原文來自:Modulus Labs
編譯:DeFi 之道
很高興終於可以與你們分享我們的第一篇論文,該論文是通過以太坊基金會的資助完成的,它的名稱是《The Cost of Intelligence: Proving Machine Learning Inference with Zero-Knowledge》(或paper0,這是酷孩子們的叫法)。
沒錯,這些都是真數字!有圖表!論文還討論了理論結構及其對性能的影響!事實上,paper0 是第一個跨通用AI 原語套件對ZK 證明系統進行基準測試的研究工作,你現在就可以閱讀整篇論文。
而這篇文章,你可以將其視為論文的總結,有關詳細信息,請參閱原論文。
事不宜遲,讓我們深入了解:
Paper0 : 我們的調查要點
事實上,計算的未來將大量使用複雜的人工智能。看看我的文本編輯器:
Notion 的提示告訴我,他們的LLM 可以讓這句話變得更好
然而,鏈上不存在功能性神經網絡,甚至連最小的推薦系統或匹配算法都不存在。真見鬼!甚至連實驗也沒有一個……當然,原因是非常明顯的,因為這太貴了,畢竟,即使運行價值數十萬FLOP 的計算(僅夠在微型神經網絡上進行一次推理)的成本也是數百萬gas,目前相當於數百美元。
那麼,如果我們想將AI 範式帶入無需信任的世界,我們該怎麼做?我們會翻車(roll-over),然後放棄(give up)嗎?當然不是…等等! Roll-over)……Give up……
如果像Starkware、Matter Labs 和其他公司這樣的Rollup 服務,正在使用零知識證明來大規模擴展計算,同時保持密碼學安全,那麼我們能為AI 做同樣的事情嗎?
這個問題成為推動我們在paper0 中工作的激勵種子。劇透警報,以下是我們發現的:

“現代ZK 證明系統的性能越來越高,並且越來越多樣化。它們已經可以支持成本在某種程度上是合理的人工智能操作。
事實上,有些系統在證明神經網絡方面比其他系統好得多。
然而,所有這些仍然達不到實際應用所需的性能,並且對於神奇的用例來說是嚴重不足的。
換句話說,如果不進一步加速用於AI 操作的ZK 系統,用例就會非常有限。 “
paper0 總結
這是眾所周知的秘密:AI 性能幾乎總是與模型大小成比例。這種趨勢看起來也沒有放緩。只要這種情況仍然存在,對於我們這些web3 中的人來說,這將是特別痛苦的。
畢竟,計算成本是我們最終、不可避免的噩夢來源。

今天的ZKP 已經可以支持小模型了,但中型到大型模型打破了範式
基準:實驗設計
對於paper0,我們關注任何零知識證明系統中的2 個基本指標:
-
證明生成時間:prover 創建AI 推理的伴隨證明所需的時間,以及
-
prover 內存使用峰值:證明者在證明期間的任何給定時間用於生成推理證明的最大內存;
這主要是一個實際的選擇,並且是從我們構建Rockybot 的經驗中做出的(證明時間和內存使用是確定任何無需信任人工智能用例可行性的直接優先事項)。此外,所有測量都是針對證明生成時間進行的,並且沒有考慮預處理或witness 生成。
當然,還有其他方面的成本需要跟踪。這包括驗證者運行時間和證明大小。我們將來可能會重新審視這些指標,但將它們視為paper0 的範圍之外。
至於我們測試的實際證明系統,通過投票,我們選定了6 個:
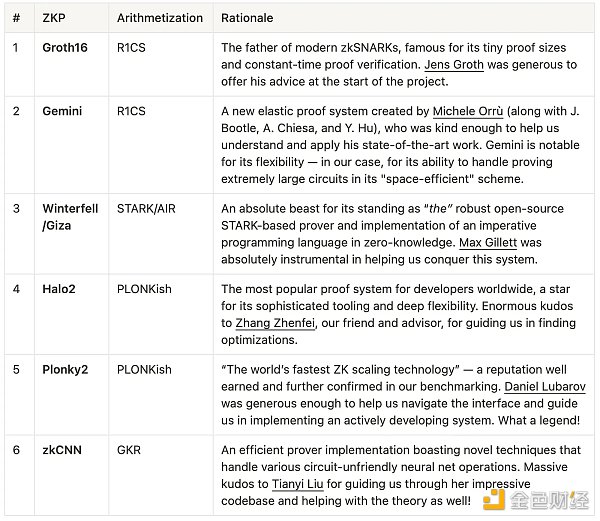
Paper0 測試的證明系統匯總表,以及協助我們的作者
最後,我們創建了兩套用於基準測試的多線性感知器(MLP)——值得注意的是,MLP 相對簡單,主要由線性運算組成。這包括一套隨著參數數量增加而擴展的架構(最多1800 萬參數和22 GFLOP),以及第二套隨著層數增加而擴展(最多500 層)的架構。如下表所示,每個套件都測試了證明系統以不同方式擴展的能力,並大致代表了從LeNet5(6 萬參數,0.5 MFLOP)到ResNet-34(2200 萬參數,3.77 GFLOP)的知名深度學習(ML)架構的規模。
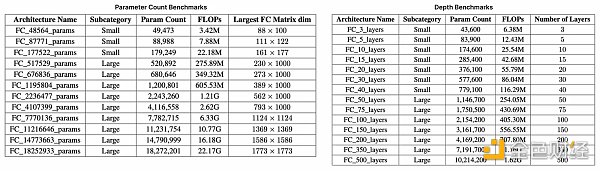
參數和深度基準套件
結果:迅如閃電
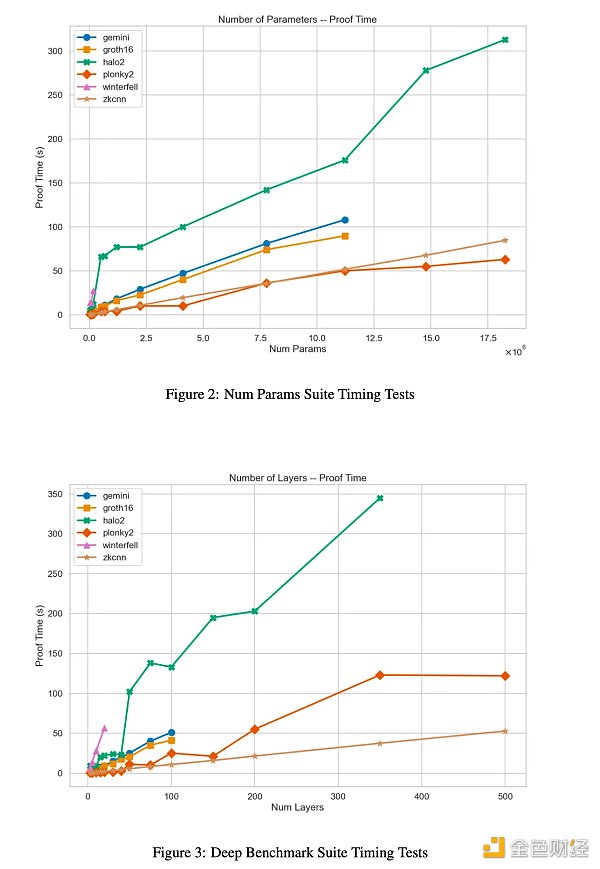
對於以上6 個證明系統的參數和深度範圍的證明生成時間結果
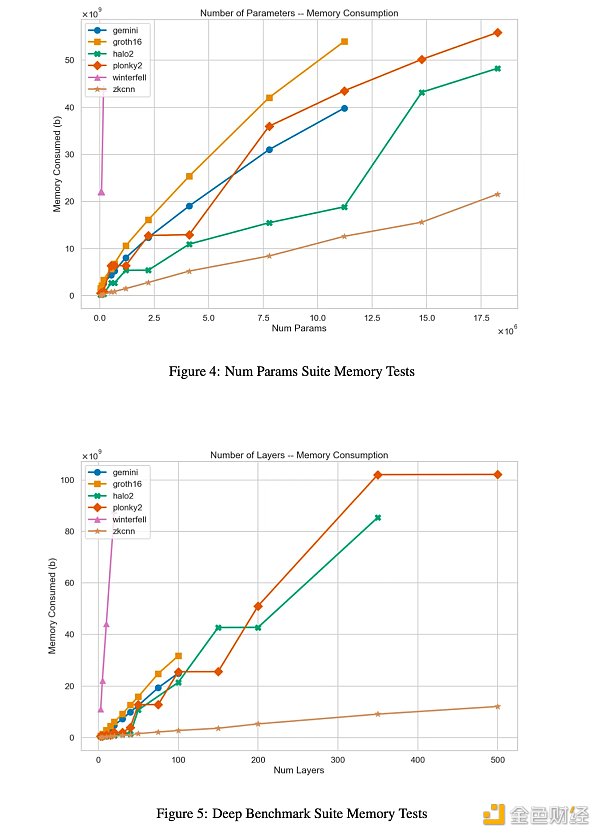
對於以上6 個證明系統的參數和深度範圍內的峰值內存結果
有關這些結果的完整內容,以及對每個系統內瓶頸的深入分析,請參閱paper0 的第4 節。
用例和最終要點
好吧,以上是一些非常簡潔的圖表,而以下則是要點:
“在證明時間方面,Plonky2 是迄今為止表現最好的系統,因為它使用了基於FRI 的多項式承諾和Goldilocks 域。 事實上,對於我們最大的基準架構,它比Halo2 快3 倍。
然而,這是以prover 內存消耗為顯著代價的,Plonky2 的性能始終較差,有時會使Halo2 的峰值RAM 使用量翻倍。
在證明時間和內存方面,基於GKR 的zkCNN prover 似乎最適合處理大型模型——即使沒有優化的實現。 ”
那這在實踐中究竟意味著什麼?我們將重點介紹2 個示例:
1、Worldcoin:Worldcoin 正在構建世界上第一個“隱私保護身份證明協議”(或PPPoPP),換句話說,通過將身份驗證與一種非常獨特的生物特徵(虹膜)聯繫起來來解決女巫攻擊問題。這是一個瘋狂的想法,它使用卷積神經網絡來壓縮、轉換和證明存儲的虹膜數據。雖然他們當前的設置涉及orb 硬件中安全飛地內的可信計算環境,但他們希望改為使用ZKP 來證明模型的正確計算。這將允許用戶對自己的生物特徵數據進行自我保護,並提供加密安全保證(只要在用戶的硬件上進行處理,比如手機)。
現在具體一點:Worldcoin 的模型具有180 萬參數和50 層。這是區分100 億個不同虹膜所必需的模型複雜性。哎呀!
雖然在計算優化的雲CPU 上證明Plonky2 等系統,可以在幾分鐘內為這種規模的模型生成推理證明,但證明者的內存消耗將超過任何商用移動硬件(數十GB 的RAM)。
事實上,沒有一個測試系統能夠在移動硬件上證明這個神經網絡……
2. AI Arena:AI Arena 是一款類似於《任天堂明星大亂鬥》風格的鏈上平台格鬥遊戲,其具有一個獨特的特點:玩家並不是操作化身實時進行對抗,而是讓玩家擁有的AI 模型相互競爭和戰鬥,是的,這聽起來很酷。
隨著時間的推移,AI Arena 的出色團隊正努力將他們的遊戲轉向一個完全無需信任的錦標賽計劃。但問題是,這涉及驗證每次遊戲數量驚人的AI 計算的挑戰。
比賽以每秒60 幀的速度運行,持續3 分鐘時間。這意味著每輪比賽,兩個玩家模型之間的推理結果超過20000 個。以AI Arena 的一個策略網絡為例,一個相對較小的MLP 需要大約0.008 秒來執行一次前向傳遞,使用zkCNN 證明該模型需要0.6 秒,即,每採取一次動作就需要增加1000 倍的計算。
這也意味著計算成本將增加1000 倍。隨著單元經濟對鏈上服務變得越來越重要,開發人員必須平衡去中心化安全的價值與證明生成的實際成本。

https://aws.amazon.com/ec2/pricing/
無論是上面的例子,ZK-KYC,DALL-E 風格的圖像生成,還是智能合約中的大型語言模型,ZKML 的世界中都存在著一個完整的用例世界。然而,要真正實現這些,我們強烈認為ZK prover 仍需要大量改進。特別是對於自我完善的區塊鏈的未來。
那麼,我們該何去何從?
我們有具體的表現數據,我們知道在證明神經網絡時哪些技術往往表現最好。當然,我們開始發現各種用例,這些用例激勵了我們不斷成長的社區。

我想知道接下來會發生什麼……
很快就會為你們提供更多更新;)