
摘要:以太坊創始人Vitalik Buterin近日針對與Proto-danksharding(又名EIP-4844)有關的疑問近了解答。 Danksharding是為以太坊提出的新分片設計,這種技術究竟能帶來什麼?什麼是Danksharding? Danksharding 是為以太坊提出的新分片設計…
以太坊創始人Vitalik Buterin近日針對與Proto-danksharding(又名EIP-4844)有關的疑問近了解答。 Danksharding是為以太坊提出的新分片設計,這種技術究竟能帶來什麼?
什麼是Danksharding?
Danksharding 是為以太坊提出的新分片設計,與之前的設計相比,它引入了一些顯著的簡化。
自2020 年以來的所有最近的以太坊分片提案(包括Danksharding 和之前的Danksharding)與大多數非以太坊分片提案的主要區別在於以太坊以匯總(Rollup)為中心的路線圖:以太坊分片沒有為交易提供更多空間,而是為數據提供,以太坊協議本身不會嘗試解釋。
驗證blob 只需檢查blob 是否可用,即是否可以從網絡下載。這些blob 中的數據空間預計將由支持高吞吐量事務的第2 層(Layer2)Rollup協議使用。
Danksharding 引入的主要創新是合併費用市場:不再有固定數量的分片,每個分片都有不同的區塊和不同的區塊提議者,在Danksharding 中,只有一個提議者選擇進入該槽的所有交易和所有數據.
為避免這種設計對驗證者提出高系統要求,我們引入了提議者/構建者分離(PBS):稱為區塊構建者的一類特殊參與者競標選擇slot的權利,提議者只需要選擇出價最高的有效header即可。
只有區塊構建者需要處理整個區塊(在這裡,也可以使用第三方去中心化預言機協議來實現分佈式區塊構建者);所有其他驗證者和用戶都可以通過數據可用性採樣非常有效地驗證區塊(請記住:區塊的“大”部分只是數據)。
什麼是proto-danksharding(又名EIP-4844)?
Proto-danksharding(又名EIP-4844)是一個以太坊改進提議(EIP),用於實現構成完整Danksharding 規範的大部分邏輯和“腳手架”(例如交易格式、驗證規則),但尚未實際實現任何分片。在proto-danksharding 實現中,所有驗證者和用戶仍然必須直接驗證完整數據的可用性。
proto-danksharding 引入的主要特徵是新的交易類型,我們稱之為一種帶有blob 的交易。帶有blob 的交易與常規交易類似,不同之處在於它還攜帶稱為blob 的額外數據。 Blob 非常大(~125 kB),並且比類似數量的calldata便宜得多。但是,EVM 執行無法訪問blob 數據; EVM 只能查看對blob 的承諾。
因為驗證者和客戶端仍然需要下載完整的blob 內容,所以proto-danksharding 中的數據帶寬目標為每個插槽1 MB,而不是完整的16 MB。然而,由於這些數據沒有與現有以太坊交易的gas 使用量競爭,因此仍然有很大的可擴展性好處。
為什麼向每個人都必須下載的塊添加1 MB 數據是可以的,而不是讓calldata 便宜10 倍?
這與平均負載和最壞情況負載之間的差異有關。今天,我們已經遇到了平均塊大小約為90 kB 的情況,但理論上可能的最大塊大小(如果塊中的所有30M gas 都用於調用數據)約為1.8 MB。以太坊網絡過去處理的區塊接近最大值。
但是,如果我們簡單地將calldata gas 成本降低10 倍,那麼儘管平均區塊大小會增加到仍然可以接受的水平,但最壞的情況會變成18 MB,這對於以太坊網絡來說實在是太多了。
當前的gas 定價方案無法將這兩個因素分開:平均負載與最壞情況負載之間的比率取決於用戶在calldata 與其他資源上花費多少gas 的選擇,這意味著gas 價格必須是根據最壞情況的可能性設置,導致平均負載不必要地低於系統可以處理的負載。
但是,如果我們改變gas 定價以更明確地創建一個多維費用市場,我們可以避免平均情況/最壞情況負載不匹配,並在每個區塊中包含接近我們可以安全處理的最大數據量的數據。 Proto-danksharding 和EIP-4488 就是這樣做的兩個提議。

proto-danksharding 與EIP-4488 相比如何?
EIP-4488 是解決相同平均情況/最壞情況負載不匹配問題的較早且更簡單的嘗試。 EIP-4488 使用兩個簡單的規則來做到這一點:
-
Calldata gas 成本從每字節16 gas 降低到每字節3 gas
-
每個塊1 MB 的限制加上每個事務額外的300 字節(理論最大值:~1.4 MB)
硬限制是確保平均情況負載的較大增加不會導致最壞情況負載增加的最簡單方法。天然氣成本的降低將大大增加匯總的使用,可能會將平均塊大小增加到數百KB,但硬限制將直接阻止包含10 MB 的單個塊的最壞情況可能性。事實上,最壞情況下的塊大小會比現在小(1.4 MB 對1.8 MB)。
Proto-danksharding 而是創建了一種單獨的事務類型,可以在大型固定大小的blob 中保存更便宜的數據,並限制每個塊可以包含多少blob。這些blob 無法從EVM 訪問(只有對blob 的承諾),並且blob 由共識層(信標鏈)而不是執行層存儲。
EIP-4488 和proto-danksharding 之間的主要實際區別在於,EIP-4488 試圖最小化今天所需的更改,而proto-danksharding 今天進行了大量更改,因此將來升級到完全分片需要很少的更改。
儘管實現全分片(使用數據可用性採樣等)是一項複雜的任務,並且在proto-danksharding 之後仍然是一項複雜的任務,但這種複雜性包含在共識層中。一旦proto-danksharding 推出,執行層客戶端團隊、rollup開發人員和用戶不需要做進一步的工作來完成向全分片的過渡。
請注意,兩者之間的選擇不是非此即彼的:我們可以盡快實施EIP-4488,然後在半年後使用proto-danksharding 跟進它。
proto-danksharding 實現了完整danksharding 的哪些部分?還有哪些需要實現?
引用EIP-4844,此EIP 中已經完成的工作包括:
-
一種新的交易類型,其格式與“全分片”中需要存在的完全相同。
-
全分片所需的所有執行層邏輯。
-
全分片所需的所有執行/共識交叉驗證邏輯。
-
BeaconBlock 驗證和數據可用性採樣blob 之間的層分離。
-
完全分片所需的大部分BeaconBlock 邏輯。
-
blob 的自調整獨立gasprice。
實現完全分片尚需完成的工作包括:
-
共識層中blob_kzgs 的低度擴展以允許2D 採樣。
-
數據可用性採樣的實際實現,
-
PBS(提議者/構建者分離),以避免要求單個驗證者在一個插槽中處理32 MB 的數據。
-
每個驗證者的託管證明或類似的協議內要求,以驗證每個區塊中分片數據的特定部分。
請注意,所有剩餘工作都是共識層更改,不需要執行客戶端團隊、用戶或Rollup開發人員的任何額外工作。
所有這些非常大的區塊都會增加磁盤空間需求怎麼辦?
EIP-4488 和proto-danksharding 都導致每個插槽(12 秒)的長期最大使用量約為1 MB。這相當於每年大約2.5 TB,遠高於以太坊今天所需的增長率。
在EIP-4488 的情況下,解決此問題需要歷史記錄到期方案(EIP-4444),其中不再需要客戶端存儲超過某個時間段的歷史記錄(已提出從1 個月到1 年的持續時間)。
在proto-danksharding 的情況下,無論是否實施EIP-4444,共識層都可以實施單獨的邏輯以在一段時間(例如30 天)後自動刪除blob 數據。但是,無論採用何種短期數據擴展解決方案,都強烈建議盡快實施EIP-4444。
這兩種策略都將共識客戶端的額外磁盤負載限制在最多幾百GB。從長遠來看,採用一些歷史過期機製本質上是強制性的:完整分片每年會增加大約40 TB 的歷史blob 數據,因此用戶實際上只能將其中的一小部分存儲一段時間。因此,值得儘早設定對此的期望。
如果數據在30 天后被刪除,用戶將如何訪問舊Blob?
以太坊共識協議的目的不是保證所有歷史數據的永久存儲。相反,目的是提供一個高度安全的實時公告板,並為其他去中心化協議留出空間進行更長期的存儲。
公告板的存在是為了確保在公告板上發布的數據可用時間足夠長,以便任何想要該數據的用戶或任何備份數據的長期協議都有足夠的時間來獲取數據並將其導入到他們的其他應用程序或協議中。
一般來說,長期歷史存儲很容易。雖然每年2.5 TB 對常規節點的要求太大,但對於專用用戶來說非常易於管理:您可以以每TB 約20 美元的價格購買非常大的硬盤驅動器,這完全可以滿足業餘愛好者的需求。
與具有N/2-of-N 信任模型的共識不同,歷史存儲具有1-of-N 信任模型:您只需要其中一個數據存儲者是誠實的。因此,每條歷史數據只需要存儲數百次,而不是完整的數千個正在做實時共識驗證的節點。
存儲完整歷史記錄並使其易於訪問的一些實用方法包括:
-
特定於應用程序的協議(例如Rollup)可能要求其節點存儲與其應用程序相關的歷史記錄部分。丟失的歷史數據對協議沒有風險,只會對單個應用程序造成風險,因此應用程序承擔存儲與自己相關的數據的負擔是有意義的。
-
在BitTorrent 中存儲歷史數據,例如。每天自動生成和分發一個7 GB 的文件,其中包含來自區塊的blob 數據。
-
以太坊門戶網絡(目前正在開發中)可以很容易地擴展到存儲歷史。
-
區塊瀏覽器、API 提供商和其他數據服務可能會存儲完整的歷史記錄。
-
個人愛好者和從事數據分析的學者可能會存儲完整的歷史記錄。在後一種情況下,將歷史存儲在本地為它們提供了重要的價值,因為它使直接對其進行計算變得更加容易。
-
TheGraph 等第三方索引協議可能會存儲完整的歷史記錄。
在更高級別的歷史存儲(例如每年500 TB)下,一些數據被遺忘的風險會變得更高(此外,數據可用性驗證系統會變得更加緊張)。這可能是分片區塊鏈可擴展性的真正極限。然而,目前所有提出的參數都距離這一點非常遠。
blob 數據的格式是什麼,它是如何提交的?
一個blob 是一個包含4096 個字段元素的向量,範圍內的數字:
0 <= x < 52435875175126190479447740508185965837690552500527637822603658699938581184513
blob 在數學上被視為表示具有上述模數的有限域上的次數< 4096 多項式,其中blob 中位置i 處的場元素是對該多項式在wi 處的評估。 w 是滿足w=1 的常數。
對blob 的承諾是KZG 承諾對該多項式的一個哈希。然而,從實現的角度來看,關注多項式的數學細節並不重要。相反,只會有一個橢圓曲線點的向量(基於拉格朗日的可信設置),而KZG 對blob 的承諾將只是一個線性組合。引用EIP-4844 的代碼:
def blob_to_kzg(blob: Vector[BLSFieldElement, 4096]) -> KZGCommitment: computed_kzg = bls.Z1 for value, point_kzg in zip(tx.blob, KZG_SETUP_LAGRANGE): assert value < BLS_MODULUS computed_kzg = bls.add( computed_kzg, bls.multiply(point_kzg, value) ) return computed_kzg
BLS_MODULUS 是上述模數,而KZG_SETUP_LAGRANGE 是橢圓曲線點的向量,它是基於拉格朗日的可信設置。對於實現者來說,現在將其簡單地視為一個黑盒專用哈希函數是合理的。
為什麼使用KZG 的哈希而不是直接使用KZG?
EIP-4844 沒有使用KZG 直接表示blob,而是使用版本化哈希:單個0×01 字節(表示這個版本)後跟KZG 的SHA256 哈希的最後31 個字節。
這樣做是為了EVM 兼容性和未來兼容性:KZG 承諾是48 字節,而EVM 更自然地使用32 字節值,如果我們從KZG 切換到其他東西(例如,出於量子抗性的原因),KZG承諾可以繼續為32 字節。
proto-danksharding 中引入的兩個預編譯是什麼?
Proto-danksharding 引入了兩種預編譯:blob 驗證預編譯和點評估預編譯。
Blob 驗證預編譯是不言自明的:它將版本化哈希和Blob 作為輸入,並驗證提供的版本化散列實際上是Blob 的有效版本化哈希。此預編譯旨在供Optimistic Rollup使用。引用EIP-4844:
Optimistic Rollup只需要在提交欺詐證明時實際提供基礎數據。欺詐證明提交功能將要求欺詐blob 的全部內容作為calldata 的一部分提交。它將使用blob 驗證功能根據之前提交的版本化哈希驗證數據,然後像今天一樣對該數據執行欺詐證明驗證。
點評估預編譯將版本化哈希、x 坐標、y 坐標和證明(blob 的KZG 承諾和KZG 評估證明)作為輸入。它驗證證明以檢查P(x) = y,其中P 是由具有給定版本化哈希的blob 表示的多項式。此預編譯旨在供ZK Rollup使用。引用EIP-4844:
ZK rollup 將為其交易或狀態增量數據提供兩個承諾:blob 中的KZG和使用ZK rollup 內部使用的任何證明系統的一些承諾。他們將使用等價協議的承諾證明,使用點評估預編譯,來證明kzg(協議確保指向可用數據)和ZK rollup 自己的承諾引用相同的數據。
請注意,大多數主要的Optimistic Rollup設計都使用多輪防欺詐方案,其中最後一輪只需要少量數據。因此,可以想像,Optimistic Rollup也可以使用點評估預編譯而不是blob 驗證預編譯,而且這樣做會更便宜。
KZG 可信設置是什麼樣的?
看:
可信設置如何工作的一般描述
https://vitalik.ca/general/2022/03/14/trustedsetup.html對powers-of-tau
所有重要的可信設置相關計算的示例實現
https://github.com/ethereum/research/blob/master/trusted_setup/trusted_setup.py
特別是在我們的例子中,當前的計劃是並行運行四個大小(n1=4096,n2=16),(n1=8192,n2=16),(n1=16834,n2=16)和(n1=32768,n2=16)的儀式(具有不同的秘密)。理論上,只需要第一個,但是運行更多的更大的尺寸,通過允許我們增加blob 來提高未來的適用性尺寸。我們不能只是有一個更大的設置,因為我們希望能夠對可以有效提交的多項式次數有一個硬限制,這個限制等於blob 大小。
可能的實用方法是從Filecoin 設置開始,然後運行一個儀式來擴展它。包括瀏覽器實現在內的多種實現將允許許多人參與。
我們不能在沒有可信設置的情況下使用其他一些承諾方案嗎?
不幸的是,使用KZG 以外的任何東西(例如IPA 或SHA256)會使分片路線圖變得更加困難。這有幾個原因:
非算術承諾(例如哈希函數)與數據可用性採樣不兼容,因此如果我們使用這樣的方案,當我們轉向完整分片時,無論如何我們都必須更改為KZG。
IPA 可能與數據可用性採樣兼容,但它會導致更複雜的方案具有更弱的屬性(例如,自我修復和分佈式區塊構建變得更加困難)
哈希和IPA 都不兼容點評估預編譯的廉價實現。因此,基於哈希或IPA 的實現將無法有效地使ZK Rollup或支持多輪Optimistic Rollup中的廉價欺詐證明。
因此,不幸的是,使用除KZG 之外的任何東西的功能損失和復雜性增加遠大於KZG 本身的風險。此外,任何與KZG 相關的風險都包含在內:一個KZG 故障只會影響Rollup和其他依賴於blob 數據的應用程序,而不會影響系統的其餘部分。
KZG有多“複雜”和“新”?
KZG 承諾是在2010 年的一篇論文中介紹的,並且自2019 年以來已廣泛用於PLONK類型的ZK-SNARK 協議中。然而,KZG 承諾的基礎數學是橢圓曲線運算和配對的基礎數學之上的一個相對簡單的算術。
使用的特定曲線是BLS12-381,它是由Barreto-Lynn-Scott在2002 年發明的。橢圓曲線配對是驗證KZG 承諾所必需的,是非常複雜的數學,但它們是在1940 年代發明並自1990 年代以來應用於密碼學。到2001 年,提出了許多使用配對的加密算法。
從實現複雜性的角度來看,KZG 並不比IPA 更難實現:計算承諾的函數(見上文)與IPA 的情況完全相同,只是使用了一組不同的橢圓曲線點常數。點驗證預編譯更複雜,因為它涉及配對評估,但數學與EIP-2537(BLS12-381 預編譯)實現中已經完成的部分相同,並且非常類似於bn128 配對預編譯(另請參閱:優化的Python 實現)。因此,實現KZG 驗證不需要復雜的“新工作”。
proto-danksharding 實現的不同軟件部分是什麼?
有四個主要組成部分:
1. 執行層共識發生更改(詳見EIP):
-
包含blob 的新交易類型
-
輸出當前交易中第i 個blob 版本化哈希的操作碼
-
Blob 驗證預編譯
-
點評估預編譯
2.共識層共識更改(請參閱repo 中的此文件夾):
-
BeaconBlockBody 中的blob KZG 列表
-
“sidecar”機制,其中完整的blob 內容與來自BeaconBlock 的單獨對像一起傳遞
-
執行層中的blob 版本化哈希與共識層中的blob KZG 之間的交叉檢查
3.內存池
-
BlobTransactionNetworkWrapper(參見EIP 的網絡部分)
-
更強大的反DoS 保護以補償大的blob 大小
4.區塊構建邏輯
-
接受來自內存池的交易封裝器,將交易放入ExecutionPayload,將KZG 放入信標區塊和sidecar中的主體
-
應對二次元手續費市場
請注意,對於最小的實現,我們根本不需要內存池(我們可以依賴第二層交易捆綁市場),我們只需要一個客戶端來實現區塊構建邏輯。只有執行層和共識層的共識變更需要進行廣泛的共識測試,相對輕量級。在這樣的最小實現和所有客戶端都支持區塊生產和內存池的“完整”部署之間的任何事情都是可能的。
proto-danksharding 多維費用市場是什麼樣的?
Proto-danksharding 引入了一個多維的EIP-1559 費用市場,其中有兩種資源,gas 和blob,具有單獨的浮動gas 價格和單獨的限制。
也就是說,有兩個變量和四個常量:
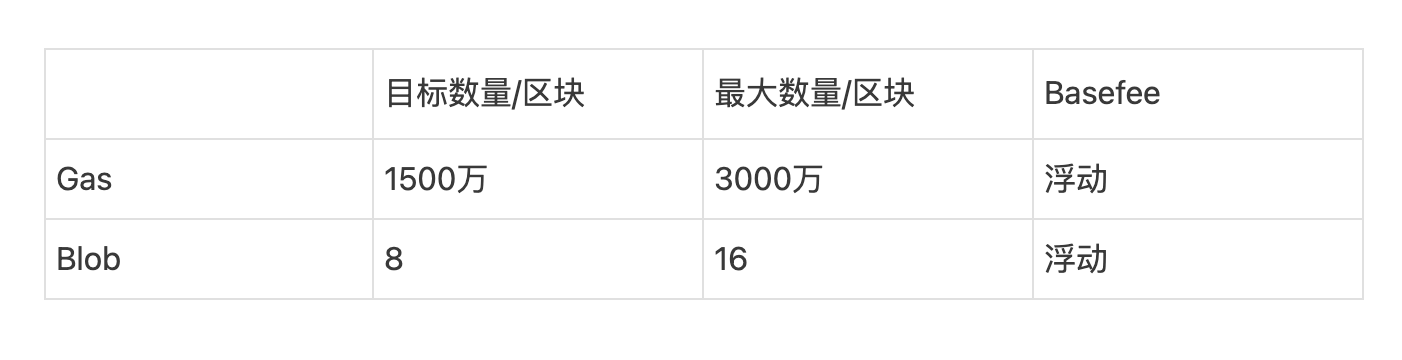
blob 費用以gas 收取,但它是可變數量的gas,它會進行調整,以便從長遠來看,每個區塊的平均blob 數量實際上等於目標數量。
二維性質意味著區塊構建者將面臨一個更難的問題:與其簡單地接受具有最高優先級費用的交易,直到它們用完交易或達到區塊gas限制,他們將不得不同時避免達到兩個不同的限制。
這是一個例子。假設gas 限制為70,blob 限制為40。 mempool 有很多交易,足以填滿區塊,有兩種類型(tx gas 包括per-blob gas):
-
優先費5 per gas, 4 blobs, 4 total gas
-
優先費3 per gas, 1 blob, 2 total gas
遵循幼稚的“降低優先費用”算法的礦工將用第一種類型的10 筆交易(40 gas)填充整個區塊,並獲得5 * 40 = 200 gas的收入。因為這10 筆交易填滿了blob完全限制,他們將無法包含更多交易。但最優策略是採取第一種類型的3 筆交易和第二種類型的28 筆交易。這為您提供了一個包含40 blob 和68 gas的塊,以及5 * 12 + 3 * 56 = 228 的收入。
執行客戶端現在是否必須實施複雜的多維背包問題算法來優化他們的區塊生產?不,有幾個原因:
-
EIP-1559 確保大多數區塊不會達到任何一個限制,因此實際上只有少數區塊面臨多維優化問題。在內存池沒有足夠(足夠的付費)交易達到任一限制的通常情況下,任何礦工都可以通過包含他們看到的每筆交易來獲得最佳收入。
-
在實踐中,相當簡單的啟發式方法可以接近最優。在類似的情況下,請參閱Ansgar 的EIP-4488 分析以獲取有關此的一些數據。
-
多維定價甚至不是專業化帶來的最大收入來源——MEV 是。通過專用算法從鏈上DEX 套利、清算、搶先NFT 銷售等中提取的專用MEV 收入佔“可提取收入”(即優先費用)總額的很大一部分:專用MEV 收入似乎平均約為0.025 ETH每個區塊,總優先權費用通常在每個區塊0.1 ETH 左右。
-
提議者/建造者分離是圍繞高度專業化的區塊生產而設計的。 PBS 將區塊構建過程轉變為拍賣,專業參與者可以競標創建區塊的特權。常規驗證者只需要接受最高出價。這是為了防止MEV 驅動的規模經濟蔓延到驗證者中心化,但它處理了所有可能使優化區塊構建變得更加困難的問題。
由於這些原因,更複雜的費用市場動態不會大大增加中心化或風險; 事實上,更廣泛應用的原則實際上可以降低DoS攻擊的風險!
指數型EIP-1559 blob 費用調整機制如何運作?
今天的EIP-1559 調整基礎費用b 以達到特定的目標gas使用水平t,如下所示:
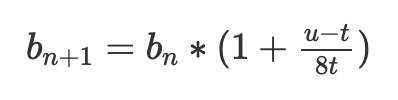
其中b(n) 是當前區塊的基本費用,b(n+1) 是下一個區塊的基本費用,t 是目標,u 是使用的gas。
這種機制的一個大問題是它實際上並不針對t。假設我們得到兩個區塊,第一個u=0,下一個u=2t。我們得到:

儘管平均使用量等於t,但基本費用下降了63/64。所以basefee只有在使用率略高於t時才會穩定; 在實踐中顯然高出約3%,儘管確切的數字取決於方差。
一個更好的公式是指數調整:
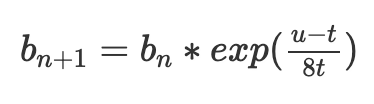
exp(x) 是指數函數e^x,其中e≈2.71828。在x 值較小時,exp(x)≈1+x。但是,它具有與交易置換無關的便利特性:多步調整
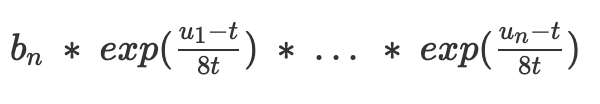
僅取決於總和u1+…+u/n,而不取決於分佈。要了解原因,我們可以進行數學運算:
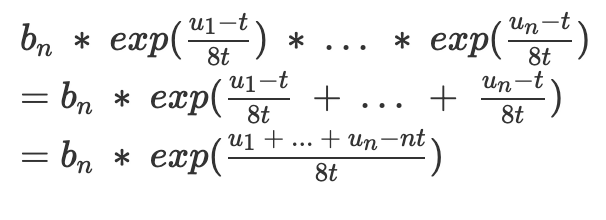
因此,包含的相同交易將導致相同的最終基礎費用,無論它們如何在不同區塊之間分配。
上面的最後一個公式也有一個自然的數學解釋:術語(u1+u2+…+u/n-nt) 可以看作是多餘的:實際使用的總gas與打算使用的總gas之間的差異。
當前基本費等於
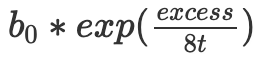
的事實清楚地表明,超出部分不能超出一個非常窄的範圍:如果超過8t∗60,那麼basefee變為e^60,高得離譜,沒有人可以支付它,如果它低於0,則資源基本上是免費的,並且鏈將被垃圾郵件發送,直到超出部分回到零以上。
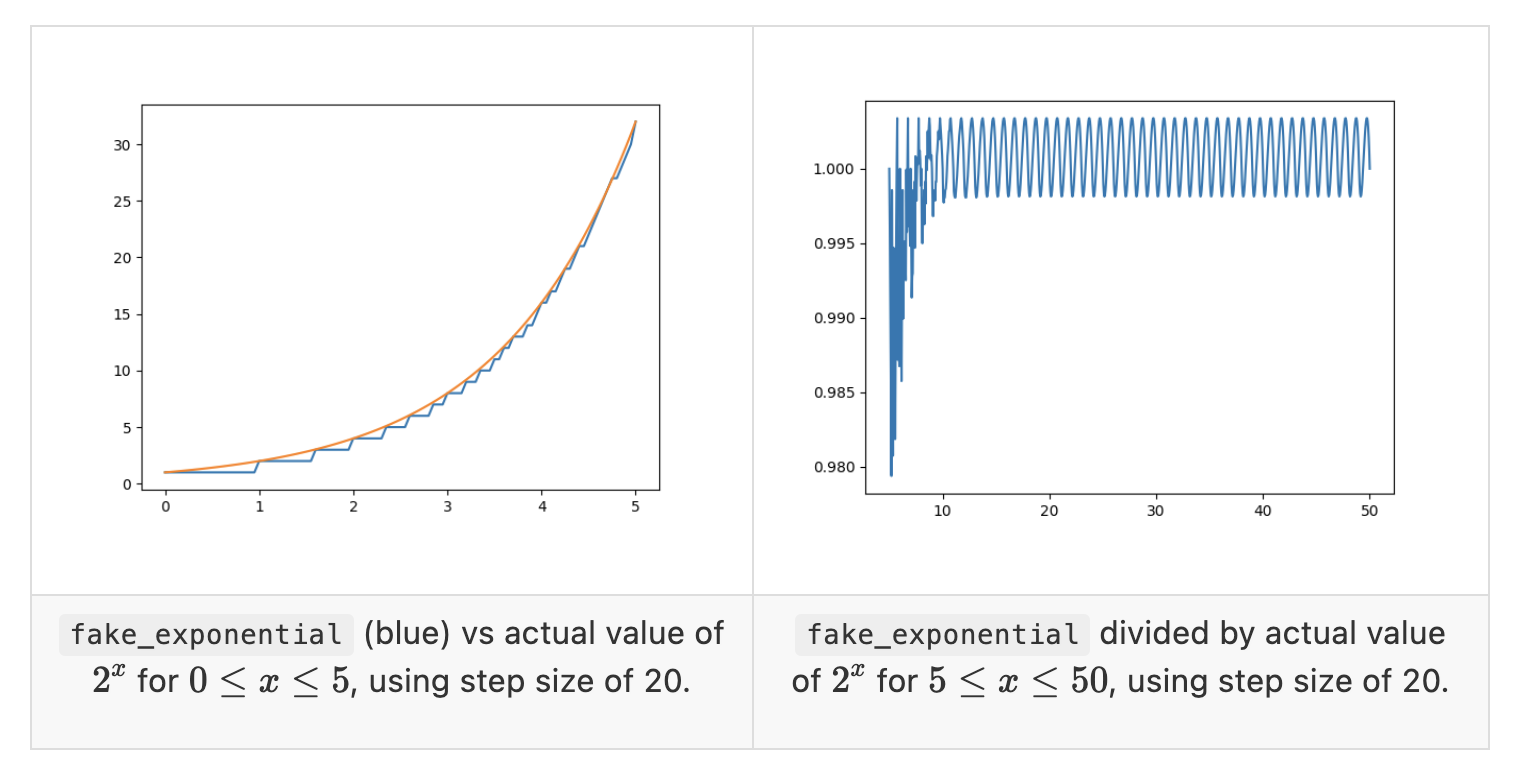
調整機製完全按照這些術語工作:它跟踪實際總計(u1+u2+…+u/n) 併計算目標總計(nt),並將價格計算為差異的指數。為了使計算更簡單,我們不使用e^x,而是使用2^x; 事實上,我們使用了2^x 的近似值:EIP 中的fake_exponential 函數。假指數幾乎總是在實際值的0.3% 以內。
為了防止長時間的未充分使用導致長時間的2倍完整區塊,我們添加了一個額外的功能:我們不會讓多餘的區塊低於零。如果actual_total 低於targeted_total,我們只需將actual_total 設置為等於targeted_total。在極端情況下(blob gas 一直下降到零),這確實破壞了交易順序的不變性,但增加的安全性使得這是一個可接受的折衷方案。
還要注意這個多維市場的一個有趣的結果:當最初引入proto-danksharding 時,最初可能只有很少的用戶,因此在一段時間內,一個blob 的成本幾乎肯定會非常便宜,即使是“常規的” 以太坊區塊鏈活動仍然很昂貴。
作者認為這種費用調整機制比目前的方法更好,因此最終EIP-1559 費用市場的所有部分都應該轉向使用它。
有關更長更詳細的解釋,請參閱Dankrad 的帖子。
fake_exponential 是如何工作的?
為方便起見,這裡是fake_exponential 的代碼:
def fake_exponential(numerator: int, denominator: int) -> int: cofactor = 2 ** (numerator // denominator) fractional = numerator % denominator return cofactor + ( fractional * cofactor * 2 + (fractional ** 2 * cofactor) // denominator ) // (denominator * 3)
這裡是用數學重新表達的核心機制,去掉了四捨五入:
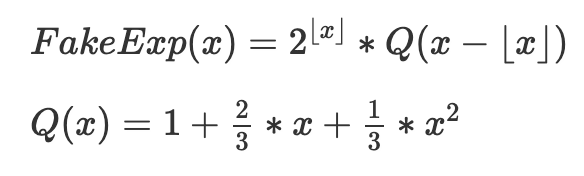
目標是將(QX)的許多實例拼接在一起,其中一個為每個 [2^k,2^(k+1)] 範圍適當地移動和放大。 Q(x) 本身是0≤x≤1 的2^x 的近似值,選擇用於以下屬性:
-
簡單性(這是一個二次方程)
-
左邊緣的正確性(Q(0)=2^0=1)
-
右邊緣的正確性(Q(1)=2^1=2)
-
平滑斜率(我們確保Q'(1)=2∗Q'(0),因此Q 的每個移位+縮放副本在其右邊緣的斜率與下一個副本在其左邊緣的斜率相同)
最後三個要求給出三個未知係數的三個線性方程,上面給出的Q(x) 給出了唯一的解。
近似值出奇地好; 對於除最小輸入之外的所有輸入,fake_exponential 給出的答案在2^x 實際值的0.3% 範圍內:
proto-danksharding 中有哪些問題仍在爭論中?
注意:此部分很容易過時。不要相信它會就任何特定問題給出最新的想法。
-
所有主要的Optimistic Rollup都使用多輪證明,因此它們可以使用(便宜得多的)點評估預編譯而不是blob 驗證預編譯。任何真正需要blob 驗證的人都可以自己實現它:將blob D 和版本化哈希h 作為輸入,選擇x=hash(D,h),使用重心評估計算y=D(x) 並使用點評估預編譯驗證h(x)=y。因此,我們真的需要blob 驗證預編譯,還是可以直接刪除它並只使用點評估?
-
該鏈在處理持久的長期1 MB+ 塊方面的能力如何?如果風險太大,是否應該在一開始就減少目標blob 數?
-
blob 應該以gas 還是ETH(被燒毀)計價?是否應該對費用市場進行其他調整?
-
應該將新的交易類型視為blob 還是SSZ 對象,在後一種情況下將ExecutionPayload 更改為聯合類型? (這是“現在做更多工作”與“以後做更多工作”的權衡)
-
可信設置實現的確切細節(技術上超出EIP 本身的範圍,因為對於實現者來說,這種設置“只是一個常數”,但仍然需要完成)。
作者:Vitalik Buterin


