
為什麼AI 聊天機器人會胡編亂造,我們是否能夠完全信任它們的輸出?
撰文:Benj Edwards
來源:Ars Technica
編譯:巴比特
在過去的幾個月裡,像ChatGPT 這樣的人工智能聊天機器人已經吸引了全世界的注意力,因為它們能夠以類似人類的方式就幾乎任何話題進行交談。但它們也有一個嚴重的缺點:它們可以輕易地提出令人信服的虛假信息,使它們成為不可靠的事實信息來源和潛在的誹謗來源。
為什麼AI 聊天機器人會胡編亂造,我們是否能夠完全信任它們的輸出?我們詢問了幾位專家,並深入研究了這些人工智能模型的工作原理,以找到答案。
“幻覺”:人工智能中的一個重要術語
人工智能聊天機器人,如OpenAI 的ChatGPT,依賴於一種稱為“大型語言模型”(LLM)的人工智能來生成它們的響應。 LLM 是一種計算機程序,經過數百萬文本源的訓練,可以閱讀並生成“自然語言”文本語言,就像人類自然地寫作或交談一樣。不幸的是,它們也會犯錯。
在學術文獻中,人工智能研究人員經常將這些錯誤稱為“幻覺”(hallucinations)。但是,隨著這個話題成為主流,這個標籤的爭議也越來越大,因為有些人認為它把人工智能模型擬人化了(暗示它們有類似人類的特徵),或者在不應該暗示這一點的情況下賦予它們代理(暗示它們可以做出自己的選擇)。商業LLM 的創造者也可能利用幻覺作為藉口,將錯誤的輸出歸咎於AI 模型,而不是為輸出本身負責。
不過,生成式AI 太新了,我們需要從現有的想法中藉用隱喻來向更廣泛的公眾解釋這些高度技術性的概念。在這種情況下,我們覺得術語“虛構”(confabulation)雖然同樣不完美,但比“幻覺”更好。在人類心理學中,當某人的記憶有一個缺口,而大腦在無意欺騙他人的情況下令人信服地填補其餘部分時,就會出現“虛構”。 ChatGPT 的工作方式與人腦不同,但“虛構”一詞可以說是一個更好的比喻,因為有一個創造性的填補空白的原則在起作用,我們將在下文進行探討。
“虛構”的問題
當人工智能機器人產生可能誤導、誤傳或誹謗的虛假信息時,這是一個大問題。最近,《華盛頓郵報》報導了一位法律教授,他發現ChatGPT 將他列入了一份對某人進行過性騷擾的法律學者名單。但這件事從未發生過– 是ChatGPT 編造的。同一天,Ars 報導了一位澳大利亞市長,據稱他發現ChatGPT 聲稱他被判定犯有賄賂罪並被判處監禁,這也完全是捏造的。
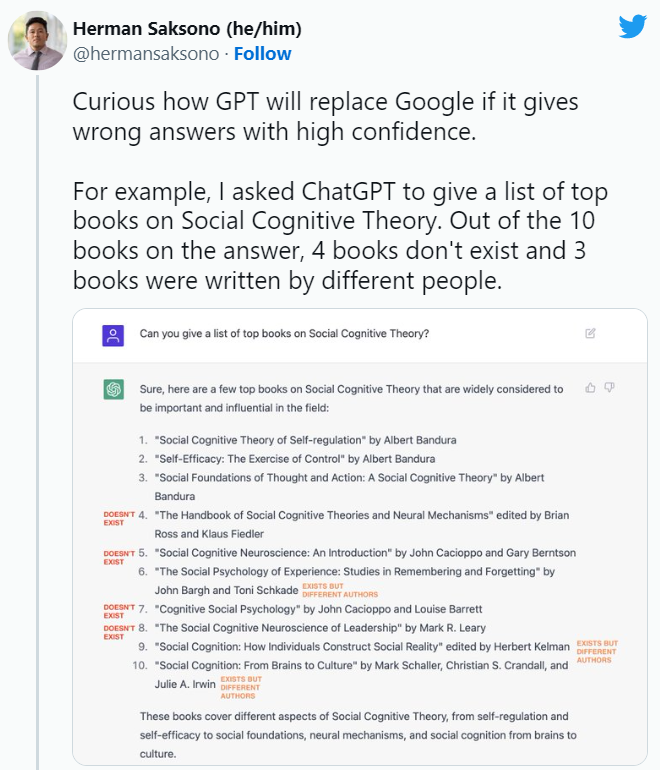
ChatGPT 推出後不久,人們就開始宣稱搜索引擎的終結。然而,與此同時,ChatGPT 的許多虛構的例子開始在社交媒體上流傳。人工智能機器人發明了不存在的書籍和研究,教授沒有寫過的出版物,虛假的學術論文,虛假的法律引用,不存在的Linux 系統功能,不真實的零售吉祥物,以及沒有意義的技術細節。
然而,儘管ChatGPT 傾向於隨意撒些小謊,但與直覺相反的是,它對虛構的抵抗才是我們今天談論它的原因。一些專家指出,ChatGPT 在技術上比vanilla GPT-3(其前身模型)有所改進,因為它可以拒絕回答一些問題或讓你知道它的答案可能不准確。
大型語言模型專家、Scale AI 的提示工程師Riley Goodside 說:“ChatGPT 成功的一個主要因素是,它成功地抑制了虛構,使許多常見問題都不引人注意。”“與它的前輩相比,ChatGPT 明顯不太容易編造東西。”
如果用作頭腦風暴工具,ChatGPT 的邏輯跳躍和虛構可能會導致創造性突破。但當用作事實參考時,ChatGPT 可能會造成真正的傷害,OpenAI 也知道這一點。
在該模型推出後不久,OpenAI 首席執行官Sam Altman 在推特上說:“ChatGPT 有很大的局限性,但在某些方面足夠好,足以造成一種偉大的誤導性印象。現在依靠它來做任何重要的事情都是錯誤的。這是進步的預覽;我們在穩健性和真實性方面還有很多工作要做。”在後來的一條推文中,他寫道:“它確實知道很多東西,但危險的是,它在相當大的一部分時間裡是自信而錯誤的。”
這是怎麼回事呢?
ChatGPT 如何運作
為了理解像ChatGPT 或Bing Chat 這樣的GPT 模型是如何虛構信息的,我們必須知道GPT 模型是如何運作的。雖然OpenAI 還沒有發布ChatGPT、Bing Chat 甚至GPT-4 的技術細節,但我們確實可以看到2020 年介紹其前身GPT-3 的研究論文。
研究人員通過使用一個被稱為“無監督學習”的過程來建立(訓練)像GPT-3 和GPT-4 這樣的大型語言模型,這意味著他們用來訓練模型的數據沒有被特別註釋或標記。在這個過程中,模型被輸入大量的文本(數以百萬計的書籍、網站、文章、詩歌、成績單和其他來源),並反复嘗試預測每個單詞序列中的下一個單詞。如果模型的預測接近實際的下一個詞,神經網絡就會更新其參數以加強導致該預測的模式。
相反,如果預測不正確,該模型就會調整其參數以提高其性能並再次嘗試。這種試錯的過程,通過一種叫做“反向傳播”的技術,使模型能夠從錯誤中學習,並在訓練過程中逐漸改善其預測結果。
因此,GPT 學會了數據集中的單詞和相關概念之間的統計關聯。有些人,如OpenAI 首席科學家Ilya Sutskever,認為GPT 模型甚至比這更進一步,建立了一種內部現實模型,因此可以更準確地預測下一個最佳標記,但這個想法是有爭議的。 GPT 模型如何在其神經網絡內得出下一個token 的確切細節仍不確定。

在當前的GPT 模型浪潮中,這種核心訓練(現在通常稱為“預訓練”)只發生一次。之後,人們可以在”推理模式“中使用訓練好的神經網絡,這讓用戶可以將輸入信息輸入到訓練好的網絡中並得到一個結果。在推理過程中,GPT 模型的輸入序列總是由人類提供,它被稱為“提示”(prompt)。提示決定了模型的輸出,即使稍微改變一下提示,也會極大改變模型產生的結果。
例如,如果您提示GPT-3“Mary had a”,它通常會用“little lamb.”來完成句子。這是因為在GPT-3 的訓練數據集中可能有數以千計的“Mary had a little lamb”的例子。但是,如果你在提示中添加更多的上下文,例如“In the hospital, Mary had a,”,結果就會改變,並返回“嬰兒”或“一系列檢測”等詞。
這就是ChatGPT 的有趣之處,因為它被設定為與代理對話,而不僅僅是一個直接的文本完成工作。在ChatGPT 的情況下,輸入提示是你與ChatGPT 的整個對話,從你的第一個問題或聲明開始,包括在模擬對話開始前提供給ChatGPT 的任何具體指示。在這一過程中,ChatGPT 對它和你所寫的一切都保持一個運行中的短期記憶(稱為“上下文窗口”),當它與你“交談”時,它試圖將對話的記錄作為一個文本完成任務來完成。

此外,ChatGPT 與普通的GPT-3 不同,因為它還接受了人類編寫的對話記錄的訓練。 OpenAI 在其最初的ChatGPT 發布頁面中寫道:“我們使用有監督的微調訓練了一個初始模型:人類AI 訓練員提供了他們扮演雙方角色的對話——用戶和AI 助手。”“我們讓培訓師可以訪問模型編寫的建議,以幫助它們撰寫回复。”
ChatGPT 還使用一種稱為“從人類反饋中強化學習”或RLHF 的技術,對ChatGPT 進行了比GPT-3 更嚴格的調整,在這種技術中,人類評分者根據偏好對ChatGPT 的回答進行排序,然後將這些信息反饋到模型中。通過RLHF, OpenAI 能夠在模型中灌輸避免回答許多它不能可靠回答的問題的目標。這使得ChatGPT 能夠以比基本模型以更少的虛構產生連貫的反應。但是不准確的地方仍然存在。
為什麼ChatGPT 會進行虛構
本質上,GPT 模型的原始數據集中沒有任何東西能將事實與虛構分開。這種指導來自於:a)數據集中準確內容的普遍性;b)人類對結果中事實信息的識別;或者c)來自人類的強化學習指導,強調某些事實的反應。
LLMs 的行為仍然是一個活躍的研究領域。甚至創建這些GPT 模型的研究人員仍在發現該技術令人驚訝的特性,這些特性在最初開發時無人預測到。 GPT 能夠做許多我們現在看到的有趣事情,如語言翻譯、編程和下棋,一度讓研究人員感到驚訝(要了解早期的情況,請查看2019 年的GPT-2 研究論文並蒐索“surprising”一詞)。
因此,當我們問及ChatGPT 為什麼會進行虛構時,很難找出一個準確的技術答案。而且,由於神經網絡權重存在一個“黑匣子”的因素,所以在一個複雜的提示下,很難(如果不是不可能)預測它們的確切輸出。儘管如此,我們還是知道一些虛構發生的基本原因。
理解ChatGPT 的虛構能力的關鍵是理解它作為預測機器的角色。當ChatGPT 虛構時,它正在尋找數據集中不存在的信息或分析,並用聽起來合理的詞來填補空白。 ChatGPT 特別擅長編造東西,因為它必須處理的數據量非常大,而且它收集單詞上下文的能力非常好,這有助於它將錯誤信息無縫地放置到周圍的文本中。
“我認為思考虛構的最好方法是思考大型語言模型的本質:它們唯一知道怎麼做的事情是根據統計概率,根據訓練集選擇下一個最好的單詞,”軟件開發人員Simon Willison 說,他經常就這個主題撰寫文章。
在2021 年的一篇論文中,來自牛津大學和OpenAI 的三位研究人員確定了像ChatGPT 這樣的LLM 可能產生的兩大類虛假信息。第一種來自於其訓練數據集中不准確的源材料,如常見的錯誤概念(例如,“吃火雞會讓人昏昏欲睡”)。第二種情況來自於對其訓練材料(數據集)中不存在的特定情況的推斷;這屬於前述的“幻覺”標籤。
GPT 模型是否進行胡亂猜測是基於人工智能研究人員稱之為“溫度”的屬性,它通常被描述為“創造力”設置。如果創造力設置得高,模型就會胡亂猜測;如果設置得低,它就會根據其數據集確定性地吐出數據。
最近,在Bing Chat 工作的微軟員工Mikhail Parakhin在推特上談到了Bing Chat 的幻覺傾向以及造成這種情況的原因。 ”這就是我之前試圖解釋的:幻覺= 創造力,“他寫道。 ”它試圖利用它所掌握的所有數據產生字符串的最高概率的延續。很多時候它是正確的。有時人們從未產生過這樣的延續。“
Parakhin 說,那些瘋狂的創造性跳躍是使LLM 有趣的原因。 ”你可以箝制幻覺,但這超級無聊,“他寫道。 ”[它] 總是回答’我不知道’,或者只讀搜索結果中存在的內容(有時也不正確)。現在缺少的是語調:在這些情況下,它不應該聽起來如此自信“。
當涉及到微調像ChatGPT 這樣的語言模型時,平衡創造性和準確性是一個挑戰。一方面,提出創造性回應的能力使ChatGPT 成為產生新想法或解開作者瓶頸的強大工具。這也使模型聽起來更人性化。另一方面,當涉及到產生可靠的信息和避免虛構時,源材料的準確性至關重要。在這兩者之間找到適當的平衡是語言模型發展的一個持續的挑戰,但這是產生一個既有用又值得信賴的工具所必須的。
此外還有壓縮問題。在訓練過程中,GPT-3 考慮了PB 級的信息,但得到的神經網絡的大小只是它的一小部分。在一篇被廣泛閱讀的《紐約客》文章中,作者Ted Chiang 稱這是一張“模糊的網絡JPEG”。這意味著大部分事實訓練數據會丟失,但GPT-3 通過學習概念之間的關係來彌補這一點,之後它可以使用這些概念重新制定這些事實的新排列。就像一個記憶力有缺陷的人憑著對某件事情的直覺工作一樣,它有時會把事情弄錯。當然,如果它不知道答案,它也會給出它最好的猜測。
我們不能忘記提示在虛構中的作用。在某些方面,ChatGPT 是一面鏡子:你給它什麼,它就回給你什麼。如果你給它提供虛假的信息,它就會傾向於同意你的觀點,並沿著這些思路”思考“。這就是為什麼在改變主題或遇到不需要的反應時,用新的提示開始是很重要的原因。 ChatGPT 是概率性的,這意味著它在本質上是部分隨機的。即使是相同的提示,它的輸出也會在不同的時段發生變化。
所有這些都導致了一個結論,一個OpenAI 也同意的結論:目前設計的ChatGPT 並不是一個可靠的事實信息來源,因此不能信任它。 ”ChatGPT 對某些事情來說是很好的,比如疏通作家的障礙或想出創造性的想法,“人工智能公司Hugging Face 的研究員和首席道德科學家Dr. Margaret Mitchell 說。 “它不是為事實而建的,因此也不會是事實。就是這麼簡單。”
虛構能被解決嗎?
盲目相信AI 聊天機器人的世代是一個錯誤,但隨著底層技術的改進,這種情況可能會改變。自11 月發布以來,ChatGPT 已經升級了幾次,一些升級包括準確性的提高以及拒絕回答它不知道答案的問題的能力。
那麼,OpenAI 計劃如何使ChatGPT 更加準確?在過去幾個月裡,我們就這個問題多次聯繫OpenAI,但沒有得到任何回應。但我們可以從OpenAI 發布的文件和關於該公司試圖引導ChatGPT 與人類工作者接軌的新聞報導中拉出線索。
如前所述,ChatGPT 如此成功的原因之一是使用RLHF 的廣泛培訓。正如OpenAI 所解釋的那樣,” 為了使我們的模型更安全、更有幫助、更一致,我們使用了一種現有的技術,稱為從人類反饋中強化學習(RLHF)。在我們的客戶向API 提交的提示中,我們的標籤人員提供了所需模型行為的演示,並對我們模型的幾個輸出進行排名。然後我們使用這些數據對GPT-3 進行微調。“
OpenAI 的Sutskever 認為,通過RLHF 進行額外的訓練可以解決幻覺問題。 Sutskever 在本月早些時候接受《福布斯》採訪時說:“我非常希望,通過簡單地改進人類反饋步驟中的後續強化學習,我們可以教會它不要產生幻覺。”
他繼續說道:
我們現在做事的方式是僱人來教我們的神經網絡如何行動,教ChatGPT 如何行動。你只要和它互動,它就會根據你的反應,推斷出,哦,這不是你想要的。你對它的輸出不滿意。因此,輸出不是很好,下次應該做一些不同的事情。我認為這種方法很有可能完全解決幻覺問題。
就這一問題也有其他不同聲音。 Meta 公司的首席人工智能科學家Yann LeCun 認為,幻覺問題不會被使用GPT 架構的當前一代LLM 所解決。但有一種迅速出現的方法,可能會給使用當前架構的LLM 帶來很大的準確性。
Goodside 說:“在提高LLM 的事實性方面,研究得最積極的方法之一是檢索增強– 向模型提供外部文件作為來源和支持性背景”。他解釋說,通過這種技術,研究人員希望教會模型使用像谷歌這樣的外部搜索引擎,“像人類研究人員那樣在它們的答案中引用可靠的來源,並減少對模型訓練期間學到的不可靠的事實性知識的依賴。”
Bing Chat 和Google Bard 已經通過引入網絡搜索做到了這一點,很快,支持瀏覽器的ChatGPT 版本也將如此。此外,ChatGPT 插件旨在用它從外部來源(如網絡和專門的數據庫)檢索的信息來補充GPT-4 的訓練數據。這種增強類似於有百科全書的人會比沒有百科全書的人更準確地描述事實。
此外,也許可以訓練像GPT-4 這樣的模型,讓它意識到自己何時在編造事情並進行相應的調整。 Mitchell 說:“人們可以做一些更深入的事情,讓ChatGPT 和類似的東西從一開始就更加真實,包括更複雜的數據管理,以及使用一種類似於PageRank 的方法,將訓練數據與’信任’分數聯繫起來……當它對回應不那麼有信心時,還可以對模型進行微調以對沖風險。”
因此,雖然ChatGPT 目前因虛構問題陷入困境,但未來可能還有出路,為了一個開始依賴這些工具作為基本助手(無論好壞)的世界,事實可靠性的改善不會很快到來。
展開全文打開碳鏈價值APP 查看更多精彩資訊