

原文:StarkWare 由DeFi 之道編譯
-
rollups 的有效性不受限於L1的吞吐量,使得L2 的TPS 可以很高。
-
在StarkNet 的性能路線圖中,解決了系統中的一個關鍵因素——排序器。
-
性能的改進主要有以下幾點:
-
排序器(Sequencer)的並行化
-
為Cairo 虛擬機(Cairo-VM)提供Rust 語境下的實現
-
在Rust 語境下的排序器
-
證明者(Provers)並不是瓶頸,他們可以處理比現在更多的東西。
簡介
大約一年前,StarkNet Alpha 正式上線了以太坊主網,這時,我們將重心放在了功能的構建上,現在,我們決定將重點轉移到提高性能之上,併計劃通過一系列的步驟來提高StarkNet 上的用戶體驗。
在這篇文章中,我將解釋為什麼有很多優化措施只適用於有效性匯總(Validity Rollups),並分享StarkNet 實施這些措施的計劃和步驟,其中一些計劃已經在StarkNet Alpha 0.10.2 中實現,在討論具體的細節之前,讓我們先來回顧一下限制鏈上性能的原因。
區塊限制:Validity Rollups 與L1
提高區塊鏈可擴展性和TPS 的方法之一是:在解除區塊的限制(比如GAS和區塊大小的限制)同時,保持區塊生成時間的不變。這需要區塊生產者(L1 上的驗證器,L2 上的排序器)提供更高效的服務,因此就需要更有效地執行這些組件,因此,我們將重點轉移到StarkNet 排序器的優化之上,在下文會詳述具體內容。
這裡會有一個問題,為什麼對排序器的優化僅僅對Validity Rollups 有效,換句話說,為什麼我們不能在L1 上以相同的方法改進,避免有效性匯總(Validity Rollups) 有復雜性?在下一節內容中,對這一問題將進行回答。
為什麼L1吞吐量有限
如果L1 的區塊限制被解除,會遇到一個很大的問題,因為鏈的高吞吐帶來了鏈上區塊的高增長率,為了確保不同的節點跟上最新的全鏈狀態,就需要增加了更多的全節點。又由於L1 全節點必須記錄所有歷史記錄,區塊大小的大幅增加會給全節點運營者帶來巨大壓力,並導致部分全節點因為機器性能落後而退出系統,結果,能夠運營全節點的都是一些比較大的實體,最終就是用戶無法以無信任的姿態驗證狀態並參與網絡。
這也讓我們明白,從某種意義上來說正是L1 吞吐量的限制,成就了一個真正去中心化的和相對安全的網絡系統。
上述問題為什麼不會出現在Validity Rollups 之上?
只有在考慮全節點的問題時,我們才能看到有效性匯總(Validity Rollups)的優勢。正常情況下,一個L1全節點需要重新執行整個鏈的歷史以確保當前狀態的正確性,而StarkNet 節點只需要驗證STARK 證明,而且這種驗證需要的計算資源呈指數級下降。重點是,鏈上全節點狀態的驗證同步沒有涉及到執行;一個節點可以從另一個全節點那裡接受當前狀態的轉儲,只需通過STARK 證明來驗證這個狀態是否有效即可。這讓我們在增加網絡的吞吐量的同時,不用增加全節點的數量。
因此,在L2 上,通過對排序器的優化可以對整個系統的性能進行提升,但這在L1上不能實現的。
StarkNet 的未來性能路線圖
這一部分,我們將討論目前有哪些計劃用於對StarkNet 排序器的優化。
排序器並行化
性能路線圖的第一步是為交易執行引入並行化。這個提議是在StarkNet alpha 0.10.2 中正式引入的,該版本於11月29日在以太坊主網上發布,我們現在來深入探討下什麼是並行化。
一般來說,並行執行多個交易區塊是不可以的,因為不同的交易可能是相互依賴的。以下方示例中進行說明,我們假設有一個包含來自同一用戶的三筆交易的區塊:
-
Tx A(交易A,下同):將USDC兌換ETH
-
Tx B:為某款NFT支付ETH費用
-
Tx C:將USDT兌換BTC
顯然,交易A必鬚髮生在交易B之前,但交易C完全獨立於兩者,是可以並行執行的。如果每個交易需要1秒執行,那麼通過引入並行化處理之後,區塊生產時間可以從3秒減少到2秒。
問題的關鍵在於,我們事先並不知道不同交易之間的依賴性。在實踐中,只有當我們執行到示例中的Tx B 時,我們才會發現它是依賴於Tx A所做的改變。更準確地說,這種依賴性源於 Tx B 從 Tx A 寫入的存儲單元中讀取這一動作。我們可以把不同的Tx 看成是一個依賴圖,其中存在從交易A 到交易B 的一條邊,當且僅當A 寫入一個由B 讀取的存儲單元時,B 才可能執行。下圖顯示了這種依賴之間的關係:
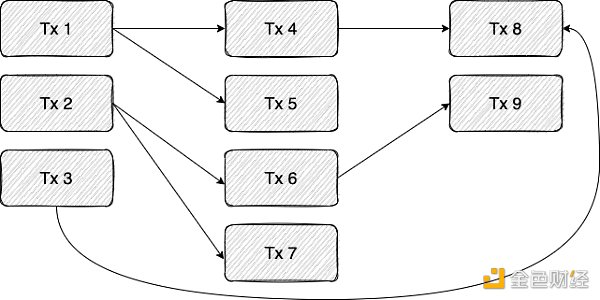
在上面的示例中,每一列都可以並行執行。
為了克服事先無法確定不同交易事件之間的依賴關係,我們根據Aptos Labs 推出的BLOCK-STM,將OP 並行化(optimistic parallelization)引入到StarkNet 排序器中。在這種模式下,會以樂觀地方式並行地處理事務,並在發現碰撞時重新執行。比如在上述示例圖中,我們可以並行執行TX1-4,但事後發現Tx 4 依賴於Tx1,因此這次執行是無效的(應該在Tx1 執行後運行Tx 4 ),在這種情況下,將重新執行Tx4。
請注意,在上述這種樂觀並行化的基礎上我們也增加一些優化措施。例如,與其等待每個執行的結束,可以在發現一個使之運行結果無效的依賴關係時就中止執行。
另一個優化的例子是選擇哪些事務來重新執行。假設由上述示例圖的所有事務組成的區塊被送入一個擁有五核CPU的排序器。首先,我們嘗試並行執行tx 1-5,如果完成的順序是Tx2、Tx3、Tx4、Tx1,最後是Tx5,那麼我們將在Tx4 已經執行後才發現依賴關係Tx1→Tx4,這表明它應該被重新執行。直觀地說,考慮到Tx4的重新執行,Tx5也需要重新執行,然而,我們可以遍歷由執行已經結束的事務構建的依賴圖,只重新執行依賴於Tx4的事務,而不是將失效Tx4之後的事務都重新執。
Rust 語境下的Cairo-VM 實現
StarkNet 中的智能合約是通過Cairo 語言編寫的,並在Cairo-VM 虛擬機中執行。目前,排序器正在使用python 語言在Cairo-VM 上運行。為了優化虛擬機的實現性能,我們之前發起了用Rust 重寫Cairo-VM 虛擬機的工作。
目前,cairo-rs可以執行原生Cairo 代碼,下一步是處理智能合約的執行和與pythonic 排序器的集成,一旦與cairo-rs 集成,排序器的性能有望進一步提高。
Rust 語境下的排序器
通過python 到rust 的轉變以提高網絡性能,不僅限於Cairo-VM,StarkNet 用Rust 重寫了排序器相關的代碼。除了Rust 的內部優勢之外,這還為排序器的其他優化提供了可能,比如,可以集合cairo-rs 的優勢,而無需python-rust 通信的開銷,也可以完全重新設計狀態的存儲和訪問方式。
證明者(Provers)
在整篇文章中,沒有提到有效性匯總(Validity Rollups)中核心元素之一——證明者(Provers)。作為可以說是架構中最複雜的組件,證明者(Provers)算是瓶頸,也是優化的重點。但現在,StarkNet 的瓶頸是更加“標準”的組件,特別是對於遞歸證明,可以將當前測試網/主網上的更多交易放入證明中。事實上,StarkNet 區塊與StarkEx 交易一起得到有效的市場證明,後者有時會有數十萬NFT 的鑄造事件。
總之,並行化、Rust 等改進,都是為接下來StarkNet 提升TPS 所做的準備。
