真正的賽點是應用。
從百度的文心一言開始,生成式AI成為中國的互聯網及科技公司進發的新高地,阿里巴巴的通義千問、騰訊的混元、華為的盤古、科大訊飛的星火到昨天360發布智腦,國產的生成式AI產品頻繁曝光,AI在國內已經儼然科技新風口,也在海外引發關注。
“中國在生成式AI上有多強?”這是近日英國時政雜誌《經濟學人》發文的標題。文章從論文數、系統數、算力和芯片硬件幾個基礎層面的4張圖表,比對了兩國的實力。文章認為,目前中國的大模型落後於美國兩到三年,原因在於兩國在訓練數據、芯片等硬件及科技人才上的距離。
文章也指出,這些差距都有各自的解決方式,最終,差距不會太大,而美國真正的優勢地帶是將技術高效應用和擴散的能力。以下為這篇《經濟學人》文章的編譯節選:

從北京和華盛頓唱的高調來看,中國和美國正在全力投入一場爭奪科技霸主的較量。
“從根本上說,我們相信少數幾項技術將在未來十年發揮極其重要的作用。”美國總統拜登的國家安全顧問傑克·沙利文(Jake Sullivan)去年9月這樣說。今年2月,中國領導人同樣呼應了這一觀點稱“我們迫切需要加強基礎研究,從源頭和底層解決關鍵的技術問題”,以“應對國際科技競爭、實現高水平的自立自強”。
當下,沒有哪項技術比人工智能(AI)更能吸引太平洋兩岸決策者的關注。 ChatGPT等生成式AI能力的迅速提升,愈發加強了這種關注。這類大模型分析網絡上所有的文本、圖像或聲音,然後創造出越來越真實的仿造物。
如果生成式AI真的像其支持者說的那樣具有革命性,那麼善於運用它的國家就可能在21世紀重要的地緣政治競爭中獲得經濟和軍事上的優勢。西方和中國的戰略家已經在討論AI軍備競賽。這場競賽中,中國能贏嗎?
過去幾年,中國在某些衡量AI實力的指標上領先於美國。 2019年,中國的AI論文佔比超過了美國。 2021年,全球26%的AI論文來自中國,而來自美國的佔比只有17%。按AI論文發表量計算,全球排名前十的機構中有九個在中國。根據一個常用的基準,計算機視覺領域排名前五的實驗室也都在中國。
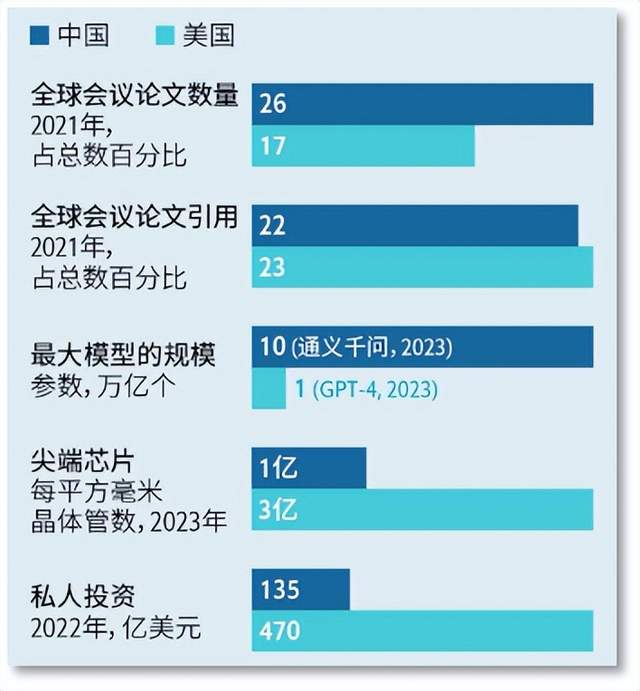 中美AI相關指標的對比
中美AI相關指標的對比
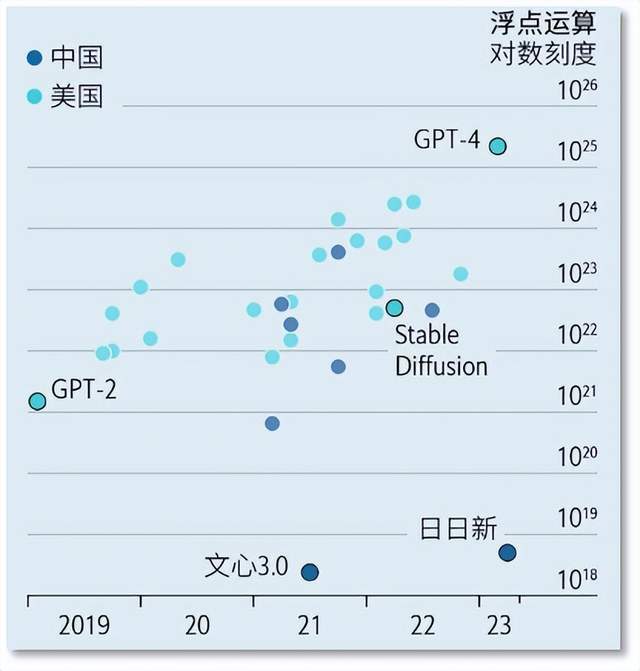
然而,在“基礎模型”這種賦予生成式AI智慧的領域,美國的優勢明顯。
ChatGPT及其背後先進的模型(最新版本為GPT-4)是美國創業公司OpenAI研發的。其他美國公司也有自己強大的系統,其中既有Anthropic或StabilityAI等小公司,也有谷歌、Meta和微軟(持有部分OpenAI股份)等科技巨頭。文心一言是中國互聯網搜索巨頭百度打造的對標ChatGPT的產品,人們普遍認為它的智能程度沒有ChatGPT高。
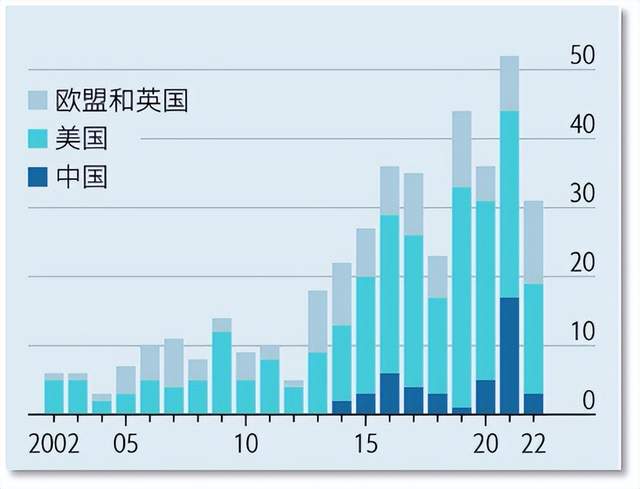 中國、美國、歐洲的機器學習系統的數量對比
中國、美國、歐洲的機器學習系統的數量對比
這使業內人士得出了這樣的結論:中國在建立基礎模型方面比美國落後兩到三年。
造成這一差距的原因有三個。第一個原因涉及數據。例如,商湯科技、曠視科技等AI公司獲得來自政府部門的數據後,在其領先的計算機視覺實驗室的幫助下開發出了一流的面部識別系統。這項優勢到了生成式AI上卻沒有那麼強大了,因為基礎模型是用網絡上大量的非結構化數據訓練的。
根據互聯網研究網站W3Techs的數據,全球56%的網站是英文的,而只有1.5%的網站是中文的,這有利於美國的建模者。
斯坦福大學的傅亦沁博士指出,中國人主要是通過微信和微博等App上網互動。這些App屬於“圍牆內的花園”,其中大部分內容都沒有在搜索引擎上建立索引。這讓AI模型在訓練時難以吸收這些內容。例如,北京智源人工智能研究院於2021年推出的模型“悟道2.0”儘管在計算層面上有可能比GPT-4更複雜,但未能引起轟動,缺乏數據也許是一個原因。
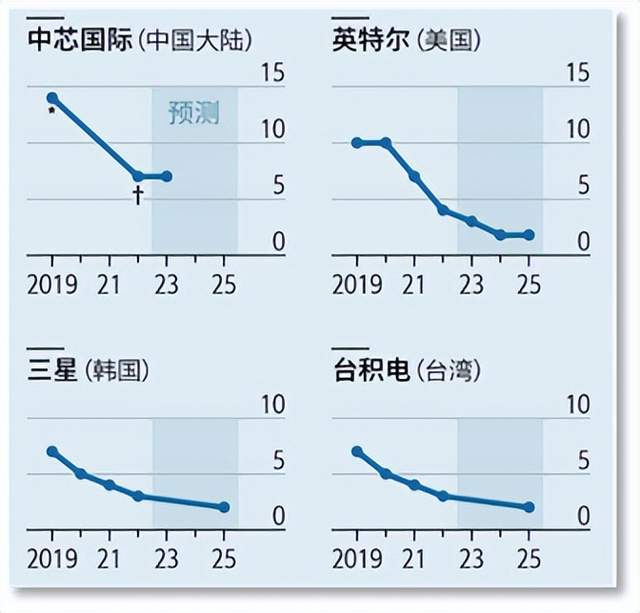 各大半導體公司的芯片生產能力
各大半導體公司的芯片生產能力
中國在生成式AI上的表現平平的第二個原因與硬件有關。去年,美國對一些AI領域的關鍵技術實施了面向中國的出口管制,其中包括雲計算數據中心(基礎模型在其中學習)所用的微處理器,以及可以讓中國自行製造此類半導體的芯片製造工具。
這打擊了中國的大模型研發。英國智庫AI治理中心分析了26個中國大模型後發現,超過一半的模型的芯片都要依賴美國芯片公司英偉達。一些報告表明,中國最大的芯片製造商中芯國際的產品只比行業領導者台積電晚一兩代,但中芯國際目前只能大規模生產台積電在三四年前就量產了的芯片。
另一樣中國AI公司難以從美國引入的東西是人才。目前,美國對全球科技人才仍然極具吸引力:在期刊上發布論文的美國AI專家中有三分之二在國外出生。 2019年,華裔工程師占到這個頂尖群體的27%。許多中國的AI研究人員曾在美國學習或工作,然後帶著專業知識回國。不過,新冠疫情和中美關係緊張加劇導致這一群體的人數下降。 2022年上半年,美國向中國學生髮放的簽證數量是2019年同期的一半。
數據、硬件和人才的三重短缺對中國的AI發展造成了障礙,但這些因素是否會在更長時間內阻礙中國的AI雄心則是另一回事。
先說數據問題。今年2月,在聚集了中國近三分之一AI公司的北京,當地政府承諾開放115個政府下屬單位的數據,為建模機構提供15880個數據集。前美國駐華外交官,現就職於牛津大學的凱拉·布洛姆奎斯特(Kayla Blomquist)表示,中國政府此前曾表示希望拆除中國App的圍牆,這樣可能會釋放出更多數據。
另外,近期這批大火的生成式大模型能夠將機器學習的成果從一種語言轉換為到另一種語言。 OpenAI表示,儘管在訓練數據中缺乏中文材料,但GPT-4在中文任務上的表現非常出色。喬治華盛頓大學的杰弗里丁(Jeffrey Ding)指出,百度的文心接受了大量英語數據的訓練。
在硬件方面,中國也在尋找變通辦法。英國《金融時報》3月報導稱,被美國列入黑名單的商湯科技利用了中間商規避出口管制。另一些中國AI公司正通過位於其他國家的雲服務器使用英偉達的芯片。還有一個辦法是購買更多英偉達不太先進的產品。為了繼續服務廣大的中國市場,英偉達設計了符合製裁規定的產品,這些產品的速度比頂級產品慢10%到30%。對於中國客戶來說,這增加了處理能力的成本,但至少還夠用。
中國還可以用開源模型讓缺乏芯片和人才的問題得到一定程度的緩解。任何人都可以下載開源模型的內在工作機制,並針對特定任務進行微調。這當中包括了模型參數,這些數字決定了模型的結構,是經由成本高昂的大量訓練得出的。斯坦福大學的研究人員使用Meta的基礎模型LLaMA的參數構建了一個名為Alpaca的模型,成本不到600美元,而訓練GPT-4這樣的模型可能需要1億美元。 Alpaca在某些任務上的表現不遜於ChatGPT的最初版本。
考慮到上述因素,很難想像美國或中國能夠在AI大模型方面建立不可逾越的領先優勢。兩國可能最終將擁有能力類似的AI,即使中國在過程中會因為美國的製裁而付出額外代價。但是,如果大模型的競爭勢均力敵,那麼美國的另一個優勢有可能讓它成為AI大贏家,那就是它有能力在經濟體系中廣泛應用其尖端科技。歷史上,正是新技術在大範圍內的高效應用幫助美國在與蘇聯的科技競賽中取得領先,儘管蘇聯在上世紀50年代培養的理科博士數量是美國的兩倍。
中國遠比蘇聯善於應用新科技。它的金融科技平台、5G電信和高鐵都是世界一流的。儘管如此,杰弗裡·丁表示,這些成功可能只是例外,而不是常態,尤其是中國在部署雲計算和商業軟件方面的表現沒那麼出色,而這兩者都是AI的配套設施。
儘管美國的出口管制可能並不會阻礙中國所有的大模型進展,但會在更廣的範圍裡限制中國的科技產業,從而減緩對新科技的採用。比如,中國企業整體而言缺乏積極推動新技術擴散的技術專家,以及資金流向AI行業的不確定性。去年,對中國AI創業公司的私人投資為135億美元,不到流向美國競爭對手的資金的三分之一。據數據供應商PitchBook稱,在2023年的前四個月,這一投資的差距似乎又進一步擴大了。
無論生成式AI是否真的具有革命性,自由市場已經把賭注押在能充分利用它的玩家身上。
展開全文打開碳鏈價值APP 查看更多精彩資訊