
推薦理由:
“我是誰”,是任何一個有自我意識的人對於他自己的一種自覺意識,在這種自覺意識中,他成為他自己思考的對象。身份,是一個綜合性的複雜概念,在心理學上構成一個人或群體的特質、信念、個性、相貌和表達。鏈上身份、數字身份、網絡身份的概念如何表達,在去中心化敘事中,我們需要什麼樣的身份管理體系?去中心化身份(DID)如何優於現有的web2身份體系?
我們在web2世界的孤島裡存活了太久,隱私洩露、信息濫用、算法剝削,本文試圖探討,我們如何在Data sovereignty的領導下,通過分佈式身份表的方式,構建出全新的”I own my data”的身份體系。
一個人寫的關於“身份”的文章越多,這個詞就越會成為一個深不可測的術語,因為它無處不在。 ——Erik Erikson
正如創造“身份危機”一詞的心理學家埃里克·埃里克森(Erik Erikson) 所說,我經常感覺這是真的:身份是一個模糊的概念,有很多內涵,其含義高度依賴於上下文,這在Web3 中也不例外。
在這篇文章中,我將嘗試解決這個問題:建立一個框架——一個將網絡中的身份視為主要用於存儲、管理和檢索信息的工具的框架。
它不會澄清該術語的所有使用和誤用,但我希望它有助於清晰地思考身份如何塑造Web3,應用程序如何為此構建,以及這些選擇對我們的網絡體驗意味著什麼。
名字裡有什麼? “身份”的三種含義
當人們談論身份時,他們通常指的是三個相關但完全不同的範圍之一:a)唯一標識符,b)一個實體(entity)的整體視圖,或c)關於實體的特定上下文。
唯一標識符在任何社交環境中都至關重要。在可以假定熟悉的朋友、家人或小部落(低於鄧巴的150 人閾值)中,名字是一個足夠的“標識符”。除此之外,更嚴格的標識符有助於使參與者在更廣泛的系統中“清晰可見”。各州實施身份證來管理稅收、徵兵和社會計劃。 Web 應用程序在用戶表中有用戶ID,用於跟踪、管理和服務其客戶。
整體視圖是指有關用戶或其他參與者的所有可能信息。嘗試將大量數據附加到唯一標識符可以創建有關人員或實體的豐富信息集。在Facebook 和谷歌的用戶數據庫、印度的Aadhaar 和中國的社會信用體系,以及像Segment 和LiveRamp 這樣的客戶數據平台中都可以看到對這一點的追求。
特定的上下文可以表示為整體視圖的許多子集中的任何一個。 KYC 或身份驗證——一個價值數十億美元的行業——是關於驗證某人是否是他們所聲稱在國家系統內的唯一可驗證的身份。同樣,身份驗證、反欺詐、反垃圾郵件和信用算法是專注於整體視圖中信息子集的特定服務。
自相矛盾嗎?很好,我自相矛盾,那麼我很強大,我包含許多人。 ——沃爾特·惠特曼
身份:將信息附加到標識符
唯一標識符是必要的,但就其本身而言毫無用處。它們幾乎總是用於跳轉到某些信息。這可能是狀態記錄中的名稱和地址、文件系統中的文檔、應用程序數據庫中的密碼,或者區塊鏈上的代幣餘額或交易歷史。在任何情況下,標識符都是有用的,因為它傳達了相關信息。
許多情況需要檢索或驗證鏈接到標識符的特定上下文。例如,Gitcoin 需要一個“身份系統”來防止外界對其Grants 平台的攻擊。在實踐中,他們需要將人格證據(KYC 驗證、推特賬戶)映射到唯一標識符。他們掌握的關於該個體獨特或欺詐的可能性的信息越多,他們的平台就可以運作得越好。
身份的整體觀點總是不完整的——就像我們永遠無法完美地描述我們在空間中的“真實自我”一樣,我們的數字化自我也永遠不會完全一致或全面。但是圍繞單個(或一組鏈接)標識符收集的數據越多,我們針對任何給定上下文能使用的信息就越多。
共同點是: 身份系統創建了將信息與唯一標識符可靠關聯的能力。身份系統越可靠,那它就越有用,並且:
-
越可靠:可用、容錯、防篡改
-
越靈活:可以處理更多類型的信息
-
越易用:可以在更多的上下文中使用,統一而不是分散信息
不同的環境需要不同的隱私和安全考慮;比如是通過第三方的可審計性還是通過去中心化獲得信任;事更強調一致性還是可用性。但在最原始的層面,如果身份系統有可能使更多信息更清晰、更一致,它就會變得更強大。
數字身份作為網絡的鑰匙
最大程度上簡化來說,網絡是運行在硬件、代碼和數據上。您訪問的每個網站都有用代碼編寫的邏輯和規則,並且幾乎所有網站都填充了以數據編碼的信息。這些數據——無論是今天的新聞、你朋友的推文還是你最近的電子郵件草稿——都必須在您到達該站點時準確可靠地檢索。這是通過標識符完成的。
正如唯一標識符在沒有附加數據的情況下沒有用處一樣,如果不能在正確的時間檢索到網絡上的數據,它也不是很有用。唯一標識符,以及圍繞它們構建的路由表和邏輯,用於在網絡上組織填充它的數據。誰在創建這些標識符?誰在圍繞它們組織數據?
今天,它幾乎是您訪問的每一個站點、您使用的每個產品或您遇到的公司。標識符列在他們創建的數據庫中,大部分是私有的,並且與其他所有公司的數據庫隔離開來。數據放在那裡,也在那裡鏈接。這通常圍繞用戶表進行組織:每一行代表一個用戶,每一列代表一種數據,並且該表存儲或指向每個用戶對該類型數據的記錄。
應用程序數據庫上的傳統用戶表
這個身份系統符合我們上面的標準嗎?
-
可靠: 非常可靠,但 沒有可審計性,極易受到黑客攻擊和錯誤的影響
-
靈活:數據庫類型可以鏈接以處理各種信息,儘管它可能有點混亂
-
可用: 每個應用程序都需要自己的標識符,信息(和它的管理)非常分散、冗餘和低效
從宏觀的角度來看,這對於網絡來說是一個非常糟糕的身份系統——因為它不是一個身份系統,它是許多不同的身份系統。它使信息碎片化,限制了它對每個參與者的價值和使用。 (這也為囤積和濫用超出本文範圍的用戶數據創造了可怕的誘因)。
從更微觀的角度來看,在用戶使用任何給定應用程序的體驗中,是應用程序負責用戶的身份——他們的唯一標識符、與之關聯的數據以及它們之間的可靠鏈接。之所以出現這種情況,僅僅是因為目前我們還沒有其他選擇。這在直覺上是錯誤的。
去中心化身份:Web3 如何超越Web2
區塊鍊是分佈式賬本技術(DLT)的一種形式,基本上是共享數據庫。共享數據庫似乎是放置統一用戶表的好地方,並且擺脫了每個應用程序創建自己的身份系統的陳舊需求。
這是去中心化身份的未來願景,也是Web3 願景的核心支柱:每個用戶和構建者都可以控制自己的數據、價值、關係和信息。在這個願景中,每個用戶都成為他們自己數據的統一發現點,從而在應用程序之間創建重複使用和可組合性。這創造了共享網絡效應、互操作性和復合體驗,孤立的集中式應用程序無法與之競爭。
原始版本的願景設想了一個統一的用戶註冊表(在一個DLT 上)和一種為所有應用程序向該註冊表添加信息的標準方法。用戶可以控制他們自己的加密的主權地址(或標識符),他們使用該地址簽署所有數據,以在開放環境中創建數據所需的信任。我們讓每個應用程序使用相同的註冊表(區塊鏈)並使用標準格式(NFT)發布數據,理論上我們處於身份涅槃——一個將社交圖譜帶到應用程序的網絡,與受眾和社區無縫互動平台,並在新產品和服務可用後立即在它們之間輕鬆移動,因為它們都是互操作的。
然而,這種去中心化身份的願景——依賴於地址和NFT,在實踐中很快就崩潰了。它過於死板,不能作為身份系統很好地管理和路由到大規模數據。在我們的標准上:
-
可靠:今天的區塊鏈,專為稀缺金融資產達成共識而設計,無法擴展以滿足大量數據的規模;他們也不能處理鏈下的(或部分的)更新
-
靈活: 大多數鏈上賬本支持新的數據結構和標準,但在共識系統約束的範圍內。這限制了該系統的用例和應用程序
-
可訪問性: 單個註冊表將用戶和應用程序限制為單個DLT 或區塊鏈,而我們會不可避免地使用不同的鍊和網絡
我們可以從原始密碼身份系統的缺陷中學習,以了解更可靠的去中心化身份系統需要什麼。很明顯,單一的註冊表(索引)、標識符標准或數據結構標準總是過於死板。
它必須與各種標識符一起使用。它必須對一組靈活、可擴展的數據模型和結構開放。它必須跨網絡環境和網絡工作。它的設計應該遵循身份是關於管理和發現信息的原則,因此它應該把數據放在首位。
Web3 將如何處理用戶表
為了管理數據,我們需要一個協議,以便於存儲、發現和路由有關標識符的信息。為了讓Web3 兌現其承諾,該路由表應該a) 是統一的,而不是被應用程序或任何其他邊界孤立,並且b) 具有主權,將數據控制權直接授予每個標識符。
這表明了一個簡單的設計:每個標識符都維護一個包含自己數據的表。統一的,這些以身份為中心的用戶表形成了互聯網的分佈式用戶表。這個分佈式用戶表不是一個實際的表,而是一個虛擬表,它由與傳統用戶表的部分相對應的幾個組成部分產生:
-
標識符:去中心化標識符不應是應用程序數據庫中的條目,而應該是可證明的唯一性和密碼學控制的。可訪問性需要在各種網絡中接受多種形式的標識符——類似於分散標識符的DID 標準。
-
數據結構:類似於應用程序開發人員如何定義自己的數據結構,分散的數據層需要使開發人員能夠定義自定義數據模型,同時確保這些模型可複用和公開存儲。
-
索引:當應用程序定義數據模型時,用戶帶來他們的標識符。標準索引可以將這些元素組合到一個用戶表(或應用程序表)中,以便當用戶與應用程序交互(創建數據)時,該信息被適當地編目以供將來路由。這會創建一個易於發現的用戶數據記錄——映射到數據模型並以加密方式關聯到標識符。
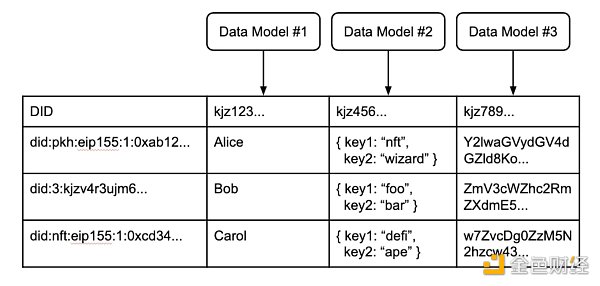
一個分佈式虛擬用戶表,具有來自不同網絡的各種DID、開發人員定義的數據模型以及與每個相關的記錄
對於這個分佈式用戶表,來自@Ceramic 博客:“每個用戶都可以完全自主地控制他們的行,並且可以將這些數據帶到他們訪問的每個應用程序中。如果一個應用程序想知道哪些數據可用以及如何使用它,他們可以引用包含名稱、描述和其他元數據的數據模型。”
利用分佈式用戶表構建
這個基於DID 和數據模型以及分佈式用戶表的身份系統如何符合我們的標準?
可靠: 在任何人都可以參與的公共網絡集合上運行,包括分區或本地網絡
靈活: 適用於開發人員可以定義的任何數據結構
可用性: 適用於任何開放的網絡和唯一標識符
該系統還具有許多附加屬性,這些屬性構成了高度靈活和可靠的身份系統。包括:
假名優先:無需創建帳戶或驗證即可開始,用戶(或其他實體)只需攜帶一個加密密鑰對,即可開始圍繞它積累信息
可生成:信息隨著時間的推移而積累,創造出一個新興的整體身份
可組合的:無需預先定義的集成或可移植性標準,就可以跨上下文發現和共享信息
可分離和選擇性:信息集可以加密或混淆,或跨多個標識符分離,或以其他方式可根據控制器的偏好進行分割
如果“身份系統能夠將信息與唯一標識符可靠地關聯起來”,如前所述,我們需要一個互聯網身份系統,它建立了管理和路由到可信數據的最低限度協議,其他一切都留給獨創性和應用程序開發人員的多樣性。
我們希望避免孤立的系統——包括特定的應用程序、註冊表或區塊鏈——並最大限度地提高數據類型的靈活性。我們需要一個易於使用的系統,讓我們能夠構建具有豐富數據形式的應用程序,將這些數據與適當的標識符相關聯,並從我們的身份和集體信息中獲得最大的效用。
這種技術和模式較新,但發展迅速。成千上萬的Web3 開發人員已經在使用Spruce 等工具和Ceramic 等基礎設施構建此身份系統。這種身份和數據模型不僅可以幫助開發人員比以往任何時候都更快地構建更強大和可擴展的Web3 應用程序,而且Web3 可以共同構建Web2 平台無法與之競爭的可組合數據宇宙。
譯者筆記:
web3與元宇宙的未來模糊了鏈下世界與鏈上空間的界限,因此對於身份管理體系的構建,如何建立鏈下身份與鏈上數據之間的映射關係,是開拓新型社會體系的數字生活空間的必做功課與立足之本。
孤立的身份系統對未來無縫的Dapp體驗是一種障礙,構建分佈式用戶表有利於打通現有的應用孤島,如何在靈活性、開放性、可靠性之間找到DID系統的均衡,作者推薦了Ceramic 等基礎設施,我們會在之後的相關文章中做出項目分析。
H.Forest Ventures對每一篇分享的內容都會盡最大努力去全面了解相關信息,如果對本文內容有任何想法均可聯繫H.Forest Ventures團隊。
Effective communication is everything.