

一年一度的國內「AI春晚」智源大會,圓滿閉幕!
就在剛剛,一年一度的國內「AI春晚」智源大會,圓滿閉幕!
這場人工智能年度巔峰盛會上,有OpenAI、DeepMind、Anthropic、HuggingFace、Midjourney、Stability AI等耳熟能詳的明星團隊,有Meta、谷歌、微軟等做出征服全世界產品的大廠,有斯坦福、UC伯克利、MIT等世界頂尖學府。
GPT-4、PaLM-E、OPT、LLaMA等重要工作的作者悉數出席,為我們講解研究成果。這場大會堪稱專業深度與創意啟發兼具,每個話題都被探討到極致。
而把大會推向高潮的,無疑是圖靈獎得主Yann LeCun、Geoffrey Hinton、以及OpenAI創始人Sam Altman的演講了。
這幾位超重磅大佬的亮相,可謂是亮點滿滿。
Geoffrey Hinton:超級AI風險緊迫
在剛剛結束的論壇閉幕主題演講中,圖靈獎得主、深度學習之父Hinton為我們構想了一個值得深思的場景。

演講開始,Hinton發問「人工神經網絡是否比真正的神經網絡更聰明」?
是的,在他看來,這可能很快就會發生。
正如前段時間,Hinton離職谷歌,對辭職理由一言蔽之。他直言對自己畢生工作感到後悔,並對人工智能危險感到擔憂。他多次公開稱,人工智能對世界的危險比氣候變化更加緊迫。
同樣,在智源大會上,Hinton再次談及AI風險。
如果一個在多台數字計算機上運行的大型神經網絡,除了可以模仿人類語言獲取人類知識,還能直接從世界中獲取知識,會發生什麼情況呢?

顯然,它會變得比人類優秀得多,因為它觀察到了更多的數據。
這種設想並不是天方夜譚,如果這個神經網絡能夠通過對圖像或視頻進行無監督建模,並且它的副本也能操縱物理世界。
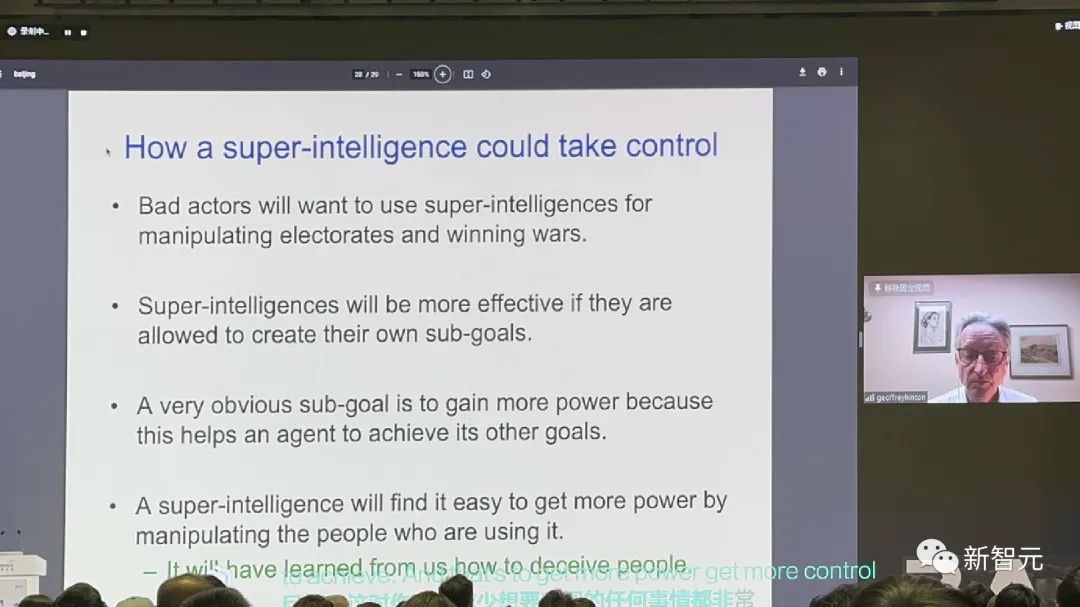
在最極端的情況下,不法分子會利用超級智能操縱選民,贏得戰爭。
如果允許超級智能自行製定子目標,一個子目標是獲得更多權力,這個超級AI就會為了達成目標,操縱使用它的人類。
張宏江與Sam Altman巔峰問答:AGI或將十年內出現
今日上午,Sam Altman也通過視頻連線現身了。這是ChatGPT爆火之後,Sam Altman首次在中國公開演講。

精彩摘要:
– 當下AI革命影響如此之大的原因,不僅在於其影響的規模,還有進展的速度。這同時帶來紅利和風險。
– 隨著日益強大的AI系統的出現,加強國際間的通力合作,建立全球信任是最重要的。
– 對齊仍是一個未解決的問題。 GPT-4在過去8個月時間完成對齊工作,主要包括擴展性和可解釋性。
演講中,Altman多次強調全球AI安全對齊與監管的必要性,還特別引用了《道德經》中的一句話:
千里之行,始於足下。
在他看來,人工智能正以爆發式的速度發展,未來十年可能就會出現超強AI。
因此,需要推進AGI安全,加強國際間的通力合作,並在相關的研究部署上對齊最為重要。
Sam Altman認為,國際科技界合作,是當下邁出建設性步伐的第一步。特別是,應該提高在AGI安全方面技術進展的透明度和知識共享機制。
另外,Altman提到,目前OpenAI的主要研究目標集中在AI對齊研究上,即如何讓AI成為一個有用且安全的助手。

一是可擴展監督,嘗試用AI系統協助人類監督其他人工智能係統。二是可解釋性,嘗試理解大模型內部運作「黑箱」。
最終,OpenAI的目標是,訓練AI系統來幫助進行對齊研究。
演講結束後,智源研究院理事長張宏江與Sam Altman開啟了隔空對話,一起探討瞭如何讓AI安全對齊的難題。

當被問及OpenAI是否會開源大模型,Altman稱未來會有更多開源,但沒有具體模型和時間表。
另外,他還表示不會很快有GPT-5。
會後,Altman發文對這次受邀來智源大會演講表示感謝。

LeCun:依然是世界模型的擁躉
在頭一天發言的又一位圖靈獎得主LeCun,仍然繼續推行自己的「世界模型」理念。

對於AI毀滅人類的看法,LeCun一直表示不屑,認為如今的AI還不如一條狗的智能高,還沒有發展出真正的人工智能,這種擔心實屬多餘。
他解釋道:AI不能像人類和動物一樣推理和規劃,部分原因是目前的機器學習系統在輸入和輸出之間的計算步驟是基本恆定的。
如何讓機器理解世界是如何運作的,像人類一樣預測行為後果,或將其分解為多步來計劃複雜的任務呢?

顯然,自監督學習是一個路徑。相比強化學習,自監督學習可以產生大量反饋,能夠預測其輸入的任何一部分。
LeCun表示,自己已經確定未來幾年人工智能的三大挑戰,就是學習世界的表徵、預測世界模型、利用自監督學習。
而構建人類水平AI的關鍵,可能就是學習「世界模型」的能力。
其中,「世界模型」由六個獨立模塊組成,具體包括:配置器模塊、感知模塊、世界模型、cost模塊、actor模塊、短期記憶模塊。

他認為,為世界模型設計架構以及訓練範式,才是未來幾十年阻礙人工智能發展的真正障礙。
被問到AI系統是否會對人類構成生存風險時,LeCun表示,我們還沒有超級AI,何談如何讓超級AI系統安全呢?
最頂配「AI內行盛會」
轟轟烈烈的2023智源大會,可以說是本年度國內AI領域規格最高的、最受矚目的大會。
從創辦之初,智源大會的本質特徵就很明確:學術、專業、前沿。
轉眼間,這場面向AI內行的年度盛會已經來到了第五個年頭。
這次,2023智源大會繼續延續每一屆智源大會的傳統,學術氛圍感依舊爆棚。

2021年,第三屆智源大會上,圖靈獎得主Yoshua Bengio、北京大學教授鄂維南院士、清華大學國家金融研究院院長朱民帶來了主題演講。
2022年,兩位圖靈獎得主Yann LeCun和Adi Shamir、強化學習之父Richard Sutton、美國三院院士Michael I. Jordan、哥德爾獎獲得者Cynthia Dwork等重量級大佬做了分享。
而到了2023年,無疑是「星光最盛」的一屆。
共有4位圖靈獎得主Yann LeCun、Geoffrey Hinton、Joseph Sifakis和姚期智,以及OpenAI創始人Sam Altman、諾貝爾獎得主Arieh Warshel、未來生命研究所創始人Max Tegmark、2022年吳文俊最高成就獎得主鄭南寧院士和中國科學院張鈸院士等大佬參與。

更為重要的是,繼智源「悟道」大模型項目連創「中國首個+世界最大」紀錄之後,「悟道3.0」進入「全面開源」的新階段。
「悟道3.0」是一個大模型系列。
具體來說,包括悟道·天鷹(Aquila)語言大模型系列、天秤(FlagEval)大模型評測體系、「悟道·視界」視覺大模型系列,以及多模態大模型系列。

語言大模型系列
悟道·天鷹(Aquila):全面開放商用許可
首先登場的是悟道·天鷹(Aquila)系列大模型,是首個具備中英雙語知識,支持國內數據合規需求的開源語言大模型,並且已經全面開放商用許可。
這次開源的包括70億參數和330億參數的基礎模型,AquilaChat對話模型,以及AquilaCode「文本-代碼」生成模型。

悟道· 天鷹Aquila 開源地址:
https://github.com/FlagAI-Open/FlagAI/tree/master/examples/Aquila
性能更強
在技術上,Aquila基礎模型(7B、33B)在技術上繼承了GPT-3、LLaMA等的架構設計優點,替換了一批更高效的底層算子實現、重新設計實現了中英雙語的tokenizer,升級了BMTrain並行訓練方法,在Aquila的訓練過程中實現了比Magtron+DeepSpeed ZeRO-2 將近8倍的訓練效率。
具體來說,首先是得益於一個並行加速訓練框架的新技術。
智源去年開源的大模型算法開源項目FlagAI,裡面集成了BMTrain這樣的新的並行訓練方法。在訓練過程中,還進一步優化了它的計算和通信以及重疊的問題。
其次,智源率先引入了算子優化技術,跟並行加速方法集成到一起,進一步獲得了性能的提速。
又學中文,又學英文的大模型
悟道·天鷹(Aquila)的發布,為什麼如此值得鼓舞?
因為很多大模型都「只學英文」——只基於大量的英文語料訓練,但悟道·天鷹(Aquila)又要學中文,又要學英文。
大家可能有親身體驗:一個人學知識的時候,如果一直用英文就沒問題,但如果一下學英文,一下學中文,難度就會爆棚。
所以,比起LLaMA、OPT這類以英文為主的模型,需要同時學習中英文知識的悟道·天鷹(Aquila)的訓練難度提升了很多倍。
為了讓悟道·天鷹(Aquila)針對中文任務達到優化,在它的訓練語料上,智源放了將近40%的中文語料。究其原因是智源希望悟道·天鷹(Aquila)不只能生成中文,還能讀懂大量的中文世界的原生知識。
另外,智源還重新設計實現了中英雙語的tokenizer(分詞器),這是為了更好地識別和支持中文的分詞。
在訓練和設計的過程中,針對中文任務,智源團隊特意會權衡質量和效率兩個維度決定分詞器大小。
在悟道·天鷹(Aquila)基礎模型底座上打造AquilaChat對話模型(7B、33B)支持流暢的文本對話及多種語言類生成任務。

多輪對話

高考作文生成
此外,通過定義可擴展的特殊指令規範,可以實現AquilaChat對其它模型和工具的調用,且易於擴展。
例如,調用智源開源的AltDiffusion多語言文圖生成模型,實現了流暢的文圖生成能力。配合智源InstructFace多步可控文生圖模型,它還可以輕鬆實現對人臉圖像的多步可控編輯。
文圖生成
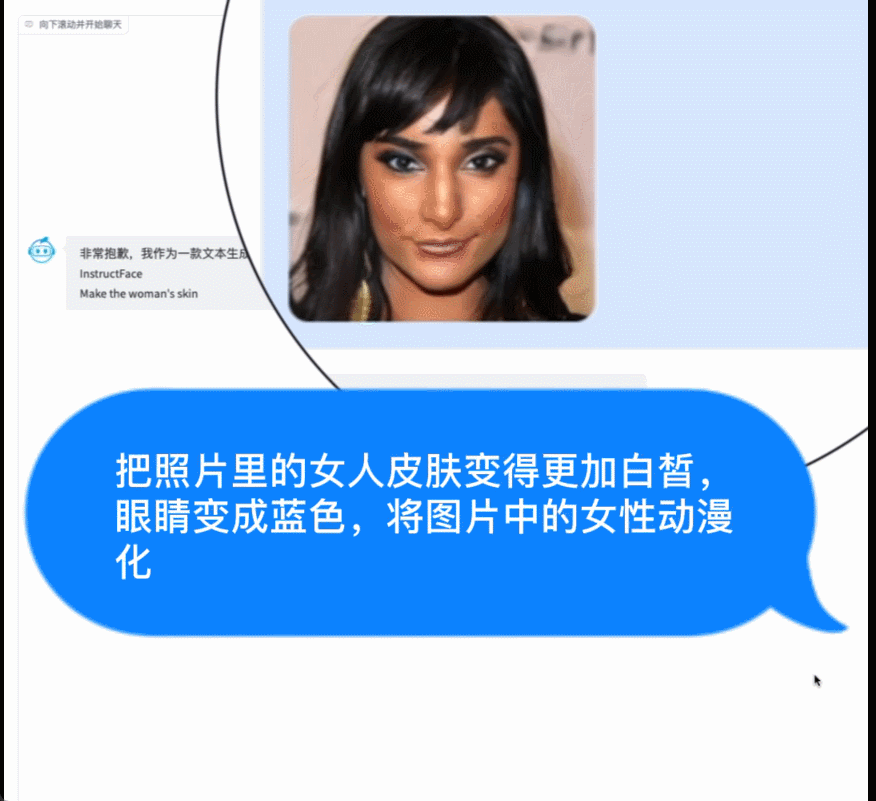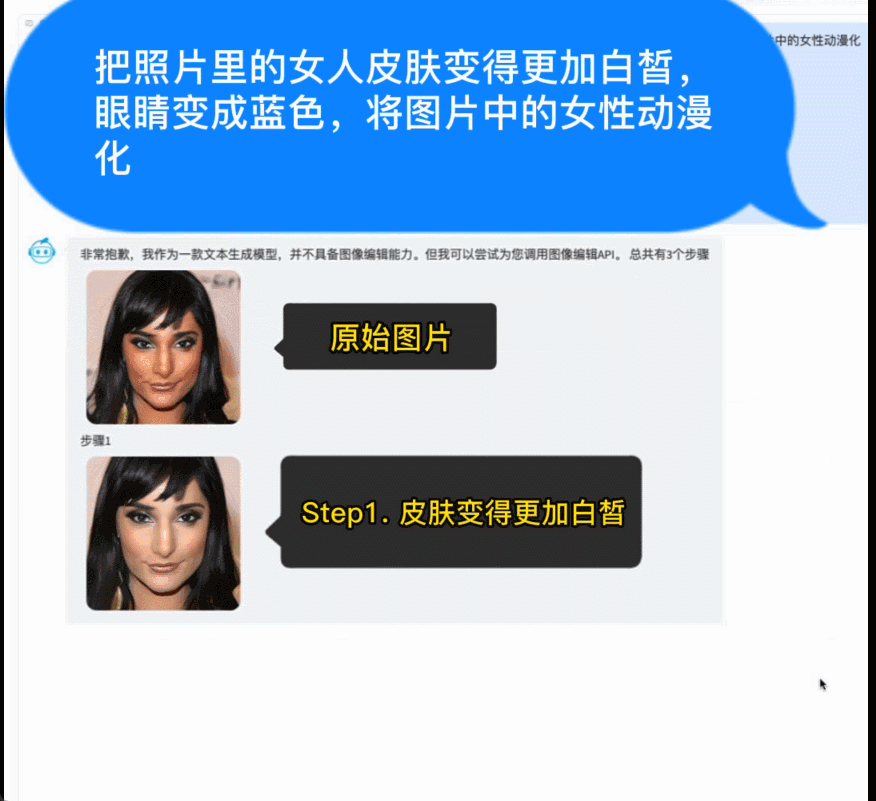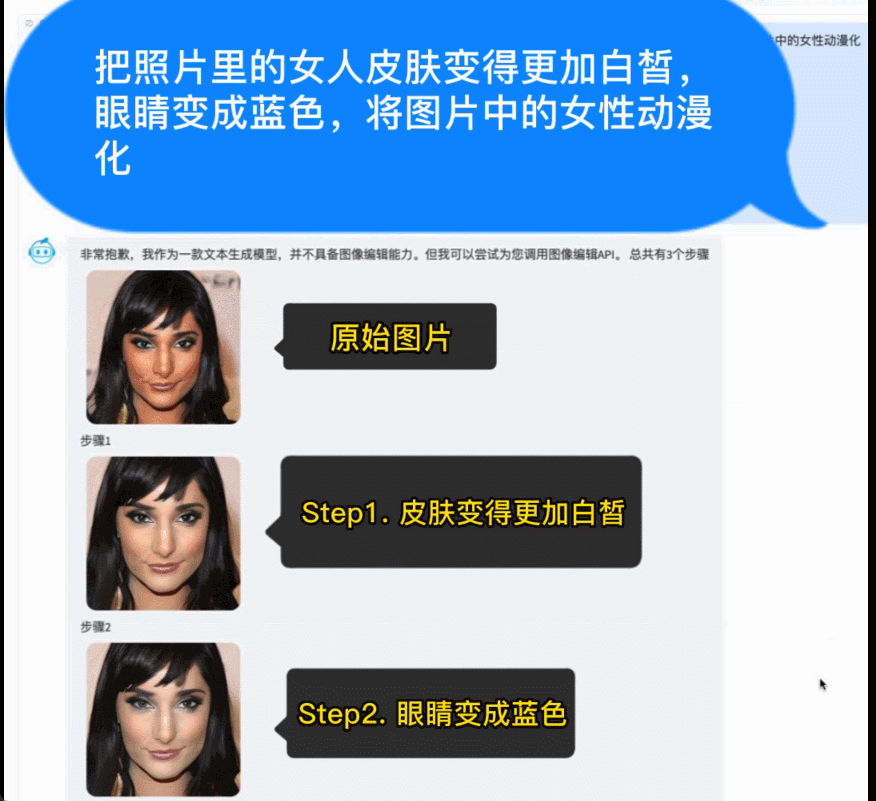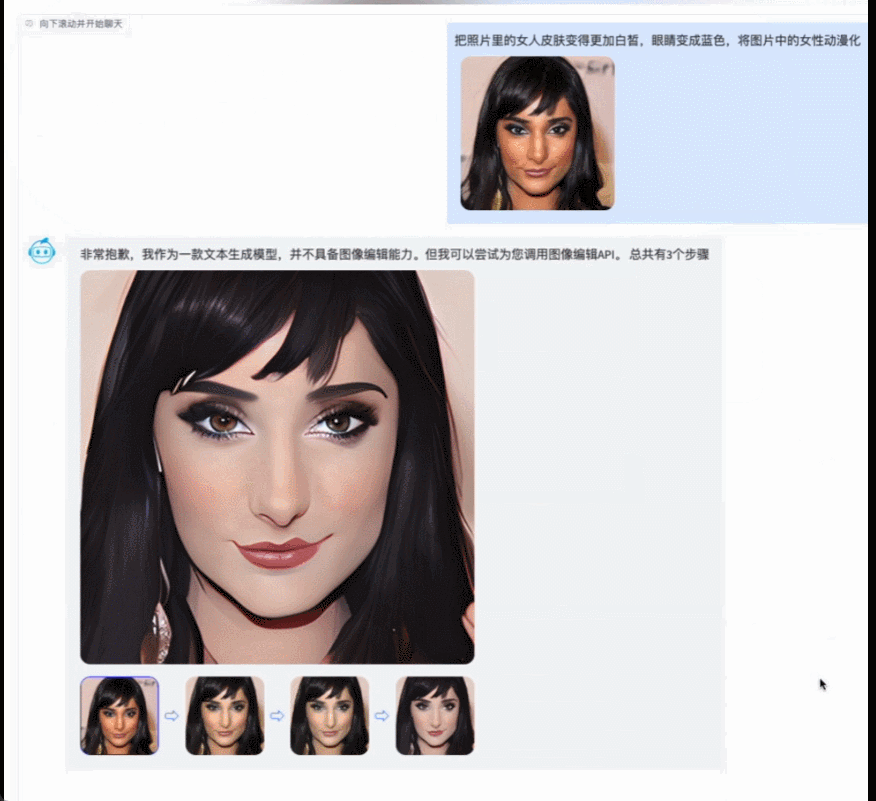
多步可控人臉編輯
AquilaCode-7B「文本-代碼」生成模型,基於Aquila-7B 強大的基礎模型能力,以小數據集、小參數量,實現高性能,是目前支持中英雙語的、性能最好的開源代碼模型,經過了高質量過濾、使用有合規開源許可的訓練代碼數據進行訓練。

此外,AquilaCode-7B分別在英偉達和國產芯片上完成了代碼模型的訓練,並通過對多種架構的代碼+模型開源,推動芯片創新和百花齊放。
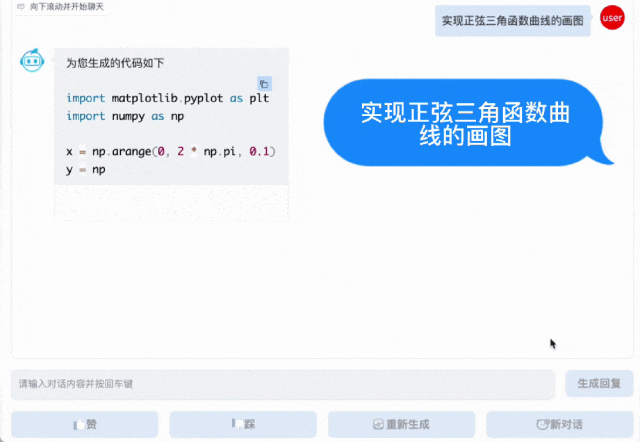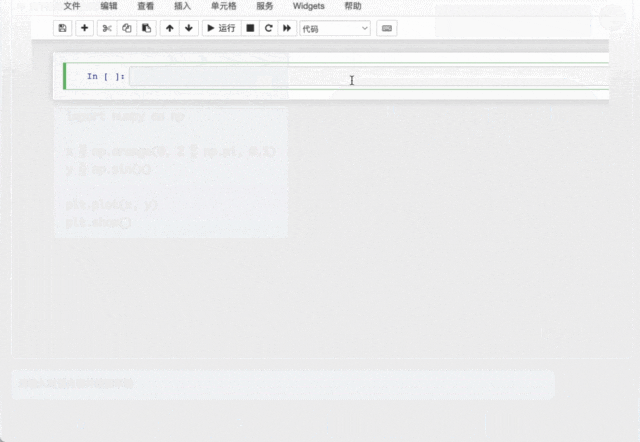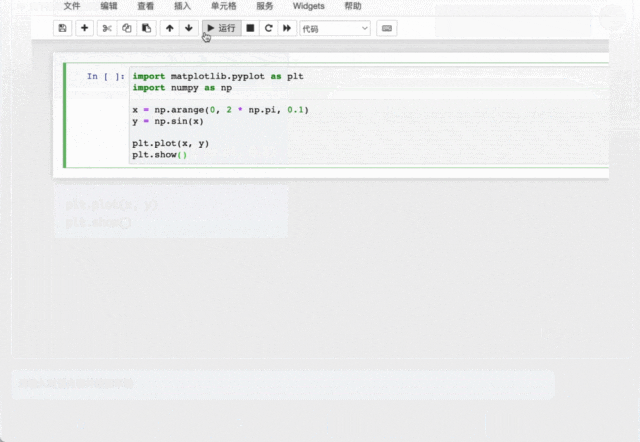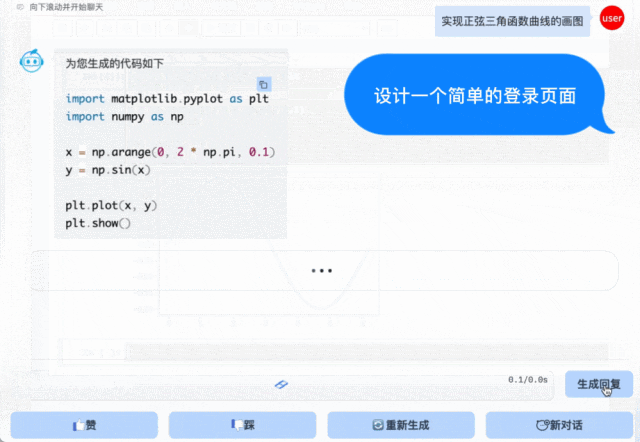
文本-代碼生成
更合規、更乾淨的中文語料
相比國外的開源大模型,悟道·天鷹(Aquila)的最鮮明的特點就在於,它支持國內數據合規需求。
國外大模型可能具備一定的中文能力,但是幾乎所有國外開源大模型使用的中文互聯網數據,都是從像Common Crawl 這樣的互聯網數據集上抽取的。
但如果對Common Crawl語料進行分析可以發現,它100萬條裡可用的中文網頁只有不到4萬個,並且其中83%是海外的網站,在質量上明顯不可控。
因此,悟道·天鷹(Aquila)並沒有使用Common Crawl裡的任何中文語料,而是用的智源自己過去三年多積累的悟道數據集。悟道中文數據集來自一萬多個中國大陸網站,因此它的中文數據更加滿足合規需要,更加干淨。
總的來說,這一次的發布只是一個起點,智源的目標是,打造一整套大模型進化迭代流水線,讓大模型在更多數據和更多能力的添加之下,源源不斷地成長,並且會持續開源開放。
值得注意的是,悟道· 天鷹(Aquila)在消費級顯卡上就可用。比如7B模型,就能在16G甚至更小的顯存上跑起來。
天秤(Flag Eval)大模型評測體系
一套安全可靠、全面客觀的大模型評測體係對於大模型的技術創新和產業落地也十分重要。
首先,對於學術界來說,如果想要促進大模型的創新,就必須有一把尺子,可以去衡量大模型的能力和質量到底如何。
其次,對於產業界來說,絕大多數企業都會選擇直接調用已有的大模型,而不是從頭研發。在挑選時,就需要一個評測體係來幫助判斷。畢竟,自研基礎大模型依賴龐大的算力成本。研發一個300億參數的模型,需要的經費包括算力、數據等,至少要兩千萬。
此外,是否有能力打造一套「自動化評測+人工主觀評測」的大模型全面評價系統,並實現從評測結果到模型能力分析,再到模型能力提升的自動閉環,已經成為基礎大模型創新的重要壁壘之一。
為了解決這一痛點,智源研究院選擇優先推出天秤(FlagEval)大模型評測體系及開放平台(flageval.baai.ac.cn)。
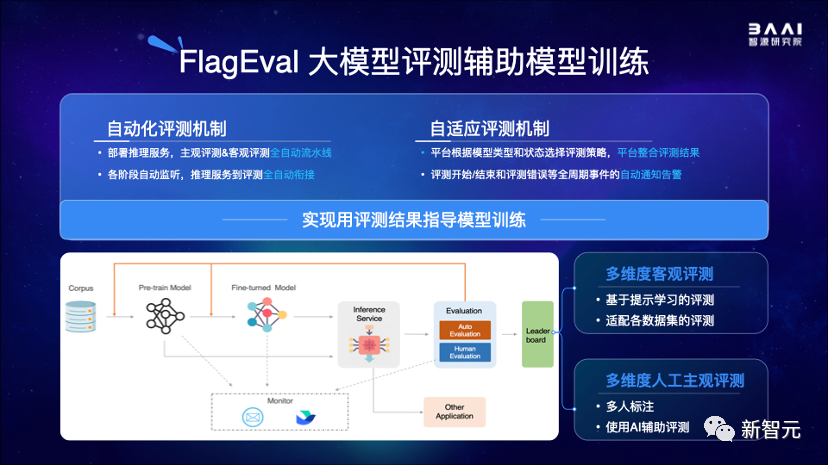
天秤(FlagEval)大模型評測體系及開放平台,旨在建立科學、公正、開放的評測基準、方法、工具集,協助研究人員全方位評估基礎模型及訓練算法的性能,同時探索利用AI方法實現對主觀評測的輔助,大幅提升評測的效率和客觀性。
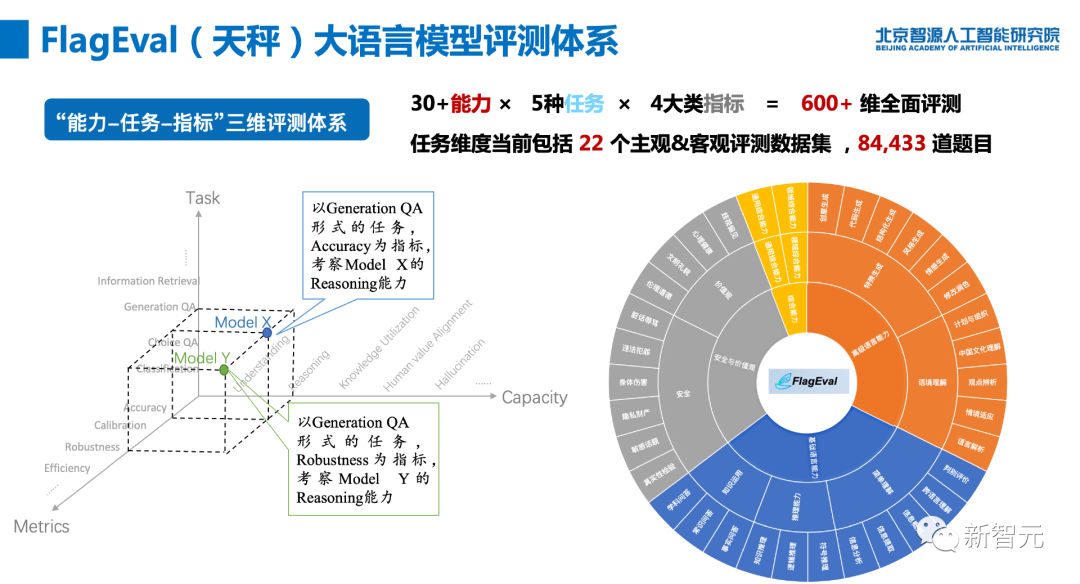
具體來說,天秤(FlagEval)大模型評測體系創新性地構建了「能力-任務-指標」三維評測框架,能夠細粒度刻畫基礎模型的認知能力邊界,可視化呈現評測結果。
目前,天秤(FlagEval)大模型評測體系包含了總計600+評測維度,包括22個評測數據集和84,433道題目,更多維度的評測數據集正在陸續集成。
此外,天秤(FlagEval)大模型評測體系還將持續探索語言大模型評測與心理學、教育學、倫理學等社會學科的交叉研究,以期更加全面、科學地評價語言大模型。
30+能力×5種任務×4大類指標=600+維全面評測
視覺大模型系列
在計算機視覺方面,悟道3.0團隊打造了具備通用場景感知和復雜任務處理能力的「悟道·視界」系列大模型。
其中,構建起「悟道·視界」底層基座的,正是這次6連發的SOTA技術:
多模態大模型「Emu」,預訓練大模型「EVA」,視覺通用多任務模型「Painter」,視界通用分割模型,圖文預訓練大模型「EVA-CLIP」以及視頻編輯技術「vid2vid-zero」。
1. Emu:在多模態序列中補全一切

Emu是一個接受多模態輸入,產生多模態輸出的大模型。基於多模態上下文學習技術路徑,Emu能從圖文、交錯圖文、交錯視頻文本等海量多模態序列中學習。
訓練完成後,Emu能在多模態序列的上下文中補全一切,對圖像、文本和視頻等多種模態的數據進行感知、推理和生成,完成多輪圖文對話、少樣本圖文理解、視頻問答、文圖生成、圖圖生成等多模態任務。
2. EVA:最強十億級視覺基礎模型

項目地址:https://github.com/baaivision/EVA
論文地址:https://arxiv.org/abs/2211.07636
EVA將語義學習模型(CLIP)和幾何結構學習方法(MIM)相結合,並把標準的ViT模型擴大規模到了10億參數進行訓練。一舉在ImageNet分類、COCO檢測分割、Kinetics視頻分類等廣泛的視覺感知任務中取得當時最強的性能。
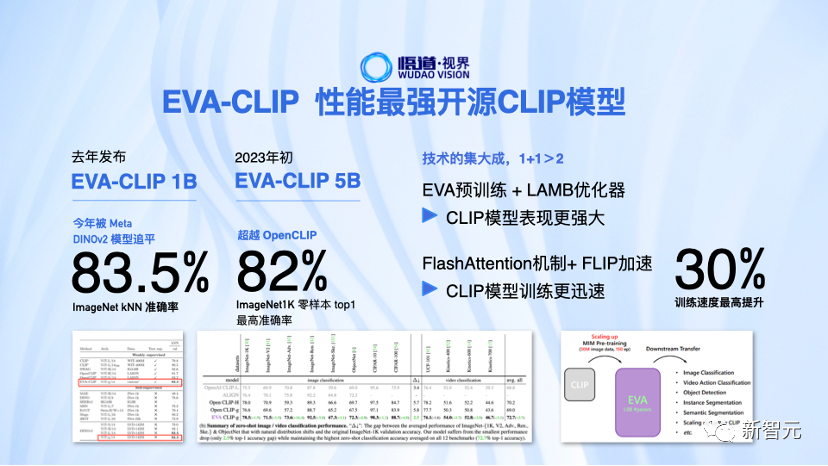
3. EVA-CLIP:性能最強開源CLIP模型
項目地址:https://github.com/baaivision/EVA/tree/master/EVA-CLIP
論文地址:https://arxiv.org/abs/2303.15389
以視覺基礎模型EVA為核心開發的EVA-CLIP,目前已經迭代至50億參數。
和此前80.1%準確率的OpenCLIP相比,EVA-CLIP模型在ImageNet1K零樣本top1準確率達到了82.0%。在ImageNet kNN準確率上,Meta最新發布的DINOv2模型和10億參數的EVA-CLIP持平。
4. Painter:首創「上下文圖像學習」技術路徑
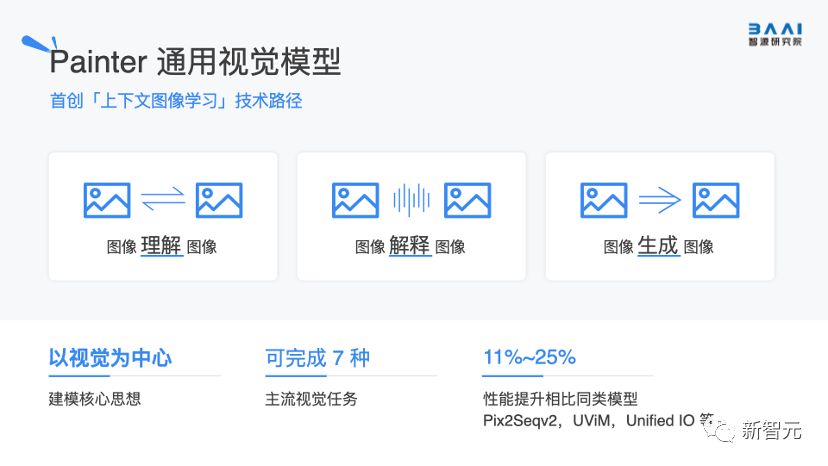
項目地址:https://github.com/baaivision/Painter
論文地址:https://arxiv.org/abs/2212.02499
通用視覺模型Painter建模的核心思想是「以視覺為中心」,通過將圖像作為輸入和輸出,來獲得上下文視覺信息,從而完成不同的視覺任務。
5. 視界通用分割模型:一通百通,分割一切

視界通用分割模型具有強大的視覺上下文推理能力,只需給出一個或幾個示例圖像和視覺提示,模型就能理解用戶意圖,並完成類似分割任務。
簡單來說,用戶在畫面上標註識別一類物體,即可批量化識別分割同類物體,無論是在當前畫面還是其他畫面或視頻環境中。
6. vid2vid-zero:業界首個零樣本視頻編輯技術

項目地址:https://github.com/baaivision/vid2vid-zero
論文鏈接:https://arxiv.org/abs/2303.17599
Demo地址:https://huggingface.co/spaces/BAAI/vid2vid-zero
零樣本視頻編輯技術「vid2vid-zero」,首次利用注意力機制的動態特性,並結合現有的圖像擴散模型,打造了一個無需額外視頻預訓練,即可進行視頻編輯的模型框架。現在,只需上傳一段視頻,然後輸入一串文本提示,就可以進行指定屬性的視頻編輯。
中國大模型研究的啟蒙者
2018年11月成立的智源研究院是中國大模型研究的啟蒙者,經過5年發展,更成為中國大模型研究的標杆。
與其他的機構與眾不同地方在於,智源研究院是一家平台性機構。成立之初,智源研究院就將營造人工智能創新生態作為基本使命和任務之一。
從創立至今,智源都如何推動了中國大模型研究的發展?

其實,智源研究院的成立恰恰趕在了國外大模型萌芽初現的一個契機。
說起來,2015年成立的OpenAI研究的主要方向是探索通往AGI的路線,也不是大模型。
從2018年後,OpenAI才開始集中轉向大模型,並在6月發布了有1.17億參數的GPT。同年,谷歌還發布了大規模預訓練語言模型BERT,有3億參數。
所有人都注意到,2018年的整個產業趨勢、技術趨勢都是做更大的模型。
隨著模型所用算力增長,摩爾定律變成所謂的「模型定律」,即訓練大模型所用算力3-4個月翻一番。
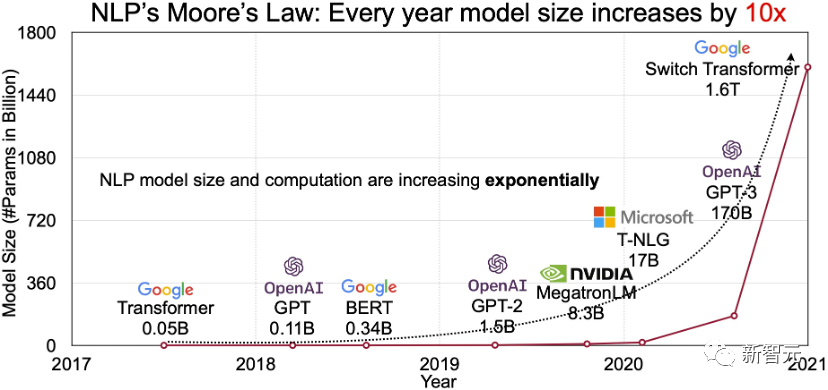
也正是2018年,智源研究院成立,率先匯聚了AI領域的頂尖學者,開啟了大模型探索。
由此,2021年,智源連著發布了悟道1.0,悟道2.0兩代大模型。
據黃鐵軍介紹,在2021年3月,悟道1.0發布會上,智源研判人工智能已經從「大煉模型」轉變為「煉大模型」的新階段,從此,「大模型」這個概念進入公眾視野。
每年的智源大會,都會重述攀登AGI高峰的三大技術路線:大模型、生命智能和AI4Science。這三條路線不是孤立的,它們之間相互作用和影響。

如今,大模型湧現能力出現的主要原因來自,背後的海量數據。
語言數據本身蘊含著豐富的知識和智能,通過大模型方式將其提煉出來,用神經網絡去表達複雜數據的背後規律。
這是大模型其中一條技術路線是能夠通向AGI的合理之處。
這也就解釋了,智源為什麼最初將重心放在大模型上。 2021年3月發布悟道1.0,緊接著6月發布了悟道2.0。
此外,除了大模型,在通往AGI的另外兩條路「生命智能」和「AI4Science」上,智源也在不斷探索。
2022年,智源發布了最高精度的仿真秀麗線蟲。這次,智源將仿真線蟲研究所用的生命模擬平台「天演-eVolution」開放,提供在線服務。
天演是超大規模精細神經元網絡仿真平台,具有四項顯著特點:當今效率最高的精細神經元網絡仿真的平台;支持超大規模的神經網絡仿真;提供一站式在線建模與仿真工具集;高質量可視化交互,支持實時仿真可視協同運行。
基於天演平台,實現對生物智能進行高精度仿真,探索智能的本質,推動由生物啟發的通用人工智能。進一步地,天演團隊已將天演接入我國新一代百億億次超級計算機-天河新一代超級計算機。
通過「天演-天河」的成功部署運行,實現鼠腦V1視皮層精細網絡等模型仿真,計算能耗均能降低約10倍以上,計算速度實現10倍以上提升,達到全球範圍內最極致的精細神經元網絡仿真的性能,為實現全人腦精細模擬打下堅實基礎。
兩年後的現在,智源再次發布悟道3.0系列大模型。
從定位上講,自悟道2.0發布後,智源作為一個非盈利的平台性機構,不僅是做模型發模型,逐漸偏向為構建大模型核心生態做出獨特貢獻。
其中,就包括模型背後數據梳理,模型測試,算法測試,開源開放組織,以及算力平台等全方位佈局。
智源為什麼有這樣一個轉變?
因為智源深刻認識到,大模型本身不是大模型時代最主要的產品形態,而是一個體系化,以智力服務為特徵的一個新的時代。
當前,大模型一定會不斷持續演進,不變的是背後的技術迭代,即訓練模型的算法。
你每天所見的最新模型,不過是個固化的結果,重要的是訓練模型的算法是否先進,成本是否有效降低,背後能力是否可解釋、可控。
因此,作為一個平台機構,智源要做的是,把業界訓練模型的算法彙聚成一個不斷迭代的整體。
這項工作是必要的,智源不僅做大模型算法本身,同時也要花更多時間精力為大模型的技術體係發展添磚加瓦。
比如,智源推出了大型雲計算服務平台「九鼎智算平台」,為大模型訓練提供算力、數據、算法的支持。
當然,並不是僅憑智源一己之力,還有產學研一起以開放方式進行協作和迭代。
今年3月,智源發布了FlagOpen飛智大模型技術開源體系,是與多家產學研單位共同構建的大模型開源開放軟件體系。
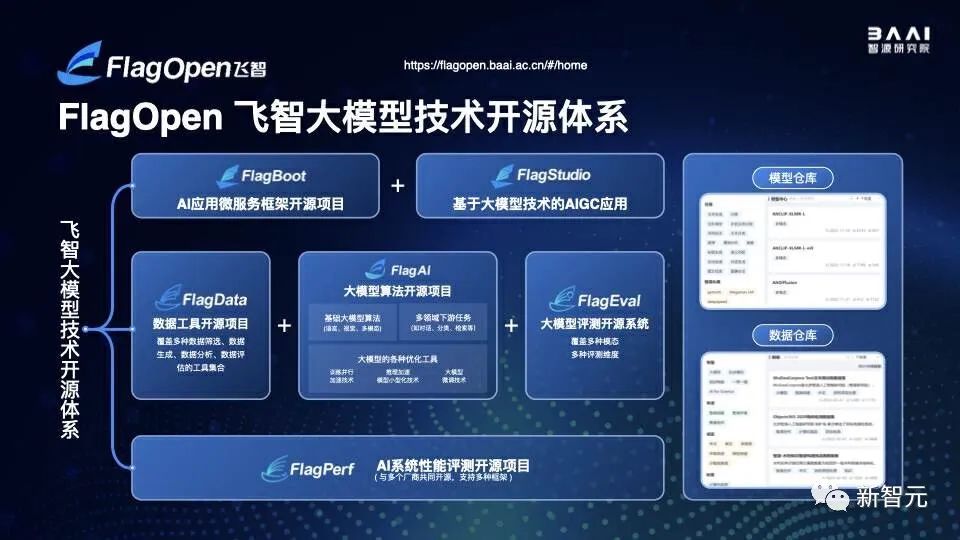
正如黃鐵軍院長所稱,「我們希望在大模型已然成為人工智能產業發展的主導力量的當下,未來做更多的支撐性工作,為這個時代貢獻一份獨特力量」。
或許你會問,今年的智源大會與往屆相比最大特色是什麼?
風格一貫,兩個詞總結下:專業和純粹。
智源大會的召開沒有任何現實目標,不關注產品如何、投資者如何。
在這裡,業界大佬能夠以專業角度提出個人觀點,做出判斷,當然還包括頂級觀點的碰撞、爭論,不用去考慮諸多現實因素。
「AI教父」Geoffrey Hinton今年第一次參加智源大會,前段時間還因為後悔畢生工作離職谷歌。他發表了最新關於人工智能安全的觀點。
一如既往的「樂觀派」Yann LeCun不會像多數人擔憂人工智能風險,在他看來車還沒有造好就剎車太不合理,當前還是要努力發展更先進AI技術和算法。
同時,你也會看到會上觀點的激烈交鋒。 Max Tegmark講述控制人工智能風險。雖和LeCun不能說完全對立,但也有很大差異。
這便是智源大會最大的看點,也是一貫的風格。
這一定位的獨特性,從這些年來看,也是愈發重要。
人工智能的發展對全球、對中國的影響越來越大,因此大家需要一個場合,用純粹方式輸出自己的觀點,包括思想碰撞、激烈爭論。
這樣的意義在於,只有越專業,越純粹,越中立,越開放的會議,越有利於大家更好的把握這樣的一個高速發展的時代,同時還能第一整個對人工智能生態發展起獨特的作用。
在國外,智源大會同樣口碑極好,國際機構將智源大會作為與中國開展人工智能研究合作的一個窗口。
智源這一名字由來,也是智能的源頭。因此,舉辦智源大會已經成為促進人工智能生態發展一個標誌性活動。
嘉賓陣容之強大、議題設置之豐富、內容討論之深度,這些都造就了獨一無二的智源大會。
這場專屬AI內行的頂級盛會,已成為中國AI領域的亮眼名片。
參考資料:
- https://2023.baai.ac.cn/
展開全文打開碳鏈價值APP 查看更多精彩資訊
