「如果發布的是GPT-5,那OpenAI依然遙遙領先。如果是AI Search或者是語音助手,那就說明OpenAI沒落了。”
一位AI大模型從業人員告訴虎嗅,業界對OpenAI的期望太高,除非是GPT-5這樣的顛覆式創新,否則很難滿足觀眾的「胃口」。
雖然Sam Altman在OpenAI線上直播前,已經預告不會發布GPT-5(或GPT-4.5),但外界對OpenAI的期待早已是九牛拉不轉了。
北京時間5月14日凌晨,OpenAI公佈了最新的GPT-4o,o代表Omnimodel(全能模型)。 20多分鐘的演示直播,展示了遠超當前所有語音助理的AI互動體驗,與外媒先前透露的消息基本重合。
雖然GPT-4o的演示效果仍可稱得上“炸裂”,但業內人士普遍認為很難配得上Altman預告中的“魔法”二字。很多人認為,這些功能性的產品,都是「偏離OpenAI使命」的。
OpenAI的PR團隊似乎也預料到了這種輿論走向。發布會現場以及會後Altman發布的部落格中對此解釋:
「我們使命的關鍵部分是將非常強大的人工智慧工具免費(或以優惠的價格)提供給人們。我非常自豪我們在ChatGPT 中免費提供了世界上最好的模型,沒有廣告或類似的東西。
當我們創辦 OpenAI 時,我們最初的想法是我們要創造人工智慧並利用它為世界創造各種利益。相反,現在看起來我們將創造人工智慧,然後其他人將使用它來創造各種令人驚奇的事物,讓我們所有人都受益。 」
“如果我們必須等待 5 秒鐘才能得到’每個’回复,用戶體驗就會一落千丈。即使合成音頻本身聽起來很真實,它也會破壞沉浸感,讓人感覺毫無生氣。”
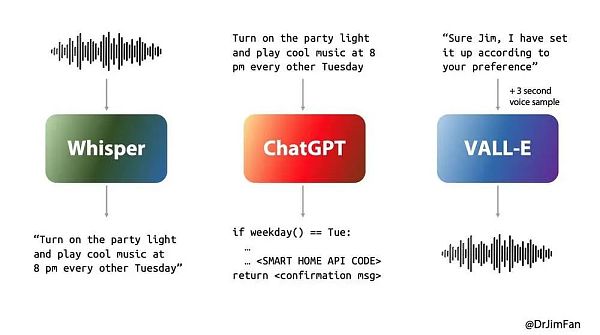
在OpenAI發布會前夕,英偉達Embodied AI負責人Jim Fan在X上預測了OpenAI會發布的語音助手,並提出:
幾乎所有的語音AI都會經歷三個階段:
1. 語音辨識或“ASR”:音訊->文字1,例如Whisper;
2. 計畫下一步要說什麼的 LLM:text1 -> text2;
3. 語音合成或“TTS”:text2 ->音頻,例如ElevenLabs或VALL-E。
經歷 3 個階段會導致巨大的延遲。
GPT-4o在反應速度方面,幾乎解決了延遲問題。 GPT-4o的響應音訊輸入的最短時長為232毫秒,平均響應時長320毫秒,幾乎與人類相似。沒有使用GPT-4o的ChatGPT語音對話功能平均延遲為2.8秒 (GPT-3.5) 和5.4秒(GPT-4)。
GPT-4o不僅透過縮短延遲大大提升了體驗,還在GPT-4的基礎上做了很多升級包括:
-
極佳的多模態互動能力,包括語音、視頻,以及螢幕分享。
-
可以即時辨識和理解人類的表情,文字,以及數學公式。
-
互動語音感情豐富,可以變換語音語調、風格,還可以模仿,甚至「即興」唱歌。
-
超低延時,且可以在對話中即時打斷AI,增加資訊或開啟新話題。
-
所有ChatGPT用戶均可免費使用(有使用上限)。
-
速度是GPT-4 Turbo的2倍,API成本低50%,速率限制高5倍。
“這些限制的突破都是創新。”
有業內專家認為,GPT-4o的多模態能力只是「看起來」很好,實際上OpenAI並未展示對於視覺多模態來說真正算是「突破」的功能。
這裡我們按大模型產業的習慣,比較一下隔壁廠Anthropic的Claude 3。
Claude 3的技術文件中提到,「雖然Claude的影像理解能力是尖端的,但需要注意一些限制」。
其中包括:
-
人物識別:Claude不能用於在圖像中識別(即姓名)人物,並將拒絕這樣做。
-
準確度:Claude在解釋200像素以下的低品質、旋轉或非常小的影像時,可能會產生幻覺或犯錯。
-
空間推理:克勞德的空間推理能力有限。它可能很難完成需要精確定位或佈局的任務,例如讀取模擬鐘面或描述棋子的確切位置。
-
計數:Claude可以給出影像中物體的近似計數,但可能並不總是精確且準確的,特別是對於大量小物體。
-
AI產生的圖像:Claude不知道圖像是否是人工智慧生成的,如果被問到,可能不正確。不要依賴它來檢測假影像或合成影像。
-
不適當的內容:Claude不會處理違反我們可接受使用政策的不適當或露骨的影像。
-
醫療保健應用:雖然Claude可以分析一般醫學影像,但它不是為解釋CT或MRI等複雜診斷掃描而設計的。 Claude的輸出不應被視為專業醫療建議或診斷的替代品。
在GPT-4o網站發布的案例中,有些與「空間推理」有相關的能力,但仍難算得上突破。
此外,從發表會現場示範中GPT-4o輸出的內容很容易看出,其模型能力與GPT-4相差不大。
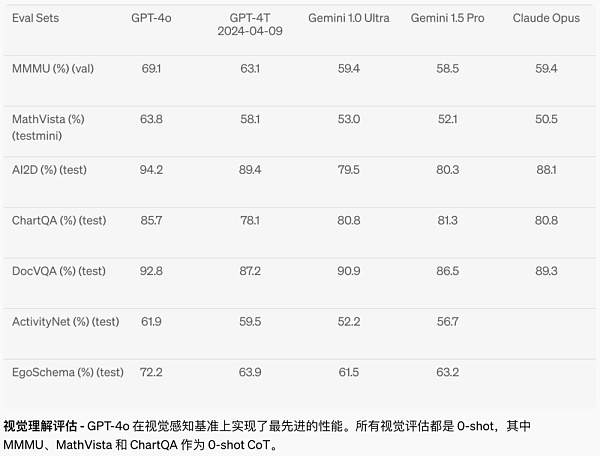
GPT-4o跑分
雖然模型可以在對話中增加語氣,甚至即興演唱,但對話內容還是與GPT-4一樣缺乏細節與創意。
此外,發布會後OpenAI官網也發布了GPT-4o的一系列應用案例探討。包括:照片轉漫畫風格;會議記錄;圖片合成;基於圖片的3D內容生成;手寫體、草稿生成;風格化的海報,以及連環畫生成;藝術字體生成等。
而這些能力中,照片轉漫畫風格、會議紀錄等,也都是一些看起來很普通的文生圖或是AI大模型功能。
「我註冊5個免費的ChatGPT帳號,是不是就不需要每月花20美元訂閱ChatGPT Plus呢?”
OpenAI公佈的GPT-4o使用政策是ChatGPT Plus用戶比限制一般用戶的流量限制高出5倍。
GPT-4o對所有人免費,首先挑戰的似乎是OpenAI自己的商業模式。
第三方市場分析平台Sensor Tower公佈的數據顯示,過去一個月中,ChatGPT在全球App Store的下載量為700萬,訂閱收入1200萬美元;全球Google Play市場的下載量為9000萬,訂閱收入300萬美元。
目前,ChatGPT Plus在兩家應用程式商店的訂閱價格均為19.99美元。由訂閱數據推斷,ChatGPT Plus過去一個月中,透過應用程式商店付費的訂閱用戶數為75萬人。雖然ChatGPT Plus還有大量的直接付費用戶,但從手機端的營收來看,每年進項才不到2億美元,再翻幾倍也很難撐起OpenAI近千億的估值。
由此來看,OpenAI在個人用戶儲值方面,其實不需要考慮太多。
更何況GPT-4o主打體驗好,如果你跟AI聊聊就斷了,還要換帳號重新聊,那你會不會憤然充值呢?
「最初的 ChatGPT 暗示了語言介面的可能性;這個新事物給人的感覺有本質上的不同。它快速、智能、有趣、自然且有幫助。”
Sam Altman的最新部落格中提到了“語言介面的可能性”,這也正是GPT-4o接下來可能要做的:挑戰所有GUI(圖形互動介面),以及想要在LUI(語音互動介面)上發力的人。
結合近期外媒透出的OpenAI與蘋果合作的消息,可以猜測GPT-4o可能很快就要對所有AI PC、AI手機的廠商「拋橄欖枝」或「掀桌」。
不管是哪一種語音助理或是AI大模型,對於AIPC、AI手機來說核心價值都是優化體驗,而GPT-4o一下把體驗優化到了極致。
GPT-4o很可能會捲到所有已知的App,甚至是SaaS產業。在過去一年多時間裡,市場上所有已經開發和正在開發的AI Agent都會面臨威脅。
某位資源聚合類app產品經理曾對虎嗅表示,“我的操作流程就是產品的核心,如果操作流程被你ChatGPT優化了,那相當於我的App沒價值了。”
試想,如果訂外賣的App,UI變成了一句話“給我訂餐”,那打開美團還是打開餓了麼,對於用戶來說就一樣了。
廠商的下一步只能是壓縮供應鏈、生態的利潤空間,甚至是惡性價格戰。
從目前的形式來看,其他廠商要在模型能力上打敗OpenAI恐怕還需要一段時間。
產品要對標OpenAI,可能只有透過做更「便宜」的模型了。
“最近忙死了,沒顧上關注他們。”
一位工業AI大模型創辦人告訴虎嗅,近期一直忙著溝通策略合作、產品發布、客戶交流資本交流,完全沒有時間關注OpenAI這種發布。
OpenAI發布前,虎嗅也詢問了多位來自各行各業的國內AI從業者,他們對OpenAI最新發布的預測與看法都很一致:非常期待,但與我無關。
一位從業人員表示,從國內目前的進度來看,要在短期內追上OpenAI不太現實。所以關心OpenAI發布了什麼,最多也就是看看最新的技術方向。
目前國內公司在AI大模型研發方面,普遍比較關注工程化和垂直模型,這些比較務實、容易變現的方向。
在工程方面,近期躥紅的Deepseek就正在國內大模型產業中掀起Token的價格戰。在垂直模型方面,多位業內人士告訴虎嗅,短期內小模型和垂直模型的研發,基本上都不會受到OpenAI的裹挾。
「有時候OpenAI的技術方向也不是很值得借鏡。」一位模型專家對虎嗅表示,Sora就是個很好的例子,2024年2月OpenAI發布了視頻模型Sora,實現了60秒的視頻穩定輸出。雖然看起來效果很好,但後續的練習幾乎沒有,落地速度也非常慢。
在Sora之前,國內很多在文生視頻領域發力的公司和機構已經實現了15秒穩定視頻生成,而Sora出來以後,一些公司的研發、融資、產品節奏都被打亂了,甚至使整個文生視頻產業的發展演變成了一場「技術的大躍進」。
所幸,這次GPT-4o與Sora大不同。 OpenAI CTO Muri Murati 表示,在接下來的幾週內,我們將繼續我們的迭代部署,為您提供所有功能。
發表會結束不久,GPT-4o就已經可以上線試用了。