
原文:Enabling AI-Generated Content (AIGC) Services in Wireless Edge Networks
編譯:DeFi 之道
簡介
人工智能生成內容(AIGC)技術由於具有的獨特能力 [1],在文本、圖像和視頻等內容領域的有著很大的應用潛力。毫無疑問,AIGC將顯著影響未來的很多日常應用,特別是在元宇宙賽道。由於能夠高效地生成大量高質量的內容,AIGC 可以節省在手工內容創建上的時間花費和其他資源,最近的研究表明,AIGC 在技術發展方面已經取得了重大進展。
具體來說,在文本生成方面,參考文獻中[2]和[3]的作者已經探索了使用深度學習技術生成連貫和多樣化文本的方法。對於圖像生成,[4]和[5]作者則重點研究使用第一代對抗網絡(generative adversarial networks-GANs)來生成逼真的圖像。在音頻生成中,[6]的作者探索了用於合成高質量語音的深度學習技術。此外,擴散模型(diffusion models)是AIGC 領域的最新突破,2020年,OpenAI 發布了GPT-3 模型,作為一種多模式的全能語言模型,GPT-3 能夠進行機器翻譯、文本生成、語義分析等[7]。而在2022年發布的基於擴散模型的DALL-E2 被認為是最先進的圖像生成模型,其性能可以優於GANs [8]。
但是,AIGC 模型需要大量的數據來進行訓練,而且大型的AIGC 模型還很難被部署。以Stable Diffusion 為例,Stability AI 公司維護了超4000個NVIDIA A100 GPU集群,運營成本就達到了5000萬美元。而Stable Diffusion V1 模型的一次訓練需要15萬A100 GPU小時。此外,由不同數據集訓練的AIGC 模型只能適用於特定的任務,例如,由人臉數據集訓練的AIGC 模型可以用於修復損壞的人臉圖像,但不能有效地糾正模糊的景觀圖像。由於用戶任務的多樣性和有限的邊緣設備容量,很難在每個網絡邊緣設備上部署多個AIGC 模型。為了進一步提高AIGC 服務的可用性,一個很有前途的部署方案是基於“Everything-as-a-service”(EaaS),它可以有效地為用戶提供基於訂閱的服務。通過採用EaaS部署方案,我們進一步提出了“AIGC-as-a-service”(AaaS)的概念,具體來說就是AIGC 服務提供商(ASPs)可以在邊緣服務器上部署人工智能模型,通過無線網絡向用戶提供即時服務,提供更方便和可定制的體驗。用戶可以輕鬆地訪問和享受AIGC 的低延遲,在邊緣網絡中部署AaaS 有幾個優點:
-
個性化:AIGC 模型可以根據每個用戶的需求進行定制的內容,提供個性化的體驗。例如,可以提供個性化的產品推薦,通過根據用戶的位置、偏好和使用模式給用戶提供服務。
-
高效率:通過在更接近用戶的地方部署AIGC服務,服務質量(QoS)將得到顯著提高,例如,通過本地的內容傳輸,可以更有效地利用網絡和計算資源,降低延遲。
-
靈活性:AIGC 可以進行定制和優化,以滿足動態需求和資源可用性。通過調度無線網絡用戶對AIGC 的訪問,可以使網絡中用戶的整體QoS最大化。
因此,基於邊緣網絡的AaaS 有可能徹底改變通過無線網絡來創建和交付內容的方式。然而,目前對AIGC 的研究主要集中在AIGC 模型的訓練上,而忽略了在無線邊緣網絡中部署AIGC 時的資源分配問題。具體來說,AIGC 可能需要大量的帶寬和計算能力來生成內容以及向用戶交付內容,而這可能會導致網絡性能的下降。此外,擴展AaaS 以滿足大量用戶的需求也是一項挑戰。因此,為用戶分配合適的AIGC 服務提供商(ASPs)至關重要的,一方面,用戶追求那些能提供優質服務的ASPs;另一方面,也要避免某些AIGC 服務過載和需要重新傳輸,從而消耗稀缺的網絡資源,文章主要有以下幾個方面的內容:
-
對AIGC及其背後的技術的全面概述,討論了AIGC 的各種應用及其在無線邊緣網絡中的用例和部署挑戰。
-
回顧了現有的基於圖像的感知質量指標。通過實際實驗,我們提出了一個通用模型來揭示AaaS中計算資源消耗與生成內容質量之間的關係。
-
提出了一種支持深度強化學習(DRL)的方法來實現最優ASPs 的動態選擇。證明了DRL算法相比其他四種解決方案上的優勢。
AI內容生成與技術
在本節中,我們將回顧AIGC 的發展進展,介紹了AIGC 背後的技術。然後,我們將討論幾種AIGC 在邊緣網絡中的相關應用。
1. 生成技術(Generative Techniques)
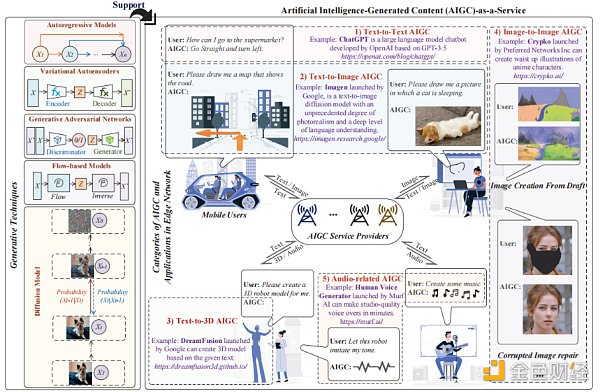
我們在訓練AIGC 模型[9]中引入了生成技術,基本模型結構下圖所示。
圖1:AIGC [9]中的生成技術、AIGC的類別和在無線邊緣網絡中的應用
l 自動回歸模型(ARMs): ARMs屬於統計模型,它涉及到基於過去的值[9]來預測一個時間序列的未來值。 ARMs可以通過基於前一個元素預測下一個元素來生成文本或其他媒體類型。 ARMs的一個潛在應用是,通過根據邊緣用戶之前的音符來預測音樂序列中的下一個音符,進而來生成音樂。
-
變分自編碼器(VAEs): VAEs可以通過學習輸入數據來生成新的數據,其中包括一個編碼器網絡和一個解碼器網絡[9]。編碼器網絡處理輸入數據並輸出一個潛在的表示,解碼器網絡以這種潛在的表示作為輸入,並生成與輸入數據相似的合成數據。
-
生成對抗網絡(GANs): GANs由兩個神經網絡組成,即生成器網絡和鑑別器網絡[4]。將這兩個網絡一起進行訓練,以提高生成器生成真實圖像的能力和鑑別器區分合成圖像和真實圖像的能力。
-
基於流的模型(FBMs): FBMs通過一系列可逆變換[9]將一個簡單的分佈轉換為目標分佈,這些轉換被實現為神經網絡,而應用這些轉換的過程被稱為“流(Flow)”。
-
擴散模型(DMs):訓練DMs對被高斯噪聲模糊的圖像進行去噪,以學習如何實現逆轉擴散過程[8]。幾種基於擴散的生成模型已經被提出,包括擴散概率模型、噪聲條件評價網絡和去噪擴散概率模型等。
此外,經典的技術,如Transformer,也可以用於訓練AIGC 模型,這將在下面進行討論。
2. 移動網絡中的AIGC與應用程序類別
下文介紹了幾類AIGC 技術及其在邊緣網絡中的應用,這可以作為未來潛在的研究方向。
-
文本到文本的AIGC:文本到文本AIGC 可以根據給定的文本輸入生成類人的回复輸出。因此,它可以用於自動回答、語言翻譯或文章摘要。一個代表性的文本到文本AIGC 模型就是GPT(https://openai.com/blog/chatgpt/),它是由OpenAI [7]開發的語言模型。 GPT 是在大量生成的文本數據集上訓練的,比如書籍或文章,該模型可以根據前面的單詞來預測序列中的下一個單詞並創建文本。 GPT 非常成功,並且已經在幾個自然語言處理(NLP)基準測試上取得了非常好的效果。 GPT 可以用來構建許多基於語言的服務,在無線邊緣網絡中,如圖1所示,GPT可以作為一個聊天機器人,為司機提供導航和信息警報等服務。
-
文本到圖像的AIGC:文本到圖像AIGC 允許用戶基於文本輸入來生成圖像,允許通過書面描述創建對應的視覺內容。它可以被看作是自然語言處理和計算機視覺技術的結合。如圖1所示,文本到圖像的AIGC 可以幫助移動用戶進行各種活動。例如,車聯網中的用戶可以請求基於視覺的路徑規劃,此外,文本到圖像的AIGC還可以幫助用戶創建藝術,並根據用戶的描述或關鍵字創作各種風格的圖片。
-
文本到3D 的AIGC:文本到3D AIGC 可以通過使用無線AR應用程序從文本描述生成3D模型。通常,生成3D模型比生成2D圖像需要更高的計算資源。考慮到下一代互聯網服務的發展,如元宇宙[10],基於文本來生成3D模型而無需複雜的手工設計,未來將會有非常大的應用潛力。
-
圖像到圖像的AIGC:指使用人工智能模型從源圖像中生成真實的圖像,或創建輸入圖像的程式化版本。例如,當涉及到輔助藝術品創作時,圖像到圖像的AIGC 可以僅根據用戶輸入的草圖生成視覺上令人滿意的圖片。此外,圖像到圖像的AIGC 還可以用於圖像編輯服務,比如用戶可以刪除一個圖像中的遮擋或修復損壞的圖像。
-
與音頻相關的AIGC:與音頻相關的AIGC模型可以分析、分類和操作音頻信號,包括語音和音樂。具體來說,文本到語音模型的設計是為了從文本輸入中合成自然的語音。音樂生成模式可以綜合各種風格和流派的音樂。視聽音樂的生成包括使用音頻和視覺信息,如音樂視頻或專輯藝術作品,以生成與特定視覺風格或主題更緊密相關的音樂作品。此外,與音頻相關的AIGC 可以作為語音助手,回答用戶的查詢。 Alexa 和Siri 是現實應用程序的例子。
鑑於AIGC 模型的強大能力,在無線邊緣網絡中部署AaaS 存在幾個挑戰,下面將介紹這些挑戰。
AaaS與無線邊緣網絡
在本節中,我們將詳細討論AaaS,包括挑戰和性能指標。
AaaS 的挑戰
為了在無線邊緣網絡中部署AaaS,ASPs 首先應該在大數據集上訓練AIGC 模型。 AIGC 模型和邊緣網絡生成技術中的應用程序擴散模型需要託管在邊緣服務器上,並且可以被用戶訪問。需要持續的維護和更新,以確保AIGC 模型在生成高質量內容方面保持準確和有效。用戶可以提交內容生成請求,並從ASPs 租用的邊緣服務器接收生成的內容。儘管在無線邊緣網絡中部署AaaS 有優點,但仍有相應的挑戰需要解決:
-
帶寬消耗:AIGC 消耗了大量的帶寬。特別是對於與高分辨率圖像相關的AaaS,上傳和下載過程都需要大量的網絡資源來實現,來確保低延遲的服務。例如,在壁紙天堂應用中,一個人工智能生成的壁紙的數據大小可以達到10兆字節左右。此外,由於生成的圖像的多樣性,用戶可能為了獲得滿意的圖像,向特定的邊緣服務器進行多次重複請求,進一步消耗網絡資源。
-
時變頻道質量:AaaS 中的QoS 會受到生成內容的無線傳輸影響。低信噪比(SNR)、低中斷概率(OP)和高誤碼概率(BEP)會降低AIGC 服務的QoS 和用戶滿意度,這是時變信道偶爾遇到深度衰落時造成的。
-
用於訓練AIGC 模型的數據集:用於訓練AIGC 模型的數據集可能會影響生成內容的質量。由於不同的ASPs 有不同的AIGC 模型,用戶可以被分配到合適的ASPs 來滿足他們的需求。例如,使用了更多的人臉圖像進行訓練的AIGC 模型將比使用其他數據集進行訓練的AIGC 模型更適合生成虛擬化身。
-
計算資源消耗:訓練有素的AIGC 模型在生成內容時仍然消耗一定的時間和計算資源,例如,擴散模型AaaS的輸出質量隨著推理步驟數的增加而增加。
-
l 效用最大化和激勵機制:激勵機制的設計在AaaS 中具有重要意義,因為它可以激勵ASPs 生成高質量的內容,滿足期望的目標和目標。
解決上述挑戰的一個常見問題是如何評估AIGC 的性能。雖然目前市面上已經提出了許多不同模式的評估指標,但大多數都是基於人工智能模型或者本身難以計算,沒有數學表達式。對於無線網絡中AaaS 的優化設計,基於人工智能的資源分配解決方案可以利用基於人工智能的性能指標來模擬對用戶的主觀感受。然而,傳統的數學資源分配方案需要有對計算資源消耗的關係,如擴散模型中的推理步數與生成內容的質量之間的關係進行建模,如圖2所示。為了解決這一問題,我們以與圖像相關的AaaS 為例,引入了各種性能評價指標,並探討了度量值之間的數學關係。
性能指標
我們首先討論AIGC 的評估指標。我們專注於評估圖像的感知質量,但同樣的方法也可以應用於其他類型的內容,我們還建立了AaaS 中計算資源消耗與生成內容質量之間的關係。
1) 基於圖像的指標:圖像質量評估指標可以是基於分佈的和基於圖像的。基於分佈的度量標準,例如,弗雷切特初始距離[11],取一個圖像特徵列表來計算分佈之間的距離,以評估生成的圖像。然而,對於無線網絡中的實際AaaS,質量評價是主觀的,用戶很難計算出基於分佈的指標。因此,我們關注基於圖像的指標,試圖通過建模人類視覺系統的生理和心理視覺特徵,或通過信號保真度度量來實現對質量預測的一致性。具體來說,如果不以原始圖像作為參考,無參考圖像質量評價方法可以被認為是[11]:
-
全分辨(TV):TV 是對圖像平滑度的一種度量。計算全分辨的一種常見方法是取圖像中相鄰樣本之間的絕對值之和,它衡量了圖像的“粗糙度”或“不連續性”。
-
無參考的空間域圖像質量評估(BRISQUE):BRISQUE 用局部歸一化亮度係數的場景統計數據來量化由於[12]失真而可能造成的圖像“自然性”損失,研究表明,BRISQUE 表現與人類對圖像質量的感知類似。
圖像質量越高,TV 值越小,對於有參考圖像的AaaS,我們可以使用全參考圖像質量的評價方法[11]:
-
離散餘弦變換圖像質量評價(DSS):DSS 通過測量離散餘弦變換(DCT)域的結構信息變化,利用人類視覺感知的基本特徵,對這些次頻帶[13]的質量進行加權計算。
-
基於Haar小波的感知相似性指數(HaarPSI): HaarPSI利用從Haar小波分解得到的係數來評估兩幅圖像之間的局部相似性,以及圖像區域的相對重要性。
-
平均偏差相似指標(MDSI): MDSI 利用梯度相似度、色度相似度和偏差池等,是一個可靠和完整的參考感知圖像質量評估的模型。
-
視覺信息保真度(VIF): VIF 是一種有競爭力的測量保真度的方法,它量化了參考圖像中的信息,以及從失真圖像中可以提取多少參考信息。
圖像質量越高,上述衡量圖像質量的度量值就越高。
2) 感知圖像質量度量值的一般模型:基於擴散模型的AIGC 模型正在成為主流。如圖1的所示,擴散過程可以看作是一個逐級去噪的過程。因此,增加推理步驟的數量將提高感知圖像的質量。然而,生成的圖像質量並不總是隨著步驟數的增加而增加。過度的推理步驟會導致不必要的資源消耗。我們進行了真實的實驗來調查推理步驟數和各種感知圖像質量指標之間的關係,即TV、BRISQUE、DSS、HaarPSI、MDSI 和VIF。
實驗平台建立在一個通用的Ubuntu 20.04 系統上,AMD 銳龍Threadripper PRO 3975WX 處理器規格和NVIDIA RTX A5000 的GPU。我們以基於擴散模型的損壞圖像恢復服務作為AaaS為例子。具體來說,我們在服務器上部署了[14]中提出的訓練有素的模型RePaint。如圖2(A部分)所示,我們首先生成一系列損壞的圖像,例如20張圖像。然後,將這些損壞的圖像輸入“重新繪製”。我們可以觀察到,隨著推理的進行,損壞的圖像逐漸恢復,如圖2(D部分)所示。此外,衡量圖像質量的BRISQUE度量值下降,如圖2(B部分)所示。我們在圖3中展示了在不同的時間和推理步驟下的各個度量值的變化。
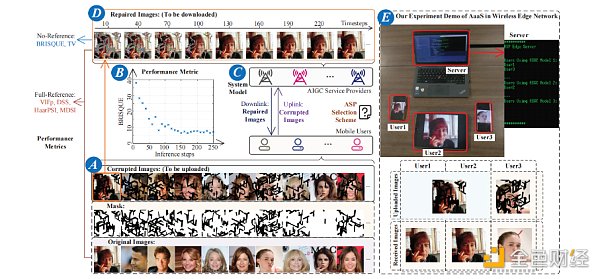
圖2:用於修復損壞的圖像的AaaS示例
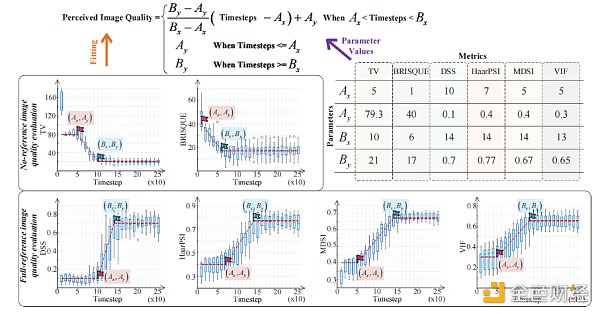
圖3. 推理步驟的數量與不同感知圖像質量指標之間的關係
因此,我們給出了一個包含四個參數的感知圖像質量度量的一般模型,如圖3的頂部所示。具體來說,Ax是圖像質量開始提高時的最小推理步驟數,Ay是圖像質量的下限,可以視為高噪聲圖像的評價值,Bx是根據AIGC 模型的能力而使圖像質量開始穩定時的推理步驟數,By是模型所能達到的最高圖像質量的值。無論性能度量值與圖像質量成正比還是成反比,無論AaaS類型如何,我們都可以很容易地通過實驗找到點(Ax,Ay)和(Bx,By),如圖3所示。
經驗教訓:儘管擴散過程存在固有的不確定性,但從圖3中我們可以觀察到,感知到的圖像質量隨著推理步驟的增加而近似成比例的增加或下降。在實際的AIGC 模型分析中,我們可以用圖3所示的簡單擬合方法對一個性能度量進行實驗,得到我們提出的一般數學模型中的四個參數。然後,該模型可用於無線邊緣網絡支持的AIGC 服務分析。
深度強化學習的動態ASPs選擇
在本節中,我們研究了最優的ASPs 邊緣服務器選擇問題。我們提出了一個支持DRL 的解決方案,以最大化實用功能,同時滿足用戶的需求。
AaaS系統模型
如我們的演示圖2 (E部分)所示,三個用戶分別在兩個圖像修復AIGC 模型中進行選擇,在CelebA-HQ 和Places2 [14]數據集上進行訓練。用戶1和用戶2上傳了相同的損壞圖像,我們可以觀察到不同的AIGC 模型對於相同的用戶任務會產生不同的結果。
進一步研究了在無線邊緣網絡中大規模部署AaaS 的情況,模擬設置了20個AIGC服務提供商(ASPs)和1000個邊緣用戶。每個ASPs 為AaaS 提供最大的資源容量,即在一個時間窗口內的總擴散步數,在600 到1500 範圍內隨機,每個用戶在不同的時間向ASPs 提交多個AIGC 任務請求。這些任務指定了其所需要的AIGC 資源的數量,即擴散步數,我們將其設置為一個在100到250之間的隨機值,用戶任務的到達情況遵循泊松分佈。具體來說,在288小時內,用戶任務到達速率λ=0.288h/請求,總共有1000個任務。需要注意的是,由不同的ASPs提供的AIGC模型的質量是不同的,例如,修復後的圖像可以更真實和自然。
一個簡單但不太有效的ASPs 選擇是,用戶將任務請求直接發送到生成內容質量最好的ASPs。然而,由於計算資源不足和實踐中任務可能中斷,這種方法不可避免地使一些ASPs 過載,此外,用戶此時也不知道ASPs 生成內容的質量。移動用戶需要多次要求ASPs 來估計生成內容的質量,以進行近似選擇,這帶來了不必要的負載和無線網絡資源消耗。為此,在生成內容質量未知的前提下,如何為用戶任務選擇合適的ASPs,最大限度地提高整個系統的效用,減少集中某個ASPs 造成的AIGC 資源過載和中斷問題,是一個具有挑戰性但又非常重要的問題。
基於深度強化學習的解決方案
我們使用Soft Actor-Critic(SAC軟行為者-批評者)DRL [15]來解決上述動態ASPs 選擇問題。如圖4所示,學習過程在評估(批評者)和改進(行為者)之間交替進行。與傳統的行為者-批評者體系結構不同,SAC 中的策略被訓練為最大限度地在預期回報和信息熵之間進行權衡。 AaaS環境中的狀態空間、動作空間和獎勵的定義如下:
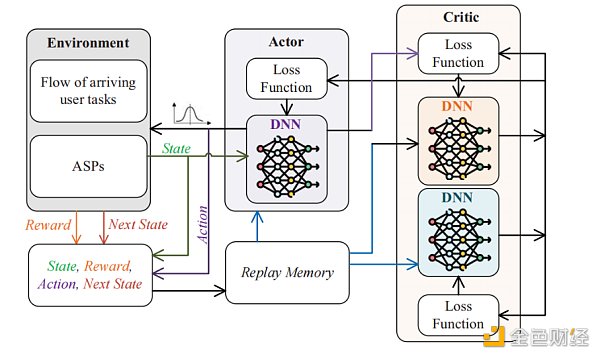
圖4:The structure of soft actor–critic DRL algorithm.
-
狀態:狀態空間由兩部分組成,(a) 到達的用戶任務的特徵向量(當前用戶任務對AIGC資源的需求和任務的估計完成時間;(b) 當前狀態下所有ASPs 的特徵向量(i個ASPs 的總AIGC 資源和第i個ASPs 的當前可用資源)。
-
動態:ASPs 選擇問題的動態空間是一個表示所選ASPs 的整數。
-
獎勵:包括兩部分,生成內容的質量獎勵和擁塞懲罰。前者被定義為修復後的圖像的感知質量。此外,任何超載AIGC 模型的操作都必須作進行懲罰。首先,行為本身應該受到固定的懲罰。其次,考慮到操作原因會導致ASPs 的模型崩潰,並且正在運行的任務將被中斷,當前的操作也會根據正在進行的任務的進度受到額外的懲罰。返回的總回報是質量獎勵減去擁塞懲罰。
圖5顯示了啟用了DRL 後的ASPs 選擇策略和四個基準測試策略的效用曲線(即獎勵曲線)。由於DRL 可以學習和進化,隨著學習步驟的進展,DRL 對ASPs 的選擇更全面、更準確。因此,效用迅速上升,顯示出獨特的學習能力。一個有趣的發現是,當DRL超過循環時,DRL已經有了一個特定的負載平衡能力,此時,DRL已經學會了避免可能導致崩潰的操作,從而避免了擁塞懲罰。然後,DRL開始學習不同的ASPs 的優先級,並尋求將當前的用戶任務放在高質量的ASPs 上,以最大化獎勵。
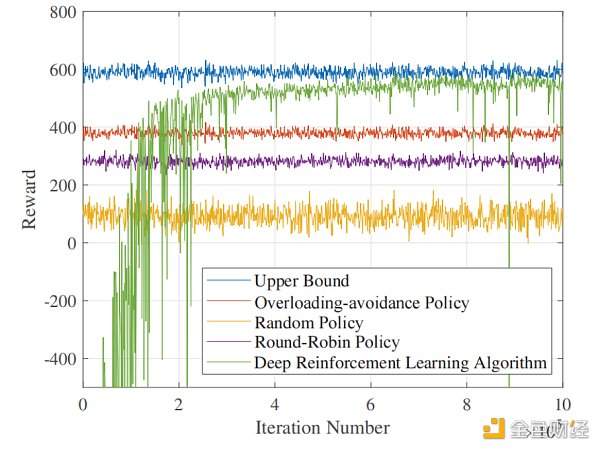
圖5:獎勵值與DRL中迭代次數的關係
圖6計算了五種策略下AIGC 任務崩潰的數量、已完成任務的平均獎勵和崩潰任務的數量。一方面,啟用了DRL 的ASPs 選擇策略可以實現零任務崩潰,並將擁塞懲罰最小化,這對於為用戶提供令人滿意的生成內容質量至關重要。另一方面,DRL 策略可以了解ASPs 可能提供的內容質量,而這在其他策略中是未知的。然後,DRL 可以將用戶任務分配給能夠提供更高QoS 的ASPs,從而有效地增加每個任務的平均獎勵。以上兩個優勢的結合最終使得DRL下的ASPs 選擇策略能獲得更高的獎勵。
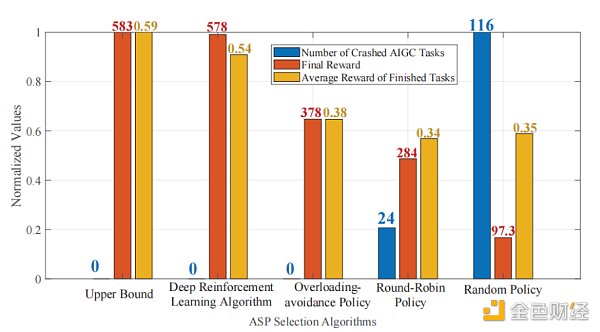
圖6:五種策略下的任務崩潰的數量、已完成任務的平均獎勵和崩潰任務統計
未來方向
Assa安全
在無線網絡中部署AaaS 時,來自用戶的請求和生成的內容都是在無線環境中傳輸的。因此,需要研究AIGC 的安全技術,例如,通過改進物理層安全技術來保護AIGC 數據的傳輸,此外,區塊鏈可以用於實現分佈式的內容分發,允許在用戶之間直接共享和訪問內容,而不需要一個中央節點。通過區塊鏈驗證AIGC 的真實性和來源,確保AIGC 的準確和可信。此外,在AIGC 模型的訓練過程中,需要保證訓練數據的隱私性,特別是生物特徵數據,如人臉圖像等數據的安全,一種可能的解決方案是通過federated learning 模型來進行訓練。
基於物聯網和無線傳感輔助的AaaS
考慮到傳感技術的快速發展,我們的目標是利用無線傳感信號實現無源AaaS。例如,無線傳感器可以收集有關環境或用戶行為的數據,然後可以將這些數據輸入到AIGC 模型中,以生成相關的內容,這可以被應用到醫療保健,比如借助使用物聯網設備,通過無線傳感來檢測用戶的活動水平、睡眠模式或心率,AIGC 可以生成個性化鍛煉計劃等內容。
AaaS的個性化資源分配
雖然目前的AIGC 模型可以通過定制化來滿足用戶的需求,但還需要更多的研究來實現個性化的AIGC服務。例如,對於文本到圖像的AaaS,當兩個用戶都輸入文本“一隻猴子站在一隻斑馬旁邊”時,當前的ASPs 會為用戶生成類似的圖像,但是,如果我們推斷這兩個用戶分別是馴馬師和猴子研究者,我們就可以進行個性化的計算資源分配[10]。具體來說,應該分配更多的計算資源來為馴馬師生成和傳輸圖像中的斑馬。對於猴子研究人員來說,更適合生成猴子圖像的AIGC 模型應該被分配來處理這個任務。一個潛在的解決方案是將用戶反饋和偏好納入到內容生成過程中,並開發評估個性化內容有效性的技術。
總結
在本文中,我們回顧了AIGC 技術,並討論了其在無線網絡中的應用。為了向用戶提供AIGC服務,我們提出了AaaS的概念。然後,討論了在無線網絡中部署AaaS 所面臨的挑戰。在解決這些挑戰時,一個基本的問題是關於資源消耗和生成內容的感知質量之間的數學關係。在探索了各種基於圖像的性能評價指標之後,我們提出了一個通用的建模方程,此外,我們還研究了重要的ASPs 選擇問題。採用DRL算法實現了接最優的ASPs 選擇,我們希望本文能夠激勵研究人員為無線邊緣網絡感知的AaaS 發展做出貢獻。
參考目錄:
[1] L. Yunjiu, W. Wei, and Y. Zheng, “Artificial intelligence-generated and human expert-designed vocabulary tests: A comparative study,” SAGE Open, vol. 12, no. 1, Jan. 2022.
[2] M. Chen, A. Radford, R. Child, J. Wu, H. Jun, D. Luan, and I. Sutskever,“Generative pretraining from pixels,” in Proc. Int. Conf. Mach. Learn.PMLR, 2020, pp. 1691–1703.
[3] J. Guo, S. Lu, H. Cai, W. Zhang, Y. Yu, and J. Wang, “Long text generation via adversarial training with leaked information,” in Proc.AAAI Conf. Artif. Intell., vol. 32, no. 1, 2018.
[4] T. Karras, T. Aila, S. Laine, and J. Lehtinen, “Progressive growing of gans for improved quality, stability, and variation,” in Proc. Int. Conf.Mach. Learn., 2018.
[5] X. Huang, M.-Y. Liu, S. Belongie, and J. Kautz, “Multimodal unsupervised image-to-image translation,” in Proc. Eur. Conf. Comput. Vis.,2018, pp. 172–189.
[6] W. Ping, K. Peng, K. Zhao, and Z. Song, “WaveFlow: A compact flowbased model for raw audio,” in Proc. Int. Conf. Mach. Learn. PMLR,2020, pp. 7706–7716.
[7] L. Floridi and M. Chiriatti, “GPT-3: Its nature, scope, limits, and consequences,” Minds Mach., vol. 30, no. 4, pp. 681–694, Apr. 2020.
[8] P. Dhariwal and A. Nichol, “Diffusion models beat GANs on image synthesis,” Adv. Neural Inf. Process. Syst., vol. 34, pp. 8780–8794, 2021.
[9] G. Harshvardhan, MK Gourisaria, M. Pandey, and SS Rautaray,“A comprehensive survey and analysis of generative models in machine learning,” Comput. Sci. Rev., vol. 38, p. 100285, 2020.
[10] H. Du, J. Liu, D. Niyato, J. Kang, Z. Xiong, J. Zhang, and DI Kim,“Attention-aware resource allocation and QoE analysis for metaverse xURLLC services,” arXiv preprint arXiv:2208.05438, 2022.
[11] S. Kastryulin, D. Zakirov, and D. Prokopenko, “PyTorch Image Quality:Metrics and measure for image quality assessment,” 2019, opensource software available at https://github.com/photosynthesis-team/piq.[Online]. Available:https://github.com/photosynthesis-team/piq
[12] A. Mittal, AK Moorthy, and AC Bovik, “No-reference image quality assessment in the spatial domain,” IEEE Trans. Image Process., vol. 21,no. 12, pp. 4695–4708, Dec. 2012.
[13] L. Gatys, A. Ecker, and M. Bethge, “A neural algorithm of artistic style,”J. Vis., vol. 16, no. 12, pp. 326–326, Dec. 2016.
[14] A. Lugmayr, M. Danelljan, A. Romero, F. Yu, R. Timofte, and L. Van Gool, “Repaint: Inpainting using denoising diffusion probabilisticmodels,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2022, pp.11 461–11 471.
[15] P. Christodoulou, “Soft actor-critic for discrete action settings,” arXiv preprint arXiv:1910.07207, 2019.
