數據正在逐漸成為關鍵生產要素,各產業對數據的需求也隨之不斷增長。
本文原載於《信息安全研究》2021年10期
莊媛媛靳晨華控清交信息科技(北京)有限公司
何昊青清華大學五道口金融學院
摘要:數據正在逐漸成為關鍵生產要素,各產業對數據的需求也隨之不斷增長。 2021年9月1日開始實施的«中華人民共和國數據安全法»,對國內信息和數據安全領域的普適性法律框架作了進一步完善.作為數據中最為特殊的一部分,個人信息在«中華人民共和國個人信息保護法»受到更加嚴格的保護. «個人信息保護法»中有關匿名化與去標識化的概念與歐盟相關規定類似,但亦有其不同之處.以歐美相關規定為起點,洞察歐美對匿名化相關概念的差異,評價其可操作性與值得借鑒之處.隨後,將我國相關規定與基於多方計算(Multi-party Computation,MPC)的數據交易場景進行結合, 分析目前匿名化與去標識化相關規定在適用上可能面臨的問題.最後,從個人信息保護與數據流通的角度,對匿名化與去標識化及其相關規定提出建議.關鍵詞匿名化; 去標識化; 假名化; 多方計算; 個人信息保護; 數據流通
1 匿名化相關規定對數據流通的意義
新一代信息技術的迅速發展,使得數據控制者(controller)對於數據主體(data subject)個人信息的收集、處理、利用的深度與廣度不斷加大.隨著數據控制者越發強勢,數據主體的權利顯得微不足道.為了消弭數據控制者與數據主體之間的權責失衡,保障個人信息能夠合理利用,各國紛紛出台了建立在“告知同意”框架下的個人信息保護相關法律法規,定義了匿名化等概念,並給出了相應的管理規定.各國對匿名化等相關術語的定義多有出入,寬嚴不一,但主要皆聚焦於信息能否“識別出特定個人”,其根本目的在於通過將特定個人“埋沒”於群體中,在“統計學意義上”保障個人隱私.在我國,“匿名化”“去標識化”“假名化”等原屬於技術概念的範疇,2021年出台的«中華人民共和國個人信息保護法»(以下簡稱«個保法»),定義了“去標識化”與“匿名化”,並將匿名化處理後的信息排除在«個保法»規制的範疇之外,至此“去標識化”與“匿名化”在我國已經成為法律概念.對於匿名化處理後的數據的豁免規定,歐盟的«通用數據保護條例»(General Data Protection Regulation, GDPR)將匿名化數據排除GDPR規制範疇; 美國«加利福尼亞州消費者隱私保護法案»(California Consumer Privacy Act, CCPA)將去標識化後且無法合理識別出特定個人的信息排除CCPA規制範疇,以上規定皆旨在平衡個人信息隱私保護與個人信息流通所能帶來利益之間的關係.從匿名化數據消除了數據集中個體顆粒度的角度來看,該方式確實能夠在一定程度上保障個人隱私,但還有以下問題亟待釐清:1)匿名化既是法律概念也是技術問題,是網絡安全、信息安全與數據保護的關鍵一環,需要考慮涉及數據上下游產業鏈對數據的利用情況,輔之以政策、法律法規、標準、內部管理制度;2)匿名化不是孤立的,數據鏈條上相關方的數據處理與保護能力各不相同,對於數據的顆粒度需求也不同,故需結合數據的實際使用場景和目的去探討;3)匿名化是一種對數據“狀態”的評估,但數據處理是一個動態的過程,需充分衡量整個動態過程的評估與管理;4)合理利用數據是匿名化的目的,但匿名化不是唯一的起點或者手段,新技術的出現將會改變合理利用數據的方式.在目前的研究過程中,上述問題並未受到充分關注.因此,本文將以歐美對匿名化的相關規定為起點,闡釋上述觀點並結合具體應用場景辨析匿名化相關規定在合規實踐上的難點,於文末提出相關的政策建議.
2 歐美匿名化相關規定及其發展
2.1 歐盟匿名化規定解讀
2.1.1 歐盟匿名化概念及發展歷程
在技術領域,匿名化模型的起點可以追溯至1997年美國的Samarati和Sweeney提出的k匿名模型,目前也發展出許多其他的技術與解決方案.在法律領域,歐盟1995年的«數據保護指令»提及“匿名化”的概念.隨著技術的進步,各產業對數據挖掘、共享、交換的需求越來越高,為保護個人隱私,各界紛紛對匿名化及其技術投入了更多關注,在與個人信息有關的法律法規中都有跡可循.例如,2014年歐盟第29條數據保護工作組起草的«關於匿名技術的意見»,對匿名化的場景因素、判斷標準、常用匿名化技術等,結合1995年的«數據保護指令»與2002年的«電子隱私指令»作了詳盡的介紹. 2020年歐盟«電子隱私條例»延續了匿名化的相關規定,規定用於研究的元數據必須匿名化或假名化、電子通信服務商必須對其元數據刪除或匿名化處理(如圖1所示).
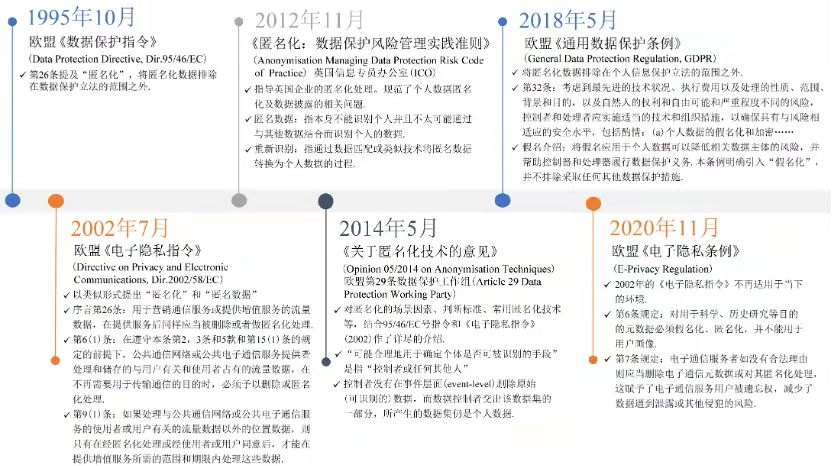 圖1 歐盟匿名化相關概念的發展
圖1 歐盟匿名化相關概念的發展
2.1.2 歐盟匿名化和假名化的區別
歐盟在對於個人數據匿名化方面提出了“假名化”與“匿名化”這2個概念.假名化(pseudonymisation)是一種處理數據的方式,使其在不結合額外信息的情況下,無法再度識別到特定數據主體,前提是這些額外信息必須單獨保存,採取相應技術和組織措施,確保個人數據不再被用於識別特定自然人(如圖2所示).匿名數據(anonymous data)則是與已識別或可識別的自然人無關的數據,以及經過處理後無法或不再可識別到特定自然人的數據.在«關於匿名化技術的意見»中對其有更詳盡的闡釋,認為“只有當數據控制者將數據匯總到個別事件(event-level)不再可識別的水平時”該數據集才是匿名的數據集,即數據控制者應當在事件層面刪除原始(可識別)的數據(如圖3所示).
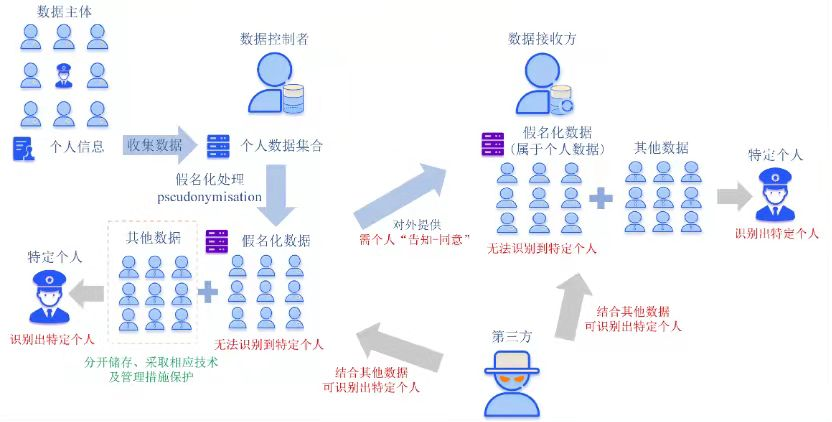 圖2 歐盟去標識化概念圖例
圖2 歐盟去標識化概念圖例
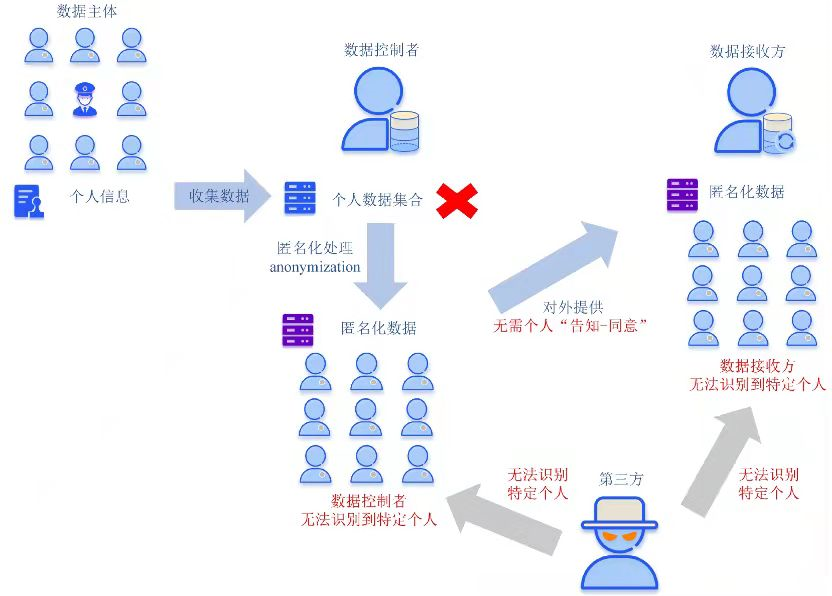 圖3 歐盟匿名化概念圖例
圖3 歐盟匿名化概念圖例
2.1.3 歐盟關於匿名化的技術評估
欧盟的«关于匿名技术的意见»主要从3个维度考虑匿名化技术的稳健(robustness)程度:1)筛选(singling out).将数据集中的所有或某些记录分离出来,从而识别出特定个人.2)关联(linkability).从1个数据集中的至少2条记录或者至少不同数据集中的2条记录关联到特定个人(单独的数据集中无法筛选出特定个人则不具有筛选风险).3)推断(inference).从1组其他属性显著可能地推断出其他属性.当数据集有可能出现筛选、关联、推断情况时,数据集就不是匿名化的数据集,需受GDPR的约束.«关于匿名技术的意见»中将对标签进行加密的一类密码学相关技术归类为假名化的技术,认为该类技术在不结合其他技术的情况下,无法实现匿名化(如图4所示).在评估稳健性要求时,采取“合理可能”(reasonably likely)的标准,即综合考虑了采取重识别的技术手段需付出的成本(所需时间与资源)和技术,并且考虑了技术随时间发展的变化.
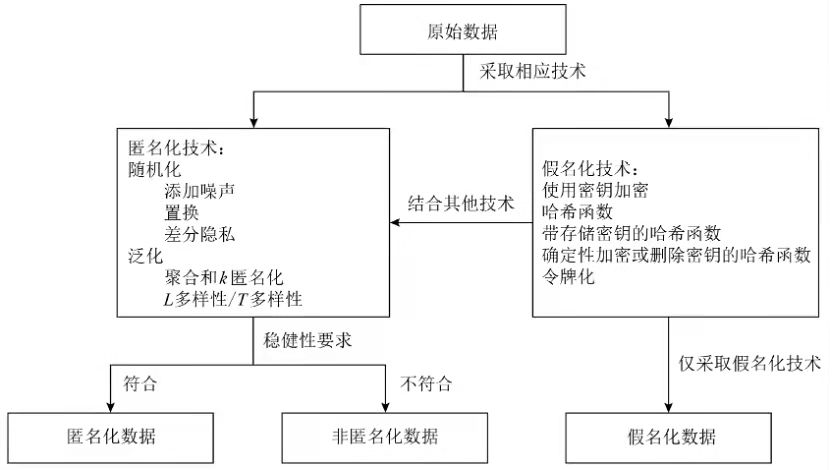 圖4 歐盟關於匿名化的判斷
圖4 歐盟關於匿名化的判斷
2.2 美國不採用匿名化,而採用假名化和去標識化
美國採用去標識化(de-identification)與假名化(pseudonymization)的概念,而未有匿名化的概念,即將個人信息中的直接或者間接標識符刪除. 1996年出台的«健康保險責任流通法案»(Health Insurance Portability and Accountability Act, HIPAA)是最早有關個人信息去身份化的法律規定. HIPPA 指出去標識化處理後的健康信息,使用和公開不再受限,其認定標准採取“專家標準”與“安全港標準”. 2015年美國國家標準與技術協會發表了«個人信息去標識化»,將去標識化定義為從數據庫刪除身份信息,使其不能再鏈接到特定個人,處理後的數據不再受到隱私保護的限制.美國關於去標識化的方法較為簡單,將標識符分為直接標識符與準標識符(間接標識符),對於與特定個人高度關聯的直接標識符,應採取“刪除”或者“置換”的方式.準標識符無法直接識別到特定個人,但結合其他信息後則可連接到特定個人,對其可選擇抑制(suppression)、泛化(generalization)、干擾(perturbation)、交換(swapping)、子抽樣(sub-sampling)的處理方式. 2018年的«加利福尼亞州消費者隱私法案»(The California Consumer Privacy Act, CCPA)將去標識化的消費者信息或聚合消費者信息排除在個人信息的範圍之外. “假名化”則是一種個人信息的處理方式,在附加信息單獨保存並受技術合組織管理的前提下,通過該方式處理後的數據若不附加其他信息則不再被用於識別到特定個人. 2020年的«加利福尼亞隱私權法案»(Consumer Privacy Bill of Right Act, CPRA)對去標識化與假名化的相關規定與CCPA一致,同時還認為去標識化後的數據仍有殘存的安全風險,規定信息處理者有禁止重新識別的義務,從管理的角度上保障個人信息安全(如圖5所示).
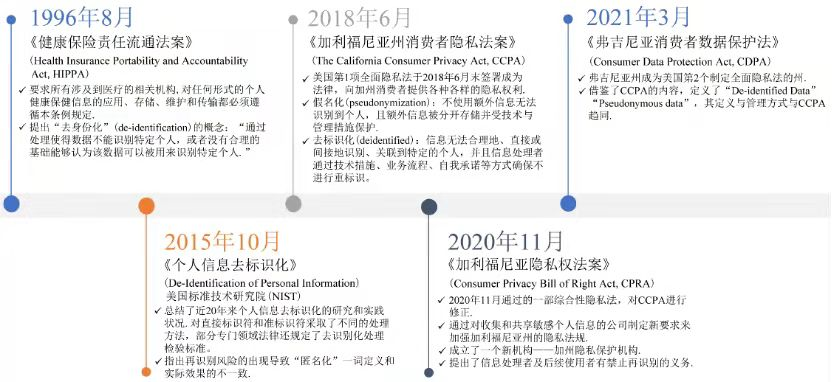 圖5 美國匿名化相關概念發展
圖5 美國匿名化相關概念發展
 圖6 歐美匿名化、假名化、去標識化相關概念對比
圖6 歐美匿名化、假名化、去標識化相關概念對比
3 國內對去標識化、匿名化的定義及發展
2016年出台的«網絡安全法»是我國法律領域與“匿名化”相關概念的起點.其中第42條規定,不得向他人提供個人信息,但經處理無法識別特定個人且不能複原的除外. 2017年«信息安全技術個人信息安全規範»是我國首次對“匿名化”“去標識化”定義的標準.匿名化為通過對個人信息的技術處理,使得個人信息主體無法被識別或者關聯,且處理後的信息不能被復原的過程.個人信息經匿名化處理後所得的信息不屬於個人信息.去標識化指的是通過個人信息的技術處理,使其在不借助額外信息的情況下,無法識別或者關聯個人信息主體的過程. 2019年«信息安全技術個人信息去標識化指南»(以下簡稱«去標識化指南»)提出了常用去標識化技術,並且對技術的去標識化效果進行了評價.需要提及的是,該評價並非從“匿名化”的角度出發,而是將所有技術都置於“去標識化”的框架下,最後將去標識化後的效果進行重標識風險評估(如圖7所示).與歐盟的«關於匿名化技術的意見»類似,«去標識化指南»列舉了3類重標識的方法即隔離、關聯、推斷,並提出了重標識概率的定量分析方法,即先計算每行的重標識概率,從而得出數據集重標識的概率,再結合環境風險計算整個數據集重標識的概率. 2021年4月,«信息安全技術個人信息去標識化效果分級評估規範(徵求意見稿)»(以下簡稱«分級評估規範»)給出了定量的去標識化評估方式,如圖8所示,這與歐美的技術意見相比增加了可供評價的依據.
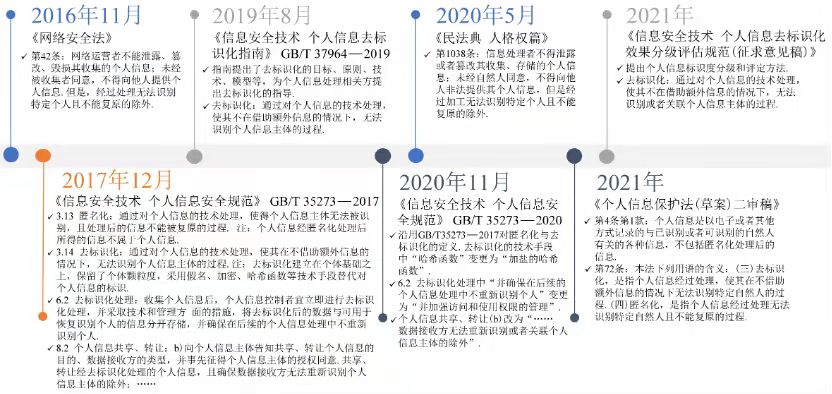 圖7 我國去標識化、匿名化相關概念發展
圖7 我國去標識化、匿名化相關概念發展
相較去標識化,我國關於匿名化的提法不多. 2020年«民法典人格權篇»將散見於相關法律法規當中的人格權統一其中,人格權、隱私權、個人信息有了新的內涵.對匿名化信息有關的規定可見於第1038條,未經自然人同意不得向他人非法提供其個人信息,但是經過加工無法識別特定個人且不能複原的除外. 2021年«個保法»定義了匿名化與去標識化,其由標準中的技術概念,上升為法律概念.具體地,«個保法»指出匿名化為個人信息經過處理無法識別特定自然人且不能複原的過程,個人信息不包括匿名化處理後的信息,隱含了數據控制者可不經數據主體同意對數據進行處理的意涵;而經過去標識化的個人信息,借助額外信息還能識別到特定自然人,需遵循«個保法»的各項規定.
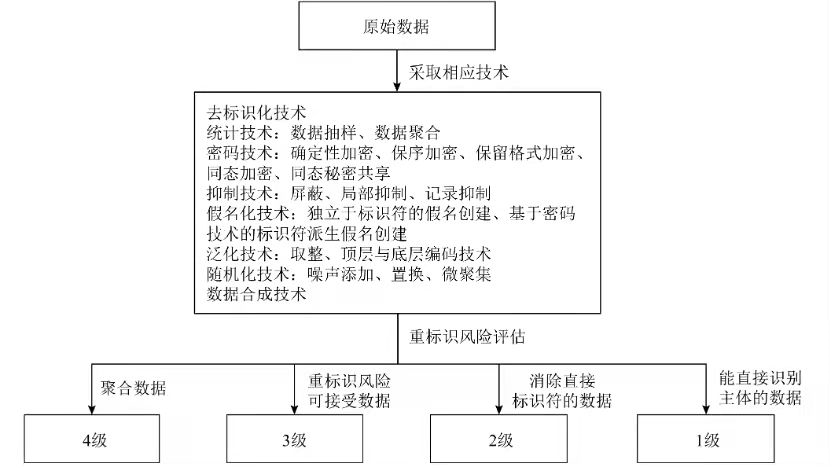 圖8 我國匿名化相關的判斷
圖8 我國匿名化相關的判斷
4 對我國個人信息保護的法律思考
從上可知,我國«個保法»對匿名化、去標識化的闡釋較為籠統,在實踐中結合不同的場景可能有不同的解釋,故需要具備更廣泛的適用性.在技術上,去標識化可結合«去標識化指南»對具體數據集作出相應操作,並參照其中風險評估方法考核去標識化的具體效果,落地可操作性較強.但對於匿名化而言,我國目前尚未有匿名化相關的技術指南、評估標準,實踐中亦未有人能明確自身處理後的數據為匿名化數據,若未能很好地結合實際,規範恐將淪為一個空洞且無意義的概念.故將現有的法律法規、標準結合歐美對於匿名化一類概念的相關規定以及實踐中可能遇到的問題,提出如下觀點,以茲參考.
4.1 定級方面
«分級評估規範»將去標識化的效果分為4級,但未明確說明哪一個級別或者達到何種程度效果的數據為匿名化數據,或者可在哪個範圍使用的去標識化數據,從規範到實踐有一定的跨度.例如:«分級評估規範»中的4級聚合數據僅具有統計概念上的意義,符合«個保法»對匿名化定義的內涵.
4.2 定量分析方面
«分級評估規範»是以“重標識概率”來定義風險,但必須明確的是“重標識”只是數據風險的其中一個維度,通過定量分析出來重標識概率高的數據集並不能完全代表數據集的其他風險就高.比如:完全公開共享數據,除非數據集足夠大、等價類足夠多,否則在該計算方法下總體風險值為1(數值越大風險越高).但從數據敏感程度的角度來看,被完全公開的數據集(合法合規的前提下),一般是風險極低的非敏感數據.故«分級評估規範»評估出的重標識風險與數據實質上面臨的風險考慮上應當有所區別.
4.3 對於密碼學技術去標識化的認識
無論是在歐盟«關於匿名技術的意見»中還是在我國的«去標識化指南»中都有提及密碼學相關技術,對於密碼學技術的考慮局限於用其對標識符進行加密處理,只要密鑰沒刪除,個人信息就可以被“重新識別”. «去標識化指南»認為其不可能降低隔離風險、關聯風險、推導風險與可辨別風險.上述認識具有一定局限性,因為在密碼學技術中,在安全性假設成立的前提下其安全性具有嚴謹的數學證明.只要符合基於其安全性假設建立的安全模型,隔離、關聯與推斷風險對於密碼技術來說在所有“合理可能”(攻擊者的能力,如有效時間和計算能力)的情況下是可忽略的,除非攻擊者付出“不合理的努力”(違法攻擊服務器)才會發生,即在“合理可能”的情況下該風險近乎於0,符合匿名化的要求.
4.4 關於“合理可能”的考慮
歐盟認為匿名化應當考慮重識別所需的具體手段,特別是實施這些手段的成本和技術,評估對匿名化付出的努力和成本.我國的相關規定則不具備這方面的考慮,是一種較為絕對的規定方式.
4.5 關於“可操作性”的考慮
美國的相關規定則是將規定中的標識符刪除或置換即可達到相應標準,從技術上看是一種較為“簡單粗暴”的保障方式,但是操作方式較為簡便,評估也具備可行性,其關鍵在於對管理的要求較高,包括對於違反規則所導致個人或群體利益受損時的追責機制健全.
4.6 對於“識別主體”的考慮
目前«個保法»對匿名化與去標識化的定義中未有對“無法識別到特定個人”的“識別主體”作出相應規定,但在實際業務場景中,對個人信息的保護考慮可能是“第三人”不可識別出特定個人,而對數據發送和接收方則是利用管理的手段保障個人信息安全.
4.7 對於數據處理全流程活動的考慮
去標識化考慮的模式是單方採集、享有、處理的數據,要對外發送時,用去除可識別出特定自然人標籤的方式來保障個人信息不被洩露.但目前市場上對數據多方融合的需求已經進入深水區,對於數據中存在的個人信息保護已經可以貫穿數據處理的全流程活動,而無需將其限定在數據處理的起點.
5 基於多方計算數據交易所場景下的匿名化認定
在釐清我國匿名化、去標識化相關概念與實踐中,近年來我國隱私計算技術的發展也為數據流通創造了新的可能性.本文在自主可控的多方計算(multi-party computation, MPC)應用可能存在問題的基礎上,選取大數據交易所為例,對在採用MPC的特定場景下匿名化的認定進行分析. MPC是一種基於多方數據協同完成計算目標,實現除計算結果及其可推導出的信息之外不洩露各方隱私數據的密碼技術.計算因子是基於多方計算輸入數據產生的數據,包括輸入因子、輸出因子和中間因子.輸入因子是指數據提供方執行數據輸入過程後可供計算方執行後續計算的數據;輸出因子是指計算方執行計算後,返回給結果使用方用以恢復最終計算結果的數據;中間因子指計算方中間計算過程中產生的數據.數據交易所基於MPC的數據交易平台,可實現數據的安全交易,降低因數據交易造成的個人信息洩露的風險.
5.1 數據交易的參與主體
1)每個需要作數據共享的部門或單位都是數據提供方,如圖9的數據提供方1與數據提供方2.在每個數據提供方部署數據接入模塊,對應圖中的“MPC數據輸入處理”,用於實現數據的密文接入. 2)數據交易平台是計算方,主要提供算力,監督數據交易過程. 3)結果獲得方一般也是數據的實際需求方.
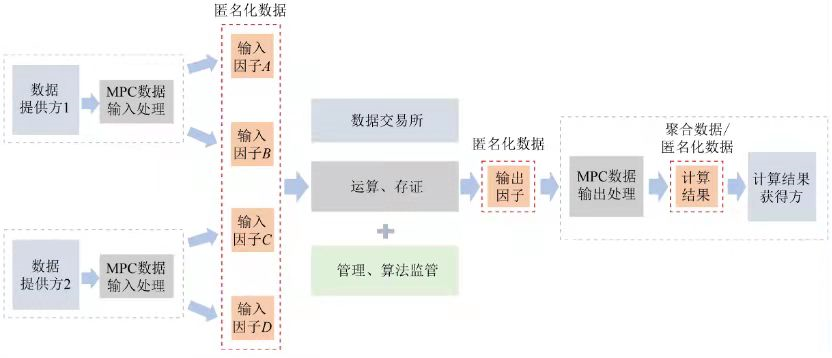 圖9 基於MPC的數據交易平台匿名化的認定
圖9 基於MPC的數據交易平台匿名化的認定
5.2 數據交易的流程
1)數據提供方提供數據目錄;2)數據需求方查看數據目錄,根據自身需求與數據交易所訂立合約;3)數據提供方審核所需數據及算法後,將數據通過MPC數據輸入處理後形成計算因子,將計算因子傳輸至數據交易平台;4)數據交易平台對接入的計算因子根據合約中的算法進行計算;5)數據交易平台將計算後的結果發送至數據需求方(結果獲得方).
5.3 數據交易的管理
數據提供方對算法進行審核,只有審核通過後,數據需求方才能正常使用該算法.數據交易平台基於區塊鍊等技術搭建的應用,負責數據資源目錄管理、數據合約訂立和執行以及數據安全融合流程存證等功能,建立多方可見且不可篡改的存證體系,支持問題溯源和審計需求.
5.4 數據交易中匿名化數據的認定
1)輸入因子,不降低數據的可用性,其他方只有在獲得所有輸入因子時才可能恢復、識別出原始數據集中的特定自然人,可以說每個獨立的輸入因子完全符合匿名化的相關規定;2)輸入因子在數據交易平台集中計算,可能被視為“加密數據與密鑰結合”,導致不再被視為“匿名化”,但計算場所是一個可監管的環境,通過嚴格的管理約束,按照計算合約限制的範圍完成計算,基本不存在洩露特定個人數據的風險;3)數據交易平台輸出的輸出因子依然是加密數據,符合匿名化的相關規定;4)輸出因子傳輸至計算結果獲得方,通過MPC數據輸出處理(解密),從而獲得“計算結果”,其一般為一個不具備任何可識別出特定自然人可能性的“模型”或者符合“聚合數據”特徵的數據. “聚合數據”在«分級評估規範»被定為第4級, 雖然目前該級別數據尚未被認定為匿名化數據,但根據其“不可重識別出特定個人”的特性,可認為其符合匿名化的相關規定.
5.5 數據交易需考慮的風險點
1)計算因子僅在符合安全性假設的前提下,可視為完全清除“隔離”“關聯”“推斷”風險,即不存在被識別出的可能性;2)計算因子的“匿名化”保證,需結合管理上的措施,對算法用途的審核,保證數據有限的用途,且不可用於識別出特定個人.
6 結論與建議
6.1 法律法規與標準的製定應當考慮技術進步及其應用場景
去標識化是一種通過對標識符處理來達到不可識別具體個人效果的技術,較少考慮數據在具體場景應用上的問題,也忽略了技術進步在法律法規中的融合實踐.因為信息技術的快速發展,如果對相關法令的運用解釋過度製式化、僵化,亦可能造成產業創新的阻礙.應當考慮具體化、匿名化與加工信息流程的關係,並保持彈性以應對各種可能場景的個案問題.
6.2 對於匿名化的“合理保證”與“重新被識別”的標準
匿名化應當是一種“合理保證”而不是“絕對保證”,法律法規與標準的製定應當考慮可操作性,以在實踐中更好地應用.應適當考慮“重新被識別”的標準是一種合理的可能性,並建立數據責任人自證其管理完備且已盡到合理可能範圍內最大努力的機制.目前對於匿名化的效果未有相應的標準,«分級評估規範»建立了去標識化後的數據集的評價機制,但對應級別是什麼樣類型的數據卻未有明示.
6.3 關於數據處理的全流程活動與重新識別的主體
目前所有去標識化的技術都是“單方”“本地處理”,新的技術應用方式“多方融合”與數據處理的全流程活動卻沒有被考慮.去標識化與匿名化考慮的是單方採集、享有、處理的數據,要對外發送時,用去除可識別出特定自然人標識符的方式來保障個人信息不被洩露,是一種靜態的、基於數據接收方取得的是明文數據集的思路.採用類似MPC的技術已經可以對數據中存在的個人信息保護貫穿數據處理的全流程活動,通過對數據使用的限製做到數據接收方不能濫用個人信息.同時,可由6.2節對數據交易所的場景示例得知,在數據交易的關鍵節點,數據符合“匿名化”相關規定;有被“重新識別”可能性的數據交易節點,被嚴格監管.
6.4 管理機制對於個人信息保護的重要性
匿名化不能只考慮技術,隨著法律法規的逐步完善,數據處理的管理機制對於個人信息保護至關重要.借鑒美國的規定,認識管理手段對個人信息保護的重要性,制定技術保護措施與管理規定,禁止重新識別到特定自然人.需充分認識到:1)數據洩露或濫用造成風險的本質是數據控制者對數據的“用途”與“用量”失去控制,而在基於MPC的數據交易平台是對數據“用途”與“用量”的交易,是一種從源頭上控制風險的手段. 2)在基於MPC的數據交易平台的數據交易中,應當防範的是利用多次計算重新識別出特定個人及其相關信息的行為.因此對數據的監管應重點關注對計算用途的監管,而不能僅停留在對數據集標識符去標識化處理的效果及其度量本身.在基於MPC的數據交易平台中,平台監督數據交易的全過程、審核計算合約中的算法、對交易過程進行存證,是一種事前審核+事中存證+事後審計的管理模式.
6.5 保障暢通的維權渠道保護個人信息
去標識化與匿名化的規定是一種風險防範的思維,為了更好地保障個人信息主體的各項權益,還應當完善侵權責任的相關規定,並且通暢個人維護自身權益的渠道.以數據交易所的場景為例,參與數據交易的主體與交易所應積極地、謹慎地採取有效措施確保信息安全,防止個人信息洩露與濫用.除了«數據安全法»中對數據交易中介所需遵循的相關規定外,若數據交易引起有關個人信息洩露、濫用等問題,應當採取過錯責任推定,即參與數據交易的主體、交易所不能自證無過錯的情況下,推定其對個人信息的洩露、濫用有過錯,應承擔賠償損害的民事責任,以更好地保護個人的權益,平衡數據交易參與各方的權益.
6.6 對於特定行業應用的考慮
日本的«次世代醫療基盤法»立法移除了現行個人信息保護法對利用醫療大數據造成的障礙,讓各醫院、醫療機關的個人醫療信息相互串聯流通,有助於醫療領域能更靈活利用醫療數據作多目的研究與創新.我國«刑法修正案九»提出非法出售和提供個人信息罪,絕對禁止個人信息的交易行為.但必須明確,排除一切個人信息有關數據的商業化應用,對於數字經濟而言將會是毀滅性的打擊.同樣以數據交易為例,交易的“價值”所在是數據“用途”與“用量”,並不是含有個人隱私的“個人信息”本身,出於促進數據流通的考慮,建議探討對特定行業應用個人信息制定相關豁免條款的可行性.
6.7 結語
2021年8月20日«個保法»正式通過,其中匿名化處理後的信息不再是個人信息,此概念備受數據相關從業人士關注.從«個保法»條文看來,可理解為匿名信息由數據控制者(企業)原始取得,但處理後的效果與邊界仍有待進一步釐清,以更好地劃分數據流通過程中的“權責利”.當前基於大數據分析、人工智能的發展,推動了海量數據的匯聚融合,考慮到法律落地與未來執法的可操作性,“匿名化”的實現路徑應當是法律、標準、技術、管理與效果評估的結合.本文借鑒歐美匿名化相關規定、技術可操作性,結合基於多方計算的數據交易所的場景,旨在提出一種可行的匿名化認定方式,對«個保法»中匿名化落地提出相關建議.
參考文獻
[1] 美國國家標準與技術研究所。 個人信息的去標識化 [R]. 2015. http://dx.doi.org/10.6028/NIST.IR.8053[2] 金濤,謝安明,陳星,等. GB/T 37964-2019信息安全技術個人信息去標識化指南[S].北京:中國標准出版社,2019[3] 金濤,王建民,周晨煒,等.信息安全技術個人信息去標識化效果分級評估規範(徵求意見稿)[S/OL]. 2021. 國家標準計劃- 全國標准信息公共服務平台(samr.gov.cn) [4] JR/T 0196-2020多方安全計算金融應用技術規範 [S/OL]. 2020. http://hbba.sacinfo.org.cn/stdDetail/199888ae21b34ea00b3f61462c07c430ffbedd0a4fbac8c9b47eb8a3e6169e7e[5] Yao, Andrew C. 安全計算協議 [C]. 計算機協會第 23 屆年度計算機理論研討會論文集,1982:160-164。[6] 李黎. 個人信息概念的反思:以“識別”要件為中心[J]. 信息安全研究, 2021, 7(8): 754-762.[7] 谷勇浩郭振洋劉威歆. 匿名化隱私保護技術性能評估方法研究[J]. 信息安全研究, 2019, 5(4): 293-297.[8] 李俊柴海新. 生物特徵識別隱私保護研究[J]. 信息安全研究, 2020, 6(7): 589-601
展開全文打開碳鏈價值APP 查看更多精彩資訊