
注:本文基於Optimism 團隊研究員、前以太坊基金會研究員Protolambda 於今年7 月在EthCC Paris 所做的演講進行編譯,並參考了其他優秀的文章進行整理(在文末列出)。
引入
合併(The Merge) 的關鍵里程碑已於9 月15 日完成,根據Vitalik 在2021 年底發布的以太坊協議開發路線圖,下一個重要階段是The Surge —— 解決以太坊可擴展性問題,降低交易費並提高吞吐量。 The Surge 圍繞以rollup 為中心的路線圖開發,在繼承以太坊網絡安全性的同時,進一步提高L2 rollup 的可擴展性。
cr:https://twitter.com/ethereumcn/status/1466731320537612296?s=46&t=9yOAkX-0nd_xvSJIJ8_Pmw
本文主要介紹這一技術路線圖中的一個關鍵工作:EIP-4844 Proto-danksharding,它如何使得rollup 所需要使用的數據變得更加便宜以及獲得更多存儲數據的容量(capacity)。 EIP-4844 是對以太坊網絡的一次升級,它將使得rollup 的開銷降低10-100 倍。它通過向以太坊引入一種新的交易類型來實現,這種交易類型攜帶短暫存在的blob 數據。這種新的數據存儲方式是為了存放rollup 的一些數據,它會比目前calldata 的方式便宜得多。此外,4844 是完整版Danksharding (在前面的基礎上再擴容10-100 倍!) 的前提條件。
以太坊分片技術路線圖
對於以太坊分片設計的現狀,前以太坊基金會開發者Protolambda 做了一個簡潔的描述:
帶有“crosslink” 的可執行的“分片鏈” 已被淘汰,而是更新為:在信標鏈中實現EVM;使用“數據可用性採樣” 的以rollup 為中心的以太坊路線圖,擴容以太坊基礎層而無需增加應用環境的複雜性。
之所以做這樣的簡化,主要有兩個原因:
-
避免添加更多的L1 複雜性。分片的規範已重寫多次,許多研究都過於抽象乃至實現的日子遙遙無期,並且讓L1 變得僵化。
-
而如果能夠巧用封裝複雜性和應用區塊鏈模塊化結構,以太坊基礎層作為rollup 的數據可用性層,將計算的重任交給作為執行層的L2。這樣L1 只專注於解決數據問題,不同的rollup 團隊解決各自的開發問題,從而大大地提升擴容的效率。
封裝複雜性和模塊化在以太坊上的應用
模塊化區塊鍊是擴容中一個非常重要的概念。模塊化意味著“封裝複雜性”,這允許我們在不同的模塊中添加可擴展性。根據Vitalik 的文章《協議設計中的封裝複雜性和系統複雜性權衡》中的解釋,當一個系統包含著一些複雜的子系統,但對外提供一個簡單的“接口”時,就會出現“封裝複雜性”;當系統的不同部分甚至不能完全分離,並且相互之間具有復雜作用時,就會出現“系統複雜性”。
2020 年10 月,Vitalik 發布了文章《以Rollup 為中心的以太坊路線圖》,確定了為L2 rollup 擴容協議保駕護航的基本思路:將執行層(L2) 和數據層(L1) 分離,以太坊共識層(L1) 為其提供安全保障。
分離執行層和數據層的好處是,數據層的發展可以保持相對穩定,而執行層(即rollup) 則可以更加多自主性、更加創新地快速迭代,無需獲得L1 核心開發者社區的的許可進行升級。
上面簡單介紹了以rollup 為中心的以太坊路線圖中的區塊鏈分層情況,那在PoW 與PoS、L1 與L2 之間的模塊化架構是怎樣的呢?
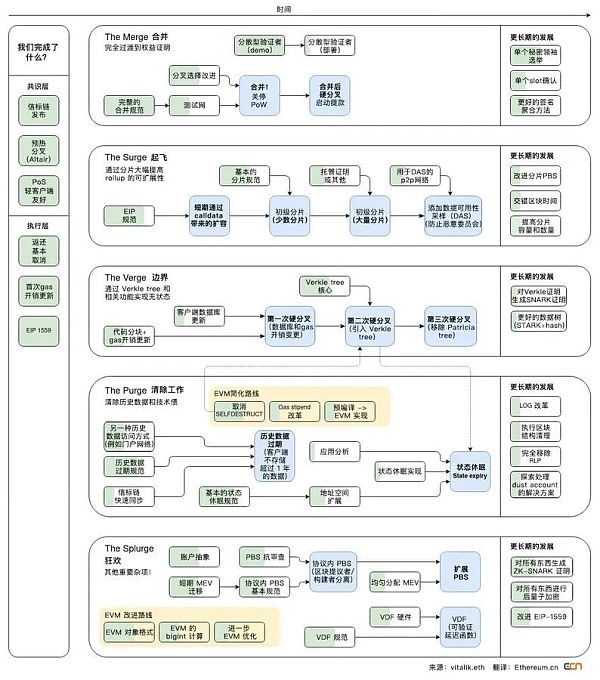
cr: Protolambda
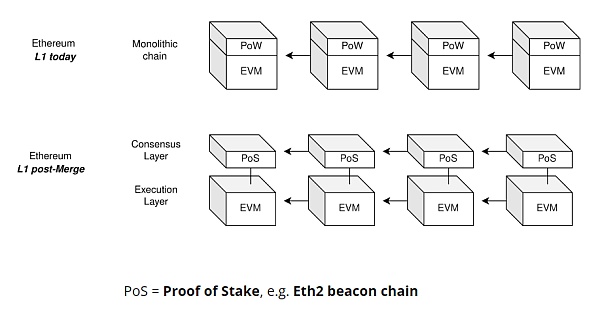
圖中展示了合併前的單一型PoW 鏈vs. 合併後的L1 共識層(PoS) 和L1 執行層(EVM) 之間的模塊化關係。而PoS 和EVM 之間的合併技術是通過一個叫做”Engine API“ 的東西實現的。下圖是合併後完整客戶端的樣子,中間的API 使得以太坊共識層(PoS) 和執行層(PoW) 之間可以實現通信。這是以太坊主網上的首個模塊化設計。
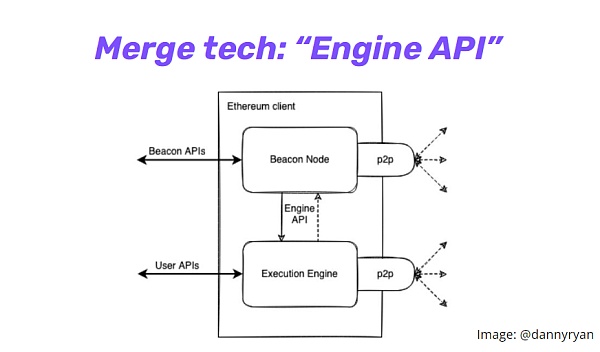
cr: Danny Ryan
那麼L1 和L2 之間是如何連接的呢?
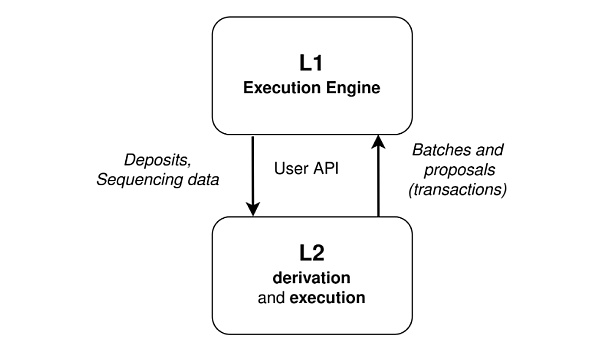
cr: Protolambda
可以看到上圖中,L1 和L2 之間會有一個API,它們分別是兩套軟件。
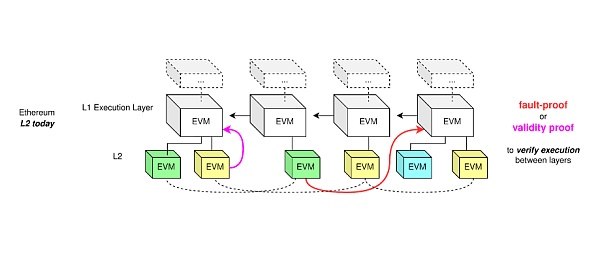
cr: Protolambda
這是以太坊加上欺詐證明和有效性證明之後的示意圖,相當於將L2 作為一個執行層連接以太坊EVM,然後你維持當前的L2 執行層。但這也會有一個問題,因為就算可以堆疊執行層,但是這樣效率不高,所以我們需要一個數據層。
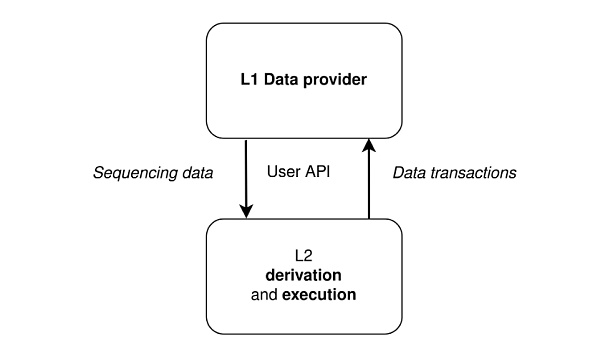
cr: Protolambda
如上示意圖,L1 作為數據層,L2 負責執行計算。
數據可用性是擴容的關鍵瓶頸
以太坊目前面臨的一大瓶頸就是數據可用性,這是我們接下來一年裡增加可擴展性所需要提高的範疇。
首先我們看一筆rollup 交易包含哪些開銷:
-
執行開銷(網絡中所有節點執行交易並且驗證其有效性的開銷)
-
存儲/狀態開銷(使用新的值更新區塊鏈“數據庫” 的開銷)
-
數據可用性開銷(將數據發布至L1 的開銷)
其中,前兩筆開銷都是Rollup 網絡上的花費,佔總開銷的比例非常低。而數據可用性開銷才是擴容的關鍵瓶頸。
我們為什麼需要這種數據呢?
保證數據的可用性可以讓任何人都可以無需許可地重構狀態。
L2 提供的可擴展性是通過將執行檢查和保證數據安全這兩項工作分離而獲得的。這讓我們有機會同步以及獲取驗證狀態的數據,而這個過程中定序器不會對其有直接影響。
目前,rollup 上傳數據到L1 都是以calldata 的形式。這種方式非常貴,calldata 是一種沒有修剪過的非常沒有效率的數據形式,需要以一種迂迴的方式將數據存放在以太坊,一個非0 字節就需要花費16 gas。所以出現了兩種粗暴的降低這種開銷的方法:
-
calldata 壓縮,不少rollup 項目都已經開始研究壓縮calldata 的算法並集成到他們的系統中。
-
EIP-4488,將每個非0 字節的calldata 開銷從16 gas 降低到3 gas。
但是使用calldata 的方式始終是不可持續的,因為這會帶來L2 不需要的遺留開銷。那麼有沒有更優雅的方法呢?
數據可用性、數據可恢復性、長期數據可用性等等這些不同類型的名詞,它們之間的差異就是可用性的時長各不同。譬如說,你希望這些數據的可用時間足夠長來挑戰定序者、重構狀態。事實上,你不需要數據是永遠可用的。在以太坊的假設中,存儲超過一年的數據,用戶可能在某個地方找到它,可能會將它同步到某個點,而不需要一直追溯到創世區塊。
而EIP-4844 這個提案則是讓我們能夠對數據做一些修剪,因為在這個提案下,數據只需要保留其可用性足夠長的時間,讓誠實的網絡參與者重構完整狀態並且挑戰定序器。
EIP-4844 Proto-danksharding
EIP-4844 提議什麼呢?
將數據可用性添加至以太坊且不會破壞可組合性,也就是說我們可以在L1 有一個執行層,同時可以在上面添加數據可用性。
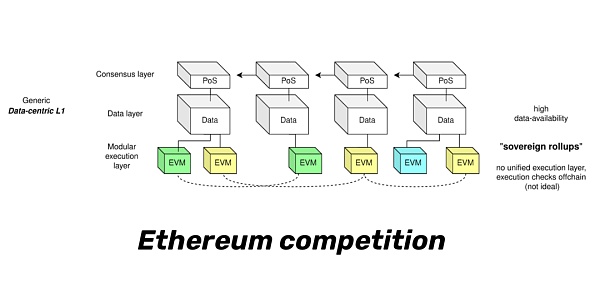
cr: Protolambda
如圖所示,我們現在有L1 共識層、L1 執行層、L1 數據層、L2 執行層。在這樣的分層架構下,我們獲得了封裝性,然後我們不同的團隊可以針對不同的問題,並單獨地提高某一層的可擴展性。
引入新的交易類型Blob-carrying Transaction
EIP-4844 引入一種新的交易類型,這種交易類型與普通以太坊交易相比多了一個blob 的位置用來存放L2 的數據。比較獨特的是,Blob 數據在一個月之後就會被節點刪除,從而很大地節省了存儲空間。
那麼我們如何添加這種數據呢?
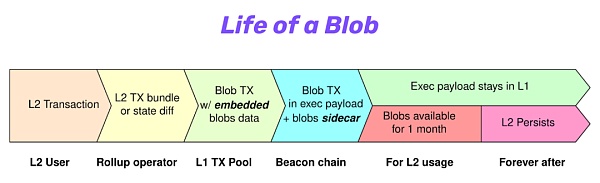
圖:一個“Blob” 的生命週期,cr: Protolambda
我們稱這種數據為“blob”,這是一種非常模糊的數據形式,類似於一種字符串。 “Blob” 會被附加到一筆交易中,這筆交易就像其他交易一樣在以太坊系統中運行。
但附加的內容具有自己的生命週期。請看上圖圖示:首先,rollup 運營者會納入普通的交易,生成L2 交易捆,目前是通過calldata 的方式將交易batch 直接發送至L1。而有了4844 之後,新增了一種攜帶“blob” 數據的交易類型“blob 交易”。這個“blob 交易” 負責支付交易費,將承諾(commitment) 包含進交易中以有效地證明該blob 中存在的任意數據。但是附加的內容(即blob 數據) 本身是與“blob 交易” 分離的,可以把這種數據看作是一個挎鬥(sidecar)。
(Sidecar 在不改變主應用的情況下,會起來一個輔助應用,來輔助主應用做一些基礎性的甚至是額外的工作。這個sidecar 通常是和主應用部署在一起,所以在同樣環境下運行。這其中還有一些性能上的考慮,sidecar 如果和主程序網絡通信上有延遲就會造成性能問題。這個輔助應用不一定屬於應用程序的一部分,而只是與應用相連接。這就像是挎鬥摩托車,每個摩托車都有自己獨立的輔助部分,它隨著主應用啟動或停止。因為sidecar 其實是一個獨立的服務,我們可以在上面做很多東西,例如sidecar 之間相互通信、或者通過統一的節點控制sidecar ,形成網絡服務Service Mesh。來源:https://blog.csdn.net/lxlmycsdnfree/article/details/126286243)
blob data vs. calldata
要想知道兩者的區別,我們首先要了解以太坊合併前以及合併後的區塊組成。
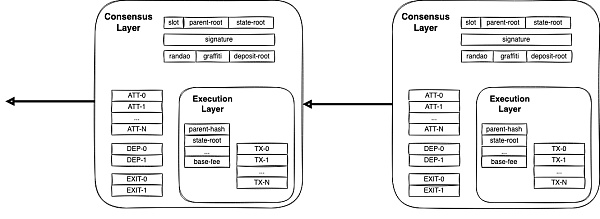
cr: Danny Ryan
上圖為合併後的信標區塊,執行層被包裹在共識層裡,而EL 最核心的部分就是ExecutionPayload (執行負載)。
EL 和CL 分別負責兩個主要功能,前者執行EVM,後者負責PoS 共識。信標區塊中包含EL 的ExecutionPayload,外層的狀態根為信標鏈狀態的更新,EL 內的狀態根則是EVM 賬戶狀態更新。
現在我們重新來看Calldata 和blob data 之間的區別。
首先,這兩種數據類型有不同的生命週期。 Calldata 存在於“execution payload” 中(普通的L1 交易),而blob 數據存儲於共識層中。也就是說“blob” 存儲在一個Prysm 節點或者Lighthouse 節點中,而不是在Geth 中。然後這些共識層節點會在特定一段時間之後對blob 數據進行修剪。
“Blob” 在網絡的運作流程如下圖所示:
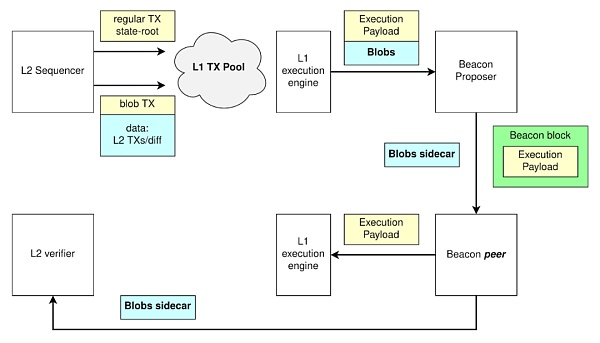
cr: Protolambda
-
定序器提供數據->
-
L1 敲定數據->
-
將Blob sidecar 從Blob 交易中分離出來->
-
Blob 交易中的執行發生在Execution Payload 中->
-
rollup 驗證狀態所需要的數據則去到另一側的數據庫中,L2 驗證者可以下載這些sidecar 並同步L2。
Blob 有兩個顯著的特點:
第一就是不被合約讀取,下圖是一筆blob 交易的樣子,可以看到EVM 不會讀取blob。
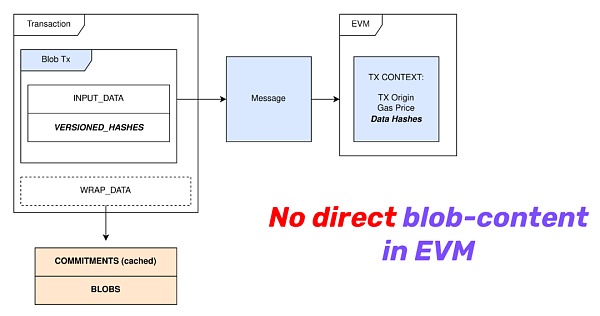
cr: Protolambda
就像前面所介紹那樣,blob data 存儲在共識層節點中,和calldata 需要被合約讀取所消耗的資源相比要便宜得多。
第二就是,一個月後,共識層節點會對blob 內的值進行刪除。區塊空間一直以來主要都由交易占用著,而隨著L2 的發展,L1 基礎層轉而成為L2 的數據層,calldat 就會佔用更多的區塊空間。能夠定期刪除blob 數據的話,可以很好地解決L1 狀態膨脹的問題。
總結
隨著Rollup 技術的逐漸完善,數據可用性成為各個解決方案更進一步擴容的瓶頸。而L1 作為一個為Rollup 保駕護航的基礎層,它不僅可以為rollup 提供安全保障,還可以充當rollup 的數據層,讓可擴展性實現指數級的提升。 Proto-danksharding 作為完整版Danksharding 的前提條件,通過引入攜帶“blob data” 的交易類型這樣的一個新設計,讓基礎層更無壓力地存放L2 數據,同時不影響數據可用性的安全性。
