

在AI競速的賽道上,奔跑的不只有科技巨頭,開源社區正在從小徑中湧入大道,成為人工智能開發層面不可忽視的力量。
一份被意外洩露的谷歌內部文件,將Meta的LLaMA大模型“非故意開源”事件再次推到聚光燈前。
“洩密文件”的作者據悉是谷歌內部的一位研究員,他大膽指出,開源力量正在填平OpenAI與穀歌等大模型巨頭們數年來築起的護城河,而最大的受益者是Meta,因為該公司2月意外洩露的LLaMA模型,正在成為開源社區訓練AI新模型的基礎。
幾週內,開發者與研究人員基於LLaMA搞起微調訓練,接連發布了Alpaca、Vicuna、Dromedary等中小模型,不只訓練成本僅需幾百美元,硬件門檻也降低至一台筆記本電腦甚至一部手機,測試結果不比GPT-4差。
除了AI模型之外,FreedomGPT等類ChatGPT應用也如雨後春筍般湧現,基於LLaMa的“羊駝家族”不斷壯大,這位研究員認為,Meta很可能藉此形成生態,從而成為最大贏家。
事實上,人工智能的世界裡,的確有一部分進入了“安卓時刻”,這個部分就是開源社區。特斯拉前AI主管Andrej Karpathy評價開源社區中的AI進化時稱,他看到了“寒武紀大爆發的早期跡象”。
在AI競速的賽道上,奔跑的不只有科技巨頭,開源社區正在從小徑中湧入大道,成為人工智能開發層面不可忽視的力量。
LLaMa意外開源養出“羊駝家族”
“我們沒有護城河,OpenAI 也沒有。”一篇來自Google 內部的文章在SemiAnalysis 博客傳播,文章作者認為,Meta的LLaMa開源模型快速聚集起生態雛形,正在消除與GPT之間的差距,開源AI最終會打破Google與OpenAI的護城河。
這篇文章讓人重新註意到了Meta的LLaMA 大模型,該模型代碼被洩露後的2個月裡意外成了開源社區訓練自然語言模型的基礎,還產生了諸多中小模型及應用。
時間回到今年2月24日,Meta推出大語言模型LLaMA,按參數量分為7B、13B、33B和65B四個版本。別看參數量遠遠不及GPT-3,但效果在AI圈內獲得了一些正面評價,尤其是能在單張GPU運行的優勢。
Meta在官方博客中曾稱,像LLaMA這種體積更小、性能更高的模型,能夠供社區中無法訪問大量基礎設施的人研究這些模型,進一步實現人工智能大語言模型開發和訪問的民主化。
“民主化”來得異常快。 LLaMA推出一周後,一位名叫llamanon的網友在國外論壇4chan上以種子文件的方式上傳了7B和65B的LLaMA模型,下載後大小僅為219GB。此後,這個種子鏈接被發佈到開源社區GitHub,下載量超過千次。 LLaMA就這樣被洩露了,但也因此誕生了諸多實驗成果。
最初,名叫Georgi Gerganov 的開發者開源了一個名為llama.cpp的項目,他基於LLaMA 模型的簡易Python語言的代碼示例,手擼了一個純C/C++ 語言的版本,用作模型推理。換了語言的最大優勢就是研究者無需GPU、只用CPU能運行LLaMA模型,這讓大模型的訓練硬件門檻大大降低。
正如穀歌那位研究員寫得那樣,“訓練和實驗的門檻從一個大型研究機構的全部產出降低到1個人、1晚上和1台性能強大的筆記本電腦就能完成。”在開發者的不斷測試下,LLaMA已經能夠在微型計算機樹莓派4和谷歌Pixel 6手機上運行。
開源社區的創新熱情也徹底點燃,每隔幾天都會有新進展,幾乎形成了一個“LLaMA(羊駝)生態”。
3月15日,斯坦福大學微調LLaMA後發布了Alpaca(美洲駝)模型,僅用了52K數據,訓練時長為3小時。研究者宣稱,測試結果與GPT-3.5不分伯仲,而訓練成本還不到600美元,在一些測試中,Alpace與GPT-3.5的獲勝次數分別為90對89。
隨後,加州大學伯克利分校、卡內基梅隆大學、加州大學聖地亞哥分校的研究人員又提出新的模型Vicuna(小羊駝),也是基於LLaMa做出來的,訓練成本僅300美元。
在該項目的測評環節,研究人員讓GPT-4當“考官”,結果顯示,GPT-4在超過90%的問題中更強傾向於Vicuna的回答,並且Vicuna在總分上達到了ChatGPT的92%。
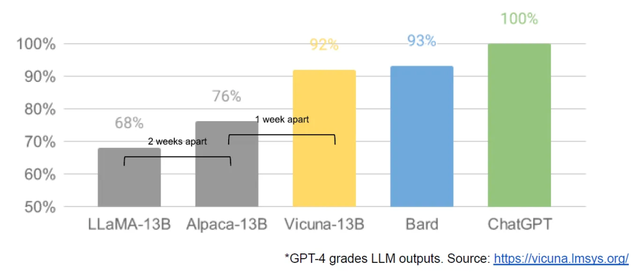 用GPT-4測評Vicuna與其他開源模型
用GPT-4測評Vicuna與其他開源模型
短短幾週,基於LLaMa構建的“羊駝家族”不斷壯大。
4月3日,伯克利人工智能研究院發布了基於LLaMa微調的新模型Koala(考拉),訓練成本小於100美元,在超過一半的情況下與ChatGPT 性能相當;5月4日,卡內基梅隆大學語言技術研究所、IBM 研究院與馬薩諸塞大學阿默斯特分校的研究者們,推出了開源自對齊語言模型Dromedary(單峰駱駝),通過不到300行的人工標註,就能讓65B的LLaMA基礎語言模型在TruthfulQA(真實性基準)上超越GPT-4。
在國內,垂直醫療領域的“羊駝家族”成員也出現了,哈爾濱工業大學基於LLaMa模型的指令微調,推出了中文醫學智能問診模型HuaTuo(華駝),該模型能夠生成專業的醫學知識回答。

哈工大推出中文醫學智能問診模型HuaTuo(華駝)
基於該模型的開源創新不僅在大模型上,應用層也有多點開花之勢。
3月31日,AI公司Age of AI推出了語言模型FreedomGPT,正是基於斯坦福大學的Alpaca開發出來的;3月29日,加州大學伯克利分校在它的Colossal-AI基礎下發布了ColossalChat對話機器人,能力包括知識問答、中英文對話、內容創作、編程等。
從基礎模型層到應用層,基於LLaMa所誕生的“羊駝家族”還在一路狂奔。
由於被“開源” 的LLaMA 出自Meta 之手,那位發文的谷歌研究員認為,Meta意外成了這場AI競爭中的最大受益者——借助開源社區的力量,Meta獲得了全世界頂級開發者的免費勞動力,因為大多數開源的AI 創新都發生在他們的基礎架構內,因此,沒有什麼能阻止Meta將這些成果直接整合到他們的產品中。
開源力量觸發“AI的安卓時刻”
ChatGPT引爆AI熱後,英偉達的CEO黃仁勳將這股浪潮喻為“AI的iPhone時刻”,他認為,AI行業進入瞭如iPhone誕生顛覆手機行業時的革命性時間點。而當LLaMA開啟開源社區的小宇宙後,網友認為,“AI的安卓時刻”來了。
回顧過去,谷歌曾以開源思想讓更多的開發者參與到安卓應用生態的建設中,最終讓安卓成為電腦與手機的系統/應用主流。如今,LLaMA再次讓AI業內看到了開源力量的強大。
智能軟硬件件開發公司出門問問的CEO李志飛也注意到了谷歌這篇內部聲音:
“大模型這個領域,Google已經在聲勢上大幅落後於OpenAI。在開源生態上,如果Google再猶豫不決,後面就算想開源也會大幅度落後於Meta的LLaMA。相反,如果開源,可以把OpenAI的壁壘進一步降低,而且會吸引(或留住)很多支持開源的高級人才。”
特斯拉前AI主管Andrej Karpathy認為:
“當前開源大模型的生態之勢,已經有了寒武紀大爆發的早期跡象。”
確實,開發者對開源的AI模型前所未有的熱情正在從Github的打星量指標中溢出:Alpaca獲得了23.2k星,llama.cpp獲26.3k星,LLaMA獲20.8k星……而在“羊駝家族”之前,AutoGPT等開源項目也在Github擁有超高的人氣,突破100k星。
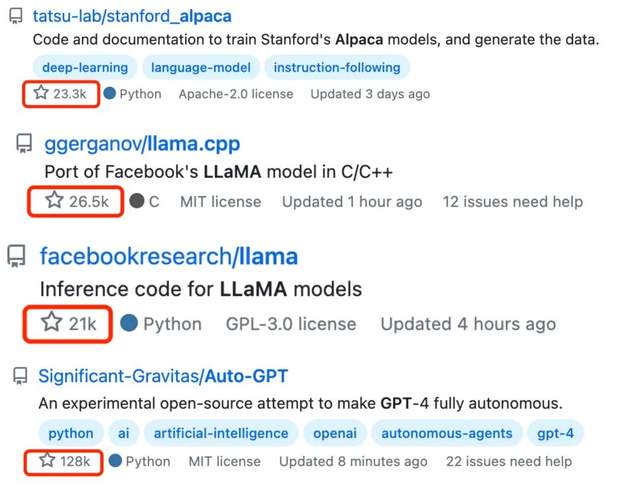 開發者對開源AI模型的打星量
開發者對開源AI模型的打星量
此外,為了追趕ChatGPT,構建大型開源社區的AI 初創公司Hugging Face 也在近日推出了開源聊天機器人HuggingChat,該機器人的底層模型擁有300 億個參數,並對外開放了訓練數據集。英偉達AI 科學家Jim Fan認為,如果後續開發應用程序,Hugging Face將比OpenAI 更具優勢。
開源力量來勢洶洶,手握OpenAI的微軟也並不准備把雞蛋都放在一個籃子裡。今年4月,微軟推出了開源模型DeepSpeed Chat,為用戶提供了“傻瓜式” 操作,將訓練速度提升了15倍。
以LLaMA 為核心的AI開源社區正在平行空間中,與OpenAI等走閉源路線的大模型巨頭展開競速,開源思想與實踐中爆發出的創新力量已經不容巨頭小覷了。
展開全文打開碳鏈價值APP 查看更多精彩資訊

