves丨達瓴智庫
排版:Jane、Shine 丨達瓴智庫
審核:Amber丨達瓴智庫
展開全文打開碳鏈價值APP 查看更多精彩資訊