

網頁抓取是一項重要的技能。
數據就是新石油
互聯網上海量的加密貨幣數據是進一步進行加密貨幣投資研究的豐富資源。擁有管理和利用這些數據的能力將使我們在加密投資方面具有優勢。
網頁抓取是指從網站下載數據並從這些數據中提取有價值的信息的過程(因此得名抓取)。出於我們的目的,我們對網頁抓取加密貨幣數據感興趣。
在本系列文章中,我們將從概念開始,並在此基礎上慢慢構建。到最後,網頁抓取加密貨幣數據應該成為你的第二天性!
網頁抓取是一項重要的技能。通過收集和分析來自多個來源的數據,我們可以提高我們的投資情報。
為什麼網頁抓取?
既然有這麼多網站提供免費的工具,為什麼還會有人想要收集你自己的數據呢?大多數用戶將使用網站,如CoinMarketCap, CoinGecko, Live Coin Watch來獲取他們的數據並建立他們的觀察名單。那樣不是更方便嗎?
在我看來,我們應該兩者都用,從新手(使用典型加密網站的標準功能)到我們自己的數據分析(網頁抓取和構建我們自己的智能數據)。
根據我的經驗,發現了以下好處:
保持控制和專注:我更加專注和控制,知道我使用電子表格構建的列表和分析是我投資目的的主要工作版本。我不需要依賴其他人的數據。從一個站點跳到另一個站點也會分散我的注意力,使我不能專心於我的主要任務。
填補空白:並不是所有的替代幣都可以在主要的網站上使用。在幣列表中總是存在空白和不一致。當我們擁有自己的數據時,我們可以管理它。
高級分析:通過電子表格中的數據,可以進行高級分析和過濾,以找到網站無法提供的小眾幣。
個人筆記和評論:可以添加列到自己的電子表格,以獲得更多的評論和投資見解。我還添加了我將使用的場所,以及我將分配到幣的資本金額。
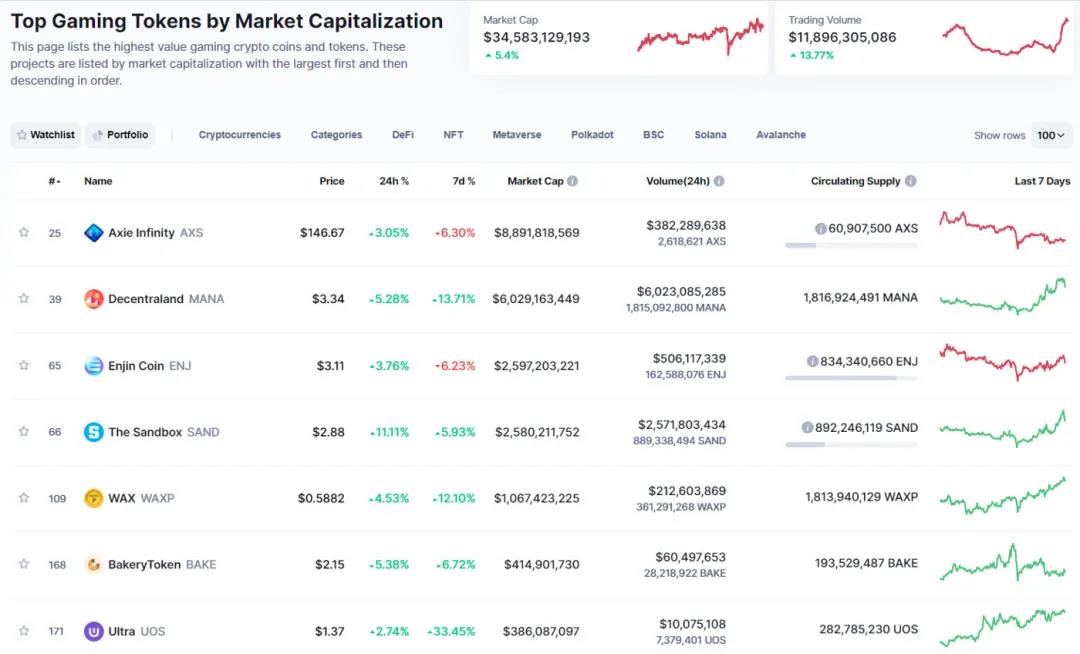
例如,當我們在電子表格中擁有數據時,我們可以在Solana和遊戲中搜索幣:
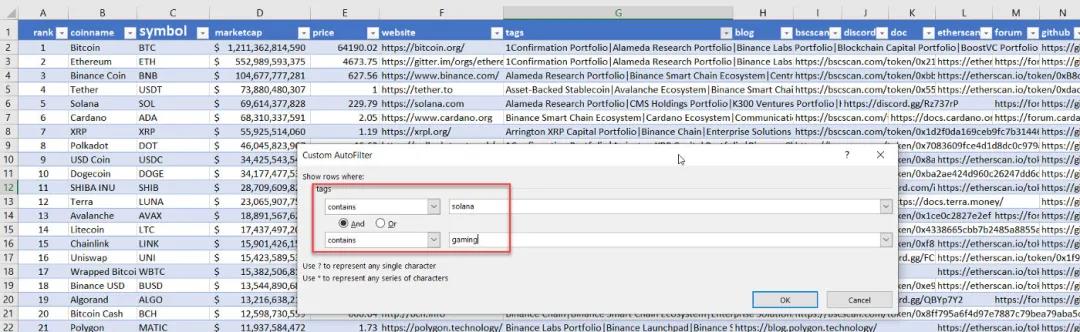
過濾我們的數據與包含這兩個標籤索拉納和遊戲

有兩種幣符合此標準:ATLAS 和POLIS。我們來自網頁抓取的數據集還將包含更多投資研究的附加信息(市值、網站、推特鏈接等)
尋找既適用於polkadot又適用於遊戲的幣怎麼樣:
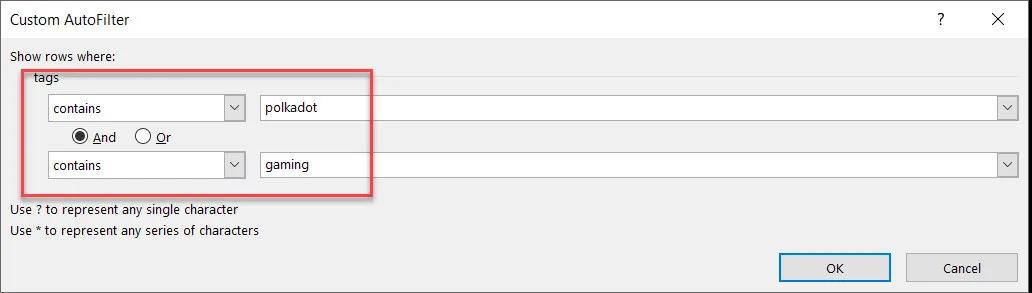

四種幣在Polkadot 和Gaming 中:EFI、SAITO、RING、CHI
作為比較,大多數網站只支持一級過濾。例如,CoinMarketCap可以列出Polkadot生態系統中的所有幣:
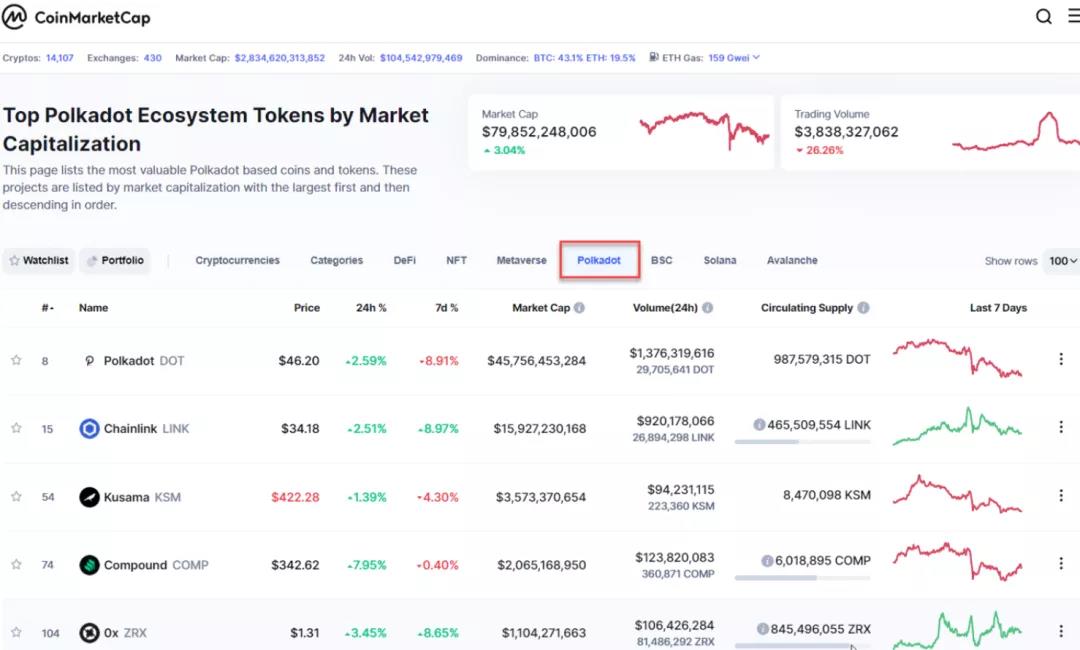
CoinMarketCap也可以列出所有遊戲代幣,但不能同時列出Polkadot和遊戲。
一般來說,這些網站不能超過兩個或三個級別的過濾,例如列出所有與Polkadot相關的遊戲幣。
從表面上看,高級過濾似乎不是一個大問題,但市場上有成千上萬的幣,擁有這種自動化的能力並保持我們的專注是成功的關鍵。
概念
我們將在Python中使用兩個庫:
BeautifulSoup是一個Python庫,用於從HTML、XML和其他標記語言中獲取數據。
Request,用於從網站獲取HTML數據。如果您已經在HTML文件中擁有數據,則不需要請求庫。
我也在谷歌云平台上使用Jupyter Notebook來運行,但是下面的Python代碼可以在任何平台上運行。
根據各自的Python設置,可能需要pip install beautifulsoup4。

通過例子學習:網頁抓取的“Hello World”
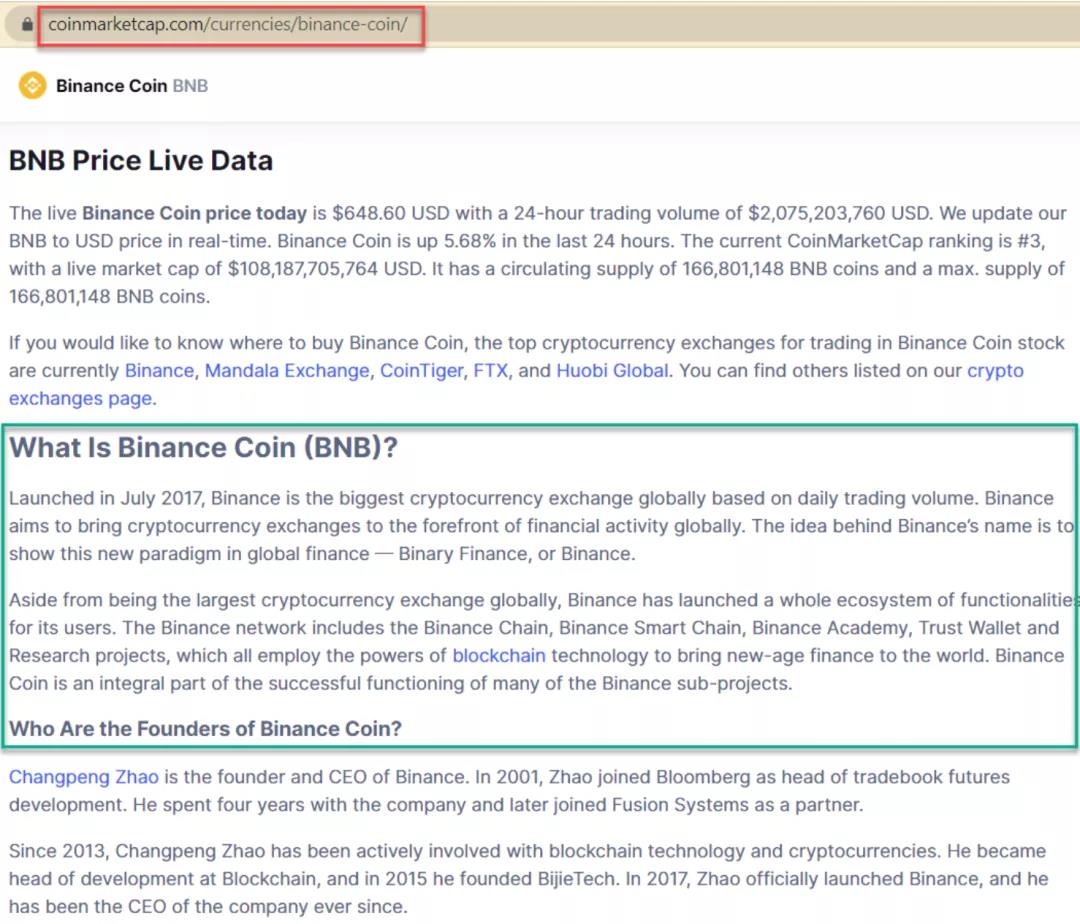
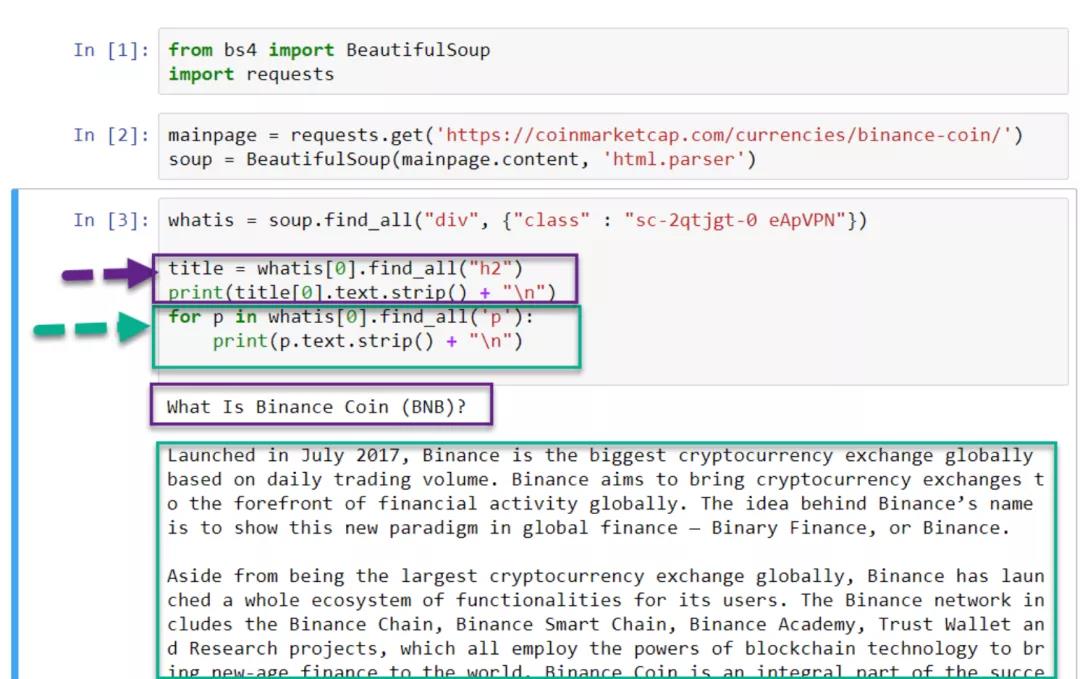
我們將從網頁抓取的“Hello World”開始,通過抓取什麼是幣安幣(BNB)的介紹文本,如下面的綠色框所示。

訪問BNB頁面與你的Chrome瀏覽器,然後右鍵單擊頁面,然後單擊檢查以檢查元素:
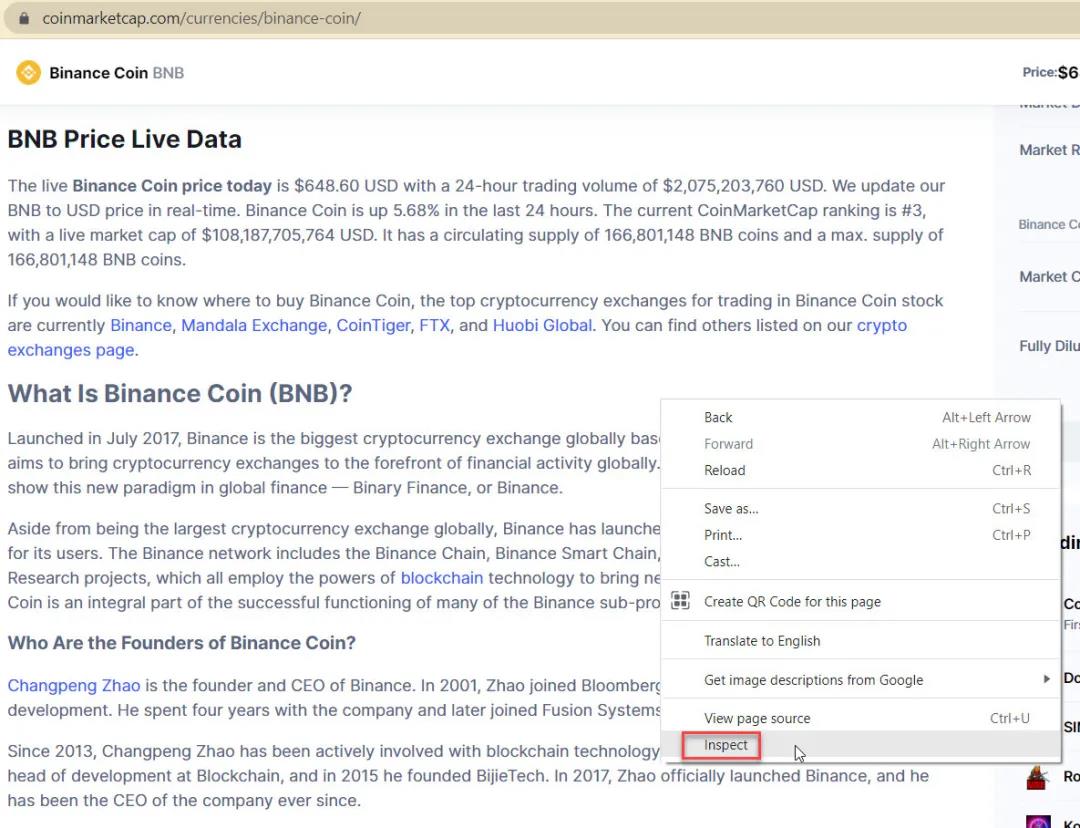
點擊屏幕中間的小箭頭,然後點擊相應的網頁元素,如下圖所示。
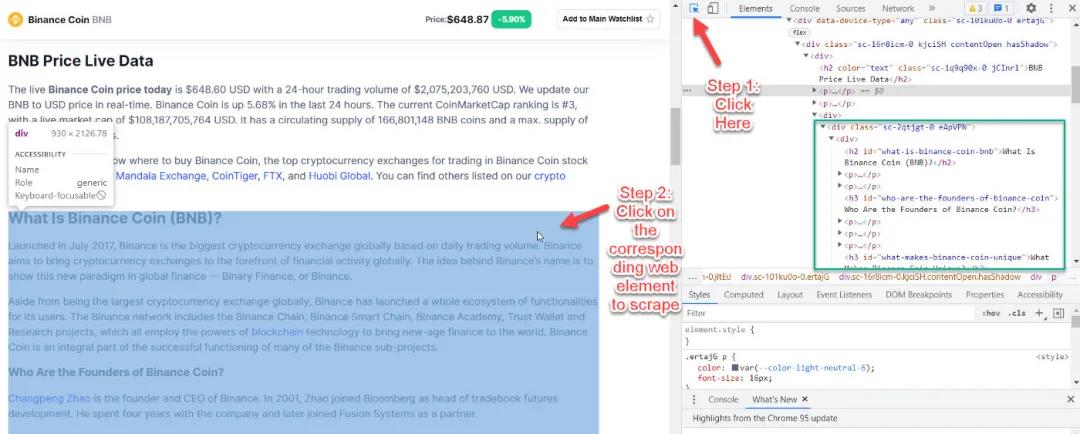

從檢查,我們看到網頁元素是
在div 類sc-2qtjgt-0 eApVPN 下
標題使用h2
字幕使用h3
剩下的在p下
從 bs4 導入 BeautifulSoup
導入請求#檢索網頁並解析內容
mainpage = requests.get(‘https://coinmarketcap.com/currencies/binance-coin/’)
湯 = BeautifulSoup(mainpage.content, ‘html.parser’)
whatis = soup.find_all(“div”, {“class” : “sc-2qtjgt-0 eApVPN”})#從內容中提取元素
標題 = 是什麼[0].find_all(“h2”)
打印(標題[0].text.strip() + “n”)
對於 p in whatis[0].find_all(‘p’):
打印(p.text.strip()+“n”)
例2:網頁抓取幣統計信息
在這個例子中,我們將使用BNB的統計數據,即市值、完全稀釋市值、成交量(24小時)、流通供應量、成交量/市值。
在相同的BNB幣頁面上,去頁面的頂部,點擊Market Cap的網頁元素。觀察整個區塊被調用
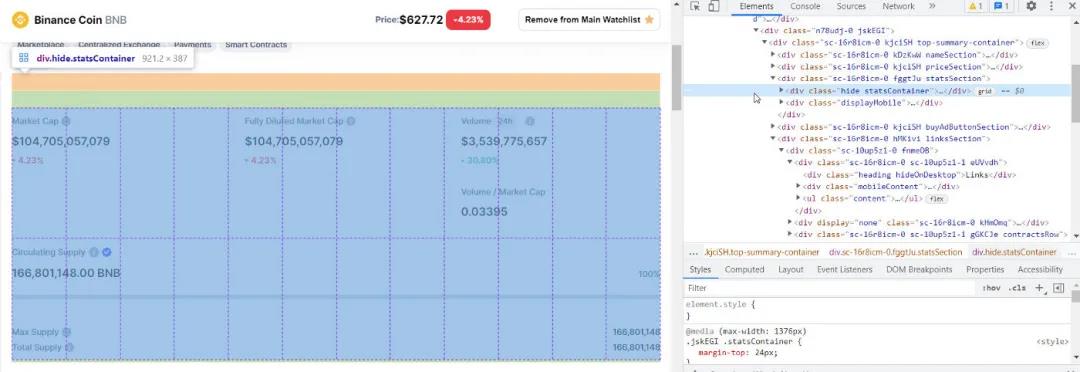
每個統計數據都有類型:

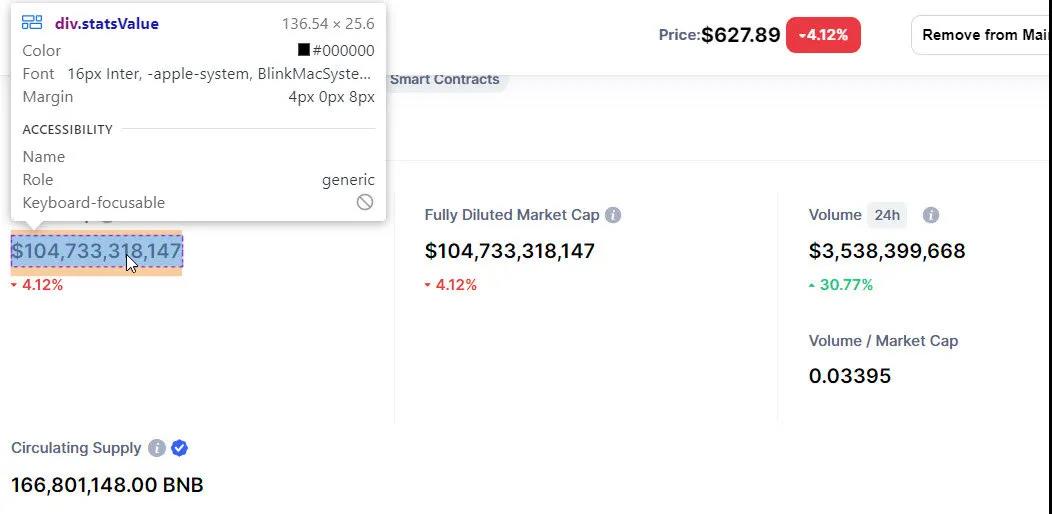
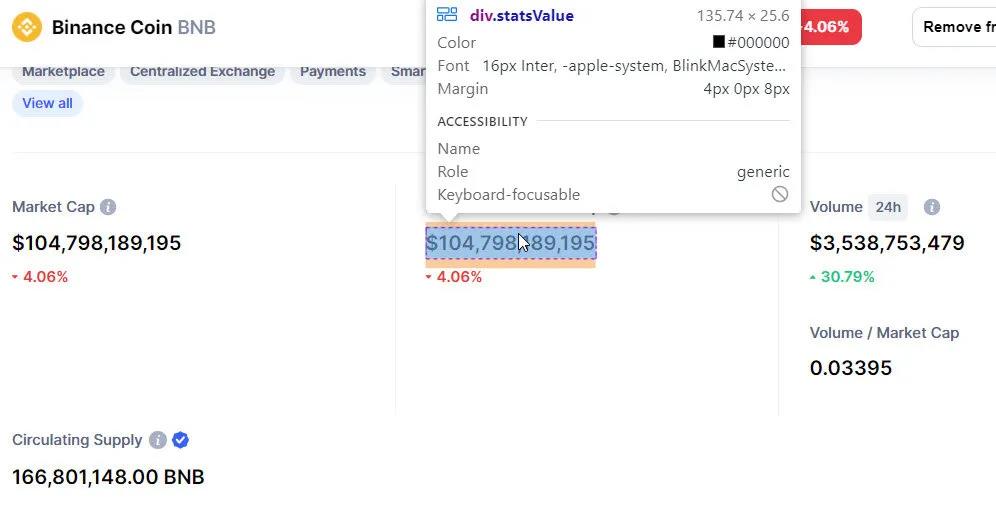
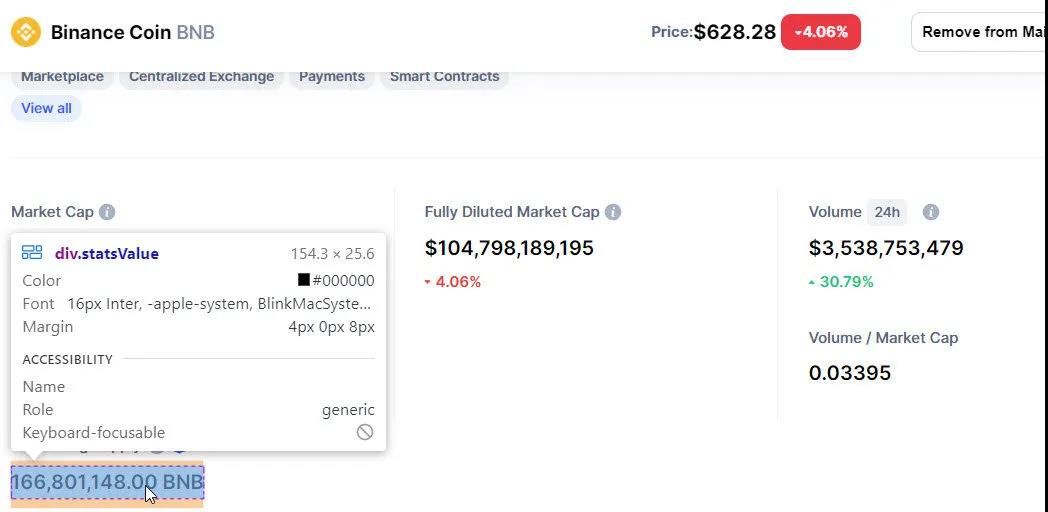
我們要找到


這將檢索五個統計數字。 (由於加密貨幣是24×7 交易,這些數字一直在變化,與之前的屏幕截圖略有不同。)
statsContainer = soup.find_all(“div”, {“class” : “hide statsContainer”})statsValues = statsContainer[0].find_all (“div”, {“class”: “statsValue”}) statsValue_marketcap = statsValues[0].text.strip()
打印(statsValue_marketcap)statsValue_fully_diluted_marketcap = statsValues[1].text.strip()
打印(statsValue_fully_diluted_marketcap)statsValue_volume = statsValues[2].text.strip()
打印(statsValue_volume)statsValue_volume_per_marketcap = statsValues[3].text.strip()
打印(statsValue_volume_per_marketcap)statsValue_circulating_supply = statsValues[4].text.strip()
打印(statsValue_circulating_supply)
輸出如下(結果隨時間變化,價格隨時間變化)。
104,432,294,030 美元 104,432,294,030 美元 3,550,594,245 美元 0.034 166,801,148.00 BNB
示例3:練習
作為練習,使用前兩個部分的知識並檢查是否可以為BNB和ADA (Cardano)提取最大供應和總供應的數據。
最大供應量和總供應量



ADA (Cardano) 最大供應量和總供應量



附錄:BeautifulSoup的替代品
其他替代品有Scrapy和Selenium。
Scrapy和Selenium比用於獲取HTML數據的Request和用作HTML解析器的BeautifulSoup有更陡峭的學習曲線。
Scrapy是一個完整的網頁抓取框架,負責從獲取HTML到處理數據的所有事情。
Selenium是一個瀏覽器自動化工具,例如,它可以讓用戶在多個頁面之間導航。
網頁抓取的挑戰:長壽
任何網頁抓取的主要挑戰是代碼的壽命。 CoinMarketCap等網站的開發人員正在不斷更新他們的網站,舊代碼可能在一段時間後就不能工作了。
一個可能的解決方案是使用各種網站和平台提供的應用程序編程接口(API)。然而,API的免費版本是有限的。使用API時,數據的格式不同於通常的網頁抓取,即JSON或XML,而在標準的網頁抓取中,我們主要處理的是HTML格式的數據。
來源:https://medium.com/crypto-code/learn-the-basics-of-web-scraping-data-with-python-and-beautifulsoup-2222e6dbe117
關於
ChinaDeFi – ChinaDeFi.com 是一個研究驅動的DeFi創新組織,同時我們也是區塊鏈開發團隊。每天從全球超過500個優質信息源的近900篇內容中,尋找思考更具深度、梳理更為系統的內容,以最快的速度同步到中國市場提供決策輔助材料。
Layer 2道友- 歡迎對Layer 2感興趣的區塊鏈技術愛好者、研究分析人與Gavin(微信: chinadefi)聯繫,共同探討Layer 2帶來的落地機遇。敬請關注我們的微信公眾號“去中心化金融社區”。
展開全文打開碳鏈價值APP 查看更多精彩資訊

