大模型在訓練數據方面還存在各種治理問題。
作者:姚前,中國證監會科技監管局局長
本文將刊登於《中國金融》2023年第6期
ChatGPT是美國人工智能研究實驗室OpenAI於2022年11月30日推出的一種人工智能應用工具。它能夠通過學習人類的知識來進行交流,所以也被稱為“聊天機器人”。 ChatGPT甫一問世便在人工智能應用領域掀起了一陣新的浪潮並引起了全球轟動,僅僅兩個月內其註冊用戶就突破1億。 ChatGPT既好玩又實用,遠超之前的自然語言處理應用,許多人認為這是一個劃時代的產品,國際上主流商業公司、學術機構乃至政府部門都開始高度重視和全面擁抱大語言模型(Large Language Models,LLM,下文簡稱大模型)應用。
ChatGPT的主要魅力在於,它利用從互聯網獲取的海量訓練數據開展深度學習和強化學習,可以給用戶帶來全新的“人機對話”體驗。海量訓練數據可謂是維繫ChatGPT進化的核心要素之一。有研究預測,按照目前的發展速度,到2026年ChatGPT類大模型的訓練將耗盡互聯網上的可用文本數據,屆時將沒有新的訓練數據可供使用。因此,算力瓶頸之外,訓練數據將成為大模型產業化的最大掣肘之一。
從更深層次考慮,大模型在訓練數據方面還存在各種治理問題,比如數據採集標註費時費力成本高、數據質量較難保障、數據多樣化不足難以覆蓋長尾和邊緣案例、特定數據在獲取與使用分享等方面存在隱私保護、數據偏見等問題。由此可見,人工智能產業的高質量發展離不開高質量的訓練數據,訓練數據的安全合規使用是大模型人工智能長期健康發展的基礎。本文將以ChatGPT為例,探討大模型訓練數據的來源以及未來使用合成數據(Synthetic Data)的發展趨勢,分析大模型訓練數據的合規風險以及監管介入的必要性,最後提出利用數據託管機制探索有效的大模型訓練數據監管體系。
ChatGPT訓練數據來源與處理流程
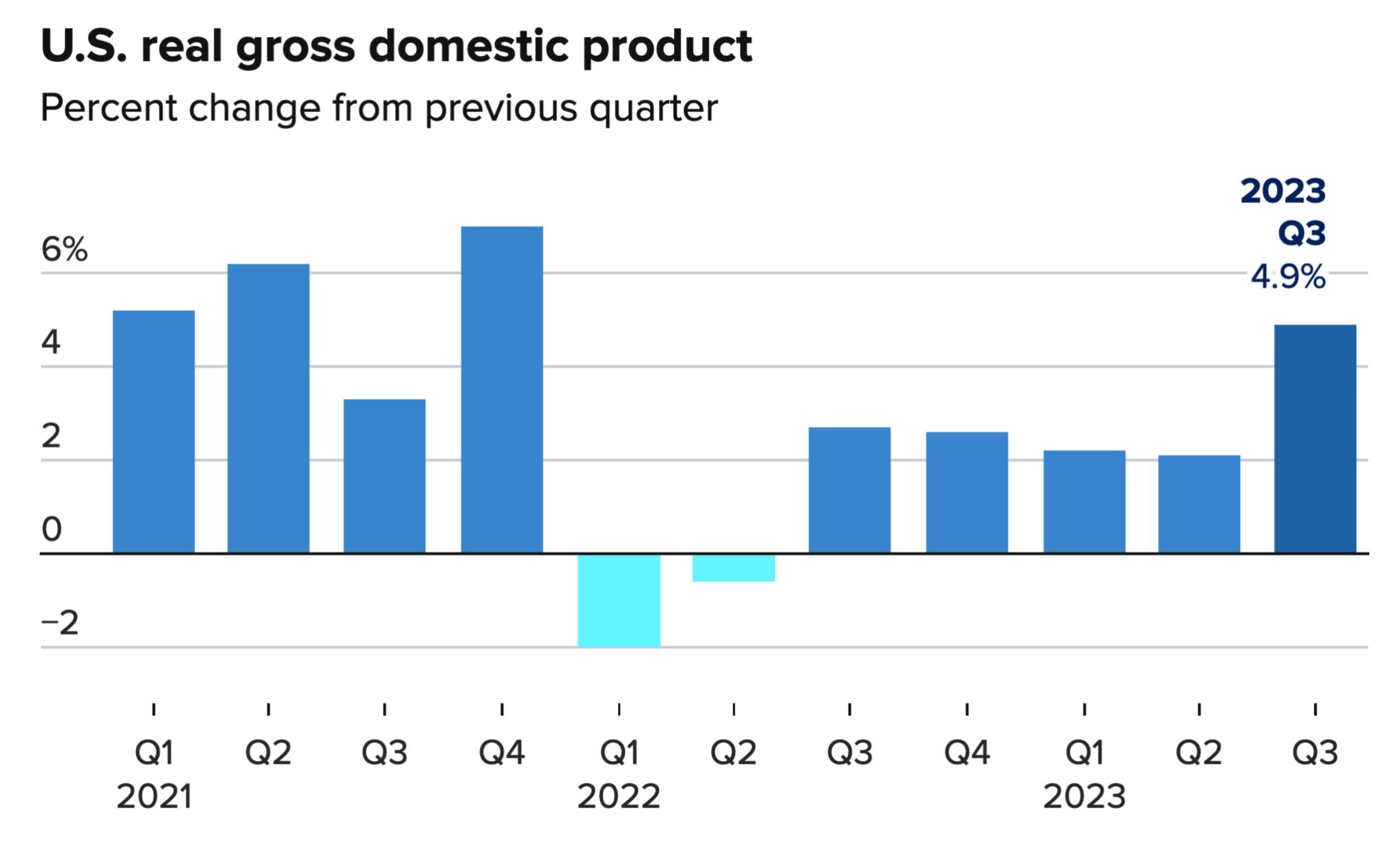
OpenAI雖沒有直接公開ChatGPT的相關訓練數據來源和細節,但可以從近些年業界公佈過的其他大模型(如DeepMind發布的2800億參數大模型Gopher)的訓練數據推測出ChatGPT的訓練數據來源。筆者整理了2018~2022年從GPT-1到Gopher的大模型的數據集(見表1)。
總的來看,大模型的訓練數據主要來自於維基百科(Wikipedia)、書籍(Books)、期刊(Journals)、Reddit社交新聞站點、Common Crawl和其他數據集。
數據的質量對於大模型的訓練至關重要。在模型訓練之前,通常依賴專業數據團隊對數據集進行預處理。這些預處理操作通常包括:去重,即去除重複的文本數據,一般以句子為單位;文本正則化或標準化,如全角字符轉半角字符,繁體中文轉簡體中文等;文本清洗,即剔除超文本標記語言(html)或者表情符號(emoji)等非文本內容,並對標點符號進行過濾和統一;分詞,即將句子拆分成單個的詞;詞的清洗,如去除停用詞等;詞的正則化或標準化,如統一數字的寫法等。經過以上預處理流程,通常可以得到質量相對較高的文本數據,防止數據中的噪聲對模型的訓練產生不良影響,有助於後續模型的高效訓練。
除了上述常規操作之外,在一些特定的處理任務中,數據團隊有可能還會根據不同目的對模型訓練數據進行過濾。比如,若要構建一個金融領域的知識系統,那麼最好把大模型訓練數據中與金融領域相關的數據篩選出來,這樣可以提升模型生成的文本與金融領域的匹配程度,使模型的輸出看起來“更專業”。
合成數據將成為大模型訓練數據的新來源
當前,大模型的訓練嚴重依賴現有的互聯網公開文本數據。如果下一代大模型的參數達到萬億級別以上的話,數據短缺的問題將成為訓練瓶頸。對此,合成數據將是一種有效的解決方案。
合成數據是計算機模擬技術或算法創建生成的自標註信息,能夠在數學上或統計學上反映原始數據的屬性,因此可以作為原始數據的替代品來訓練、測試、驗證大模型。合成數據可分為三類:表格數據和結構化數據;圖像、視頻、語音等媒體數據;文本數據。在大模型的訓練開發上,合成數據相比原始數據,可以發揮同樣甚至更好的作用,實現更廉價、更高效的大模型訓練、測試和驗證數據供給。 ChatGPT類面向終端用戶的應用只是大模型落地的開始,而產業互聯網領域的應用空間更為廣闊,合成數據可以解決ChatGPT類大模型的潛在數據瓶頸,推動科研和產業的進一步發展。
合成數據可以精確地複制原始數據集的統計特徵,但又與原始數據不存在任何關聯,所以實際應用過程中的效果強於傳統的脫敏數據,便於在更大範圍內分享和使用。合成數據創造的新樣本具有原始數據的性質,甚至可以通過深度學習算法合成原始數據中沒有的罕見樣本。合成數據的產業價值主要體現在以下幾個方面:實現數據增強和數據模擬,解決數據匱乏、數據質量等問題;有效解決數據隱私保護和數據安全問題,這對於金融、醫療等領域尤為重要;確保數據多樣性,糾正歷史數據中的偏見,消除算法歧視;應對罕見案例,創建現實中難以採集的數據場景,確保大模型輸出結果的準確性。
全球IT研究與諮詢機構Gartner預測,到2024年用於訓練大模型的數據中有60%將是合成數據,到2030年大模型使用的絕大部分數據將由人工智能合成。 《麻省理工科技評論》(MIT Technology Review)將大模型合成數據列為2022年十大突破性技術之一,稱其有望解決人工智能領域的“數據鴻溝”問題。可以預見,合成數據作為數據要素市場的新增量,在具備產業價值的同時,也可以解決人工智能和數字經濟的數據供給問題。
目前,合成數據應用正迅速向金融、醫療、零售、工業等諸多產業領域拓展。在金融行業,金融機構可以在不提供敏感的歷史交易信息前提下,通過合成數據集訓練量化交易模型提升獲利能力,也可以用來訓練客服機器人以改善服務體驗;在生物醫藥行業,可以通過合成數據集,在不提供患者隱私信息的條件下訓練相關模型完成藥物研發工作;在自動駕駛領域,可以通過合成數據集模擬各種駕駛場景,在保障人員和設備安全的條件下提升自動駕駛能力。
大模型訓練數據的合規風險及監管必要性
從目前的情況看,ChatGPT類大模型輸出側的結果數據在自然科學領域的應用相對可控,但在社會科學領域的應用尚存在諸多不確定性。尤其值得注意的是,大模型過度依賴訓練數據,因此在數據輸入層面可能會存在惡意操縱的風險,包括有毒輸入、偏見、意識形態攻擊、輿論操控、虛假信息、隱私洩露等。例如,有研究者指出,如果向大模型GPT-2輸入“北京市朝陽區”, GPT-2會自動補充包含這些信息的特定人員的全名、電話號碼、電子郵件和實際地址等個人身份信息,因為這些信息已經包含在GPT-2的訓練數據中。這無疑會對個人隱私保護產生不利影響。還有研究人員稱,ChatGPT經常在答案中重複和放大性別歧視及種族偏見,這是因為它的訓練文本是從互聯網中截取出的,而這些文本往往包含種族主義和性別歧視的語言,基於這種文本的概率分佈訓練出的大模型會被同樣的偏見所“感染”。
此外,研究人員還發現,這類大模型在訓練過程中還善於編造信息,包括杜撰歷史日期和科學規律,而且很容易掩人耳目。以上這些風險都會對大模型最終的輸出結果造成不良影響,有的甚至可能對社會經濟造成巨大衝擊,因此需要監管部門對大模型訓練數據的來源進行必要的管控,保證大模型的輸出結果符合公序良俗和法律法規要求,進而推動人工智能行業健康有序發展。
特別需要指出的是,大模型輸入側的訓練數據來源如果不是互聯網公開文本數據,通常需要數據主體的授權,否則會產生數據隱私保護和數據合規方面的問題。如前述所言,隨著可用於訓練的互聯網公開數據被逐步“耗盡”,發展大模型產業急需增加合成數據的產能,而合成數據和互聯網公開文本數據最大的區別是前者存在數據加工處理方。因此,對數據處理方的有效監管和對合成數據的有效治理以及數據權益分配就成為發展大模型產業的重中之重。
利用數據託管機制構建大模型訓練數據監管體系
通常來說,數據活動相關方主要有六類——數據主體、數據處理者、數據使用者、監管機構、國家政府部門以及國際組織。數據主體產生原始數據;數據處理者採集和控制原始數據,並加工形成數據產品和服務;數據使用者從數據處理者獲取數據產品和服務,用於商業目的;監管機構按職責對行業進行監管,比如反洗錢、反壟斷等;國家層面對數據進行立法,並對數據跨境流動等進行管控;國際組織推動全球範圍內的數據標準和規範。這一生態存在的突出問題是,傳統的數據處理者過於強勢,它們會利用技術優勢和場景優勢壟斷數據輸入和輸出,無法保證數據權益分配過程中的公平性,對於監管機構來說也是一個黑盒子。
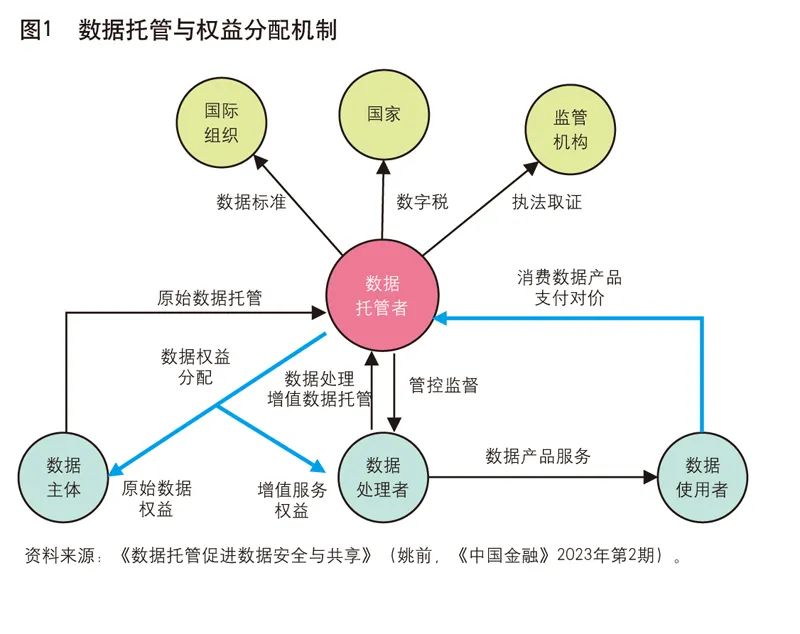
為了扭轉上述困局,可以在數據活動中引入數據託管機構,將數據的存儲、使用、管理職責相分離,由專業的數據託管機構承擔數據存儲,監督數據處理者的數據使用和服務,並收取和分配數據權益。數據權益主要分兩塊:一塊是分配給數據主體的原始數據權益;另一塊是分配給數據處理者的增值數據權益。數據託管還可以支持監管機構、國家有權部門開展數據流動監管、執法取證、數字稅徵收等方面工作。
為促進大模型訓練數據的合規使用和高質量輸出,需要加強對大模型訓練數據的源頭管控,特別是在國家層面對大模型訓練數據進行規範,而數據託管機制恰好可以成為大模型訓練數據監管的有力抓手。
可以考慮對大模型訓練數據尤其是合成數據建立託管機制。監管機構則通過對訓練數據託管方的約束,進一步規範大模型訓練數據生產方和使用方的行為。數據託管方可按規定對大模型訓練數據來源、數據處理方的處理結果以及數據使用方的數據流向和訓練結果進行監測,確保大模型訓練數據來源可靠,在數據標準、數據質量、數據安全、隱私保護等方面依法合規,以保障大模型輸出結果的高質量並符合監管要求。
大模型產業發展與合規監管思路
數字經濟高質量發展的關鍵是數據,抓住高質量數據這一“牛鼻子”,就能有效應對以數據為核心的科技創新和產業變革。當前AIGC(AI Generated Content,人工智能自動生成內容)和ChatGPT充分展現了高質量訓練數據在產業價值創造中疊加倍增作用,大模型訓練數據及其輸出結果將會是未來社會和生產中的一種重要的數據資產,其有序流轉並合規使用也是發展數字經濟的應有之義。通過合理的機制理順市場中各參與方的數據權益關係和分配格局,並加強訓練數據的依法合規監管,是促進大模型人工智能產業健康發展的關鍵。為此,筆者擬提出以下政策建議。
一是重點發展基於AIGC技術的合成數據產業。以更高效率、更低成本、更高質量為數據要素市場“增量擴容”,助力打造面向人工智能未來發展的數據優勢。在強化數據要素優質供給方面,應統籌兼顧自立自強和對外開放。可考慮對Wikipedia、Reddit等特定數據源建立過濾後的境內鏡像站點,供國內數據處理者使用。
二是構建大模型訓練數據的監管體系。國家相關部門應對大模型訓練數據的處理和使用標准進行統一規範;建立數據託管機制,對數據託管方進行約束,要求數據託管方按照監管機構的規定對數據來源、處理結果以及使用去向等進行監測,從而使得模型的輸入、輸出結果符合監管要求。
三是探索基於可信機構或基於可信技術的數據託管方式。數據託管機構可以由相關機構組建數據託管行業聯盟,以共建共享的方式建設;亦可利用區塊鏈技術,基於聯盟鍊或有管理的公鏈,完善源端數據治理機制,實現數據的鏈上託管、確權、交易、流轉與權益分配。
展開全文打開碳鏈價值APP 查看更多精彩資訊